在学习Python的时候,针对的如何导入模块、包等基本上都是一笔带过。原因除了导入的语法非常简单外,另一方面是学习初期不会涉及到大型的项目,也不会涉及到自己编写模块和包,通常不会在这里遇到什么问题。而在实际使用Python的过程中往往会在部署或者打包时遇到import出错或者失败,在不了解相关机制的情况下很难解决问题。
关于Python模块、包、库、框架的区别前面已经简单的梳理了一遍,这里就不再重复,接下来就直入主题。
Python的import语句
import语句是Python最常用的导入机制,但不是唯一方式。importlib.import_module() 以及内置的 __import__() 函数都可以调起导入机制。
Python的import语句实际上结合了两个操作:
- 搜索操作:根据指定的命名查找模块
- 绑定操作:将搜索的结果绑定到当前作用域对应的命名上
当一个模块被首次导入时,Python会搜索该模块,如果找到就创建一个module对象并初始化;如果未找到则抛出ModuleNotFoundError 异常。至于如何找到这些模块,Python定义了多种的搜索策略(search strategy),而这些策略可以通过importlib等提供的各类hook来修改和扩展。
根据Python3.3的changlog可知目前导入系统已完全实现了PEP302的提案,所有的导入机制都会通过sys.meta_path暴露出来,不会再有任何隐式的导入机制。
绝对导入与相对导入
相对导入是Python2.5之前的默认的导入方法,形式如下:
from .example import a from ..example import b from ...example import c
绝对导入也叫做完全导入,在Python2.5之后被完全实现,同时在PEP8中也提倡使用,它的使用方式如下:
from pkg import foo from pkg.moduleA import foo
使用绝对导入,我们经常会遇到因为位置问题,Python找不到相应的库文件从而抛出ImportError异常。
模块搜索路径
当我们要导入一个模块时,解释器首先会根据命名查找内置模块,如果没有找到,它就会去查找sys.path列表中的目录,看目录中是否有。
import sys from pprint import pprint pprint(sys.path)
输出结果:
['D:\\CodeHub\\LearnPython', 'D:\\CodeHub\\LearnPython', 'D:\\ProgramFiles\\JetBrains\\PyCharm' '2020.1.1\\plugins\\python\\helpers\\pycharm_display', 'D:\\ProgramFiles\\Python37\\python37.zip', 'D:\\ProgramFiles\\Python37\\DLLs', 'D:\\ProgramFiles\\Python37\\lib', 'D:\\ProgramFiles\\Python37', 'D:\\CodeHub\\LearnPython\\venv', 'D:\\CodeHub\\LearnPython\\venv\\lib\\site-packages', 'D:\\ProgramFiles\\JetBrains\\PyCharm' '2020.1.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
sys.path的初始值来自于:
- 运行脚本所在的目录(如果打开的是交互式解释器则是当前目录)
- PYTHONPATH环境变量(类似于PATH变量,也是一组目录名组成)
- Python安装时的默认设置
当然,这个sys.path是可以修改的。注意,如果当前目录包含有和标准库同名的模块,会直接使用当前目录的模块而不是标准模块。
如果不想修改sys.path的同时又想扩展搜索路径,可以使用.pth文件。首先该文件内容很简单,只需要补充你要导入的库的路径(绝对路径),一行一个;然后将该文件放到特定的位置,Python在加载模块时,就会读取.pth文件中的路径。
这个特定位置可以通过site模块的getsitepackages方法得到:
import site from pprint import pprint pprint(site.getsitepackages())
不同的平台返回的结果不同,其结果是一个路径列表,在Windows下,该位置一般是对应环境(或虚拟环境)的site-packages目录。
import语句机制概览
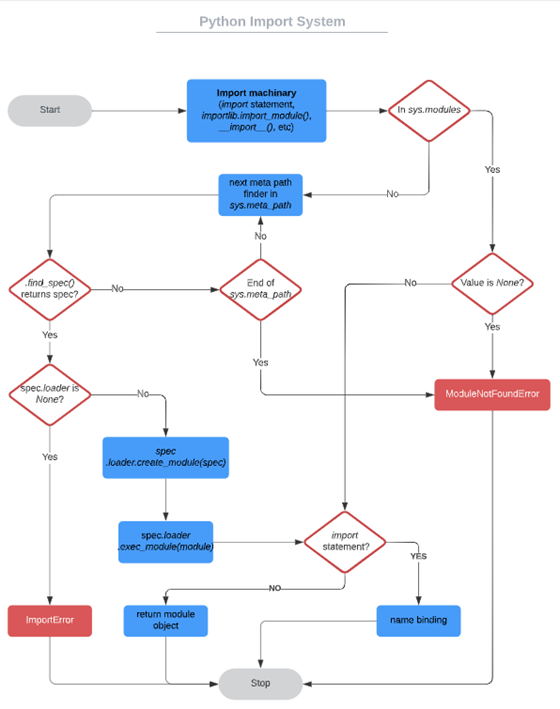
下面的代码简要说明了import加载部分的过程:
module = None
if spec.loader is not None and hasattr(spec.loader, 'create_module'):
# It is assumed 'exec_module' will also be defined on the loader.
# 假定loader中已经定义了`exec_module`模块
module = spec.loader.create_module(spec)
if module is None:
module = ModuleType(spec.name)
# The import-related module attributes get set here:
# 和模块导入相关联的属性在这个初始化方法中被设置
_init_module_attrs(spec, module)
if spec.loader is None:
if spec.submodule_search_locations is not None:
# namespace package
# 倘若这个模块是命名空间包
sys.modules[spec.name] = module
else:
# unsupported
# 不支持命名空间包
raise ImportError
elif not hasattr(spec.loader, 'exec_module'):
module = spec.loader.load_module(spec.name)
