在使用开源的大语言模型或者调用大语言模型API的时候会遇到temperature、top_p、top_k等参数,对于不了解的LLM的原理的人,可能一头雾水,不知道如何设置。

LLM的原理
LLM看似很神奇,但本质还是一个概率问题,神经网络根据输入的文本,从预训练的模型里面生成一堆候选词,选择概率高的作为输出,上面这三个参数,都是跟采样有关(也就是要如何从候选词里选择输出)。
更多参考:自然语言处理之GPT
Temperature
在大模型中,Temperature(温度参数)是控制生成结果多样性和随机性的关键超参数,尤其在文本生成任务中(如GPT、LLaMA等模型)。
Temperature作用于模型的输出层(softmax层),通过调整logits(模型输出的原始分数)的概率分布来控制采样策略。
adjusted_logits = logits / temperature probabilities = softmax(adjusted_logits)
- 当T=1:概率分布保持原样,忠实反映模型的置信度
- 当T→0:概率分布趋向于脉冲函数(只有最高概率token被选中)
- 当T>1:概率分布趋向均匀分布,增加不确定性
具体公式为:
$$P_{\text{temp}}(x_i)=\frac{\exp(z_i/T)}{\sum_j\exp(z_j/T)}$$
- $z_i$:模型对第i个词的原始logit值。
- T:温度参数(T>0)。

Temperature使用softmax的原因可以总结如下:
- 规范化概率分布:Softmax函数将Temperature缩放后的对数概率转换为有效的概率分布,确保所有概率之和为1。
- 平滑概率分布:Softmax函数能够根据Temperature的不同,平滑或集中概率分布,实现对生成文本多样性的调控。
- 数学推导支持:通过数学公式,Softmax确保了缩放后的对数概率被正确转换为概率分布。
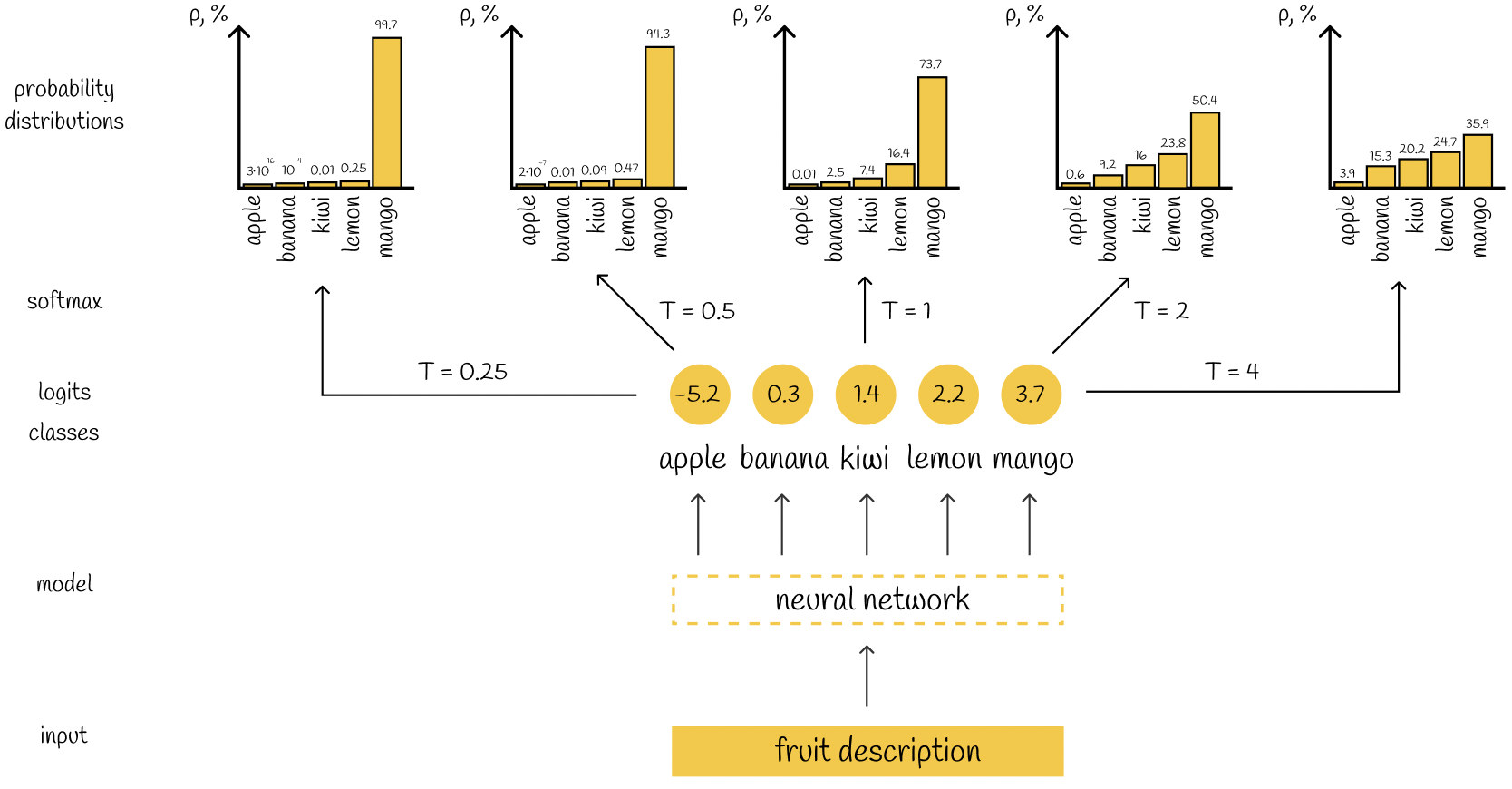
因此,Temperature使用softmax是为了规范化和调整概率分布,从而控制生成文本的多样性和确定性。
在大语言模型中,Temperature参数通过调整生成的概率分布,影响生成文本的随机性和多样性。尽管经过softmax处理后,概率值的相对大小关系保持不变,但Temperature的调整改变了这些概率的绝对值分布。当Temperature增高时,原本高概率的词的概率被降低,而低概率词的概率相对提升。这使得模型在生成时,更倾向于选择多样化的词汇,从而增加了生成文本的随机性。具体来说:
- 概率分布的变化:Temperature调整后,高概率词的概率减少,低概率词的概率增加,导致概率分布更加均匀。
- 生成时的选择多样性:在采样过程中,模型更有可能选择概率较低的词,增加了生成内容的多样性和随机性。
- 实际生成的影响:尽管相对概率顺序不变,但绝对概率的调整使得模型在选择词时有更多的可能性,从而提升了生成文本的多样性和创造性。
然而,这里似乎有一个矛盾:如果概率值的相对大小关系没有改变,为什么会选择低概率的词更多次呢?这可能是因为在实际生成过程中,模型通常会选择概率最高的几个词,而Temperature的调整会影响这些词的概率分布,使得原本概率较低的词在高Temperature下有更高的概率被选择。
为了验证这个理解,我需要考虑一个具体的例子。假设在模型的原始概率分布下,三个词的概率分别为0.7、0.2、0.1。当Temperature增加时,这些概率会被缩放并重新归一化,导致高概率词的概率降低,低概率词的概率相对提高。例如,在Temperature=2时,概率可能变为0.4、0.3、0.3。此时,模型在选择词时,虽然最高概率的词还是第一个词,但由于概率降低,模型可能会有更高的概率选择第二个或第三个词,从而增加了生成文本的多样性。因此,Temperature通过调整概率分布的“平滑”程度,影响了模型在选择词时的多样性。即使概率值的相对大小关系没有改变,绝对值的变化使得模型在生成时有更多的选择空间,从而增加了随机性。
此外,我还需要考虑生成过程的随机性。在实际生成过程中,模型通常会根据概率分布进行采样。即使在相同的概率分布下,采样结果也会因为随机性而有所不同。Temperature的调整会影响采样的概率分布,使得在高Temperature下,模型更倾向于选择多样化的词,从而生成更随机的文本。
