imbalanced-learn(通常简称为 imblearn)是一个专门用于处理类别不平衡数据的 Python 库。它与 Scikit-learn 兼容,提供了多种方法来解决分类任务中类别样本数量差异过大的问题。

为什么需要 imbalanced-learn?
在处理分类任务时,数据中的类别不平衡(Class Imbalance)问题广泛存在且极具挑战性。例如:
- 欺诈检测:99% 的交易是正常的,1% 是欺诈行为。
- 医学诊断:罕见病患者的样本远少于健康人群。
- 网络入侵检测:大多数流量是合法的,攻击仅占极少数。
传统机器学习模型(如逻辑回归、决策树、SVM 等)的优化目标通常是整体准确率最大化,导致模型倾向于忽略少数类,将所有样本预测为多数类。例如,若数据中 99% 是多数类,模型只需全部预测为多数类,就能达到 99% 的准确率,但这对实际问题毫无意义。
imbalanced-learn 的核心价值在于提供系统化的解决方案,直接针对类别不平衡问题调整数据或模型,而非依赖传统模型的默认行为。
传统方法的局限性
直接训练模型的缺陷
- 问题:模型偏向多数类,少数类的召回率(Recall)或精确率(Precision)极低。
- 示例:在癌症检测中,模型将所有样本预测为“健康”,虽然准确率高,但会漏诊所有真实患者。
简单策略的不足
- 调整类别权重:Scikit-learn 的class_weight 参数可为少数类分配更高权重,但仅适用于部分模型(如逻辑回归、SVM),且无法解决极端不平衡(如 1:1000)。
- 随机过采样/欠采样:手动复制少数类样本会导致过拟合,随机删除多数类样本会丢失关键信息。
imbalanced-learn 的独特优势
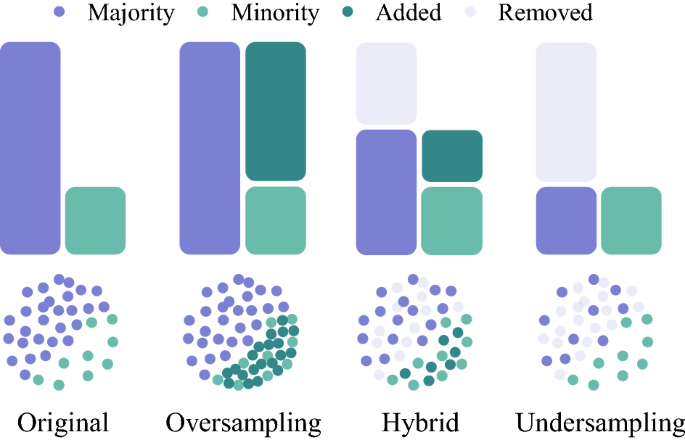
系统化的重采样技术
- 过采样(Oversampling):
- SMOTE:通过插值生成“逼真”的少数类样本,而非简单复制,缓解过拟合。
- Borderline-SMOTE:专注于在类别边界附近生成样本,强化分类边界。
- ADASYN:根据少数类样本的密度动态调整生成策略,优先覆盖难以学习的区域。
- 欠采样(Undersampling):
- Tomek Links:移除多数类中与少数类相邻的样本,简化分类边界。
- NearMiss:基于距离线路最具代表性的多数类样本,保留更多信息。
- 混合采样(Combined):
- SMOTE + Tomek Links:先过采样生成新样本,再清理噪声,平衡数据质量与数量。
集成学习与自适应算法
- Balanced Bagging:在集成过程中对每个基学习器的训练数据进行重采样,确保每轮训练的数据平衡。
- RUSBoost:结合欠采样与 AdaBoost,动态调整样本权重,提升对少数类的关注。
与 Scikit-learn 无缝兼容
管道(Pipeline)支持:
from imblearn.pipeline import Pipeline
pipeline = Pipeline([
('smote', SMOTE(sampling_strategy=0.5)), # 过采样至多数类的50%
('scaler', StandardScaler()), # 标准化
('clf', RandomForestClassifier()) # 分类器
])
确保重采样仅在训练集进行,避免验证集/测试集数据泄露。
交叉验证集成:
from imblearn.under_sampling import RandomUnderSampler
from sklearn.model_selection import cross_val_score
sampler = RandomUnderSampler()
model = LogisticRegression()
pipeline = Pipeline([('sampler', sampler), ('model', model)])
scores = cross_val_score(pipeline, X, y, cv=5) # 正确重采样流程
实际场景中的必要性
极端不平衡数据
- 示例:信用卡欺诈检测(正样本占比1%)。
- 解决方案:
- 使用SMOTE 生成欺诈样本,将其提升至 10%。
- 结合BalancedRandomForest 训练模型,每棵树仅采样部分多数类样本。
多类别不平衡
- 示例:手写数字识别,但数字“1”的样本是其他数字的 10 倍。
- 解决方案:
from imblearn.over_sampling import SMOTE
smote = SMOTE(sampling_strategy={2: 500, 4: 1000}) # 指定每个类别的目标样本数
X_res, y_res = smote.fit_resample(X, y)
高维数据与小样本
- 示例:基因数据中,某疾病的阳性样本仅 50 个,特征维度超过 1000。
- 解决方案:使用SVM-SMOTE 在高维空间生成样本,避免普通 SMOTE 因距离计算失效导致的噪声。
与其他工具的区别
| 方法 | Scikit-learn | imbalanced-learn |
| 处理类别不平衡 | 仅支持 class_weight | 提供 20+ 种重采样算法和集成模型 |
