交叉验证方法盘点
在机器学习中,常见有的交叉验证方法有留出法(Holdout cross validation)和k折交叉验证(k-fold cross validation)等,除此之外还有留一法(Leave-One-Out,LOO)、留P法(Leave-P-Out,LPO)等,抽时间做了一些简单的整理。
留出法(Holdout cross validation)
留出法是将原始数据随机分为两个互斥的集合,一个作为训练集,另一个作为测试集。在对训练集进行训练后,用测试集来评估模型的性能。
优点:
- 简单易用,计算量较小。
- 对于大规模数据集,可以快速构建并验证模型。
缺点:
- 训练集和测试集的划分可能不够随机或不够充分,导致结果偏差。
- 只进行一次划分,对于数据量较小时可能无法保证模型稳定性。
- 数据集划分后会浪费部分数据,尤其是当数据集非常小的时候。
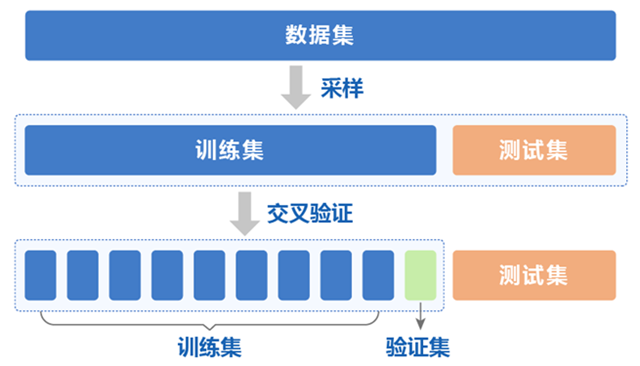
有些场景下,留出法还会额外增加一个验证集,具体的功能划分为:
- 训练集:训练模型
- 验证集:调参
- 测试集:评估模型的泛化能力
Scikit-Learn中的数据集拆分train_test_split()方法可以用于留出法。由于先前已经介绍过这里就不再做重复介绍了。
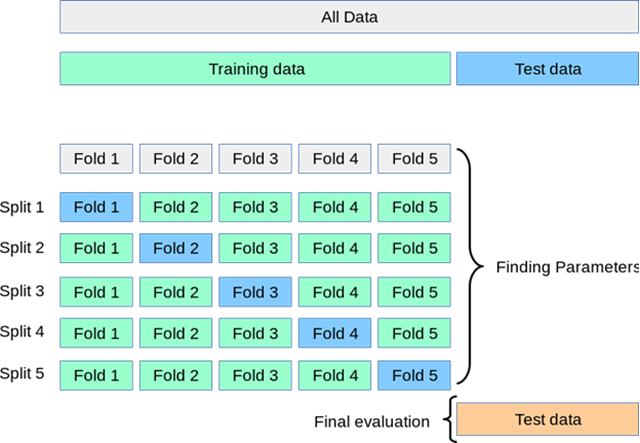
k折交叉验证(k-fold cross validation)
k折交叉验证首先将原始数据随机分成k个互斥的子集,然后利用其中的k-1个子集作为训练集,剩下的1个子集作为验证集。对于这k种划分情况,分别进行k次训练和测试,最终返回平均测试结果。
优点:
- 数据集的每个子集都有机会作为验证集和训练集,增加了模型的稳定性和精度。
- 能够更好地利用数据,相对于留出法和留一法更加可靠。
缺点:
- 计算量相对于留出法和留一法略大。
- 在某些特殊情况(如数据分布不均衡、数据中存在噪声等)下,结果可能不太可靠。
Scikit-learn中的k折交叉验证
KFold
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold
from sklearn.linear_model import LogisticRegression
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 定义5折交叉验证器
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 创建逻辑回归模型
lr = LogisticRegression()
# 对于每个训练集和测试集进行训练和评估
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 训练模型
lr.fit(X_train, y_train)
# 评估模型
score = lr.score(X_test, y_test)
print("Accuracy:", score)
GroupKFold
GroupKFold是一种交叉验证的策略,它将数据集按照分组信息进行划分,保证同一组中的样本要么全部在训练集中,要么全部在测试集中。
具体来说,GroupKFold会将数据集分为K份,其中每份保持同一组中的样本比例相同。然后,依次选取其中一份作为测试集,其余的K-1份作为训练集,进行模型训练和测试。这个过程会重复K次,每次选取不同的测试集和训练集,最终得到K个模型性能评估结果的平均值。
GroupKFold的主要参数包括:
- n_splits:表示将数据集拆分成几份,默认为5。
GroupKFold的优点是能够确保同一组中的样本要么全部在训练集中,要么全部在测试集中,从而更好地反映模型的实际表现。缺点是对于某些数据集和模型,可能需要更多的训练时间和计算资源。
下面是一个使用GroupKFold进行交叉验证的示例代码:
from sklearn.datasets import make_classification
from sklearn.model_selection import GroupKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 生成分类数据集和分组信息
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
groups = [i % 3 for i in range(len(X))]
# 定义GroupKFold对象
gkf = GroupKFold(n_splits=3)
# 定义模型
model = LogisticRegression()
# 用GroupKFold进行交叉验证
scores = []
for train_index, test_index in gkf.split(X, y, groups):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/- {:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先生成了一个分类数据集和分组信息,然后定义了一个GroupKFold对象,将数据集拆分为3份,保持同一组中的样本比例相同。接着定义了一个LogisticRegression模型,并用GroupKFold进行交叉验证,最后输出了模型的平均准确率和标准差。
RepeatedKFold
RepeatedKFold是一种交叉验证的策略,它将数据集随机拆分为训练集和测试集,可以用于评估模型的性能和选择最优参数。与KFold不同的是,RepeatedKFold会重复运行K次,每次生成不同的随机拆分结果。
具体来说,RepeatedKFold会将数据集分为K份,然后依次选取其中一份作为测试集,其余的K-1份作为训练集,进行模型训练和测试。这个过程会重复R次,每次选取不同的随机拆分结果,最终得到R*K个模型性能评估结果。
RepeatedKFold的主要参数包括:
- n_splits:表示将数据集拆分成几份,默认为5。
- n_repeats:表示重复运行几次交叉验证,默认为10。
RepeatedKFold的优点是能够生成多个随机拆分结果,从而减小误差和提高可靠性。缺点是由于每次随机拆分都需要重新生成,因此计算代价较大,适合数据量较小的场景。
下面是一个使用RepeatedKFold进行交叉验证的示例代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import RepeatedKFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
X, y = load_iris(return_X_y=True)
# 定义RepeatedKFold对象
rkf = RepeatedKFold(n_splits=5, n_repeats=3, random_state=42)
# 定义模型
model = DecisionTreeClassifier()
# 用RepeatedKFold进行交叉验证
scores = []
for train_index, test_index in rkf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/- {:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了鸢尾花数据集,然后定义了一个RepeatedKFold对象,将数据集拆分为5份,重复运行3次。接着定义了一个DecisionTreeClassifier模型,并用RepeatedKFold进行交叉验证,最后输出了模型的平均准确率和标准差。
StratifiedKFold
StratifiedKFold 是一种交叉验证的策略,它将数据集按照类别信息进行分层划分,可以确保每个类别在训练集和测试集中的比例相同。
具体来说,StratifiedKFold 会将数据集分为 K 份,其中每份保持不同类别的样本比例相同。然后,依次选取其中一份作为测试集,其余的 K-1 份作为训练集,进行模型训练和测试。这个过程会重复 K 次,每次选取不同的测试集和训练集,最终得到 K 个模型性能评估结果的平均值。
StratifiedKFold 的主要参数包括:
- n_splits:表示将数据集拆分成几份,默认为 5。
StratifiedKFold 的优点是能够确保每个类别在训练集和测试集中的比例相同,从而更好地反映模型的实际表现。缺点是对于某些数据集和模型,可能需要更多的训练时间和计算资源。
下面是一个使用 StratifiedKFold 进行交叉验证的示例代码:
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
X, y = load_iris(return_X_y=True)
# 定义 StratifiedKFold 对象
skf = StratifiedKFold(n_splits=5)
# 定义模型
model = DecisionTreeClassifier()
# 用 StratifiedKFold 进行交叉验证
scores = []
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/- {:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了鸢尾花数据集,然后定义了一个 StratifiedKFold 对象,将数据集拆分为 5 份,保持不同类别的样本比例相同。接着定义了一个 DecisionTreeClassifier 模型,并用 StratifiedKFold 进行交叉验证,最后输出了模型的平均准确率和标准差。
RepeatedStratifiedKFold
RepeatedStratifiedKFold 是一种交叉验证的策略,它将数据集按照类别信息进行分层划分,可以确保每个类别在训练集和测试集中的比例相同。与 StratifiedKFold 不同的是,RepeatedStratifiedKFold 会重复运行 K 次,每次生成不同的随机拆分结果。
具体来说,RepeatedStratifiedKFold 会将数据集分为 K 份,其中每份保持不同类别的样本比例相同。然后,依次选取其中一份作为测试集,其余的 K-1 份作为训练集,进行模型训练和测试。这个过程会重复 R 次,每次选取不同的随机拆分结果,最终得到 R*K 个模型性能评估结果。
RepeatedStratifiedKFold 的主要参数包括:
- n_splits:表示将数据集拆分成几份,默认为 5。
- n_repeats:表示重复运行几次交叉验证,默认为 10。
RepeatedStratifiedKFold 的优点是能够确保每个类别在训练集和测试集中的比例相同,从而更好地反映模型的实际表现。缺点是由于每次随机拆分都需要重新生成,因此计算代价较大,适合数据量较小的场景。
下面是一个使用 RepeatedStratifiedKFold 进行交叉验证的示例代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import RepeatedStratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载手写数字数据集
X, y = load_digits(return_X_y=True)
# 定义 RepeatedStratifiedKFold 对象
rskf = RepeatedStratifedKFold(n_splits=5, n_repeats=3, random_state=42)
# 定义模型
model = LogisticRegression()
# 用 RepeatedStratifedKFold 进行交叉验证
scores = []
for train_index, test_index in rskf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/- {:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了手写数字数据集,然后定义了一个 RepeatedStratifiedKFold 对象,将数据集拆分为 5 份,重复运行 3 次。接着定义了一个 LogisticRegression 模型,并用 RepeatedStratifiedKFold 进行交叉验证,最后输出了模型的平均准确率和标准差。
留一法(Leave one out cross validation)
留一法是 k 折交叉验证的特例。在留一法中,每个样本依次被作为测试集,其余所有样本作为训练集,进行模型训练和测试。
优点:
- 将原始数据集的全部信息都用于训练模型,从而得到最准确的模型评估结果。
- 对于小数据集比较适用。
缺点:
- 运算开销较大,需要训练 n 个模型,其中 n 为数据集大小。
- 对于大数据集,由于需要进行大量的重复实验,留一法计算成本很高。
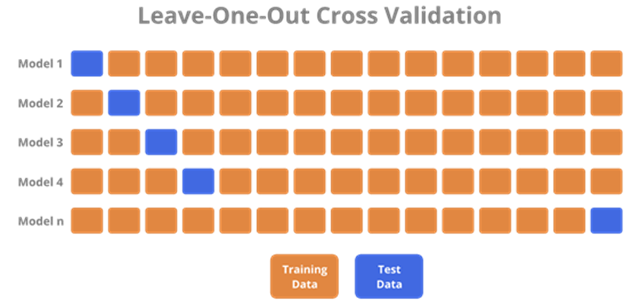
Scikit-learn 中可以使用 LeaveOneOut 类来进行留一法交叉验证(Leave-One-Out Cross Validation)。留一法交叉验证是将每个样本都作为测试数据,其余样本作为训练数据,这样得到 n 个分类器的评估结果,最后计算平均值。对于小规模数据集(如当样本数量小于 20 时),留一法交叉验证是一种很好的验证方法。
下面是一个使用留一法交叉验证进行模型评估的范例:
from sklearn.datasets import load_iris
from sklearn.model_selection import LeaveOneOut
from sklearn.linear_model import LogisticRegression
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建逻辑回归模型
lr = LogisticRegression()
# 定义留一法交叉验证器
loo = LeaveOneOut()
# 初始化正确分类数和总样本数
correct = 0
total = 0
# 对于每个训练集和测试集进行训练和评估
for train_index, test_index in loo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 训练模型
lr.fit(X_train, y_train)
# 预测测试集并计算准确率
y_pred = lr.predict(X_test)
if y_pred == y_test:
correct += 1
total += 1
# 输出模型在所有测试集上的准确率
print("Accuracy:", correct/total)
在上述代码中,我们首先加载了鸢尾花数据集,然后创建了一个逻辑回归模型,并定义了一个留一法交叉验证器。接着,我们对于每个训练集和测试集进行训练和评估,并记录了模型在所有测试集上的正确分类数和总样本数。最后,我们输出了模型在所有测试集上的准确率。
留P法(Leave-P-Out,LPO)交叉验证
留P法交叉验证(Leave-P-Out Cross Validation,简称LPO)是一种K折交叉验证的特例。在LPO中,每次将P个样本作为测试集,其余的样本作为训练集,重复这个过程直到所有的组合都被尝试一遍,即共有nCp种情况。
相对于其他的交叉验证方法,LPO更加严格和耗时,但由于考虑了全部的nCp种情况,因此能给出非常准确的模型评估结果,而且可以充分利用小数据集中的所有样本。因此,在样本数量较少或使用机器学习算法比较困难的情况下,LPO可以作为一种有效的交叉验证策略。
Scikit-learn中可以使用LeavePOut类来实现LPO交叉验证。下面是一个使用留P法交叉验证进行模型评估的示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import LeavePOut
from sklearn.linear_model import LogisticRegression
# 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 创建逻辑回归模型
lr = LogisticRegression()
# 定义留P法交叉验证器
lpo = LeavePOut(p=2)
# 初始化正确分类数和总样本数
correct = 0
total = 0
# 对于每个训练集和测试集进行训练和评估
for train_index, test_index in lpo.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# 训练模型
lr.fit(X_train, y_train)
# 预测测试集并计算准确率
y_pred = lr.predict(X_test)
if y_pred == y_test:
correct += 1
total += 1
# 输出模型在所有测试集上的准确率
print("Accuracy:", correct/total)
在上述代码中,我们首先加载了鸢尾花数据集,然后创建了一个逻辑回归模型,并定义了一个留P法交叉验证器。接着,我们对于每个训练集和测试集进行训练和评估,并记录了模型在所有测试集上的正确分类数和总样本数。最后,我们输出了模型在所有测试集上的准确率。
总的来说,留P法交叉验证是一种严格和耗时的验证方法,但对于小规模数据集来说是一种很好的验证方法。在样本数量较少或机器学习算法比较困难的情况下,可以使用LPO来进行模型评估。
随机排列交叉验证ShuffleSplit
ShuffleSplit是一种交叉验证的策略,它将数据随机拆分为训练集和测试集,可以用于评估模型的性能和选择最优参数。
具体来说,ShuffleSplit会对整个数据集进行多次随机划分,每次划分都会按照指定比例生成训练集和测试集。这些划分是互相独立的,可以用来对同一个模型进行多次评估,从而减小误差和提高可靠性。
ShuffleSplit的主要参数包括:
- n_splits:表示拆分成几份,默认为10。
- test_size:表示每次拆分中测试集的大小,可以是一个浮点数(表示占总数据量的比例)或整数(表示具体数量),默认为1。
- train_size:表示每次拆分中训练集的大小,如果不设置,则默认为1-test_size。
- random_state:表示随机数种子,用于确保每次拆分结果的可重复性。
ShuffleSplit的优点是可以利用全部数据对模型进行训练和测试,并且每次划分的结果都是随机的,能够更好地反映模型的实际表现。缺点是由于每次随机划分都需要重新生成,因此计算代价较大,适合数据量较小的场景。
下面是一个使用ShuffleSplit进行交叉验证的示例代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import ShuffleSplit
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载手写数字数据集
X, y = load_digits(return_X_y=True)
# 定义ShuffleSplit对象
ss = ShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
# 定义模型
model = LogisticRegression()
# 用ShuffleSplit进行交叉验证
scores = []
for train_index, test_index in ss.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/-{:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了手写数字数据集,然后定义了一个ShuffleSplit对象,将数据集拆分为5份,每次测试集占比20%。接着定义了一个LogisticRegression模型,并用ShuffleSplit进行交叉验证,最后输出了模型的平均准确率和标准差。
需要注意的是,由于ShuffleSplit划分结果是随机的,因此每次运行代码得到的结果可能会略有不同。
分层K折交叉验证StratifiedKFold
分层K折交叉验证(StratifiedKFold)是一种交叉验证的策略,它可以确保每个类别在训练集和测试集中的比例相同。这种交叉验证方法适用于有不同类别或标签的分类问题。
具体来说,StratifiedKFold会将数据集分为K份,其中每份保持原始数据集中各类别样本的比例。然后,依次选取其中一份作为测试集,其余的K-1份作为训练集,进行模型训练和测试。这个过程会重复K次,每次选取不同的测试集和训练集,最终得到K个模型性能评估结果的平均值。
StratifiedKFold的主要参数包括:
- n_splits:表示将数据集拆分成几份,默认为5。
- shuffle:表示是否对数据集进行随机打乱,默认为True。
- random_state:表示随机数种子,用于确保每次拆分结果的可重复性。
StratifiedKFold的优点是能够确保不同类别的样本在训练集和测试集中的比例相同,从而更好地反映模型的实际表现。缺点是对于某些数据集和模型,可能需要更多的训练时间和计算资源。
下面是一个使用StratifiedKFold进行交叉验证的示例代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载手写数字数据集
X, y = load_digits(return_X_y=True)
# 定义StratifiedKFold对象
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 定义模型
model = LogisticRegression()
# 用StratifiedKFold进行交叉验证
scores = []
for train_index, test_index in skf.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/-{:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了手写数字数据集,然后定义了一个StratifiedKFold对象,将数据集拆分为5份,并对每份进行随机打乱。接着定义了一个LogisticRegression模型,并用StratifiedKFold进行交叉验证,最后输出了模型的平均准确率和标准差。
分层随机排列交叉验证StratifiedShuffleSplit
分层随机排列交叉验证(StratifiedShuffleSplit)是一种交叉验证的策略,它将数据集随机拆分为训练集和测试集,同时保持每个类别在训练集和测试集中的比例相同。
具体来说,StratifiedShuffleSplit会对整个数据集进行多次随机划分,每次划分都会按照指定比例生成训练集和测试集,并且保持每个类别在训练集和测试集中的比例相同。这些划分是互相独立的,可以用来对同一个模型进行多次评估,从而减小误差和提高可靠性。
StratifiedShuffleSplit的主要参数包括:
- n_splits:表示拆分成几份,默认为10。
- test_size:表示每次拆分中测试集的大小,可以是一个浮点数(表示占总数据量的比例)或整数(表示具体数量),默认为1。
- train_size:表示每次拆分中训练集的大小,如果不设置,则默认为1-test_size。
- random_state:表示随机数种子,用于确保每次拆分结果的可重复性。
StratifiedShuffleSplit的优点是能够确保不同类别的样本在训练集和测试集中的比例相同,从而更好地反映模型的实际表现。缺点是由于每次随机划分都需要重新生成,因此计算代价较大,适合数据量较小的场景。
下面是一个使用StratifiedShuffleSplit进行交叉验证的示例代码:
from sklearn.datasets import load_digits
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载手写数字数据集
X, y = load_digits(return_X_y=True)
# 定义StratifiedShuffleSplit对象
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=42)
# 定义模型
model = LogisticRegression()
# 用StratifiedShuffleSplit进行交叉验证
scores = []
for train_index, test_index in sss.split(X, y):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = accuracy_score(y_test, y_pred)
scores.append(score)
# 输出结果
print("Accuracy: {:.3f} (+/-{:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了手写数字数据集,然后定义了一个StratifiedShuffleSplit对象,将数据集拆分为5份,每次测试集占比20%。接着定义了一个LogisticRegression模型,并用StratifiedShuffleSplit进行交叉验证,最后输出了模型的平均准确率和标准差。
时间序列分割法TimeSeriesSplit
时间序列分割法(TimeSeriesSplit)是一种交叉验证的策略,它将数据集按照时间顺序进行划分,保证训练集和测试集之间不存在时间上的重叠。
具体来说,TimeSeriesSplit会将时间序列数据集划分为K份,其中每份都包含相同数量的连续时间窗口。然后,依次选取其中一份作为测试集,其余的K-1份作为训练集,进行模型训练和测试。这个过程会重复K次,每次选取不同的测试集和训练集,最终得到K个模型性能评估结果的平均值。
TimeSeriesSplit的主要参数包括:
- n_splits:表示将时间序列数据集拆分成几份,默认为5。
- TimeSeriesSplit的优点是能够确保训练集和测试集之间不存在时间上的重叠,从而更好地反映模型在未来的实际表现。缺点是对于某些数据集和模型,可能需要更多的训练时间和计算资源。
下面是一个使用TimeSeriesSplit进行交叉验证的示例代码:
from sklearn.datasets import load_boston
from sklearn.model_selection import TimeSeriesSplit
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
X, y = load_boston(return_X_y=True)
# 定义TimeSeriesSplit对象
tss = TimeSeriesSplit(n_splits=5)
# 定义模型
model = LinearRegression()
# 用TimeSeriesSplit进行交叉验证
scores = []
for train_index, test_index in tss.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
score = mean_squared_error(y_test, y_pred)
scores.append(score)
# 输出结果
print("MSE: {:.3f} (+/-{:.3f})".format(np.mean(scores), np.std(scores)))
在这个例子中,我们首先加载了波士顿房价数据集,然后定义了一个TimeSeriesSplit对象,将数据集划分为5份。接着定义了一个LinearRegression模型,并用TimeSeriesSplit进行交叉验证,最后输出了模型的平均MSE和标准差。
快速交叉验证工具
Scikit-learn中的cross_val_score 和 cross_validate 是2个快速交叉验证工具。
核心功能对比
| 特性 | cross_val_score | cross_validate |
| 返回值 | 单一指标的测试集得分数组 | 包含测试集得分、训练时间等的字典 |
| 多指标支持 | 仅支持单个评估指标 | 支持同时计算多个评估指标 |
| 训练时间 | 不记录 | 记录每折训练和预测时间 |
| 返回训练集得分 | 不支持 | 可选返回训练集得分(return_train_score=True) |
| 灵活性 | 简单快速 | 高(支持复杂需求) |
参数详解
共同参数
- estimator: 待评估的模型(如RandomForestClassifier())。
- X,y: 输入数据和标签。
- cv: 交叉验证策略(默认5折):可传入整数(折数)、KFold对象或自定义划分器。
- n_jobs: 并行计算的核心数(-1表示使用所有核心)。
- verbose: 输出日志详细程度(0为静默,值越大输出越多)。
cross_val_score 特有参数
- scoring: 单一评估指标(如’accuracy’、’f1’、’neg_mean_squared_error’)。
cross_validate 特有参数
- scoring: 支持多指标(传入列表或字典,如[‘accuracy’, ‘f1’])。
- return_train_score: 是否返回训练集得分(默认False)。
- return_estimator: 是否返回每折训练的模型(默认False)。
使用场景与选择建议
选择 cross_val_score 的情况
- 只需快速获取模型在单一指标 上的验证结果。
- 无需额外信息(如训练时间、训练集得分)。
选择 cross_validate 的情况
- 需要同时评估多个指标(如准确率和F1分数)。
- 需分析训练/测试时间 或 过拟合程度(通过训练集和测试集得分对比)。
- 需保存每折训练的模型(用于后续分析或集成)。
代码示例
cross_val_score 基础用法(分类问题)
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# 加载数据
X, y = load_iris(return_X_y=True)
model = RandomForestClassifier(n_estimators=100)
# 5折交叉验证,计算准确率
scores = cross_val_score(
estimator=model,
X=X, y=y,
cv=5,
scoring='accuracy',
n_jobs=-1
)
print("测试集准确率:", scores) # 例如 [0.97, 0.96, 0.98, 0.95, 0.97]
print("平均准确率:", scores.mean()) # 0.966
cross_validate 多指标与时间记录(回归问题)
from sklearn.model_selection import cross_validate
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Ridge
# 加载数据
X, y = load_diabetes(return_X_y=True)
model = Ridge(alpha=0.5)
# 定义多指标:R²和负均方误差(MSE)
scoring = ['r2', 'neg_mean_squared_error']
# 交叉验证,返回训练时间和训练集得分
results = cross_validate(
estimator=model,
X=X, y=y,
cv=5,
scoring=scoring,
return_train_score=True,
n_jobs=-1
)
# 输出结果
print("测试集R²:", results['test_r2'])
print("训练集MSE:", -results['train_neg_mean_squared_error']) # 注意负号转换
print("每折拟合时间:", results['fit_time'])
输出结果解析(cross_validate 返回的字典)
- test_score/ train_score: 测试集/训练集的得分数组(多指标时为字典,如 test_r2)。
- fit_time: 每折模型训练时间(秒)。
- score_time: 每折模型预测时间(秒)。
- estimator(若return_estimator=True): 各折训练好的模型对象。
高级技巧与注意事项
评估指标的选择
- 分类任务常用指标:
- ‘accuracy’(准确率)、’f1’(二分类)、’f1_macro’(多分类)。
- ‘roc_auc’(需要概率预测,需设置predict_proba())。
- 回归任务常用指标:
- ‘r2’(R平方)、’neg_mean_squared_error’(负均方误差,需取负号得MSE)。
自定义指标:
from sklearn.metrics import make_scorer
def custom_loss(y_true, y_pred):
return ... # 自定义计算逻辑
scorer = make_scorer(custom_loss, greater_is_better=False)
处理交叉验证中的随机性
若模型或数据划分包含随机性(如 ShuffleSplit、随机森林),需固定随机种子:
cv = KFold(n_splits=5, shuffle=True, random_state=42) model = RandomForestClassifier(random_state=42)
性能优化
- 设置n_jobs=-1 利用多核加速(但对大型模型可能内存不足)。
- 对计算密集型模型(如深度学习),减少cv 折数(如3折)。
常见问题与解决方案
Q1:如何获取每折的预测结果?
使用 cross_val_predict(但需注意数据泄露风险):
from sklearn.model_selection import cross_val_predict y_pred = cross_val_predict(model, X, y, cv=5)
Q2:如何对比训练集和测试集得分以检测过拟合?
在 cross_validate 中设置 return_train_score=True:
results = cross_validate(model, X, y, return_train_score=True)
print("训练集得分:", results['train_score'])
print("测试集得分:", results['test_score'])
Q3:如何自定义数据划分策略?
传入自定义的交叉验证对象,例如时间序列的 TimeSeriesSplit:
from sklearn.model_selection import TimeSeriesSplit cv = TimeSeriesSplit(n_splits=5) scores = cross_val_score(model, X, y, cv=cv)
交叉验证与超参数调优
GridSearchCV 核心原理
- 目标:通过遍历所有预定义的超参数组合,结合交叉验证评估每组参数的性能,最终选择最优参数组合。
- 工作流程:
- 定义参数网格:指定需要搜索的超参数及其候选值。
- 交叉验证评估:对每个参数组合,使用交叉验证计算平均得分。
- 选择最优参数:根据得分选择最佳参数,并自动用全量训练数据重新训练最终模型(若refit=True)。
核心参数解析
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(
estimator=model, # 基模型(如随机森林、SVM)
param_grid=param_grid, # 参数网格(字典或列表)
scoring='accuracy', # 评估指标(支持多指标)
cv=5, # 交叉验证折数(默认5折)
n_jobs=-1, # 并行计算核心数(-1为全核心)
verbose=1, # 输出日志详细程度(0为静默)
refit=True, # 是否用最优参数重新训练全量数据
return_train_score=False # 是否返回训练集得分(用于过拟合分析)
)
完整代码示例(分类任务)
数据准备与模型定义
from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import train_test_split # 加载数据 X, y = load_iris(return_X_y=True) # 划分训练集和测试集(避免数据泄露) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 定义基模型 model = RandomForestClassifier(random_state=42)
定义参数网格
param_grid = {
'n_estimators': [50, 100, 200], # 树的数量
'max_depth': [None, 5, 10], # 树的最大深度
'min_samples_split': [2, 5], # 节点分裂最小样本数
'criterion': ['gini', 'entropy'] # 分裂标准
}
初始化并运行网格搜索
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
scoring='accuracy',
cv=5,
n_jobs=-1,
verbose=1
)
# 在训练集上执行搜索
grid_search.fit(X_train, y_train)
输出最优结果
print("最优参数组合:", grid_search.best_params_)
print("最优模型交叉验证得分:", grid_search.best_score_)
# 使用最优模型在测试集上评估
best_model = grid_search.best_estimator_
test_accuracy = best_model.score(X_test, y_test)
print("测试集准确率:", test_accuracy)
结果分析与高级操作
查看所有参数组合的得分
import pandas as pd # 将搜索结果转为DataFrame results = pd.DataFrame(grid_search.cv_results_) # 筛选关键列(参数组合、平均得分、标准差) results = results[['params', 'mean_test_score', 'std_test_score']] # 按得分排序 results.sort_values(by='mean_test_score', ascending=False, inplace=True) print(results.head())
可视化参数影响(以n_estimators为例)
import matplotlib.pyplot as plt
# 提取n_estimators的得分
n_estimators_scores = []
for params, score in zip(results['params'], results['mean_test_score']):
if params['max_depth'] == 10 and params['min_samples_split'] == 2:
n_estimators_scores.append(score)
plt.plot([50, 100, 200], n_estimators_scores, marker='o')
plt.xlabel('n_estimators')
plt.ylabel('Accuracy')
plt.title('Impact of n_estimators on Model Performance')
plt.show()
参数网格设计策略
分阶段搜索
- 粗搜索:大范围覆盖可能值(如n_estimators: [50, 100, 200, 500])。
- 精搜索:在较优范围内细化(如n_estimators: [80, 90, 100, 110, 120])。
参数依赖处理
- 条件参数:例如,当使用SVM 的 poly 核时,需调整 degree 参数。
param_grid = [
{'kernel': ['linear'], 'C': [0.1, 1, 10]},
{'kernel': ['poly'], 'degree': [2, 3], 'C': [0.1, 1]},
{'kernel': ['rbf'], 'gamma': ['scale', 'auto'], 'C': [1, 10]}
]
避免常见陷阱
数据泄露
- 严格划分数据:确保测试集不参与参数搜索和交叉验证。
- 预处理整合:将标准化等步骤放入Pipeline:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', RandomForestClassifier())
])
param_grid = {'model__n_estimators': [100, 200]}
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
计算资源优化
- 并行化:设置n_jobs=-1 加速,但注意内存限制。
- 随机搜索替代:使用RandomizedSearchCV 减少计算时间:
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint
param_dist = {
'n_estimators': randint(50, 200),
'max_depth': [None, 5, 10],
'min_samples_split': randint(2, 6)
}
random_search = RandomizedSearchCV(
model, param_dist, n_iter=20, cv=5, n_jobs=-1
)
超参数调优与模型泛化
过拟合验证曲线
训练集 vs 验证集得分:若训练集得分远高于验证集,可能过拟合。
results = cross_validate(
grid_search.best_estimator_,
X_train, y_train,
return_train_score=True
)
print("训练集得分:", results['train_score'].mean())
print("验证集得分:", results['test_score'].mean())
最终模型评估
独立测试集:仅在调优完成后使用测试集评估,避免多次使用导致数据泄露。
交叉验证高级技巧
自定义交叉验证策略
通过生成器函数定义任意划分规则:
def custom_cv():
# 自定义索引划分逻辑(例如按数据分组)
groups = np.array([1,1,2,2,3,3]) # 假设每组数据不可分割
unique_groups = np.unique(groups)
for group in unique_groups:
val_mask = (groups == group)
train_mask = ~val_mask
yield np.where(train_mask)[0], np.where(val_mask)[0]
model = RandomForestClassifier()
scores = cross_val_score(model, X, y, cv=custom_cv())
交叉验证中的预处理
使用 Pipeline 防止数据泄露(如标准化应在训练集上拟合):
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', SVC())
])
scores = cross_val_score(pipeline, X, y, cv=5)
交叉验证的最佳实践
数据预处理与划分
避免数据泄露
- 预处理必须在交叉验证循环内进行(如标准化、缺失值填充),确保每折训练集的信息不污染验证集。
- 正确做法:使用Pipeline 封装预处理步骤和模型。
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
pipeline = Pipeline([
('scaler', StandardScaler()), # 标准化
('classifier', SVC()) # 模型
])
# 交叉验证时自动在每折训练集上拟合scaler
scores = cross_val_score(pipeline, X, y, cv=5)
严格分割训练集和测试集
先分训练集和测试集,再在训练集上做交叉验证,测试集仅用于最终评估。
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) grid_search.fit(X_train, y_train) # 在训练集上交叉验证调参 final_score = grid_search.score(X_test, y_test) # 测试集评估
选择合适的交叉验证策略
分类问题:使用分层交叉验证
保持每折中类别比例与原数据一致(避免某些折中类别缺失)。
from sklearn.model_selection import StratifiedKFold cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) scores = cross_val_score(model, X, y, cv=cv)
时间序列:用时间序列分割
按时间顺序划分,防止未来信息泄漏。
from sklearn.model_selection import TimeSeriesSplit cv = TimeSeriesSplit(n_splits=5) scores = cross_val_score(model, X, y, cv=cv)
小样本数据:留一法或重复交叉验证
样本量极小时(如<100),使用 LeaveOneOut 或重复交叉验证。
from sklearn.model_selection import LeaveOneOut cv = LeaveOneOut() scores = cross_val_score(model, X, y, cv=cv)
调参与模型选择
在训练集上使用交叉验证调参
调参时仅在训练集上运行网格搜索,测试集留作最终验证。
param_grid = {'C': [0.1, 1, 10]}
grid_search = GridSearchCV(SVC(), param_grid, cv=5)
grid_search.fit(X_train, y_train) # 训练集调参
对比不同模型时保持测试集独立
使用交叉验证分数比较模型,但最终用独立测试集确认性能。
models = [RandomForestClassifier(), SVC(), LogisticRegression()]
for model in models:
scores = cross_val_score(model, X_train, y_train, cv=5)
print(f"{model.__class__.__name__} 平均得分: {scores.mean():.3f}")
结果分析与验证
关注验证分数均值和方差
- 高均值 + 低方差:模型稳定且性能好。
- 低均值 + 高方差:可能欠拟合或数据划分敏感。
print(f"平均准确率: {scores.mean():.3f} ± {scores.std():.3f}")
检查过拟合
通过 cross_validate 返回训练集和验证集得分:
results = cross_validate(model, X, y, cv=5, return_train_score=True)
print("训练集得分:", results['train_score'].mean())
print("验证集得分:", results['test_score'].mean())
- 训练集 >> 验证集:过拟合(需简化模型或增加正则化)。
- 训练集 ≈ 验证集:欠拟合(需增加模型复杂度)。
计算资源管理
并行加速
设置 n_jobs=-1 使用所有CPU核心。
scores = cross_val_score(model, X, y, cv=5, n_jobs=-1)
权衡折数和计算成本
- 大数据集:用较少折数(如3折)减少计算时间。
- 小数据集:增加折数(如10折)提高评估稳定性。
随机搜索替代网格搜索
参数空间大时,用 RandomizedSearchCV 减少搜索次数。
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import loguniform
param_dist = {
'C': loguniform(1e-3, 100), # 对数均匀分布采样
'gamma': loguniform(1e-4, 1)
}
search = RandomizedSearchCV(SVC(), param_dist, n_iter=50, cv=5)
其他关键实践
固定随机种子
确保结果可复现,尤其是在交叉验证和模型训练中。
model = RandomForestClassifier(random_state=42) cv = KFold(n_splits=5, shuffle=True, random_state=42)
处理不平衡数据
使用分层交叉验证或调整类别权重。
cv = StratifiedKFold(n_splits=5) model = RandomForestClassifier(class_weight='balanced')
多指标评估
同时监控多个指标(如准确率、F1、AUC)。
scoring = ['accuracy', 'f1_macro', 'roc_auc'] results = cross_validate(model, X, y, cv=5, scoring=scoring)
参考链接:


