在分析特征间相关性时,常使用的方法是pandas.DataFrame.corr:
DataFrame.corr(self, method=’pearson’, min_periods=1)
其中包含的方法主要为:
- pearson:Pearson相关系数
- kendall:Kendall秩相关系数
- Spearman:Spearman等级相关系数
Pearson相关系数
在统计学中,皮尔逊相关系数相关系数(英语:Pearson product-moment correlation coefficient,又称作 PPMCC 或 PCCs, 用 r 表示)用于度量两个变量 X 和 Y 之间的相关(线性相关),其值介于 -1 与 1 之间。-1 表示完全的负相关(这个变量下降,那个就会上升),+1 表示完全的正相关,0 表示没有线性相关。通常情况下通过以下相关系数取值范围判断变量的相关强度:
- 0.8-1.0 极强相关
- 0.6-0.8 强相关
- 0.4-0.6 中等程度相关
- 0.2-0.4 弱相关
- 0.0-0.2 极弱相关或无相关
该相关系数是判断两组数据与某一直线拟合程度的一种度量,对应的公式比欧几里得距离计算公式要复杂,但是他在数据不是很规范(normalized)的时候,会倾向于给出更好的结果。
皮尔逊相关系数的定义
两个变量之间的皮尔逊相关系数定义为两个变量之间的协方差和标准差的商:
$$\rho_{X,Y}=\frac{cov(X,Y)}{\sigma_X\sigma_Y}=\frac{E[(X-\mu_X)(Y-\mu_Y)]}{\sigma_X\sigma_Y}$$
协方差是一个反映两个随机变量相关程度的指标,如果一个变量跟随着另一个变量同时变大或者变小,那么这两个变量的协方差就是正值,反之相反。虽然协方差能反映两个随机变量的相关程度(协方差大于 0 的时候表示两者正相关,小于 0 的时候表示两者负相关),但是协方差值的大小并不能很好地度量两个随机变量的关联程度,其值大小与两个变量的量纲有关,不适于比较。为了更好的度量两个随机变量的相关程度,Pearson 相关系数其在协方差的基础上除以了两个随机变量的标准差。相关系数 ρ 相当于协方差的“标准化”,消除了量纲的影响。
上式定义了总体相关系数,常用希腊小写字母 ρ (rho) 作为代表符号。估算样本的协方差和标准差,可得到样本相关系数(样本皮尔逊系数),常用英文小写字母 r 代表:
$$r=\frac{\sum_{i=1}^{n}{(X_i-\overline X)(Y_i-\overline Y)}}{\sqrt{\sum_{i=1}^{n}{(X_i-\overline X)^2}}\sqrt{\sum_{i=1}^{n}{(Y_i-\overline Y)^2}}}$$
r 亦可由 (Xi,Yi) 样本点的标准分数均值估计,得到与上式等价的表达式:
$$r=\frac{1}{n-1}\sum_{i=1}^{n}(\frac{X_i-\overline X}{\sigma_X})(\frac{Y_i-\overline Y}{\sigma_Y})$$
其中 $\frac{X_{i}-{\overline{X}}}{\sigma_{X}}$、$\overline{X}$ 及 $\sigma_{X}$ 分别是对 $X_{i}$ 样本的标准分数、样本平均值和样本标准差。
皮尔逊相关系数的数学特性
皮尔逊相关系数有一个重要的数学特性是,因两个变量的位置和尺度的变化并不会引起该系数的改变,即它该变化的不变量(由符号确定)。也就是说,我们如果把 X 移动到 a + bX 和把 Y 移动到 c + dY,其中 a、b、c 和 d 是常数,并不会改变两个变量的相关系数(该结论在总体和样本皮尔逊相关系数中都成立)。
由于 μX = E(X), σX2 = E[(X − E(X))2] = E(X2) − E2(X),Y 也类似, 并且
$$E[(X-E(X))(Y-E(Y))]=E(XY)-E(X)E(Y)$$
故相关系数也可以表示成:
$$\rho_{X,Y}={\frac{E(XY)-E(X)E(Y)}{{\sqrt{E(X^{2})-(E(X))^{2}}}~{\sqrt{E(Y^{2})-(E(Y))^{2}}}}}$$
对于样本皮尔逊相关系数:
$$r_{xy}={\frac{\sum x_{i}y_{i}-n{\bar{x}}{\bar{y}}}{(n-1)s_{x}s_{y}}}={\frac{n\sum x_{i}y_{i}-\sum x_{i}\sum y_{i}}{{\sqrt{n\sum x_{i}^{2}-(\sum x_{i})^{2}}}~{\sqrt{n\sum y_{i}^{2}-(\sum y_{i})^{2}}}}}=\frac{\sum x_i y_i-\frac{\sum x_i \sum y_i}{n}}{\sqrt{(\sum x_i^2-\frac{(\sum x_i)^2}{n})(\sum y_i^2-\frac{(\sum y_i)^2}{n})}}$$
皮尔逊相关系数的适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
- 两个变量之间是线性关系,都是连续数据。
- 两个变量的总体是正态分布,或接近正态的单峰分布。
- 两个变量的观测值是成对的,每对观测值之间相互独立。
皮尔逊相关系数的 Python 实现
def pearson(x, y):
n = len(x)
vals = range(n)
# 简单求和
sumx = sum([x[i] for i in vals])
sumy = sum([y[i] for i in vals])
# 求平方和
sumxSq = sum([x[i]**2 for i in vals])
sumySq = sum([y[i]**2 for i in vals])
# 求乘积之和
pSum = sum([x[i]*y[i] for i in vals])
# 计算皮尔逊评价值
num = pSum - (sumx * sumy / n)
den = ((sumxSq - sumx**2 / n) * (sumySq - sumy**2 / n))**0.5
if den == 0:
r = 1
else:
r = num / den
return r
皮尔逊距离
皮尔逊距离度量的是两个变量 X 和 Y,它可以根据皮尔逊系数定义成
$$d_{X,Y}=1-\rho_{X,Y}$$
我们可以发现,皮尔逊系数落在 [-1,1],而皮尔逊距离落在 [0,2]。
皮尔逊相关系数与余弦相似度和欧氏距离的关系
在数据标准化(μ=0, σ=1)后,Pearson 相关性系数、Cosine 相似度、欧氏距离的平方可认为是等价的。换句话说,如果你的数据符合正态分布或者经过了标准化处理,那么这三种度量方法输出等价,不必纠结使用哪一种。
标准化(Standardization)是一种常见的数据缩放手段,标准化后的数据均值为 0,标准差为 1。公式:
$$z(X)=\frac{X_i-\mu_X}{\sigma_X}$$
代码演示:
```python
import numpy as np
from scipy.stats import pearsonr
from scipy.spatial.distance import euclidean
from scipy.spatial.distance import cosine
from sklearn.preprocessing import StandardScaler
# 设定向量长度,均为100
n = 100
x1 = np.random.random_integers(0, 10, (n, 1))
x2 = np.random.random_integers(0, 10, (n, 1))
x3 = np.random.random_integers(0, 10, (n, 1))
p12 = 1 - pearsonr(x1, x2)[0][0]
p13 = 1 - pearsonr(x1, x3)[0][0]
p23 = 1 - pearsonr(x2, x3)[0][0]
d12 = (euclidean(x1, x2)**2)/(2*n)
d13 = (euclidean(x1, x3)**2)/(2*n)
d23 = (euclidean(x2, x3)**2)/(2*n)
c12 = cosine(x1, x2)
c13 = cosine(x1, x3)
c23 = cosine(x2, x3)
print('原始数据,没有标准化')
print('x1&x2 x2&x3 x1&x3')
print('pearson:', np.round(p12, decimals=4), np.round(p13, decimals=4),
np.round(p23, decimals=4))
print('cos:', np.round(c12, decimals=4), np.round(c13, decimals=4),
np.round(c23, decimals=4))
print('euclidean sq', np.round(d12, decimals=4), np.round(d13, decimals=4),
np.round(d23, decimals=4))
# 标准化后的数据
x1_n = StandardScaler().fit_transform(x1)
x2_n = StandardScaler().fit_transform(x2)
x3_n = StandardScaler().fit_transform(x3)
p12_n = 1 - pearsonr(x1_n, x2_n)[0][0]
p13_n = 1 - pearsonr(x1_n, x3_n)[0][0]
p23_n = 1 - pearsonr(x2_n, x3_n)[0][0]
d12_n = (euclidean(x1_n, x2_n)**2)/(2*n)
d13_n = (euclidean(x1_n, x3_n)**2)/(2*n)
d23_n = (euclidean(x2_n, x3_n)**2)/(2*n)
c12_n = cosine(x1_n, x2_n)
c13_n = cosine(x1_n, x3_n)
c23_n = cosine(x2_n, x3_n)
print('标准化后的数据:均值=0,标准差=1')
print('x1&x2 x2&x3 x1&x3')
print('pearson:', np.round(p12_n, decimals=4), np.round(p13_n, decimals=4),
np.round(p23_n, decimals=4))
print('cos:', np.round(c12_n, decimals=4), np.round(c13_n, decimals=4),
np.round(c23_n, decimals=4))
print('euclidean sq', np.round(d12_n, decimals=4), np.round(d13_n, decimals=4),
np.round(d23_n, decimals=4))
我们一般用欧氏距离(向量间的距离)来衡量向量的相似度,但欧氏距离无法考虑不同变量间取值的差异。举个例子,变量a取值范围是0至1,而变量b的取值范围是0至10000,计算欧式距离时变量b上微小的差异就会决定运算结果。而Pearson相关性系数可以看出是升级版的欧氏距离平方,因为它提供了对于变量取值范围不同的处理步骤。因此对不同变量间的取值范围没有要求(unit free),最后得到的相关性所衡量的是趋势,而不同变量量纲上差别在计算过程中去掉了,等价于z-score标准化。而未经升级的欧氏距离以及cosine相似度,对变量的取值范围是敏感的,在使用前需要进行适当的处理。例如,在低维度可以优先使用标准化后的欧式距离或者其他距离度量,在高维度时Pearson相关系数更加适合。不过说到底,这几个衡量标准差别不大,很多时候的输出结果是非常相似的。
Scipy的pearsonr方法
Scipy的pearsonr方法能够同时计算相关系数和p-value。
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)
print("Lower noise", pearsonr(x, x + np.random.normal(0, 1, size)))
print("Higher noise", pearsonr(x, x + np.random.normal(0, 10, size)))
#output:
#Lower noise (0.7182483686213842, 7.324017312997672e-49)
#Higher noise (0.05796429207933815, 0.31700993885325246)
这个例子中,我们比较了变量在加入噪音之前和之后的差异。当噪音比较小的时候,相关性很强,p-value很低。
Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。
import numpy as np from scipy.stats import pearsonr x = np.random.uniform(-1, 1, 100000) print(pearsonr(x, x**2)) #output: #(0.0020775478403054566, 0.511199686284783)
参考链接:
Kendall秩相关系数
在统计学中,肯德尔相关系数是以Maurice Kendall命名的,并经常用希腊字母τ(tau)表示其值。肯德尔相关系数是一个用来测量两个随机变量相关性的统计值。一个肯德尔检验是一个无参数假设检验,它使用计算而得的相关系数去检验两个随机变量的统计依赖性。肯德尔相关系数的取值范围在-1到1之间,当τ为1时,表示两个随机变量拥有一致的等级相关性;当τ为-1时,表示两个随机变量拥有完全相反的等级相关性;当τ为0时,表示两个随机变量是相互独立的。
假设两个随机变量分别为X、Y(也可以看做两个集合),它们的元素个数均为N,两个随机变量取的第i(1<=i<=N)个值分别用Xi、Yi表示。X与Y中的对应元素组成一个元素对集合XY,其包含的元素为(Xi,Yi)(1<=i<=N)。当集合XY中任意两个元素(Xi,Yi)与(Xj,Yj)的排行相同时(也就是说当出现情况1或2时;情况1:Xi>Xj且Yi>Yj,情况2:Xi<Xj且Yi<Yj),这两个元素就被认为是一致的。当出现情况3或4时(情况3:Xi>Xj且Yi<Yj,情况4:Xi<Xj且Yi>Yj),这两个元素被认为是不一致的。当出现情况5或6时(情况5:Xi=Xj,情况6:Yi=Yj),这两个元素既不是一致的也不是不一致的。
这里有三个公式计算肯德尔相关系数的值公式一
“`$$T_{au-a}=\frac{C-D}{\frac{1}{2}N(N-1)}$$
其中 C 表示 XY 中拥有一致性的元素对数(两个元素为一对);D 表示 XY 中拥有不一致性的元素对数。
注意:这一公式仅适用于集合 X 与 Y 中均不存在相同元素的情况(集合中各个元素唯一)。
公式二
$$T_{au-b}=\frac{C-D}{\sqrt{(N3-N1)(N3-N2)}}$$
其中:
$$N3=\frac{1}{2}N(N-1)$$
$$N1=\sum_{i=1}^{s}{\frac{1}{2}U_i(U_i-1)}$$
$$N2=\sum_{i=1}^{t}{\frac{1}{2}V_i(V_i-1)}$$
其中 C、D 与公式一中相同;N1、N2 分别是针对集合 X、Y 计算的,现在以计算 N1 为例,给出 N1 的由来(N2 的计算可以类推):将 X 中的相同元素分别组合成小集合,s 表示集合 X 中拥有的小集合数(例如 X 包含元素:1234332,那么这里得到的 s 则为 2,因为只有 2、3 有相同元素),Ui 表示第 i 个小集合所包含的元素数。N2 在集合 Y 的基础上计算而得。
注意:这一公式适用于集合 X 或 Y 中存在相同元素的情况(当然,如果 X 或 Y 中均不存在相同的元素时,公式二便等同于公式一)。
公式三:
$$T_{au-c}=\frac{C-D}{\frac{1}{2}N^2\frac{M-1}{M}}$$
注意:这一公式中没有再考虑集合 X、或 Y 中存在相同元素给最后的统计值带来的影响。公式三的这一计算形式仅适用于用表格表示的随机变量 X、Y 之间相关系数的计算。M 表示长方形表格中行数与列数中较小的一个。
原始的 Kendall 秩相关系数定义在一致对 (concordant pairs) 和分歧对 (discordant pairs) 的概念上。所谓一致对,就是两个变量取值的相对关系一致;分歧对则是指它们的相对关系不一致。这么说有点难以理解,简单的说就是将两个变量进行排序,判断两者的排序值是否一致。如果一致则为 1,如果倒叙则为 -1。Scipy 的 scipy.stats.kendalltau 提供的秩相关的检测方法:
from scipy.stats import kendalltau x1 = [12, 2, 1, 12, 2] x2 = [1, 4, 7, 1, 0] tau, p_value = kendalltau(x1, x2) print(tau, p_value) # output # -0.4714045207910316 0.2827454599327748
肯德尔相关系数与斯皮尔曼相关系数对数据条件的要求相同。针对非线性数据有一定的误差。
参考资料:
Spearman 等级相关系数
使用皮尔逊线性相关系数有 2 个局限:首先,必须假设数据是成对地从正态分布中取得的;其次,数据至少在逻辑范围内是等距的。对不服从正态分布的资料不符合使用矩相关系数来描述关联性。此时可采用秩相关(rank correlation),也称等级相关,来描述两个变量之间的关联程度与方向。斯皮尔曼秩相关系数就是其中一种。
在统计学中,斯皮尔曼等级相关系数以 Charles Spearman 命名,并经常用希腊字母 ρ(rho)表示其值。斯皮尔曼等级相关系数用来估计两个变量 X、Y 之间的相关性,其中变量间的相关性可以使用单调函数来描述。如果两个变量取值的两个集合中均不存在相同的两个元素,那么,当其中一个变量可以表示为另一个变量的很好的单调函数时(即两个变量的变化趋势相同),两个变量之间的 ρ 可以达到 +1 或 -1。
斯皮尔曼等级相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。
和最基本的相关系数一样,Spearman Rank 相关系数可以帮助我们确定两组数据是否向同一个方向移动。和相关系数不太一样的是,Spearman Rank 相关系数检验的不是数据之间的关系,而是数据排名之间的关系。这对于数据中的异常值和规模具有更强的鲁棒性。
现结合一个例子来加以说明,某工厂对工人的业务进行了一次考试,欲研究考试成绩与每月产量之间是否有联系,若随机抽选了一个样本,其考试成绩和产量数字如下表:
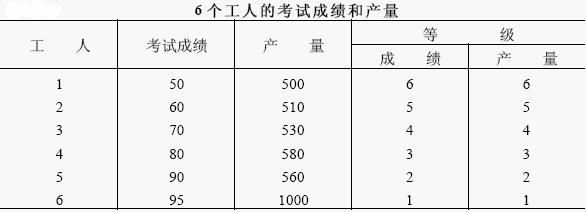
从表中的数字可以看出,工人的考试成绩愈高其产量也愈高,二者之间的联系程度是很一致的,但是皮尔逊相关系数 r=0.676 并不算太高,这是由于它们之间的关系并不是线性的,如果分别按考试成绩和产量高低变换成等级(见上表第 3、4 列),则可以计算它们之间的等级相关系数为 1。
下面我们看一看 Spearman Rank 系数如何进行计算。现在有两个数据集 X 和 Y,每个的长度是 n,两个随即变量取的第 i(1<=i<=n)个值分别用 Xi、Yi 表示。对 X、Y 进行排序(同时为升序或降序),得到两个元素排行集合 x、y,其中元素 xi、yi 分别为 Xi 在 X 中的排行以及 Yi 在 Y 中的排行。将集合 x、y 中的元素对应相减得到一个排行差分集合 d,其中 di=xi-yi,1<=i<=N。随机变量 X、Y 之间的斯皮尔曼等级相关系数可以由 x、y 或者 d 计算得到,其计算方式如下所示: $$r_{s}=1-\frac{6\sum_{i=1}^{n}d_i^2}{n(n^2-1)}$$ 斯皮尔曼等级相关系数对数据条件的要求没有皮尔逊相关系数严格,只要两个变量的观测值是成对的等级评定资料,或者是由连续变量观测资料转化得到的等级资料,不论两个变量的总体分布形态、样本容量的大小如何,都可以用斯皮尔曼等级相关系数来进行研究。对于服从 Pearson 相关系数的数据亦可计算 Spearman 相关系数,但统计效能要低一些。Pearson 相关系数的计算公式可以完全套用 Spearman 相关系数计算公式,但公式中的 x 和 y 用相应的秩次代替即可。scipy.stats.spearmanr:
Python 实现:
from scipy.stats import spearmanr x1 = [1, 2, 3, 4, 5] x2 = [5, 6, 7, 8, 7] rho, p_value = spearmanr(x1, x2) print(rho, p_value) # output # 0.8207826816681233 0.08858700531354381
相关文档:
- http://pandas.pydata.org/pandas-docs/version/0.21/generated/pandas.DataFrame.corr.html
- https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.spearmanr.html
Pearson 相关方法和 Spearman 相关方法的比较
- Pearson 相关评估两个连续变量之间的线性关系。当一个变量中的变化与另一个变量中的成比例变化相关时,这两个变量具有线性关系。
- Spearman 相关评估两个连续或顺序变量之间的单调关系。在单调关系中,变量倾向于同时变化,但不一定以恒定的速率变化。Spearman 相关系数基于每个变量的秩值(而非原始数据)Spearman 相关通常用于评估与顺序变量相关的关系。
Pearson 和 Spearman 相关系数的值介于 -1 和 +1 之间。当两个变量的上升量相同时,Pearson 相关系数为 +1。该关系会构成一条完美的直线。在本例中,Spearman 相关系数也是 +1。(Pearson=+1,Spearman=+1)

如果关系是一个变量上升,其他变量也上升,但上升量不一致,则 Pearson 相关系数为小于 +1 的正数。在本例中,Spearman 系数仍等于 +1。(Pearson=+0.851,Spearman=+1)

当存在随机关系或者不存在关系时,这两个相关系数都接近零。(Pearson=-0.093,Spearman=-0.093)

如果关系对应的是一条完美的下降关系直线,则这两个相关系数都为 -1。(Pearson=-1,Spearman=-1)

如果关系是一个变量下降,其他变量上升,但变化程度不一致,则 Pearson 相关系数为大于 -1 的负数。在本例中,Spearman 系数将仍等于 -1。(Pearson=-0.799,Spearman=-1)

其他非线性关系
Pearson 相关系数只度量线性关系。Spearman 相关系数只度量单调关系。因此,即使相关系数为 0,也可能存在有意义的关系。检查散点图可确定关系的形式。(Pearson 系数和 Spearman 系数都近似 0。)
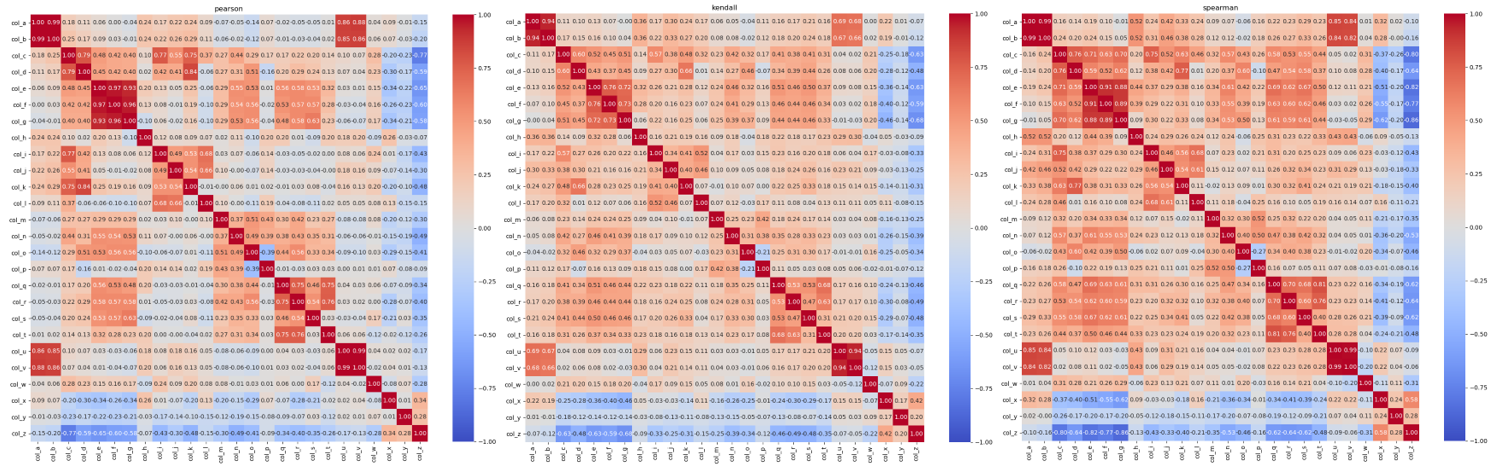
相关性检测Python实战
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_excel("data/train.xlsx")
plt.figure(figsize=(15,13))
sns.heatmap(df.corr(method="pearson"), annot=True, vmin=-1, vmax=1, cmap='coolwarm', fmt=".2f")
plt.title("pearson")
plt.savefig('corr_pearson.png')
plt.figure(figsize=(15,13))
sns.heatmap(df.corr(method="kendall"), annot=True, vmin=-1, vmax=1, cmap='coolwarm', fmt=".2f")
plt.title("kendall")
plt.savefig('corr_kendall.png')
plt.figure(figsize=(15,13))
sns.heatmap(df.corr(method="spearman"), annot=True, vmin=-1, vmax=1, cmap='coolwarm', fmt=".2f")
plt.title("spearman")
plt.savefig('corr_spearman.png')
如果觉得以上样式不够好看,可以再尝试以下代码:
from string import ascii_letters
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="white")
# Generate a large random dataset
rs = np.random.RandomState(33)
d = pd.DataFrame(data=rs.normal(size=(100,26)),
columns=list(ascii_letters[26:]))
# Compute the correlation matrix
corr = d.corr()
# Generate a mask for the upper triangle
mask = np.zeros_like(corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(11,9))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,
square=True, linewidths=.5, cbar_kws={"shrink":.5})
plt.show()