| 数据预处理流程 | 无重采样 Pipeline 支持 | 专为不平衡数据设计的 Pipeline 类 |
| 过采样技术 | 无 | SMOTE、ADASYN、KMeans-SMOTE 等 |
| 欠采样技术 | 无 | Tomek Links、NearMiss、ClusterCentroids |
| 评估指标 | 需手动计算 F1、AUC-ROC | 内置与不平衡数据兼容的评估工具 |
何时不需要 imbalanced-learn?
- 数据本身平衡(如 MNIST 数据集)。
- 少数类样本极度稀缺(如仅 5 个样本),此时重采样可能无效,需依赖数据增强或迁移学习。
imbalanced-learn的价值
imbalanced-learn 的必要性源于其对类别不平衡问题的针对性解决能力。它通过以下方式提升模型性能:
- 数据层面:调整样本分布,使模型更关注少数类。
- 算法层面:集成重采样与模型训练,避免信息丢失和过拟合。
- 流程层面:与 Scikit-learn 生态无缝集成,简化实验流程。
对于任何涉及类别不平衡的任务(如金融风控、医疗诊断、异常检测),imbalanced-learn 都是提升模型鲁棒性和实用性的关键工具。
imbalanced-learn核心功能
imbalanced-learn 的方法主要分为四类:重采样(Resampling)、集成学习(Ensemble)、混合方法(Hybrid)和数据清洗(Cleaning)。以下分别展开:
重采样(Resampling)
通过调整训练数据的类别分布,直接解决不平衡问题。
过采样(Oversampling)
- 目标:增加少数类样本数量,使其接近多数类。
- 核心方法:
- SMOTE(Synthetic Minority Over-sampling Technique)
- 原理:在少数类样本的特征空间中,随机选择两个近邻样本,并在其连线上通过线性插值生成新样本。
- 公式:对两个样本$x_i$ 和 $x_j $,生成新样本 $x_{\text{new}} = x_i + \lambda (x_j – x_i)$ ,其中 $\lambda \in [0, 1] $是随机数。
- 优势:避免简单复制样本导致的过拟合。
- 变体:
- Borderline-SMOTE:仅对靠近类别边界的少数类样本生成新样本。
- SVMSMOTE:使用 SVM 找到支持向量,沿支持向量方向生成样本。
- ADASYN(Adaptive Synthetic Sampling)
- 原理:根据少数类样本的密度动态调整生成策略,对难以学习的区域(即周围多数类样本较多的区域)生成更多样本。
- SMOTE(Synthetic Minority Over-sampling Technique)
适用于少数类样本极少的场景,通过生成新样本增加少数类多样性。
| 方法 | 原理 | 适用场景 | 优缺点 |
| SMOTE | 在特征空间插值生成新样本 | 中小规模数据,特征间线性关系较强 | 简单高效,可能生成噪声样本 |
| SMOTE-NC | 支持数值和分类特征的混合插值 | 包含分类特征的数据集 | 处理混合特征,计算复杂度较高 |
| ADASYN | 根据样本密度自适应生成更多困难样本 | 少数类分布不均匀(如存在多个子簇) | 关注分类边界,可能过拟合噪声区域 |
| Borderline-SMOTE | 仅在边界区域生成新样本 | 类别边界模糊的场景 | 提升边界清晰度,对噪声敏感 |
| KMeans-SMOTE | 先聚类再在簇内生成样本 | 高维数据或少数类存在明显子簇结构 | 减少噪声生成,依赖聚类效果 |
| SVMSMOTE | 使用 SVM 支持向量定位边界区域生成样本 | 类别边界复杂的非线性数据 | 适合复杂边界,计算成本高 |
代码示例:
from imblearn.over_sampling import SMOTE smote = SMOTE(sampling_strategy='auto', k_neighbors=5) X_resampled, y_resampled = smote.fit_resample(X, y)
欠采样(Undersampling)
- 目标:减少多数类样本数量,降低其主导地位。
- 核心方法:
- RandomUnderSampler:随机删除多数类样本。
- Tomek Links
- 原理:找到两个不同类别的最近邻样本对(称为 Tomek Link),移除其中的多数类样本,从而清晰化类别边界。
- ClusterCentroids
- 原理:对多数类样本进行 K-Means 聚类,用聚类中心替代原始样本,保留多数类的整体分布信息。
- NearMiss
- 原理:选择多数类中与少数类样本距离最近的样本(三种策略):
- NearMiss-1:保留与少数类样本平均距离最小的多数类样本。
- NearMiss-2:保留与少数类样本最远距离最小的多数类样本。
- NearMiss-3:为每个少数类样本保留固定数量的多数类近邻。
- 原理:选择多数类中与少数类样本距离最近的样本(三种策略):
适用于 多数类样本冗余 的场景,通过减少多数类样本降低计算成本。
| 方法 | 原理 | 适用场景 | 优缺点 |
| RandomUnderSampler | 随机删除多数类样本 | 快速降低数据规模,基线方法 | 可能丢失重要信息 |
