scikit-learn-extra简介 scikit-learn-extra 是 scikit-learn 的一个官方扩展工具包,专为提供那些新颖、专用或尚未纳入主库的机器学习算法而设计。它完全兼容 scikit-learn 的 API 规范,让你能在熟悉的生态里,…

Mlxtend 简介 Mlxtend 是一个Python开源库,全称为 “machine learning extensions”(机器学习扩展)。由 Sebastian Raschka 创建并维护,其核心目标是提供一系列在日常数据科学和机器学习任务中非常实用的工具和扩…
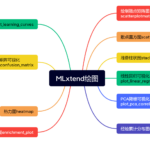
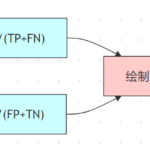
先前按照Scikit-Learn的文档整理了一份评估指标,回头看下梳理的非常的技术化,整理完有种自己都不太想看的感觉。今天抽时间再做一次重新的梳理。 分类任务评估指标 混淆矩阵(Confusion Matrix) 分类任务的基…
ColumnTransformer 是 scikit-learn 中用于对数据的不同列应用不同预处理步骤的工具,特别适用于处理包含混合类型特征(如数值型、分类型、文本型)的数据集。 ColumnTransformer核心功能与使用场景 核心功能…
超参数调优是机器学习模型开发的核心步骤,直接影响模型性能。scikit-learn 提供多种工具帮助高效优化参数。 GridSearchCV Scikit-Learn 的 GridSearchCV 是一种通过穷举参数组合并交叉验证评估性能的超参数…

类别不平衡是分类任务中常见的问题,即某些类别的样本数量显著少于其他类别。除了前面介绍的imbalanced-learn库以外,还能使用class_weight参数进行处理。 class_weight与imbalanced-learn的对比 核心定义与…

Scikit-Learn 提供了多种特征选择方法,主要分为以下几类,结合具体场景和算法特性进行选择: 过滤法 (Filter Methods) 基于统计指标评估特征重要性,独立于模型。 方差阈值 (Variance Threshold) 方差阈值…

sklearn.datasets 是 scikit-learn 中用于加载和生成数据集的工具模块,内置了多种经典数据集和灵活的数据生成方法,适合快速实验和算法验证。 内置数据集类型 模块中的数据集分为三类,通过不同函数加载: …

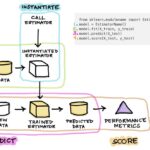
scikit-learn 的核心 API 设计以一致性和模块化为核心,所有功能模块遵循统一的接口规范,使得数据预处理、模型训练、评估和部署流程高度标准化。 API 设计原则 一致性接口:所有估计器(模型、预处理工具)均…
Scikit-Learn 的 sklearn.preprocessing 模块提供了一系列数据预处理工具,帮助将原始数据转换为适合机器学习模型的形式。 缺失值处理 在 scikit-learn 中,缺失值处理是数据预处理的关键步骤之一。大多数机器学…