综上所述,Temperature通过调整概率分布的“平滑”程度,尽管保持了相对概率顺序,却通过改变绝对概率值,使得生成过程更加多样化和随机。
如何选择Temperature
不同任务推荐的Temperature范围:
| 温度范围 | 生成特征 | 典型应用场景 |
| T=0.0~0.3 | 确定性输出,高度保守 | QA问答、代码生成、法律文书 |
| T=0.3~0.7 | 适度多样性,逻辑连贯 | 技术文档写作、邮件起草 |
| T=0.7~1.2 | 创造性增强 | 广告文案、诗歌创作、头脑风暴 |
| T>1.5 | 高风险随机,可能语义断裂 | 实验性艺术创作 |
极端情况
- Temperature=1.0→正常Softmax采样,不做额外调整
- Temperature→0→近似“贪心搜索”,总是选取概率最高的词
- Temperature→∞→近似均匀分布,等概率随机选择
top_k&top_p
这俩也是采样参数,跟 temperature 不一样的采样方式。
前面有介绍到,模型在输出之前,会生成一堆 token,这些 token 根据质量高低排名。
比如下面这个图片,输入 The name of that country is the 这句话,模型生成了一堆 token,然后根据不同的 decoding strategy 从 tokens 中选择输出。
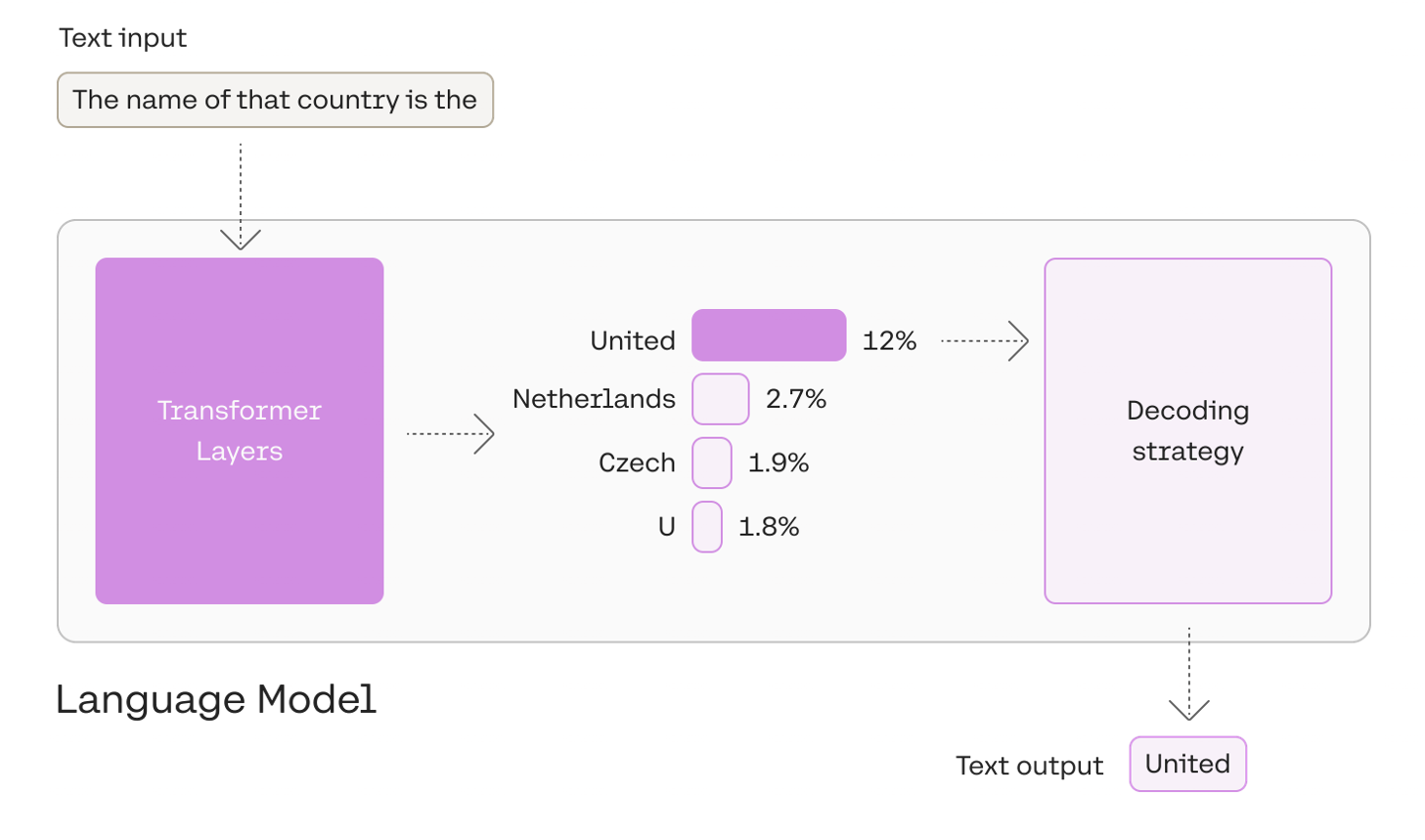
这里的 decoding strategy 可以选择
- greedy decoding: 总是选择最高分的 token,有用但是有些弊端,详见下文
- top-k: 从 tokens 里选择 k 个作为候选,然后根据它们的 likelihood scores 来采样
- top-p: 候选词列表是动态的,从 tokens 里按百分比选择候选词
top-k 与 top-p 为选择 token 引入了随机性,让其他高分的 token 有被选择的机会,不像 greedy decoding 一样总是选最高分的。
greedy decoding
好处是简单,坏处是容易生成循环、重复的内容
top-k
Top-K 采样是一种在生成模型中常用的技术,用于限制模型在每一步生成时只考虑概率最高的前 K 个词。具体来说,模型在生成下一个词时,会计算出所有可能词的概率分布,然后只选择概率最高的前 K 个词作为候选词,再在这 K 个词中按照其概率分布进行采样。

工作原理:
- 计算概率分布:模型首先计算出所有词的概率分布。
- 选择前 K 个词:从概率分布中选择概率最高的前 K 个词。
- 归一化概率:对这 K 个词的概率进行归一化,确保它们的概率之和为 1。
- 随机采样:根据归一化后的概率,从这 K 个词中随机选择一个作为下一个生成的词。
优点:
- 提高生成质量:通过限制选择范围,只选择概率较高的词,可以减少模型选择低概率但不合适词的概率,从而提高生成文本的质量。
- 降低计算复杂度:只需要考虑前 K 个词,可以减少计算量,提高生成速度。
缺点:
- 限制生成多样性:如果 K 值过小,可能会限制生成的多样性,导致生成内容过于单调和重复。
- 需要选择合适的 K 值:K 值的选择对生成结果有显著影响,选择不当可能会影响生成效果。
适用场景:
- 高质量文本生成:在需要生成高质量、准确性要求高的文本时,如新闻报道、学术论文等,较小的 K 值可以帮助提高生成的准确性。
- 减少噪声:在模型训练数据中可能存在一些噪声词,Top-K 采样可以有效过滤这些噪声词,提高生成的可靠性。
top-p
Top-P 采样也称为核采样,是一种动态选择候选词的方法。具体来说,模型在生成时,会累积地计算词的概率,直到累积概率达到或超过给定的阈值 P,然后在这些累积概率达到 P 的词中进行采样。
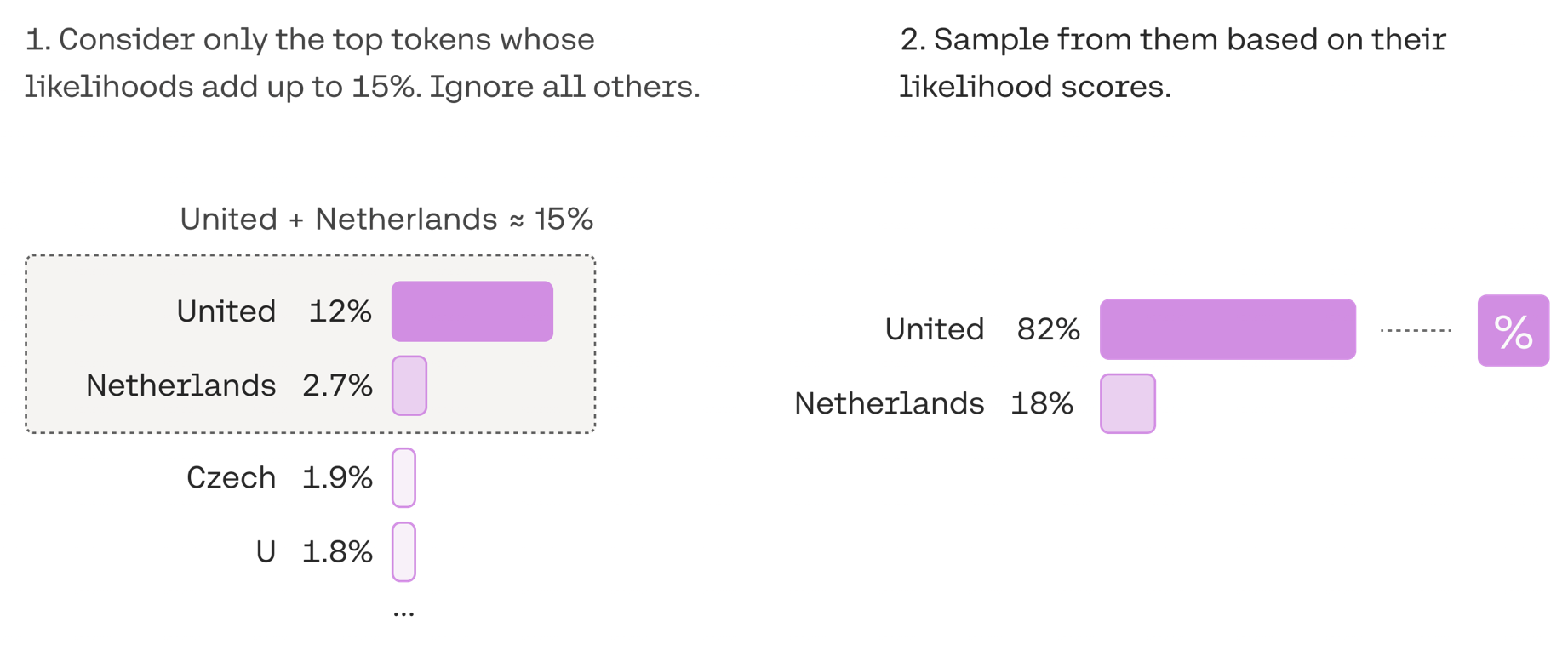
示例:将 top-p 设定为 0.15,即选择前 15% 概率的 tokens 作为候选。如下图所示,United 和 Netherlands 的概率加起来为 15%,所以候选词就是这俩,最后再从这些候选词里,根据概率分数,选择 united 这个词。
工作原理:
- 计算概率分布:模型首先计算出所有词的概率分布。
- 累积概率:从概率最高的词开始,逐步累积其概率,直到累积概率达到或超过给定的阈值 P。
- 选择候选词:所有累积概率达到或超过 P 的词作为候选词。
- 归一化概率:对这些候选词的概率进行归一化,确保它们的概率之和为 1。
- 随机采样:根据归一化后的概率,从候选词中随机选择一个作为下一个生成的词。
优点:
- 更灵活:Top-P 采样根据概率分布动态调整候选词的数量,既可以包括较多的词,也可以包括较少的词,具体取决于概率分布的情况。
- 平衡多样性和质量:通过动态调整候选词的数量,可以在保持一定多样性的同时,提高生成的质量。
缺点:
- 计算复杂度较高:需要计算累积概率,直到达到阈值 P,这可能增加计算量。
- 需要选择合适的 P 值:P 值的选择对生成结果有显著影响,选择不当可能会影响生成效果。
适用场景:
- 创意写作:在需要生成多样化和创造性的文本时,如诗歌、小说等,Top-P 采样可以帮助模型选择更多的候选词,增加生成的多样性。
- 对话系统:在对话系统中,Top-P 采样可以帮助模型生成更自然、更具多样性的回复,避免回复过于机械和单调。
Top-K 与 Top-P 的比较
| 特性 | Top-K 采样 | Top-P 采样 |
| 选择标准 | 固定选择前 K 个词 | 动态选择累积概率达到 P 的词 |
| 灵活性 | 较低,需要手动设置 K 值 | 较高,动态调整候选词数量 |
| 计算复杂度 | 较低,只需要计算前 K 个词的概率 | 较高,需要累积概率直到达到 P |
| 生成多样性 | 可能限制生成多样性,尤其是 K 值较小时 | 更好地平衡多样性和质量 |
| 适用场景 | 高质量文本生成、减少噪声 | 创意写作、对话系统 |
在实际应用中,Top-K 和 Top-P 采样可以结合使用,以发挥各自的优势。例如,先使用 Top-K 采样筛选出前 K 个词,再在这 K 个词中使用 Top-P 采样进一步筛选,确保候选词的数量和质量都符合要求。这种方法可以在保持生成多样性的同时,提高生成的质量和准确性。
选择合适的参数值
选择合适的 K 值和 P 值对生成结果有显著影响,通常需要根据具体的任务和需求进行实验和调整。以下是一些通用的指导原则:
- Top-K 采样:
- 在需要高质量、准确性要求高的任务中,选择较小的 K 值(如 K=10 到 K=50)。
- 在需要较高多样性的任务中,选择较大的 K 值(如 K=100 到 K=200)。
- Top-P 采样:
- 在需要平衡多样性和质量的任务中,选择中等的 P 值(如 P=0.3 到 P=0.7)。
- 在需要更高多样性的任务中,选择较大的 P 值(如 P=0.7 到 P=0.9)。
- 在需要更高质量的任务中,选择较小的 P 值(如 P=0.1 到 P=0.3)。
实际应用中的案例
- 聊天机器人:使用 Top-P 采样以生成更自然、多样化的回复,选择 P 值为 7。
- 新闻报道生成:使用 Top-K 采样,选择 K 值为 50,以确保生成的准确性和质量。
- 诗歌创作:结合使用 Top-K 和 Top-P 采样,先选择 K=100,再在这 100 个词中选择 P=0.5,以增加创作的多样性和艺术性。
LLM 的其他参数
max_tokens
在大语言模型中,max_tokens(最大令牌数)是一个关键参数,用于控制生成文本的长度。它指定了模型在生成过程中可以输出的最大令牌(token)数量。
令牌(token)是模型用来表示自然语言文本的基本单位,可以直观的理解为“字”或“词”;通常1个中文词语、1个英文单词、1个数字或1个符号计为1个token。
一般情况下模型中token和字数的换算比例大致如下:
- 1个英文字符≈3个token。
- 1个中文字符≈6个token。
但因为不同模型的分词不同,所以换算比例也存在差异,每一次实际处理token数量以模型返回为准,您可以从返回结果的 usage 中查看。
max_tokens是一个整数参数,表示模型在一次生成过程中可以输出的最大令牌数。max_tokens的主要作用是限制生成文本的长度,防止模型生成过长的内容,同时确保生成的文本符合用户的需求。
- 防止过长生成:模型可能会进入无限循环或生成无意义的内容,如果不限制生成长度,可能会浪费计算资源。
- 控制生成的规模:通过设置合适的max_tokens,可以让模型生成适当长度的文本,避免内容过于冗长或过于简短。