# Set __loader__ and __package__ if missing.
# 如果缺失`__loader__`和`__package__`属性则要补充
else:
sys.modules[spec.name] = module
try:
spec.loader.exec_module(module)
except BaseException:
try:
del sys.modules[spec.name]
except KeyError:
pass
raise
return sys.modules[spec.name]
以下是一些细节:
- 在loader执行exec_module之前,需要将模块缓存在modules:因为模块可能会导入自身,这样做可以防止无限递归(最坏情况)或多次加载(最好情况)。
- 如果加载失败,那么失败的模块会从modules 中被移除。任何已经存在的模块或者依赖但成功加载的模块都会保留——这和重载不一样,后者即使加载失败也会保留失败的模块在sys.modules 中。
模块的执行是加载的关键步骤,它负责填充模块的命名空间。模块执行将会全权委托给 loader,由 loader 决定如何填充和填充什么。
sys.modules
import 机制被触发时,Python 首先会去 sys.modules 中查找该模块是否已经被引入过,如果该模块已经被引入了,就直接调用它,否则再进行下一步。这里 sys.modules 可以看做是一个缓存容器。
import sys from pprint import pprint pprint(sys.modules)
输出结果:
{'__main__': <module '__main__' from 'D:/CodeHub/LearnPython/test.py'>,
'_abc': <module '_abc' (built-in)>,
'_bootlocale': <module '_bootlocale' from 'D:\\ProgramFiles\\Python37\\lib\\_bootlocale.py'>,
'_codecs': <module '_codecs' (built-in)>,
'_codecs_cn': <module '_codecs_cn' (built-in)>,
'_collections': <module '_collections' (built-in)>,
'_collections_abc': <module '_collections_abc' from 'D:\\ProgramFiles\\Python37\\lib\\_collections_abc.py'>,
'_frozen_importlib': <module '_frozen_importlib' (frozen)>,
'_frozen_importlib_external': <module '_frozen_importlib_external' (frozen)>,
'_functools': <module '_functools' (built-in)>,
'_heapq': <module '_heapq' (built-in)>,
'_imp': <module '_imp' (built-in)>,
'_io': <module 'io' (built-in)>,
'_locale': <module '_locale' (built-in)>,
'_multibytecodec': <module '_multibytecodec' (built-in)>,
'_operator': <module '_operator' (built-in)>,
'_signal': <module '_signal' (built-in)>,
'_sitebuiltins': <module '_sitebuiltins' from 'D:\\ProgramFiles\\Python37\\lib\\_sitebuiltins.py'>,
'_sre': <module '_sre' (built-in)>,
'_stat': <module '_stat' (built-in)>,
'_thread': <module '_thread' (built-in)>,
'_warnings': <module '_warnings' (built-in)>,
'_weakref': <module '_weakref' (built-in)>,
'abc': <module 'abc' from 'D:\\ProgramFiles\\Python37\\lib\\abc.py'>,
'builtins': <module 'builtins' (built-in)>,
'codecs': <module 'codecs' from 'D:\\ProgramFiles\\Python37\\lib\\codecs.py'>,
'collections': <module 'collections' from 'D:\\ProgramFiles\\Python37\\lib\\collections\\__init__.py'>,
'copyreg': <module 'copyreg' from 'D:\\ProgramFiles\\Python37\\lib\\copyreg.py'>,
'encodings': <module 'encodings' from 'D:\\ProgramFiles\\Python37\\lib\\encodings\\__init__.py'>,
'encodings.aliases': <module 'encodings.aliases' from 'D:\\ProgramFiles\\Python37\\lib\\encodings\\aliases.py'>,
'encodings.gbk': <module 'encodings.gbk' from 'D:\\ProgramFiles\\Python37\\lib\\encodings\\gbk.py'>,
'encodings.latin_1': <module 'encodings.latin_1' from 'D:\\ProgramFiles\\Python37\\lib\\encodings\\latin_1.py'>,
'encodings.utf_8': <module 'encodings.utf_8' from 'D:\\ProgramFiles\\Python37\\lib\\encodings\\utf_8.py'>,
'enum': <module 'enum' from 'D:\\ProgramFiles\\Python37\\lib\\enum.py'>,
'functools': <module 'functools' from 'D:\\ProgramFiles\\Python37\\lib\\functools.py'>,
'genericpath': <module 'genericpath' from 'D:\\ProgramFiles\\Python37\\lib\\genericpath.py'>,
'heapq': <module 'heapq' from 'D:\\ProgramFiles\\Python37\\lib\\heapq.py'>,
'io': <module 'io' from 'D:\\ProgramFiles\\Python37\\lib\\io.py'>,
'itertools': <module 'itertools' (built-in)>,
'keyword': <module 'keyword' from 'D:\\ProgramFiles\\Python37\\lib\\keyword.py'>,
'linecache': <module 'linecache' from 'D:\\ProgramFiles\\Python37\\lib\\linecache.py'>,
'marshal': <module 'marshal' (built-in)>,
'nt': <module 'nt' (built-in)>,
'ntpath': <module 'ntpath' from 'D:\\ProgramFiles\\Python37\\lib\\ntpath.py'>,
'operator': <module 'operator' from 'D:\\ProgramFiles\\Python37\\lib\\operator.py'>,
'os': <module 'os' from 'D:\\ProgramFiles\\Python37\\lib\\os.py'>,
'os.path': <module 'ntpath' from 'D:\\ProgramFiles\\Python37\\lib\\ntpath.py'>,
'pprint': <module 'pprint' from 'D:\\ProgramFiles\\Python37\\lib\\pprint.py'>,
're': <module 're' from 'D:\\ProgramFiles\\Python37\\lib\\re.py'>,
'reprlib': <module 'reprlib' from 'D:\\ProgramFiles\\Python37\\lib\\reprlib.py'>,
'site': <module 'site' from 'D:\\ProgramFiles\\Python37\\lib\\site.py'>,
'sitecustomize': <module 'sitecustomize' from 'D:\\ProgramFiles\\JetBrains\\PyCharm2020.1.1\\plugins\\python\\helpers\\pycharm_matplotlib_backend\\sitecustomize.py'>,
'sre_compile': <module 'sre_compile' from 'D:\\ProgramFiles\\Python37\\lib\\sre_compile.py'>,
'sre_constants': <module 'sre_constants' from 'D:\\ProgramFiles\\Python37\\lib\\sre_constants.py'>,'sre_parse': <module 'sre_parse' from 'D:\\Program Files\\Python37\\lib\\sre_parse.py'>,
'stat': <module 'stat' from 'D:\\Program Files\\Python37\\lib\\stat.py'>,
'sys': <module 'sys' (built-in)>,
'token': <module 'token' from 'D:\\Program Files\\Python37\\lib\\token.py'>,
'tokenize': <module 'tokenize' from 'D:\\Program Files\\Python37\\lib\\tokenize.py'>,
'traceback': <module 'traceback' from 'D:\\Program Files\\Python37\\lib\\traceback.py'>,
'types': <module 'types' from 'D:\\Program Files\\Python37\\lib\\types.py'>,
'winreg': <module 'winreg' (built-in)>,
'zipimport': <module 'zipimport' (built-in)>}
sys.modules 本质上是一个字典,如果之前已经导入过,其对应的值为各自的 module 对象。导入期间,如果在 sys.modules 找到对应的模块名的键,则取出其值,导入完成,如果值为 None 则抛出 ModuleNotFoundError 异常,否则就进行搜索操作。
sys.modules 是可修改的,强制赋值 None 会导致下一次导入该模块抛出 MoudleNotFoundError 异常;如果删掉该键则会让下次导入触发搜索操作。
import sys sys.modules['os'] = None import os
执行后报:
Traceback (most recent call last):
File "D:/CodeHub/LearnPython/test.py", line 4, in <module>
import os
ModuleNotFoundError: import of os halted; None in sys.modules
恢复方式为:删除 sys.modules 的键(副作用:前后导入的同名模块的 module 对象不是同一个),最好的做法应该是使用 importlib.reload() 函数。
查找器 finder 和加载器 loader
如果在 sys.modules 找到了对应的 module,并且这个 import 是由 import 语句触发的,那么下一步将对把对应的变量绑定到局部变量中。
如果在缓存中找不到模块对象,则 Python 会根据 import 协议去查找和加载该模块进来。这个协议在 PEP320 中被提出,有两个主要的组成概念:finder 和 loader。finder 的任务是确定能否根据已知的策略找到该名称的模块。同时实现了 finder 和 loader 接口的对象叫做 importer——它会在找到能够被加载的所需模块时返回自身。
在这个过程中 Python 将遍历 sys.meta_path 来寻找是否有符合条件的元路径查找器(meta path finder)。sys.meta_path 是一个存放元路径查找器的列表。它有三个默认的查找器:
- 内置模块查找器
- 冻结模块(frozen module)查找器
- 基于路径的模块查找器。
import sys from pprint import pprint pprint(sys.meta_path)
输出:
[<class '_frozen_importlib.BuiltinImporter'>, <class '_frozen_importlib.FrozenImporter'>, <class '_frozen_importlib_external.PathFinder'>]
查找器的 find_spec 方法决定了该查找器是否能处理要引入的模块并返回一个 ModeuleSpec 对象,这个对象包含了用来加载这个模块的相关信息。如果没有合适的 ModuleSpec 对象返回,那么系统将查看 sys.meta_path 的下一个元路径查找器。如果遍历 sys.meta_path 都没有找到合适的元路径查找器,将抛出 ModuleNotFoundError。引入一个不存在的模块就会发生这种情况,因为 sys.meta_path 中所有的查找器都无法处理这种情况:
import nosuchmodule
返回:
Traceback (most recent call last):
File "D:/CodeHub/LearnPython/test.py", line 1, in <module>
import nosuchmodule
ModuleNotFoundError: No module named 'nosuchmodule'
但是,如果这个手动添加一个可以处理这个模块的查找器,那么它也是可以被引入的:
import sys
from importlib.abc import MetaPathFinder
from importlib.machinery import ModuleSpec
class NoSuchModuleFinder(MetaPathFinder):
def find_spec(self, fullname, path, target=None):
return ModuleSpec('nosuchmodule', None)
sys.meta_path = [NoSuchModuleFinder()]
import nosuchmodule
执行后报:
Traceback (most recent call last):
File "D:/CodeHub/LearnPython/test.py", line 12, in <module>
import nosuchmodule
ImportError: missing loader
可以看到,当我们告诉系统如何去 find_spec 的时候,是不会抛出 ModuleNotFound 异常的。但是要成功加载一个模块,还需要加载器 loader。
加载器是 ModuleSpec 对象的一个属性,它决定了如何加载和执行一个模块。在加载器中,你完全可以决定如何来加载以及执行一个模块。这里的决定,不仅仅是加载和执行模块本身,你甚至可以修改一个模块:import sys
from types import ModuleType
from importlib.machinery import ModuleSpec
from importlib.abc import MetaPathFinder, Loader
class Module(ModuleType):
def __init__(self, name):
self.x = 1
self.name = name
class ExampleLoader(Loader):
def create_module(self, spec):
return Module(spec.name)
def exec_module(self, module):
module.y = 2
class ExampleFinder(MetaPathFinder):
def find_spec(self, fullname, path, target=None):
return ModuleSpec(‘module’, ExampleLoader())
sys.meta_path = [ExampleFinder()]
if __name__ == “__main__”:
import module
print(module.x)
print(module.y)
从上面的例子可以看到,一个加载器通常有两个重要的方法create_module和exec_module需要实现。如果实现了exec_module方法,那么create_module则是必须的。如果这个import机制是由import语句发起的,那么create_module方法返回的模块对象对应的变量将会被绑定到当前的局部变量中。如果一个模块因此成功被加载了,那么它将被缓存到sys.modules。如果这个模块再次被加载,那么sys.modules的缓存将会被直接引用。
注意在Python 3.4之前finder会直接返回loader而不是modulespec,后者实际上已经包含了loader。
import hook
为了简化,我们在上述的流程图中,并没有提到import机制的hook。实际上你可以添加一个hook来改变sys.meta_path或者sys.path,从而来改变import机制的行为。上面的例子中,我们直接修改了sys.meta_path。实际上,你也可以通过hook来实现。
import hook是用来扩展import机制的,它有两种类型:
- meta hook会在导入的最开始被调用(在查找缓存modules之后),你可以在这里重载对sys.path、frozen module甚至内置module的处理。只需要往sys.meta_path添加一个新的finder即可注册meta_hook。
- import path hook会在path(或package.__path__)处理时被调用,它们会负责处理sys.path中的条目。只需要往sys.path_hooks添加一个新的可调用对象即可注册import path hook。
import sys
from types import ModuleType
from importlib.machinery import ModuleSpec
from importlib.abc import MetaPathFinder, Loader
class Module(ModuleType):
def __init__(self, name):
self.x = 1
self.name = name
class ExampleLoader(Loader):
def create_module(self, spec):
return Module(spec.name)
def exec_module(self, module):
module.y = 2
class ExampleFinder(MetaPathFinder):
def find_spec(self, fullname, path, target=None):
return ModuleSpec('module', ExampleLoader())
def example_hook(path):
# some conditions here
return ExampleFinder()
sys.path_hooks = [example_hook]
# force to use the hook
sys.path_importer_cache.clear()
if __name__ == "__main__":
import module
print(module.x)
print(module.y)
元路径查找器(meta path finder)
元路径查找器的工作就是看是否能找到模块。这些查找器存放在sys.meta_path中以供Python遍历(当然它们也可以通过import hook返回)。每个查找器必须实现find_spec方法。如果一个查找器知道怎么处理将引入的模块,find_spec将返回一个ModuleSpec对象否则返回None。
find_spec(fullname, path, target=None)
以foo.bar.baz模块为例对find_spec进行说明
参数说明:
| 参数 | 说明 | 示例 |
| fullname | 被导入模块的完全限定名 | foo.bar.baz |
| path | 供搜索使用的路径列表,对于最顶级模块,这个值为None;对于子包,这个值为父包的__path__属性值 | foo.bar.__path__ |
| target | 用作稍后加载目标的现有模块对象,这个值仅会在重载模块时传入 | None |
对于单个导入请求可能会多次遍历meta_path,加入示例的模块都尚未被缓存,则会在每个finder(以mpf命名)上依次调用
- find_spec(“foo”, None, None)
- find_spec(“foo.bar”, foo.__path__, None)
- find_spec(“foo.bar.baz”, foo.bar.__path__, None)
Python 3.4之后finder的find_module()已被find_spec()所替代并弃用。
基于路径的查找器(path based finder)
上文已经提到过,Python默认自带了几个meta path的finder:内置模块查找器、冻结模块查找器、基于路径的查找器。这里重点聊一聊基于路径的查找器(path based finder)。它用于搜索一系列import路径,每个路径都用来查找是否有对应的模块可以加载。默认的路径查找器实现了所有在文件系统的特殊文件中查找模块的功能,这些特殊文件包括Python源文件(.py文件),Python编译后代码文件(.pyc文件),共享库文件(.so文件)。如果Python标准库中包含zipimport,那么相关的文件也可用来查找可引入的模块。
路径查找器不仅限于文件系统中的文件,它还可以上URL数据库的查询,或者其他任何可以用字符串表示的地址。你可以用上节提供的Hook来实现对同类型地址的模块查找。例如,如果你想通过URL来import模块,那么你可以写一个import hook来解析这个URL并且返回一个路径查找器。
PathBasedFinder会使用到三个变量,它们会提供给自定义导入机制的额外途径,包括:
- path
- path_hooks
- path_importer_cache
包的 __path__ 属性也会被使用。
sys.path 是一个字符串列表,提供了模块和包的搜索位置。它的条目可以来自于文件系统的目录、zip 文件或者其他潜在可以找到模块的“位置”(参考 site 模块)。
由于 PathBasedFinder 是一个 meta path finder,所以必须实现了 find_spec() 方法。导入机制会通过调用这个方法来搜索 import path(通过传入 path 参数——它是一个可遍历的字符串列表)。
在 find_spec() 内部,会迭代 path 的每个条目,并且每次都查找与条目相对应的 PathEntryFinder。但由于这个操作会很耗资源,因此 PathBasedFinder 会维持一个缓存——sys.path_importer_cache 来存放路径条目到 finder 之间的映射。那么只要条目找到过一次 finder 就不会重新再匹配。
如果缓存中没有对应路径条目的键,则会迭代 sys.path_hooks 中的每个可调用对象。这些可调用对象都接受一个 path 参数,并返回一个 PathEntryFinder 或者抛出 ImportError 异常。
如果遍历完整个 sys.path_hooks 的可调用对象都没有返回 PathEntryFinder,则 find_spec() 方法会在 sys.path_importer_cache 中存入 None 并返回 None,表示 PathBasedFinder 无法找到该模块。
大致的流程如图所示:
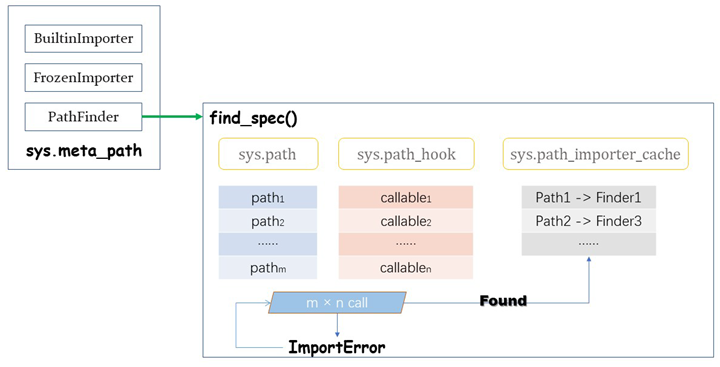
注意,路径查找器不同于元路径查找器。后者在 sys.meta_path 中用于被 Python 遍历,而前者特指基于路径的查找器。这个 finder 实际上并不知道如何进行 import,它的工作只是遍历 import path 上的每一个条目,将它们关联到某个知道如何处理特定类型路径的 path entry finder(路径条目查找器)。根据术语表,path entry finder 是由 sys.path_hook 列表中的可调用对象返回的(前提是它知道如何根据特定路径条目找到模块)。可以将 PathEntryFinder 看作 PathBasedFinder 的具体实现。实际上,如果从 sys.meta_path 中移除了 PathBasedFinder,则不会有任何 PathEntryFinder 被调用。
由于 PathEntryFinder 需要负责导入模块、初始化包以及为命名空间包构建 portion,所以也需要实现 find_spec() 方法,其形式如下:
find_spec(fullname, target=None)
其中:
- fullname: 模块的完全限定名
- target:可选的目标模块
Python 3.4 之后 find_spec() 替代了 find_loader() 和 find_module(),后两者已被弃用。
注意,如果该模块是命名空间包的 portion,为了向导入机制说明,PathEntryFinder 会将返回的 spec 对象中的 loader 设为 None 并将 submodule_search_locations 设置为包含这个 portion 的列表。
modulespec 对象
每个元路径查找器必须实现 find_spec 方法,如果该查找器知道如果处理要引入的模块,那么这个方法将返回一个 ModuleSpec 对象。这个对象有两个属性值得一提,一个是模块的名字,而另一个则是查找器。如果一个 ModuleSpec 对象的查找器是 None,那么类似 ImportError: missing loader 的异常将会被抛出。查找器将用来创建和执行一个模块。
modulespec 主要有两个作用:
- 传递——可以在导入系统的不同组件,如 finder 和 loader 之间传递状态信息
- 模板(boilerplate)构建——导入机制可以根据 modulespec 执行模板加载操作,没有 modulespec 则 loader 需要负责完成这个工作。
modulespec 通过 module 对象的 __spec__ 属性得以公开。
import requests from pprint import pprint pprint(requests.__spec__)
返回:
ModuleSpec(name='requests', loader=<_frozen_importlib_external.SourceFileLoader object at 0x0000019BDAB12148>, origin='D:\\CodeHub\\LearnPython\\venv\\lib\\site-packages\\requests\\__init__.py', submodule_search_locations=['D:\\CodeHub\\LearnPython\\venv\\lib\\site-packages\\requests'])
loader 对象
loader 是 importlib.abc.Loader 的实例,负责提供最关键的加载功能:模块执行。它的 exec_module() 方法接受唯一一个参数——module 对象,它所有的返回值都会被忽略。
loader 必须满足以下条件:
- 如果这个 module 是一个 Python module(和内置模块以及动态加载的扩展相区分),则 loader 应该在模块的全局命名空间(__dict__)中执行模块代码。
- 如果 loader 不能执行模块,应该抛出 ImportError 异常。
Python 3.4 的两个变化:
- loader 提供 create_module() 来创建 module 对象(接受一个 modulespec object 并返回 module object)。如果返回 None,则由导入机制自行创建模块。因为 module 对象在模块执行前必须存在 modules 中。
- load_module() 方法被 exec_module() 方法替代,为了向前兼容,如果存在 load_module() 且未实现 exec_module,导入机制才会使用 load_module() 方法。
导入相关的模块属性
在 _init_module_attrs 步骤中,导入机制会根据 modulespec 填充 module 对象(这个过程发生在 loader 执行模块之前)。
| 属性 | 说明 |
| __name__ | 模块的完全限定名 |
| __loader__ | 模块加载时使用的 loader 对象,主要是用于内省 |
| __package__ | 取代 __name__ 用于处理相对导入,必须设置!当导入包时,这个值和 __name__ 相同;当导入子包时,则为其父包名;为顶级模块时,应该为空字符串 |
| __spec__ | 导入时要使用的 modulespec 对象 |
| __path__ | 如果模块为包,则必须设置!这个值为可迭代对象,如果没有进一步用途,可以为空,否则迭代结果应该为字符串 |
| __file__ | 可选值,只有内置模块可以不设置 __file__ 属性 |
| __cached__ | 为编译后字节码文件所在路径,它和 __file__ 的存在互不影响 |
在命名空间包出来之前,如果想实现命名空间包功能,一般是在包的 __init__.py 中修改其 __path__ 属性。随着 PEP 420 的引入,命名空间包已经可以不需要 __init__.py 的这种操作了。
PEP 302:新的 import hook(译文)
概要
这个PEP为了自定义Python的导入(import)机制提供了一系列新的import hook(俗称“钩子”)。和现有的 __import__ hook不同,新的hook可以注入(inject)到现有的schema中,以便更好地控制模块的查找和加载。
动机(初衷)
目前唯一可以客制化import机制的手段就是重写内置的 __import__ 函数。但是,重写 __import__ 函数会带来很多问题,例如:
- 替换掉 __import__ 需要重新实现一遍整个import机制,或者是在自定义代码之前或之后调用原始的 __import__ (来控制影响范围);
- import机制不仅语义复杂而且(在Python语言中)责任重大,影响深远
- 对于已经在modules 中的模块,它们也会调用到 __import__,这几乎是你不想发生的(而又确实发生了的),除非你是在写某些监控工具。
当你需要扩展那些使用C语言(编写的模块)的导入机制时,这种情况会变得更加糟糕:除了要hack Python的 import.c 之外,还要重新实现大量的 import.c ——目前来说几乎是不可能的。
通过 __import__ 钩子,以各种途径来扩展import机制的工具编写已经有很长的一段历史了。在标准库就包含了两个这样的工具: ihooks.py 以及 imputil.py ;但是最有名的应该是 iu.py 。因为它们是Python编写的所以用处不大;这其实是一个bootstrap问题(俗称“载入问题”)——你无法通过钩子来加载包含钩子本身的模块。所以如果你希望整个标准库都可以通过import hook加载,那么这个hook必须是用C语言编写的。
用例
本小节列出了几个依赖于import hook的实际应用例子。它们当中有大量重复的工作,如果当时有更为灵活的import hook,是可以被节省下来的。这个PEP会使得将来类似的项目更为容易地实现。
当需要加载一个以非标准方式存储的模块时,你不得不扩展import机制。示例中包括了:在归档文件中捆绑打包(bundled)的若干模块;没有存储在pyc文件中的字节码;通过网络从数据库加载的模块等等。
这个PEP的工作有部分是根据PEP 273的实现而得到启发的,后者是为了给Python提供内置的从zip格式的归档文件中导入模块的功能而提出的。尽管这个PEP作为“必须要有的功能”而得到了广泛的认可,但是其实现上还是不尽人意。首先,它花了很多时间在如何整合import.c上,同时为了区分从.zip文件中导入或者不指定从.zip文件中导入而添加了大量的代码,这不仅没有什么用,而且也没有人想要。这其实也不能归咎于PEP 273的实现——鉴于目前import.c的实现,它(PEP 273)的野心可谓举步维艰。
import hook的一个典型示例就是最终用户(end user)给应用程序打包——但这不是唯一典型的示例。分发大量源文件或者.pyc文件的做法通常都不怎么合适(更不用说要单独装Python),因此经常有这种需要:将所有需要的模块打包到一个单独的文件中。而实际上这么多年来已经实现了多种的解决方案。
最古老的一个做法是包含在Python的源代码中,例如Freeze。它将编组字节码(marshalled bytecode)放到C源码的静态对象中去。Freeze 的所谓“import hook”实际上很难连接到import.c,同时它还有好几个问题待解决。后来的解决方案包括了Fredrik Lundh的Squeeze,Gordon McMillan的Installer(它包括了上文提到的 iu.py)以及Thomas Heller的 py2exe 。MacPython本身也自带了一个工具叫做 BuildApplication。
Squeeze,Installer 以及 py2exe 所用到的都是基于 __import__ 的模式(py2exe 现在还用到了 Installer 的 iu.py 而 Squeeze 则用到了 ihooks.py)。而MacPython有两个特定于Mac的import hook用于硬链接到 import.c ,它们有点类似于 Freeze 的hook。而这个PEP所提出的hook让我们摆脱以往需要硬编码的hook才能链接到import.c*(至少在理论上是这样——毕竟这不是一个短期的目标),同时还允许基于 __import__ 的工具摆脱它们当中大部分的*import.c 仿码。
在这个PEP的设计和实现工作开始之前,MacOS X上的一个类似于 BuildApplication 的新工具,给了该PEP作者之一——JvR,一个启发,在 imp 模块中将Python的冻结(固化)模块表(Table of frozen module)暴露出来,这其中主要的原因就是可以使用固定的import hook(避免花里胡俏的 __import__ 支持),同时还能在运行时提供一组模块。这导致了issue#642578(尽管它被大众莫名其妙地接受了——这主要还是因为似乎并没有人关心这个问题)。然而,当这个PEP得到认可时,你就会发现这是多虑的,因为它提供了一种更好、更通用的方式来做同样的事情。
合理性
当你尝试使用其他方法来实现内置的zip导入时,你会发现只需要对 import.c 做相当少量的修改就可以实现这一目标。它能够将特定于.zip文件的内容拆分为新的源文件,同时创建了一个新的通用的import hook模式——即你上面所读到的。
在早期的设计上,sys.path 实际上是允许非字符串类型的对象的。这样的对象必须要有处理import的方法。但这样做有两个缺点:
- 代码不能再假设path 中存储都都是字符串了;
- 它与PYTHONPATH 环境变量不兼容了,而这正是基于.zip导入所需要的条件。
Jython提出了一个折衷的做法:sys.path 可以接受string的子类对象,让它们充当 importer 对象。这避免了崩坏(大部分的不兼容),同时看上去也很适用于Jython(因为它通常是从.jar文件中加载模块的),但它依然被视为 ugly hack 。
这导致了一个更为复杂的方案(这大部分都出自 iu.py)——准备一个 候选列表,询问列表中的每一项,看它们是否能够处理 sys.path 的项目,直到有一个可以为止。这个所谓 候选列表 就是 sys 模块中的 sys.path_hooks 。
为每个 sys.path 项遍历 sys.path_hooks 代价过于高昂,因此遍历得到的结果会缓存到 sys 模块的另一个新对象 sys.path_importer_cache 中。实际上它就是将 sys.path 的每一项映射为一个个importer对象。
为了最小化对 import.c 的影响以及避免增加额外的开销,它并没有选择给现有的文件系统import逻辑增加任何显式的hook以及importer对象(正如 iu.py 所做的),它选择了一种简单的做法:当没有在 sys.path_hooks 中找到可以处理 sys.path 的项时,交回给内置的逻辑来处理。如果出现这种情况,将会在 sys.path_importer_cache 中存储一个 None 值,以避免重复查找。(稍后我们会进一步地为这个内置的机制添加一个真正的importer对象,但现在一个 None 足够作为兜底方案了)。
这时候问题就来了:如果importer对象不需要任何 sys.path 上的值(例如内置模块和固化模块frozen module这两类),那该怎么办?同样,Gordon有一个解决办法:iu.py 包含了一个他称为 metapath (元路径)的东西。在这个PEP的实现里,这个importer对象中的列表会先于 sys.path 被遍历。这个所谓 metapath 列表也是 sys 模块的新对象—— sys.meta_path。现在,这个列表默认为空,任何内置模块或固化模块都会在这个列表被遍历完之后导入,不过依然会先于 sys.path 的模块导入。
规范第一部分:importer对象协议
这个 PEP 会介绍一个新的协议 (protocol)—— Importer Protocol 。了解协议运行的上下文非常重要,因此在这里会简单介绍这个 import 机制的外部接口 (outer shell)。
译者注:在 Python 中,协议 一词通常与 magic method 相关联,也是 duck type(鸭子类型)的一部分。例如,迭代器协议即要求实现 __iter__ 方法;上下文管理器协议要求实现 __enter__ 和 __exit__ 方法等。
当遇到 import 语句时,解释器会在内置的命名空间中查找 __import__ 函数,然后给它传入四个参数,其中包括要导入的模块名称(可能是相对引用名称)以及当前全局命名空间 globals 的引用。
然后,内置的 __import__ 函数(即 import.c 中的 PyImport_ImportModuleEx() 方法)将检查要导入的模块是一个 package 还是 package 的子模块。如果它是 pacakge(或者是 package 的子模块),他会先尝试相对于 package(子模块的 package)进行导入(译者:相对导入)。例如,如果一个 spam 包执行 import eggs 语句,首先函数会去寻找叫 spam.eggs 的模块。如果失败,它会以绝对路径的形式继续导入:他会查找名为 eggs 的模块。
带点号的模块名的工作方式类似于:如果 spam 包执行 import eggs.bacon (同时 spam.eggs 是存在的而且它也是一个包),那么函数会尝试寻找 spam.eggs.bacon 这个模块。如果失败,则尝试 eggs.bacon 模块(这里省略了大量细节,不过这与 importer 协议的实现没有关系)。
让我们更加深入理解这个机制:带点号的模块名导入行为会根据其组件 (components) 进行分割;例如 import spam.ham,函数会先执行 import spam,只有成功执行之后才会将 ham 作为 spam 的子模块进行导入。
importer 协议作用在单个引入 (individual import) 上:如果 importer 得到了 spam.ham 的导入请求,那么 spam 必须是已经被导入了的。
这个协议包括两个对象:一个 finder 以及一个 loader。
finder 对象只有一个方法:
finder.find_module(fullname, path=None)
需要通过模块的 完全限定名 (fully qualified name)来调用。如果已经在 sys.meta_path 安装了这个 finder ,它将接收第二个参数 path ——对于顶层模块这个参数为 None,对于子模块或者子包来说这个值是 package.__path__。如果找到模块,那么它将返回一个 loader 对象,否则返回 None。如果 finder 的 find_module() 方法抛出异常,这个异常将会传递给调用者并终止 import。
loader 同样也只有一个方法:
loader.load_module(fullname)
此方法返回已加载的模块或抛出异常。如果一个现有的异常没有传递出去,较好的做法是提示 ImportError :如果 load_module 加载不到所要求的模块,则抛出 ImportError 。
很多情况下 finder 和 loader 可以是同一个 i 对象:即 finder.find_module() 返回 self 。
两个方法的 fullname 参数都是模块的完全限定名,例如 spam.eggs.ham 。如上所述,当 finder.find_module(“spam.eggs.ham”) 被调用时,spam.eggs 要求已经被导入同时存在于 sys.modules 列表中。但是在实际的导入中 find_module() 方法不一定会被调用:像一些元工具(如 freeze、Installer 和 py2exe)会分析导入的依赖关系而不会真正导入模块。因此 finder 不能依赖于“父 package 已经存在于 sys.modules”这种想法。
load_module() 方法在执行任何代码之前都必须要做一些工作:
- 如果 modules 中存在跟 fullname 命名一致的模块,loader 必须使用这个现有的模块(否则,内置 reload() 就不能正常工作)。如果 sys.modules 没有找到 fullname 命名的模块,loader 必须创建一个新的 module 对象并添加到 sys.modules 中去。
- 请注意,在 loader 执行模块代码之前,module 对象必须已经在 modules 中。这至关重要——因为模块代码可能(直接或间接地)import 它本身。首先将其添加到 sys.modules 可以防止发生无限递归(在最坏情况下)以及多次加载(在最好情况下)。
- 如果加载失败,loader 需要移除那些可能已经插入到 modules 的模块。如果模块是之前已经加载到 sys.modules 中的,那就不用管。
- 必须设置 __file__ 属性。它必须是一个字符串,但它可以是一个虚拟值 (dummy value),例如 <fronze> 。只有内置模块可以有这种不设置 __file__ 属性的特权。
- 必须设置 __name__ 属性。如果是通过 new_module() 创建的那么这个属性就会被自动设置。
- 如果它是一个 package,那么 __path__ 变量必须设置。它必须是一个 list,但可以为空——如果 __path__ 对 importer 没什么意义(这会在后面详细介绍)。
- loader 对象必须包含 __loader__ 属性。这主要是用于内省 (introspection) 和重载 (reload)。但它们也可以被用于特定的导入扩展,例如通过 importer 获取数据。
- __package__ 对象必须设置。
如果这个模块是一个 Python 模块(而不是内置模块或者是动态加载的扩展),他应该在模块的全局命名空间 (module.__dict__) 中执行模块代码。
这里有一个符合上述要求的轻量级的 load_module() 方法:
# Consider using importlib.util.module_for_loader() to handle
# most of these details for you
# 建议使用 importlib.util.module_for_loader 来处理其中的细节
def load_module(self, fullname):
code = self.get_code(fullname)
ispkg = self.is_package(fullname)
mod = sys.modules.setdefault(fullname, imp.new_module(fullname))
mod.__file__ = "<%s>" % self.__class__.__name__
mod.__loader__ = self
if ispkg:
mod.__path__ = []
mod.__package__ = fullname
else:
mod.__package__ = fullname.rpartition('.')[0]
exec(code, mod.__dict__)
return mod
规范第二部分:注册 hook
这里有两种类型的 import hook:Meta hook 以及 Path hook。Meta hook 会在 import 处理过程开头被调用,也就是说,它会比其他导入处理更早被处理(所以 meta hook 可以覆盖 sys.path 的处理,甚至是 frozen module 以及内置 module)。要注册 meta hook,只需要将 finder 对象添加到 sys.meta_path (即已注册的 meta hook 列表)即可。
当 sys.path (或者是 package.__path__)中相关的 path 项需要处理时,path hook 就会作为这个处理过程的一部分而被调用。添加一个 importer 的对象工厂到 sys.path_hooks 即可注册 path hook。
sys.path_hooks 是一个可调用对象列表,它会按顺序遍历其中的可调用对象,看它们中是否能够处理给定的 path 项。(如果可以)这将这个 path 项作为参数调用这个可调用对象。可调用对象如果不能处理这个 path 项,必须抛出 ImportError 异常;否则返回一个可以处理这个 path 项的 importer 对象。注意如果可调用对象返回了针对这个特定的 sys.path 条目的 importer 对象,则内置默认的 import 机制就不会再被用来处理这个条目了,即便后面这个 importer 对象处理失败也不会有任何默认机制。
这个可调用对象一般是 import hook 的类,因此会调用到类的 __init__() 方法(这也是为什么在失败时要抛出 ImportError 异常:因为 __init__() 方法不会返回任何值。当然你也可以用新式类的 __new__ 来实现这个 callable,但我们并不想强制要求针对 hook 的实现做文章)。
path hook 的检查结果将会缓存在 sys.path_importer_cache 中,这是一个字典,负责映射 path 条目和 importer 对象之间的关系。在扫描 sys.path_hooks 之前会先检查这个缓存。如果需要强制性地让 sys.path_hooks 重新扫描,那么你可能需要手动清除部分或者全部的 sys.path_importer_cache 字典。
和 sys.path 类型要求类似,这些新的 sys 变量为以下指定的类型:
- meta_path 和 sys.path_hooks 必须是 Python 列表
- path_importer_cache 必须是 Python 字典
可以适当的修改这些变量——用新的对象替换掉它们即可。
包以及 __path__ 的角色
如果一个模块包含了 __path__ 属性,根据导入机制,它将会被认为是一个包(package)。在导入包的子模块时, __path__ 变量会替代 sys.path 。sys.path 的这个规则也适用于 pkg.__path__ 。因此当遍历 pkg.__path__ 时也会查询 sys.path_hooks 。对于 Meta importer 对象而言,它们的工作不一定会用到 sys.path ,因此可能会忽略 pkg.__path__ 的值。在这种情况下,我们依然建议将其设置为空列表(而不是不设置)。
可选的 importer 协议扩展
进口商协议定义了三个可选的扩展。一是检索数据文件,二是支持模块打包工具和/或分析模块依赖关系的工具(例如 Freeze),最后是支持将模块作为脚本执行。后两类工具通常不实际加载模块,它们只需要知道它们是否可用以及在哪里可用。强烈建议通用导入器使用所有三个扩展,但如果不需要这些功能,则可以安全地将其排除在外。
为了从底层存储后端检索任意“文件”的数据,加载器对象可以提供一个名为 get_data() 的方法:
loader.get_data(path)
此方法将数据作为字符串返回,如果未找到“文件”,则引发 IOError。数据总是像使用“二进制”模式一样返回-例如,没有文本文件的 CRLF 翻译。它适用于具有一些类似文件系统的属性的导入器。’path’ 参数是一个可以通过使用 os.path.* 函数对 module.__file__ (或 pkg.__path__ 项)进行构造的路径,例如:
d = os.path.dirname(__file__) data = __loader__.get_data(os.path.join(d, "logo.gif"))
如果需要支持(例如)Freeze-like 的工具,则可以实现以下方法集。它包含三个额外的方法,为了让调用者更容易,每个方法都应该实现,或者根本不实现:
loader.is_package(fullname) loader.get_code(fullname) loader.get_source(fullname)
如果未找到模块,则所有三种方法都应引发 ImportError。
所述 loader.is_package(fullname) 方法应该返回真,如果由“全名”中指定的模块是一个包,假如果不是。
该 loader.get_code(fullname) 方法应该返回与模块,或相关的代码对象无,如果它是一个内置或扩展模块。如果加载器没有代码的对象,但它确实具有源代码,它应该返回编译源代码。(这样我们的调用者就不需要检查 get_source() 如果它只需要代码对象。)
所述 loader.get_source(fullname) 方法应该返回该模块的源代码作为字符串(使用行结尾换行符)或无如果源不可用(但它仍然应该提高的 ImportError 如果模块无法找到完全由进口商提供)。
为了支持将模块作为脚本执行,必须实现上述三种用于查找与模块关联的代码的方法。除了这些方法之外,还可以提供以下方法以允许 runpy 模块正确设置 __file__ 属性:
loader.get_filename(fullname)
如果加载了命名模块,此方法应返回 __file__ 将设置为的值。如果未找到该模块,则应引发 ImportError。
和 imp 模块的整合
新的 import hook 要集成到现有的 imp.find_module() 以及 imp.load_module() 中并不容易。我们不确定是否能在不破坏现有代码的前提下实现这个目标——因此最好的方式是为 imp 模块加一个新的函数。这意味着现有的 imp.find_module() 以及 imp.load_module() 的作用将从“暴露内置导入机制”变为“暴露基本的、未经 hook 的内置导入机制”。它们不会调用任何 import hook。一个名为 get_loader() 的新的 imp 模块函数(尽管尚未实现)将遵循以下的模式使用:
loader = imp.get_loader(fullname, path) if loader is not None: loader.load_module(fullname)
在“基本”的导入过程中,一旦使用 imp.find_module() 函数来处理,得到的 loader 对象会被包装为 imp.find_module() 函数的输出,然后 loader.load_module() 函数会带着这个输出调用 imp.load_module() 函数。
注意,这个包装器尚未实现,尽管在 test_importhooks.py 脚本中已经存在了包含这个补丁的一个 Python 原型(即 ImpWrapper 类)。
实现
PEP 302 已经在 Python 2.3a1 版本中被实现。早期的版本可以参加issue #652586的补丁来实现这个 PEP。但更为有意思的是,这个 issue 包含了相当详细的开发和设计历史。
PEP 273 已经通过 PEP 302 的 import hook 得到了实现。
资源导入 Resource Imports
有时您会拥有依赖于数据文件或其他资源的代码。在小脚本中,这不是问题——您可以指定数据文件的路径并继续!但是,如果资源文件对您的包很重要,并且您想将您的包分发给其他用户,那么会出现一些挑战:
- 您将无法控制资源的路径,因为这取决于您用户的设置以及包的分发和安装方式。您可以尝试根据您的包 __file__ 或 __path__ 属性找出资源路径,但这可能并不总是按预期工作。
您的包可能位于 ZIP 文件或旧 .egg 文件中,在这种情况下,资源甚至不会是用户系统上的物理文件。
已经有多种尝试来解决这些挑战,包括 setuptools.pkg_resources。然而,随着 Python 3.7 importlib.resources 标准库中的引入,现在有了一种处理资源文件的标准方式。
importlib.resources 简介
importlib.resources 允许访问包内的资源。在这种情况下,资源是位于可导入包中的任何文件。该文件可能对应也可能不对应于文件系统上的物理文件。这有几个优点。通过重用导入系统,您可以获得更一致的方式来处理包中的文件。它还使您可以更轻松地访问其他包中的资源文件。如果您可以导入包,则可以访问该包中的资源。
importlib.resources 成为 Python 3.7 标准库的一部分。但是,在旧版本的 Python 上,可通过安装 importlib_resources 安装。
使用时有一个要求 importlib.resources:您的资源文件必须在常规包中可用。不支持命名空间包。实际上,这意味着文件必须位于包含 __init__.py 文件的目录中。
作为第一个示例,假设您在一个包中有资源,如下所示:
books/ │ ├── __init__.py ├── alice_in_wonderland.png └── alice_in_wonderland.txt
__init__.py 只是一个需要指定 books 为常规包的空文件。
您可以分别使用 open_text() 和 open_binary() 打开文本和二进制文件:
from importlib import resources
with resources.open_text("books", "alice_in_wonderland.txt") as fid:
alice = fid.readlines()
print("".join(alice[:7]))
with resources.open_binary("books", "alice_in_wonderland.png") as fid:
cover = fid.read()
print(cover[:8])
open_text() 和 open_binary() 等同于内置 open() 与所述 mode 参数集 rt 和 rb 分别。直接读取文本或二进制文件的便捷功能也可用作 read_text() 和 read_binary()。
要在较旧的 Python 版本上可以使用以下方法导入:
try:
from importlib import resources
except ImportError:
import importlib_resources as resources
Import Tips and Tricks
处理跨 Python 版本的包
有时您需要根据 Python 版本处理具有不同名称的包。只要包的不同版本兼容,您就可以通过将包重命名为 as:
try:
from importlib import resources
except ImportError:
import importlib_resources as resources
在剩下的代码中,您可以参考 resources 而不用担心您使用的是 importlib.resources 或 importlib_resources。
通常,最容易使用 try…except 语句来确定要使用的版本。另一种选择是检查 Python 解释器的版本。但是,如果您需要更新版本号,这可能会增加一些维护成本。
import sys
if sys.version_info >= (3, 7):
from importlib import resources
else:
import importlib_resources as resources
处理丢失的包:使用替代方法
假设有一个包的兼容重新实现。重新实现得到了更好的优化,因此您希望在可用时使用它。但是,原始软件包更容易获得,并且还提供可接受的性能。
一个这样的例子是 quicktions,它是 fractions 来自标准库的优化版本。您可以像之前处理不同包名称一样处理这些首选项:
try:
from quicktions import Fraction
except ImportError:
from fractions import Fraction
另一个类似的例子是 UltraJSON 包,这是一个超快的 JSON 编码器和解码器,可用作 json 标准库中的替代品:
try:
import ujson as json
except ImportError:
import json
通过重命名 ujson 为 json,您不必担心实际导入了哪个包。
参考链接:


