sklearn.datasets 是 scikit-learn 中用于加载和生成数据集的工具模块,内置了多种经典数据集和灵活的数据生成方法,适合快速实验和算法验证。

内置数据集类型
模块中的数据集分为三类,通过不同函数加载:
小型内置数据集(Toy Datasets)
特点:数据量小,直接集成在库中,无需下载。
鸢尾花数据集(Iris)
数据集背景
- 来源:由统计学家 Ronald Fisher 于 1936 年发表,是最早用于模式识别研究的公开数据集之一。
- 用途:主要用于分类任务,尤其是监督学习中的多分类问题(如逻辑回归、决策树、SVM)。
- 特点:数据简单清晰、无缺失值、类别平衡,适合快速验证模型。
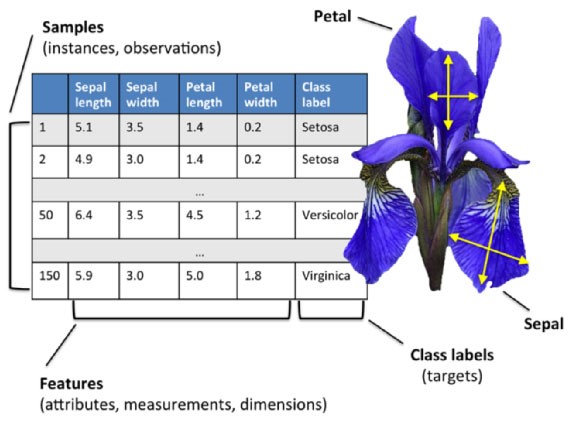
数据结构
- 样本数量:150 个样本(每个类别 50 个)。
- 特征数量:4 个数值型特征(单位均为厘米)。
- 目标类别:3 种鸢尾花(每个类别 50 个样本)。
特征说明
每个样本包含以下 4 个形态测量值:
- 花萼长度(sepal length)
- 花萼宽度(sepal width)
- 花瓣长度(petal length)
- 花瓣宽度(petal width)
目标类别
- 0: 山鸢尾(Iris setosa)
- 1: 变色鸢尾(Iris versicolor)
- 2: 维吉尼亚鸢尾(Iris virginica)
数据示例
以下是数据集的片段展示(部分示例值):
| sepal length | sepal width | petal length | petal width | target |
| 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 7.0 | 3.2 | 4.7 | 1.4 | 1 |
| 6.3 | 3.3 | 6.0 | 2.5 | 2 |
加载方法
使用 Scikit-learn 的 load_iris 函数加载数据:
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data # 特征矩阵 (150, 4)
y = iris.target # 目标标签 (150,)
# 查看特征名和类别名
print("特征名:", iris.feature_names)
# 输出:['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
print("类别名:", iris.target_names)
# 输出:['setosa' 'versicolor' 'virginica']
数据标准化与模型训练
由于特征量纲一致(均为厘米),标准化非必需,但部分模型(如 SVM、KNN)可能受益:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 训练逻辑回归模型
model = LogisticRegression(max_iter=200)
model.fit(X_train, y_train)
# 评估准确率
print("测试集准确率:", model.score(X_test, y_test))
# 输出:测试集准确率:1.0(完美分类)
主成分分析(PCA)降维
可通过 PCA 将 4 维特征降至 2 维,便于可视化:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')
plt.xlabel("主成分 1")
plt.ylabel("主成分 2")
plt.show()
关键特点
- 类别线性可分性:Iris setosa与其他两类线性可分,但versicolor和virginica存在部分重叠。
- 特征相关性:花瓣长度与宽度高度相关(相关系数>0.9),可能需处理多重共线性。
手写数字数据集(Digits)
Scikit-learn中的手写数字数据集(Digits)是一个经典的多分类数据集,广泛用于图像识别任务的入门和实践。
数据集概述
- 用途:多分类任务(识别0-9的手写数字)。
- 来源:从美国国家标准与技术研究院(NIST)的原始数据中提取并预处理。
- 特点:
- 低分辨率灰度图像(8×8像素),适合快速训练和验证模型。
- 数据已标准化(居中、去噪),无需复杂预处理。
- 类别平衡,适合作为图像分类的基准测试集。
数据结构
- 样本数量:1797个样本。
- 特征数量:64个特征(对应8×8像素的灰度值,取值范围0-16)。
- 目标类别:10类(数字0-9,每类约180个样本)。
特征说明
每个样本是一个展平的 8×8 像素矩阵,每个像素的灰度值为 0(白色)到 16(黑色)。
例如,数字 “7” 的像素矩阵可能如下(简化):
[[0. 0. 5. 13. 9. 1. 0. 0.] [0. 0. 13. 15. 10. 15. 5. 0.] [0. 3. 15. 2. 0. 11. 8. 0.] [0. 4. 12. 0. 0. 8. 8. 0.] [0. 5. 8. 0. 0. 9. 8. 0.] [0. 4. 11. 0. 1. 12. 7. 0.] [0. 2. 14. 5. 10. 12. 0. 0.] [0. 0. 6. 13. 10. 0. 0. 0.]]
目标类别
- 0~9:对应手写数字 0 到 9。
加载方法
使用 Scikit-learn 的 load_digits 函数加载数据:
from sklearn.datasets import load_digits
# 加载数据集
digits = load_digits()
X = digits.data # 特征矩阵 (1797, 64)
y = digits.target # 目标标签 (1797,)
images = digits.images # 原始图像矩阵 (1797, 8, 8)
# 查看特征名和类别名
print("目标类别:", digits.target_names.tolist()) # [0, 1, 2, ..., 9]
数据可视化
显示单个数字图像
import matplotlib.pyplot as plt
# 显示前 10 个样本
fig, axes = plt.subplots(2, 5, figsize=(10, 4))
for i, ax in enumerate(axes.flat):
ax.imshow(images[i], cmap='binary') # 使用黑白配色
ax.set_title(f"Label: {y[i]}")
ax.axis('off')
plt.show()

预处理与建模示例
数据标准化与分类
虽然像素值范围较小(0-16),但某些模型(如 SVM)可能受益于标准化:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.svm import SVC
# 将像素值归一化到 [0,1]
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, stratify=y)
# 训练 SVM 模型
model = SVC(kernel='rbf', gamma=0.001, C=10)
model.fit(X_train, y_train)
# 评估准确率
print("测试集准确率:", model.score(X_test, y_test)) # 通常可达 ~0.98
主成分分析(PCA)降维
from sklearn.decomposition import PCA
# 降至 2 维可视化
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='tab10', alpha=0.6)
plt.colorbar(ticks=range(10), label='数字')
plt.xlabel("主成分 1")
plt.ylabel("主成分 2")
plt.title("PCA 降维可视化")
plt.show()
关键特点
- 低分辨率限制:8×8 像素可能导致部分数字(如 4 和 9)边界模糊,分类难度增加。
- 适用场景:
- 验证传统机器学习模型(如 SVM、KNN、决策树)的性能。
- 教学演示图像分类流程(特征提取、模型训练、评估)。
- 扩展性不足:对于深度学习模型(如 CNN),建议使用更高分辨率的 MNIST 数据集(28×28 像素)。
威斯康星乳腺癌数据集(BreastCancer)
Scikit-learn 中的威斯康星乳腺癌数据集(BreastCancer Wisconsin Dataset)是一个经典的二分类数据集,用于预测乳腺肿瘤的恶性或良性。
数据集背景
- 来源:由威斯康星大学医院收集,基于乳腺肿块的细针穿刺(FNA)数字化图像分析。
- 历史意义:自 1990 年代起广泛用于机器学习研究,是医疗诊断领域的重要基准数据集。
- 伦理声明:数据已匿名化,不包含患者个人信息,适合学术研究。
数据结构
- 样本数量:569 个样本(良性 357 例,恶性 212 例)。
- 特征数量:30 个数值特征(由 10 个原始特征分别计算均值、标准差和最大值)。
- 目标变量:二分类标签,0 表示恶性(malignant),1 表示良性(benign)。
特征详细说明
原始测量特征(共 10 个)
每个特征通过数字化图像分析得到,描述细胞核的形态学特性:
- 半径(Radius):从中心到边缘的平均距离。
- 纹理(Texture):灰度值的标准差,反映图像局部对比度。
- 周长(Perimeter):细胞核边界的长度。
- 面积(Area):细胞核覆盖的像素面积。
- 平滑度(Smoothness):周长变化的局部差异,量化边界的光滑程度。
- 紧密度(Compactness):计算公式为 周长²/面积−1,值越大表示形状越不规则。
- 凹陷度(Concavity):轮廓凹陷部分的严重程度,反映边界凹陷的深度。
- 凹点数量(Concave Points):轮廓中凹陷区域的数量。
- 对称性(Symmetry):细胞核的对称程度。
- 分形维度(Fractal Dimension):边界复杂度的度量,值越接近 1 表示边界越接近平滑曲线。
统计量扩展
每个原始特征计算了以下 3 种统计量,形成 30 维特征:
- 均值(Mean):所有细胞核测量值的平均。
- 标准差(Standard Error):测量值的离散程度。
- 最大值(Worst):最异常(通常最大)的单个细胞核测量值。
示例特征名:mean radius, radius error, worst radius数据加载与探索
from sklearn.datasets import load_breast_cancer
# 加载数据集
cancer = load_breast_cancer()
X = cancer.data # 特征矩阵 (569, 30)
y = cancer.target # 目标标签 (569,)
# 查看元数据
print("特征名:", cancer.feature_names)
print("类别名:", cancer.target_names) # ['malignant' 'benign']
print("数据集描述:", cancer.DESCR) # 详细统计信息和背景
预处理建议
- 标准化:特征量纲差异大(如 area 范围在 143-2501,smoothness 在 0.5-0.16),需使用 StandardScaler 或 MinMaxScaler。
- 类别平衡:良性样本较多,可考虑过采样(如 SMOTE)或在训练时设置类别权重(如 class_weight=’balanced’)。
- 特征选择:高维特征可能导致过拟合,可使用:
- 单变量统计(如 ANOVA F 值)
- 递归特征消除(RFE)
- 基于模型的特征重要性(如随机森林)
关键挑战与解决方案
- 特征相关性高:如 mean radius 与 mean perimeter 高度相关(r>0.99),可通过 PCA 降维或手动剔除冗余特征。
- 类别不平衡:良性样本占比约 63%,使用分层抽样或调整模型参数(如 SVM 的 class_weight)。
- 过拟合风险:使用正则化(L1/L2)、交叉验证或简化模型复杂度。
扩展数据集
- 更大规模版本:UCI Machine Learning Repository 中的Breast Cancer Wisconsin (Diagnostic) 包含更多原始数据。
葡萄酒数据集(Wine)
Scikit-learn 中的葡萄酒数据集(Wine Dataset)是一个经典的多分类数据集,用于根据化学成分区分三种不同品种的葡萄酒。
数据集背景
- 来源:数据源自意大利同一地区种植的葡萄酿造的红酒,但来自三个不同的品种(由研究者 Forina 等人收集)。
- 用途:多分类任务(识别葡萄酒品种),适合验证分类算法(如 SVM、决策树、随机森林)。
- 特点:特征均为化学分析结果,无缺失值,适合直接用于机器学习。
数据结构
- 样本数量:178 个样本。
- 特征数量:13 个数值型特征(描述葡萄酒的化学成分)。
- 目标类别:3 种葡萄酒品种,分布如下:
- 类别 0:59 个样本
- 类别 1:71 个样本
- 类别 2:48 个样本
特征详细说明
所有特征均为连续型数值,代表葡萄酒的化学分析指标:
- Alcohol(酒精含量):体积百分比。
- Malic acid(苹果酸):苹果酸浓度(g/L)。
- Ash(灰分):高温灼烧后的无机物残留(g/L)。
- Alcalinity of ash(灰分碱度):灰分的碱度(以碳酸钾计)。
- Magnesium(镁):镁含量(mg/L)。
- Total phenols(总酚):酚类物质总量(以没食子酸计)。
- Flavanoids(类黄酮):类黄酮含量(mg/L)。
- Nonflavanoid phenols(非类黄酮酚):非类黄酮酚含量(mg/L)。
- Proanthocyanins(原花青素):原花青素浓度(mg/L)。
- Color intensity(颜色强度):颜色深浅(光学测量值)。
- Hue(色调):葡萄酒的色调(基于光谱分析)。
- OD280/OD315 of diluted wines(稀释吸光度比值):稀释后OD280与OD315的吸光度比,反映蛋白质含量。
- Proline(脯氨酸):脯氨酸含量(mg/L),一种氨基酸。
数据加载与探索
from sklearn.datasets import load_wine
# 加载数据集
wine = load_wine()
X = wine.data # 特征矩阵 (178, 13)
y = wine.target # 目标标签 (178,)
# 查看元数据
print("特征名:", wine.feature_names)
print("类别名:", wine.target_names) # ['class_0' 'class_1' 'class_2']
print("数据集描述:", wine.DESCR) # 包含详细统计信息
预处理建议
- 标准化:特征量纲差异大(如 proline 范围在 278-1680,magnesium 在 70-162),需使用 StandardScaler。
- 类别平衡:类别分布略微不均衡(类别 2 样本较少),可采用分层抽样或调整类别权重。
关键特点
- 化学特征可解释性:特征直接反映葡萄酒的化学成分,便于分析关键区分因素(如 proline 和 flavanoids)。
- 线性可分性:部分类别在 PCA 降维后呈现线性可分趋势,适合线性模型(如逻辑回归)。
- 小样本挑战:数据量较小(178 样本),需谨慎避免过拟合(如使用正则化或交叉验证)。
扩展与注意事项
- 扩展数据集:UCI 提供更详细的Wine Quality Dataset,包含红葡萄酒和白葡萄酒的感官评分。
- 注意事项:
- 避免在预处理前划分数据集以防止数据泄露。
- 对于高维特征,建议结合特征选择(如 ANOVA F 值)或降维(如 PCA)提升模型效率。
葡萄酒数据集凭借其清晰的化学特征和适中的规模,成为多分类任务的理想选择,尤其适合探索特征分析与模型解释的结合应用。
糖尿病数据集(Diabetes)
Scikit-learn 中的糖尿病数据集(Diabetes Dataset)是一个经典的回归任务数据集,用于预测糖尿病患者的疾病进展。
数据集背景
- 来源:数据源自 1990 年代的研究,旨在探索糖尿病患者的生理指标与疾病发展的关联。
- 用途:回归任务(预测糖尿病进展),适合验证回归模型(如线性回归、岭回归、随机森林回归)。
- 特点:
- 特征未标准化,需预处理。
- 无缺失值,均为数值型特征。
- 目标变量为连续值,反映疾病进展程度。
数据结构
- 样本数量:442 个患者样本。
- 特征数量:10个数值型特征(基线生理指标)。
- 目标变量:连续值(范围25-346),表示糖尿病在基线后一年内的疾病进展。
特征详细说明
所有特征均经过标准化处理(均值=0,标准差=1),但原始测量指标如下:
- Age(年龄):患者的年龄(岁)。
- Sex(性别):0表示女性,1表示男性。
- BMI(身体质量指数):体重(kg)除以身高(m)的平方。
- BP(平均血压):平均动脉压(mmHg)。
- S1(血清测定1):总胆固醇(TC,mg/dL)。
- S2(血清测定2):低密度脂蛋白(LDL,mg/dL)。
- S3(血清测定3):高密度脂蛋白(HDL,mg/dL)。
- S4(血清测定4):总胆固醇/HDL比值。
- S5(血清测定5):可能为甘油三酯(对数转换值)。
- S6(血清测定6):血糖水平(mg/dL)。
目标变量
- 疾病进展指标:基于基线后一年内患者的疾病发展评估,值越大表示病情恶化越严重。
数据加载与探索
from sklearn.datasets import load_diabetes
# 加载数据集
diabetes = load_diabetes()
X = diabetes.data # 特征矩阵 (442, 10)
y = diabetes.target # 目标变量 (442,)
# 查看元数据
print("特征名:", diabetes.feature_names)
print("数据集描述:", diabetes.DESCR) # 包含详细统计信息
预处理建议
- 标准化:虽然特征已中心化,但不同特征的尺度可能仍需调整(如使用StandardScaler)。
- 特征工程:探索交互项(如 BMI × 血压)或多项式特征。
- 特征选择:通过相关系数或 Lasso 回归筛选重要特征。
关键挑战与解决方案
- 低解释方差:R² 通常较低(约 4-0.5),表明需更复杂模型(如梯度提升树)或引入额外特征。
- 共线性问题:血清指标(S1-S6)可能存在相关性,可通过 VIF 检测或使用正则化模型(如岭回归)。
- 小样本限制:使用交叉验证(如 5 折)优化超参数,避免过拟合。
大型下载数据集(Real-World Datasets)
特点:数据量较大,首次使用需从网络下载,缓存到本地。
使用 fetch_* 函数加载(首次使用需下载):
加州房价数据集(California Housing)
Scikit-learn 中的加州房价数据集(California Housing Dataset)是一个经典的回归任务数据集,用于预测美国加利福尼亚州各区域的房屋价格中位数。
数据集概述
- 来源:基于 1990 年美国人口普查数据,由美国人口普查局(S. Census Bureau)收集。
- 用途:回归任务(预测房价),适合验证回归模型(如线性回归、梯度提升树、神经网络)。
- 特点:
- 包含地理和社会经济特征。
- 数据规模较大(约 2 万样本),适合训练复杂模型。
- 无缺失值,特征已部分预处理。
数据结构
- 样本数量:20,640 个区域(样本)。
- 特征数量:8 个数值型特征。
- 目标变量:连续值,表示区域内房屋价格中位数(单位:10 万美元)。
特征详细说明
所有特征均为数值型,描述地理和人口统计信息:
- MedInc(收入中位数):区域内家庭收入中位数(单位:万美元)。
- HouseAge(房龄中位数):房屋年龄中位数(单位:年)。
- AveRooms(平均房间数):每户平均房间数。
- AveBedrms(平均卧室数):每户平均卧室数。
- Population(人口):区域内人口总数。
- AveOccup(平均入住率):每户平均居住人数。
- Latitude(纬度):区域中心的纬度。
- Longitude(经度):区域中心的经度。
目标变量
- MedHouseVal(房价中位数):标化后的房屋价格中位数(范围 0-5,对应 0-50 万美元)。
数据加载与探索
from sklearn.datasets import fetch_california_housing
# 加载数据集
housing = fetch_california_housing()
X = housing.data # 特征矩阵 (20640, 8)
y = housing.target # 目标变量 (20640,)
# 查看元数据
print("特征名:", housing.feature_names)
print("数据集描述:", housing.DESCR) # 包含详细统计信息
预处理建议
- 标准化/归一化:特征量纲差异大(如 Population 范围 0-35,682,MedInc 0-15),需使用 StandardScaler。
- 地理特征工程:
- 将经纬度转换为区域编码(如 K-Means 聚类)。
- 计算到海岸线或城市的距离(需外部数据)。
- 处理偏态分布:对右偏特征(如 Population)进行对数转换。
关键挑战与解决方案
- 高维度与稀疏性:地理特征(经纬度)直接使用效果有限,可转换为空间聚类或距离特征。
- 非线性关系:使用树模型(如 GBDT)或引入多项式特征(如 MedInc²)。
- 数据时效性:1990 年数据已过时,可通过外部数据(如 Zillow API)获取最新房价。
扩展与注意事项
- 扩展数据集:
- 通过 fetch_openml(name=’california_housing’) 获取更详细的版本(包含更多特征)。
- 结合外部数据(如犯罪率、学校评分)提升预测精度。
- 注意事项:
- 避免将经纬度直接输入线性模型(需转换为空间特征)。
- 目标变量已截断(最高为 0),需注意模型预测值的范围限制。
Olivetti 人脸数据集
Scikit-learn 中的 Olivetti 人脸数据集(Olivetti Faces Dataset)是一个经典的人脸识别数据集,常用于图像分类、降维和聚类任务。
数据集概述
- 来源:由剑桥大学 AT&T 实验室收集,包含 40 位志愿者的面部图像。
- 用途:人脸识别、图像降维(如 PCA、LDA)、小样本学习。
- 特点:
-
- 小样本但高维度:每位志愿者仅 10 张图像,但每张图像为 64×64 像素(4096 维)。
灰度图像,背景统一,适合快速验证算法。
-
- 同一人物的图像包含不同表情、光照和面部细节变化。
数据结构
- 样本数量:400 张图像(40 人 × 10 张)。
- 特征数量:4096 个特征(64×64 像素的灰度值,范围 0-1)。
- 目标变量:40 个类别(0-39,每位志愿者对应一个类别)。
数据示例
图像内容
- 人物:40 位不同志愿者(20-50 岁,混合性别)。
- 拍摄条件:
- 表情:自然、微笑、惊讶等。
- 姿态:轻微头部转动。
- 光照:部分图像存在明暗变化。
- 细节:是否佩戴眼镜(部分人物)。
数据格式
- 每张图像被展平为一维向量(64×64=4096维),例如:
# 加载数据集后,获取第一张图像 image_sample = olivetti.images[0] # 形状(64,64) flattened_sample = olivetti.data[0] # 形状(4096,)
数据加载与探索
from sklearn.datasets import fetch_olivetti_faces
# 加载数据集(首次使用需下载)
olivetti = fetch_olivetti_faces()
X = olivetti.data # 特征矩阵(400,4096)
y = olivetti.target # 目标标签(400,)
images = olivetti.images # 原始图像矩阵(400,64,64)
# 查看元数据
print("目标类别数:", len(np.unique(y))) # 40
print("图像分辨率:", images[0].shape) # (64,64)
数据可视化
显示同一人物的多张图像
import matplotlib.pyplot as plt
# 选择第5位志愿者的所有图像(标签为4)
person_id = 4
person_images = images[y == person_id]
# 绘制前5张图像
fig, axes = plt.subplots(1,5, figsize=(12,3))
for i, ax in enumerate(axes):
ax.imshow(person_images[i], cmap='gray')
ax.axis('off')
ax.set_title(f"Person {person_id}")
plt.show()
预处理建议
- 标准化:像素值已归一化到[0,1],无需额外处理。
- 降维:使用PCA或LDA减少4096维特征,提升计算效率。
- 数据增强:对小样本(每人10张)应用旋转、平移或噪声注入(需手动扩展)。
关键挑战与解决方案
- 小样本问题:每人仅10张图像,可结合迁移学习(如VGG-Face预训练模型)。
- 高维度灾难:使用PCA将4096维降至50-100维,再输入传统分类器。
- 类内差异:同一人物的表情和姿态变化需模型具备鲁棒性,可引入数据增强或注意力机制。
注意事项
- 数据规模限制:400样本仅适合教学和小规模实验,工业级应用需更大数据集(如LFW、CelebA)。
- 图像分辨率:64×64像素较低,无法捕捉细节,可尝试超分辨率重建预处理。
- 隐私保护:尽管数据已匿名,实际应用中需遵守隐私法规。
Olivetti人脸数据集为入门级人脸识别任务提供了便捷的实验平台,尤其适合验证特征提取与降维技术的有效性。其简洁的结构和明确的类别划分,使其成为图像处理与模式识别教学的经典案例。
20类新闻文本数据集(20Newsgroups)
Scikit-learn中的20类新闻文本数据集(20Newsgroups)是一个经典的文本分类数据集,广泛用于自然语言处理(NLP)任务。
数据集概述
- 来源:收集自20个不同主题的新闻组(Usenet讨论组),涵盖技术、科学、娱乐等多个领域。
- 用途:文本分类、主题建模、信息检索、迁移学习(如预训练模型微调)。
- 特点:
- 纯英文文本,包含邮件头(发件人、主题等)和正文。
- 原始文本未预处理,需进行分词、去噪等操作。
- 提供训练集和测试集的预设划分,适合基准测试。
数据结构
- 样本数量:共约18,846篇文档(实际数量因版本和参数而异)。
- 类别数量:20个主题,每个主题约600-1,000篇文档。
- 数据划分:
- 训练集:约11,314篇文档。
- 测试集:约7,532篇文档。
- 类别示例:graphics, rec.sport.baseball, sci.med, talk.politics.mideast, alt.atheism。
数据加载与探索
from sklearn.datasets import fetch_20newsgroups
# 加载训练集和测试集(全类别)
news_train = fetch_20newsgroups(subset='train', shuffle=True, random_state=42)
news_test = fetch_20newsgroups(subset='test', shuffle=True, random_state=42)
X_train, y_train = news_train.data, news_train.target
X_test, y_test = news_test.data, news_test.target
# 查看类别名
print("类别名:", news_train.target_names)
参数说明
-
- subset: ‘train’(训练集)、’test’(测试集)或’all’(合并所有数据)。
- categories: 指定加载的类别列表(默认加载全部20类)。
remove: 去除邮件头中的特定部分(如 (‘headers’, ‘footers’, ‘quotes’))。
数据示例
# 打印第一篇训练文档的文本和类别
print("文本内容:\n", X_train[0][:500]) # 显示前500字符
print("类别ID:", y_train[0])
print("类别名:", news_train.target_names[y_train[0]])
输出示例:
From: lerxst@wam.umd.edu (where's my thing) Subject: WHAT car is this!? Nntp-Posting-Host: rac3.wam.umd.edu Organization: University of Maryland, College Park Lines: 15 I was wondering if anyone out there could enlighten me on this car I saw the other day. It was a 2-door sports car, looked to be from the late 60s/ early 70s. It was called a Bricklin. The doors were really small. In addition, the front bumper was separate from the rest of the body. This is ... 类别ID:6 类别名:rec.autos
预处理与特征工程
预处理步骤
- 去除噪声:
- 删除邮件头、签名、引用(remove=(‘headers’, ‘footers’, ‘quotes’))。
- 移除标点、数字、特殊字符。
- 分词与词干提取:
from nltk.stem import PorterStemmer
from nltk.tokenize import word_tokenize
stemmer = PorterStemmer()
def preprocess(text):
tokens = word_tokenize(text.lower()) # 小写化并分词
tokens = [stemmer.stem(t) for t in tokens if t.isalpha()] # 仅保留字母词并词干提取
return ' '.join(tokens)
- 停用词过滤:使用 corpus.stopwords 或 sklearn 内置停用词表。
- 向量化(文本转数值特征)
from sklearn.feature_extraction.text import TfidfVectorizer # 使用 TF-IDF 转换(限制最大特征数) vectorizer = TfidfVectorizer(max_features=10_000, stop_words='english') X_train_tfidf = vectorizer.fit_transform(X_train) X_test_tfidf = vectorizer.transform(X_test)
挑战与解决方案
- 类别不平衡:使用 class_weight=’balanced’ 或过采样(如 SMOTE)。
- 高维稀疏特征:使用 TruncatedSVD 或 NMF 降维。
- 文本噪声:结合正则表达式和 NLP 工具包(如 nltk、spaCy)清洗数据。
注意事项
- 版本差异:不同 Scikit-learn 版本的数据划分可能略有不同,建议固定随机种子。
- 计算资源:TF-IDF 转换后特征维度高(数万维),需注意内存消耗。
- 语言限制:仅支持英文,处理其他语言需额外预处理。
20类新闻文本数据集为文本分类任务提供了标准化的实验平台,尤其适合探索从原始文本到分类模型的端到端流程。其多样的主题和真实的文本噪声,使其成为 NLP 研究和教学的理想选择。
MNIST 手写数字数据集
Scikit-learn 中的 MNIST 手写数字数据集(MNIST Dataset)是一个经典的图像分类数据集,广泛用于验证机器学习模型(尤其是深度学习模型)在图像识别任务中的性能。
数据集概述
- 来源:由美国国家标准与技术研究院(NIST)收集,包含手写数字的灰度图像。
- 用途:图像分类(识别 0-9 手写数字)、降维、生成对抗网络(GAN)训练。
- 特点:
- 高分辨率(相比 Scikit-learn 内置的 Digits 数据集):28×28 像素。
- 样本量大,包含训练集和测试集的官方划分。
- 数据已标准化(居中、去噪),适合直接使用。
数据结构
- 样本数量:70,000 张图像。
- 训练集:60,000 张。
- 测试集:10,000 张。
- 特征数量:784 个特征(28×28 像素展平后的灰度值,范围 0-255)。
- 目标变量:10 类(数字 0-9)。
数据加载与探索
MNIST 未直接集成在 Scikit-learn 的 datasets 模块中,但可通过 fetch_openml 加载:
from sklearn.datasets import fetch_openml
# 加载MNIST数据集(首次使用需下载)
mnist = fetch_openml('mnist_784', version=1, as_frame=False)
X = mnist.data # 特征矩阵 (70000, 784)
y = mnist.target.astype(int) # 目标标签 (70000,)
# 查看数据形状
print("特征维度:", X.shape) # (70000, 784)
print("目标类别:", np.unique(y)) # [0 1 2 3 4 5 6 7 8 9]
数据划分
# 官方训练集和测试集划分 X_train, X_test = X[:60000], X[60000:] y_train, y_test = y[:60000], y[60000:]
数据可视化
显示单个数字图像
import matplotlib.pyplot as plt
# 显示第5个训练样本
digit_image = X_train[4].reshape(28, 28)
plt.imshow(digit_image, cmap='binary')
plt.title(f"Label: {y_train[4]}")
plt.axis('off')
plt.show()

预处理建议
归一化:将像素值从0-255缩放到0-1:
X_train_scaled = X_train / 255.0 X_test_scaled = X_test / 255.0
数据增强(针对深度学习):随机旋转、平移、缩放(需使用 tensorflow 或 keras 工具)。
关键挑战与解决方案
- 相似数字混淆(如 4/9、5/3):
-
- 使用数据增强生成更多样本。
- 改进模型结构(如引入残差连接)。
- 过拟合:
- 添加 Dropout 层或 L2 正则化。
- 计算资源限制:
- 使用轻量级模型(如 LeNet-5)或迁移学习。
扩展数据集
- Fashion-MNIST:替代 MNIST 的 10 类服装图像数据集(相同格式)。
- EMNIST:扩展 MNIST,包含字母和数字。
- KMNIST:日文手写字符数据集。
注意事项
- 数据泄露:使用官方划分的训练集和测试集,避免自定义划分。
- 性能天花板:传统模型(如 SVM)准确率约 95-98%,CNN 可达 5% 以上,剩余错误多为模糊书写。
MNIST 手写数字数据集是机器学习领域的“Hello World”,凭借其简洁的结构和丰富的应用场景,成为算法验证和教育的最佳选择。尽管现代研究已转向更复杂的数据集(如 CIFAR-10、ImageNet),MNIST 仍为理解图像处理基础提供了不可替代的价值。
生成模拟数据集(Synthetic Datasets)
特点:按需生成可控数据,适用于算法测试。
Scikit-learn(sklearn)提供了多种生成模拟数据集的方法,适用于分类、回归、聚类、降维等任务。这些数据集便于算法测试、模型调试和教学示例。
分类数据集
make_classification
生成适用于分类的多维数据集,可控制类别间分离度、特征类型等。
参数:
- n_samples: 样本数(默认 100)
- n_features: 特征数(默认 20)
- n_informative: 有效特征数(默认 2)
- n_redundant: 冗余特征数(默认 2,由有效特征线性组合生成)
- n_classes: 类别数(默认 2)
- random_state: 随机种子
示例:
from sklearn.datasets import make_classification X, y = make_classification(n_samples=100, n_features=4, n_classes=2, random_state=42)
make_blobs
生成各向同性高斯分布的聚类数据,适用于聚类和分类。
参数:
- centers: 中心点数量或坐标
- cluster_std: 簇的标准差
示例:
from sklearn.datasets import make_blobs X, y = make_blobs(n_samples=100, centers=3, n_features=2, random_state=42)
非线性数据集
make_circles 和make_moons: 生成环形或半月形数据,测试非线性分类器。
from sklearn.datasets import make_circles, make_moons X_circle, y_circle = make_circles(n_samples=100, noise=0.1, factor=0.5) X_moon, y_moon = make_moons(n_samples=100, noise=0.1)
回归数据集
make_regression
生成回归模型数据,可控制噪声、有效特征等。
参数:
- n_targets: 目标变量数
- noise: 噪声标准差
示例:
from sklearn.datasets import make_regression X, y = make_regression(n_samples=100, n_features=3, noise=0.5)
聚类数据集
make_blobs
(同上,常用于 K-means 等聚类算法)
make_s_curve
生成 S 型曲线,用于流形学习。
示例:
from sklearn.datasets import make_s_curve X, t = make_s_curve(n_samples=100, noise=0.1)
多标签与多输出
make_multilabel_classification
生成多标签分类数据。
参数:
- n_labels: 每个样本的标签数
示例:
from sklearn.datasets import make_multilabel_classification X, y = make_multilabel_classification(n_samples=100, n_features=5, n_classes=3)
其他数据集
make_sparse_uncorrelated
生成稀疏且无相关性的回归数据。
make_biclusters
生成双聚类数据。
使用场景与建议
- 测试模型: 快速验证算法在特定数据分布下的表现。
- 教学演示: 直观展示不同算法(如 SVM、决策树)如何处理线性/非线性数据。
- 参数调整: 通过调整噪声、特征数量等,研究模型鲁棒性。
数据集对象结构
加载后的数据集返回一个 Bunch 对象(类似字典),包含以下键:
- data:特征数据(NumPy 数组或 SciPy 稀疏矩阵)。
- target:标签数据(分类/回归目标)。
- feature_names:特征名称列表(如鸢尾花的[‘sepal length(cm)’,…])。
- target_names:类别名称列表(如鸢尾花的[‘setosa’,’versicolor’,’virginica’])。
- DESCR:数据集的完整描述文本。
示例:转换为 Pandas DataFrame
import pandas as pd iris = load_iris() df = pd.DataFrame(iris.data, columns=iris.feature_names) df['target'] = iris.target #添加标签列 df['species'] = df['target'].apply(lambda x: iris.target_names[x]) print(df.head())
核心 API 方法
加载函数
- load_*:加载小型内置数据集(如 load_iris)。
- fetch_*:下载大型数据集(如 fetch_california_housing)。
- make_*:生成模拟数据(如 make_moons 生成月牙形聚类数据)。
参数说明
- return_X_y:直接返回 (data, target) 而非 Bunch 对象。
X, y = load_iris(return_X_y=True)
- as_frame:将 data 和 target 转为 Pandas DataFrame(要求数据集支持)。
housing = fetch_california_housing(as_frame=True) X_df = housing.frame # 获取完整 DataFrame
注意事项
- 数据集缓存路径:下载的数据集默认保存在 ~/scikit_learn_data,可通过 SKLEARN_DATA 环境变量修改。
- 伦理数据集:部分数据集(如波士顿房价)因伦理争议已弃用,建议使用替代数据。
- 数据预处理:生成的数据默认无缺失值,但真实数据集可能需要处理缺失或标准化。