| Tomek Links | 删除边界附近的多数类样本 | 清理类别边界重叠样本 | 保留全局分布,删除样本有限 |
| ENN | 删除类别与邻居不一致的样本 | 去除噪声样本 | 有效清理噪声,可能误删少数类边缘样本 |
| Repeated ENN | 多次迭代应用 ENN | 存在深层噪声或复杂分布 | 更彻底清理,但数据量可能大幅减少 |
| Cluster Centroids | 对多数类聚类后保留聚类中心 | 高维数据或多数类存在冗余子结构 | 保留代表性样本,依赖聚类效果 |
| NearMiss | 保留与少数类最近的多数类样本 | 需要保留多数类关键信息的场景 | 增强类别边界,可能引入偏差 |
代码示例:
from imblearn.under_sampling import TomekLinks tl = TomekLinks() X_resampled, y_resampled = tl.fit_resample(X, y)
混合采样(Combined Sampling)
- 原理:同时使用过采样和欠采样,避免单一方法的缺陷。
- 常用方法:
- SMOTEENN:先用 SMOTE 过采样,再用 ENN(Edited Nearest Neighbours)删除噪声样本。
- SMOTETomek:SMOTE 过采样后,用 Tomek Links 清理边界样本。
SMOTEENN 示例
原理:先用 SMOTE 过采样生成少数类样本,再用 ENN(Edited Nearest Neighbours)删除噪声样本。
import numpy as np
from sklearn.datasets import make_classification
from imblearn.combine import SMOTEENN
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# 生成不平衡数据集(多数类:1000,少数类:50)
X, y = make_classification(
n_samples=1050,
weights=[0.95],
n_classes=2,
random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 初始化 SMOTEENN
# 参数说明:
# - smote=SMOTE(sampling_strategy='auto'):过采样至多数类的 50%
# - enn=EditedNearestNeighbours():删除与邻居类别不一致的样本
smote_enn = SMOTEENN(
sampling_strategy='auto', # 目标类别平衡策略(默认自动调整)
random_state=42
)
# 应用混合采样
X_resampled, y_resampled = smote_enn.fit_resample(X_train, y_train)
# 查看采样后的类别分布
print("采样后的类别数量:", np.bincount(y_resampled))
# 输出示例:array([492, 441]) 表示多数类和少数类数量接近平衡
# 训练模型并评估
model = LogisticRegression()
model.fit(X_resampled, y_resampled)
y_pred = model.predict(X_test)
# 打印分类报告
print(classification_report(y_test, y_pred))
SMOTETomek 示例
原理:先用 SMOTE 过采样,再用 Tomek Links 清理边界模糊样本。
from imblearn.combine import SMOTETomek
# 初始化 SMOTETomek
smote_tomek = SMOTETomek(
sampling_strategy='auto', # 自动平衡至多数类的 50%
random_state=42
)
# 应用混合采样
X_resampled, y_resampled = smote_tomek.fit_resample(X_train, y_train)
# 查看采样后的类别分布
print("采样后的类别数量:", np.bincount(y_resampled))
# 输出示例:array([517, 488])
# 训练模型并评估
model = LogisticRegression()
model.fit(X_resampled, y_resampled)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
参数调优与解释
关键参数
- sampling_strategy:控制采样后的类别比例。
- ‘auto’:默认将少数类过采样至多数类的 50%。
- 字典形式:例如{0: 100, 1: 200} 指定类别 0 保留 100 个样本,类别 1 生成 200 个样本。
- smote=SMOTE()和 tomek=TomekLinks():可自定义底层方法的参数。
- 例如调整 SMOTE 的k_neighbors 或 Tomek Links 的 n_jobs。
自定义 SMOTE 和 ENN/Tomek
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import TomekLinks
# 自定义 SMOTE 和 Tomek Links
smote = SMOTE(sampling_strategy=0.5, k_neighbors=3)
tomek = TomekLinks(n_jobs=-1) # 使用所有 CPU 核心
# 组合为 SMOTETomek
smote_tomek = SMOTETomek(
smote=smote,
tomek=tomek,
sampling_strategy='auto'
)
注意事项
- 过采样风险:SMOTE 可能生成噪声样本,需通过 ENN 或 Tomek 清理。
- 类别比例控制:合理设置sampling_strategy,避免极端过采样导致模型过拟合。
- 与 Pipeline 结合:确保重采样仅在训练集进行。
from imblearn.pipeline import Pipeline
pipeline = Pipeline([
('smote_tomek', SMOTETomek()),
('classifier', LogisticRegression())
])
pipeline.fit(X_train, y_train)
效果对比
| 方法 | 适用场景 | 优点 | 缺点 |
| SMOTEENN | 数据中存在较多噪声或类别重叠 | 清理噪声后数据更干净 | ENN 可能删除有用的少数类样本 |
| SMOTETomek | 需要保留更多多数类信息的场景 | 仅清理边界样本,保留多数类分布信息 | 对高维数据效果可能下降 |
通过混合采样,既能增加少数类样本的多样性,又能清理噪声或冗余样本,是处理类别不平衡问题的实用工具。
集成方法(Ensemble Learning)
将重采样技术与集成学习结合,提升模型鲁棒性。
| 方法 | 原理 | 适用场景 | 优缺点 |
| BalancedBagging | 每轮 Bagging 对多数类欠采样 | 中小规模数据,需兼容任意基模型 | 灵活,计算效率高 |
| BalancedRandomForest | 每棵树训练时欠采样多数类 | 大规模数据,需并行训练和特征重要性分析 | 高效,支持高维数据 |
| EasyEnsemble | 将多数类划分为多个子集并分别训练 | 多数类冗余度高,需增强多样性 | 降低过拟合风险,计算成本较高 |
| RUSBoost | 欠采样 + AdaBoost 动态调整样本权重 | 需要自适应关注困难样本的场景 | 提升少数类召回率,可能过拟合噪声 |
Balanced Bagging
原理:在 Bagging 的每轮迭代中,对多数类进行欠采样,使每个子训练集的类别分布平衡,从而降低模型对多数类的偏向。
代码示例:
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, roc_auc_score
from sklearn.tree import DecisionTreeClassifier
from imblearn.ensemble import BalancedBaggingClassifier
import matplotlib.pyplot as plt
from sklearn.metrics import RocCurveDisplay
# 生成不平衡数据集(多数类:1000,少数类:100)
X, y = make_classification(
n_samples=1100,
n_classes=2,
weights=[0.9], # 90% 多数类
random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 初始化 Balanced Bagging 模型
bbc = BalancedBaggingClassifier(
base_estimator=DecisionTreeClassifier(max_depth=3), # 基模型为决策树
n_estimators=50, # 50 个子模型
sampling_strategy='auto', # 欠采样至与少数类数量相同
replacement=False, # 无放回采样
random_state=42,
n_jobs=-1 # 使用所有 CPU 核心
)
# 训练模型
bbc.fit(X_train, y_train)
# 预测并评估
y_pred = bbc.predict(X_test)
y_proba = bbc.predict_proba(X_test)[:, 1] # 预测概率(用于 ROC-AUC)
print("=== Balanced Bagging 分类报告 ===")
print(classification_report(y_test, y_pred))
print("ROC-AUC 分数:", roc_auc_score(y_test, y_proba))
# 绘制 ROC 曲线
RocCurveDisplay.from_estimator(bbc, X_test, y_test)
plt.title("Balanced Bagging ROC Curve")
plt.show()
关键参数解释
- n_estimators:子模型数量,值越大模型越稳定,但计算成本增加。
- sampling_strategy:
- ‘auto’:默认将多数类欠采样至少数类数量。
- 5:将多数类欠采样至少数类的 50%。
- replacement:是否允许有放回采样(设为True 可模拟自助采样法)。
Balanced Random Forest
原理:在随机森林的每棵树训练时,对多数类欠采样,确保每棵树的训练数据平衡。支持并行计算,适合大规模数据。
代码示例:
from imblearn.ensemble import BalancedRandomForestClassifier
# 初始化 Balanced Random Forest
brf = BalancedRandomForestClassifier(
n_estimators=100, # 100 棵树
sampling_strategy='auto', # 欠采样至与少数类平衡
max_depth=5, # 控制树复杂度
random_state=42,
n_jobs=-1 # 并行计算
)
# 训练模型
brf.fit(X_train, y_train)
# 预测并评估
y_pred = brf.predict(X_test)
y_proba = brf.predict_proba(X_test)[:, 1]
print("=== Balanced Random Forest 分类报告 ===")
print(classification_report(y_test, y_pred))
print("ROC-AUC 分数:", roc_auc_score(y_test, y_proba))
# 绘制特征重要性
importances = brf.feature_importances_
plt.bar(range(X.shape[1]), importances)
plt.title("Feature Importance (Balanced Random Forest)")
plt.xlabel("Feature Index")
plt.ylabel("Importance")
plt.show()
优势
- 天然支持并行训练(通过n_jobs=-1)。
- 提供特征重要性分析,适合高维数据特征筛选。
EasyEnsemble
适用场景
- 多数类样本高度冗余(如多数类样本数量是少数类的 100 倍以上)。
- 需要提升模型多样性,避免欠采样导致的信息丢失。
代码实现
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, roc_auc_score, RocCurveDisplay
from imblearn.ensemble import EasyEnsembleClassifier
from sklearn.ensemble import AdaBoostClassifier
# 生成极端不平衡数据集(多数类:5000,少数类:50)
X, y = make_classification(
n_samples=5050,
n_classes=2,
weights=[0.99], # 99% 多数类
flip_y=0.02, # 2% 标签噪声
random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 初始化 EasyEnsemble
ee = EasyEnsembleClassifier(
n_estimators=100, # 生成 100 个平衡子集
base_estimator=AdaBoostClassifier(n_estimators=10), # 基模型为 AdaBoost
sampling_strategy='auto', # 每个子集样本数与少数类相同
random_state=42,
n_jobs=-1 # 并行加速
)
# 训练模型
ee.fit(X_train, y_train)
# 预测与评估
y_pred = ee.predict(X_test)
y_proba = ee.predict_proba(X_test)[:, 1] # 预测概率
print("=== EasyEnsemble 分类报告 ===")
print(classification_report(y_test, y_pred))
print("ROC-AUC:", roc_auc_score(y_test, y_proba))
# 可视化基模型的 ROC 曲线(部分示例)
plt.figure(figsize=(8, 6))
for i in range(10): # 仅绘制前10个基模型的曲线
RocCurveDisplay.from_estimator(ee.estimators_[i], X_test, y_test, alpha=0.1)
plt.title("EasyEnsemble 基模型 ROC 曲线(部分)")
plt.show()
关键参数说明
- n_estimators:生成的平衡子集数量,值越大模型稳定性越高,但计算成本增加。
- base_estimator:基模型选择,推荐使用轻量级模型(如浅层决策树)以提高效率。
- sampling_strategy:控制多数类欠采样的比例,设为5 可保留更多多数类信息。
RUSBoost
适用场景
- 需要动态关注分类错误的困难样本(如医疗诊断中的高风险误诊样本)。
- 数据中存在噪声,但希望通过权重调整抑制噪声影响。
代码实现
from imblearn.ensemble import RUSBoostClassifier
# 生成不平衡数据集(多数类:1000,少数类:100)
X, y = make_classification(
n_samples=1100,
n_classes=2,
weights=[0.9], # 90% 多数类
random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 初始化 RUSBoost
rusboost = RUSBoostClassifier(
n_estimators=200, # 迭代次数
learning_rate=0.1, # 学习率(控制权重更新幅度)
sampling_strategy='auto', # 欠采样至与少数类平衡
algorithm='SAMME.R', # 使用概率提升算法
random_state=42
)
# 训练模型
rusboost.fit(X_train, y_train)
# 预测与评估
y_pred = rusboost.predict(X_test)
y_proba = rusboost.predict_proba(X_test)[:, 1]
print("=== RUSBoost 分类报告 ===")
print(classification_report(y_test, y_pred))
print("ROC-AUC:", roc_auc_score(y_test, y_proba))
# 绘制特征重要性(仅当基模型为决策树时有效)
importances = rusboost.feature_importances_
plt.bar(range(X.shape[1]), importances)
plt.title("RUSBoost 特征重要性")
plt.xlabel("特征索引")
plt.ylabel("重要性")
plt.show()
关键参数说明
- learning_rate:学习率控制权重更新幅度,值越小模型越保守(需配合更多迭代次数)。
- algorithm:
- ‘SAMME’:适用于离散类别预测。
- ‘SAMME.R’:利用概率估计提升效果,通常更优。
数据清洗(Data Cleaning)
去除噪声样本或重叠样本,提升数据质量。
方法:
- Edited Nearest Neighbours (ENN):删除类别与周围样本不一致的样本。
- Repeated Edited Nearest Neighbours:多次应用 ENN 直到无法进一步清理。
Edited Nearest Neighbours (ENN)
原理:删除与周围邻居多数类别不一致的样本。
import numpy as np
from sklearn.datasets import make_classification
from imblearn.under_sampling import EditedNearestNeighbours
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# 生成包含噪声的不平衡数据集(多数类:1000,少数类:100,噪声比例约5%)
X, y = make_classification(
n_samples=1100,
n_features=2,
n_redundant=0,
weights=[0.9], # 90% 多数类
flip_y=0.05, # 5% 标签噪声
random_state=42
)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=42
)
# 查看原始数据分布
print("原始训练集类别分布:", np.bincount(y_train))
# 输出示例:array([792, 88])
# 初始化 ENN
enn = EditedNearestNeighbours(
n_neighbors=3, # 检查每个样本的 3 个最近邻
kind_sel="all" # 删除与所有邻居类别不一致的样本(可选 "mode" 保留多数类别)
)
# 应用 ENN 清洗数据
X_cleaned, y_cleaned = enn.fit_resample(X_train, y_train)
# 查看清洗后的数据分布
print("清洗后训练集类别分布:", np.bincount(y_cleaned))
# 输出示例:array([755, 80]) # 删除了部分噪声样本
# 训练模型并评估
model = LogisticRegression()
model.fit(X_cleaned, y_cleaned)
y_pred = model.predict(X_test)
# 打印分类报告
print("=== ENN 清洗后模型性能 ===")
print(classification_report(y_test, y_pred))
Repeated Edited Nearest Neighbours
原理:多次应用 ENN 直到无法进一步清理。
from imblearn.under_sampling import RepeatedEditedNearestNeighbours
# 初始化 Repeated ENN
renn = RepeatedEditedNearestNeighbours(
n_neighbors=3,
max_iter=100, # 最大迭代次数(即使未收敛也停止)
kind_sel="all"
)
# 应用 Repeated ENN 清洗数据
X_cleaned, y_cleaned = renn.fit_resample(X_train, y_train)
# 查看清洗后的数据分布
print("清洗后训练集类别分布:", np.bincount(y_cleaned))
# 输出示例:array([742, 78]) # 比单次 ENN 删除更多样本
# 训练模型并评估
model = LogisticRegression()
model.fit(X_cleaned, y_cleaned)
y_pred = model.predict(X_test)
print("=== Repeated ENN 清洗后模型性能 ===")
print(classification_report(y_test, y_pred))
参数解释与调优
关键参数
- n_neighbors:
- 值越大,对噪声的容忍度越高,但可能无法有效清理局部不一致样本。
- 典型取值范围:3-10。
- kind_sel:
- “all”:仅当样本与所有邻居类别一致时保留。
- “mode”:保留与邻居多数类别一致的样本。
- max_iter(仅用于 Repeated ENN):
- 设置最大迭代次数,防止无限循环。
自定义参数示例
# 更严格的清洗策略
strict_enn = EditedNearestNeighbours(
n_neighbors=5, # 检查 5 个邻居
kind_sel="mode" # 允许少数服从多数
)
# 更激进的 Repeated ENN
aggressive_renn = RepeatedEditedNearestNeighbours(
n_neighbors=3,
max_iter=50,
kind_sel="all"
)
效果对比
| 方法 | 适用场景 | 优点 | 缺点 |
| ENN | 数据中存在局部噪声或少量类别重叠 | 快速删除明显不一致的样本 | 可能误删少数类边缘样本 |
| Repeated ENN | 数据中存在复杂噪声或多次迭代可清理的场景 | 更彻底清理噪声 | 可能过度删除样本,导致数据量减少 |
与模型训练的集成
将数据清洗步骤嵌入 Pipeline,确保流程可复用:
from imblearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('enn', EditedNearestNeighbours(n_neighbors=3)),
('scaler', StandardScaler()),
('clf', LogisticRegression())
])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
注意事项
- 类别不平衡场景的特殊处理:
- 如果少数类样本本身很少,ENN 可能过度删除样本,需谨慎使用。
- 可先对少数类过采样(如 SMOTE),再应用 ENN 清理噪声。
- 高维数据问题:
- 在高维空间中,距离计算可能失效,导致 ENN 效果下降。建议先降维(如 PCA)再清洗。
- 评估指标选择:
- 重点关注少数类的召回率(Recall)和精确率(Precision),而非整体准确率。
通过 ENN 和 Repeated ENN 的合理使用,可以显著提升数据质量,尤其适用于噪声较多或类别边界模糊的场景。
方法选择指南
| 场景 | 推荐方法 |
| 少数类样本极少(<100) | SMOTE 或 Borderline-SMOTE(需确保特征空间可插值) |
| 多数类样本冗余(如百万级) | ClusterCentroids 或 NearMiss-3(保留代表性样本) |
| 数据中存在噪声 | 先使用 SMOTEENN 或 Tomek Links 清理数据,再训练模型 |
| 计算资源充足 | Balanced Random Forest 或 EasyEnsemble(集成方法效果更稳定) |
| 高维数据(如文本、基因数据) | SVM-SMOTE 或 KMeans-SMOTE(基于模型或聚类生成样本,避免高维空间插值失效) |
注意事项
- 过采样潜在风险:
- SMOTE 可能在类别重叠区域生成噪声样本,导致模型性能下降。
- 对高维稀疏数据(如文本 TF-IDF 矩阵),插值生成样本可能无效。
- 欠采样信息丢失:
- 随机欠采样可能丢失重要样本,需结合筛选策略(如 NearMiss)。
- 评估指标选择:
- 避免使用准确率(Accuracy),推荐使用F1-Score、ROC-AUC 或 Precision-Recall Curve。
参考链接:
- 官方文档:imbalanced-learn.org
- GitHub 仓库:com/scikit-learn-contrib/imbalanced-learn


