文章内容如有错误或排版问题,请提交反馈,非常感谢!
scikit-learn 的核心 API 设计以一致性和模块化为核心,所有功能模块遵循统一的接口规范,使得数据预处理、模型训练、评估和部署流程高度标准化。
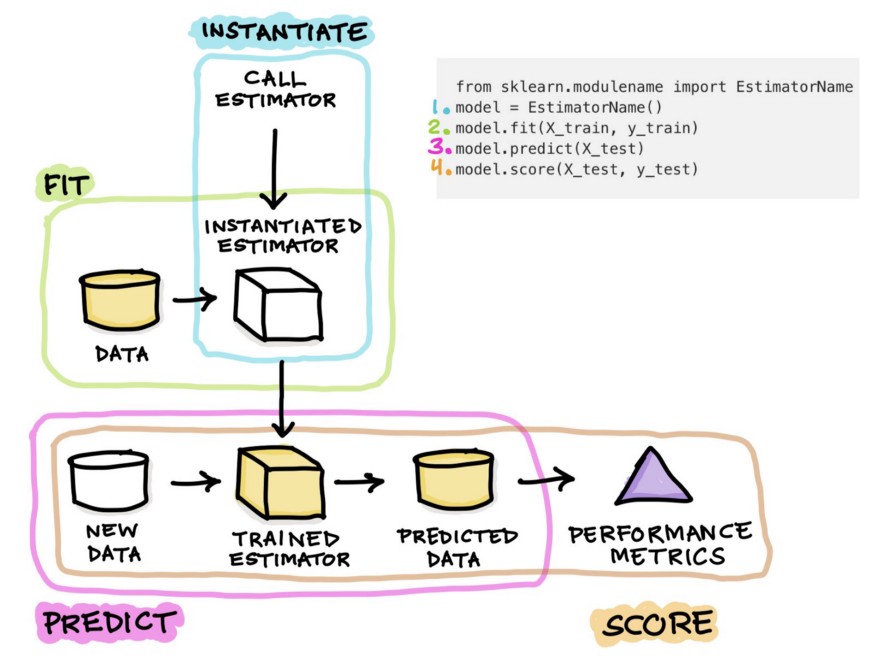
API 设计原则
- 一致性接口:所有估计器(模型、预处理工具)均实现以下方法:
- fit():训练模型或计算数据转换参数(如均值、方差)。
- predict():生成预测结果(监督学习模型)。
- transform():应用数据转换(如标准化、编码)。
- score():评估模型性能(如准确率、R² 分数)。
- 模块化组合:通过 Pipeline 和 ColumnTransformer 将多个步骤组合为单一工作流。
- 明确的参数管理:通过 get_params() 和 set_params() 动态调整参数。
核心模块与接口
估计器(Estimators)
所有功能模块的基类,分为以下类型:
监督学习模型(实现 fit 和 predict):
from sklearn.ensemble import RandomForestClassifier model = RandomForestClassifier(n_estimators=100) model.fit(X_train, y_train) # 训练 y_pred = model.predict(X_test) # 预测
无监督学习模型(实现 fit 和 predict 或 fit_predict):
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3) labels = kmeans.fit_predict(X) # 训练并预测簇标签
数据转换器(实现 fit 和 transform):
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_scaled = scaler.fit_transform(X) # 拟合并转换数据
元估计器(Meta-Estimators)
组合多个估计器以构建复杂流程:
Pipeline(管道):
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('scaler', StandardScaler()),
('classifier', LogisticRegression())
])
pipeline.fit(X_train, y_train) # 自动依次执行所有步骤
GridSearchCV(网格搜索调参):
from sklearn.model_selection import GridSearchCV
param_grid = {'classifier__C': [0.1, 1, 10]}
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)
评估工具
模型评估指标:
from sklearn.metrics import accuracy_score, confusion_matrix accuracy = accuracy_score(y_test, y_pred) cm = confusion_matrix(y_test, y_pred)
交叉验证:
from sklearn.model_selection import cross_val_score scores = cross_val_score(model, X, y, cv=5)
核心方法详解
fit() 方法
作用:从数据中学习参数(如模型的权重、预处理器的均值/方差)。
调用链:
- 预处理器的 fit() 仅计算参数(如 StandardScaler 的均值和标准差)。
- 模型的 fit() 根据输入数据优化模型参数。
transform() 方法
作用:应用数据转换(必须已调用 fit())。
示例:
# 标准化数据 scaler.fit(X_train) X_train_scaled = scaler.transform(X_train) X_test_scaled = scaler.transform(X_test) # 使用训练集的参数
predict() 方法
作用:用训练好的模型生成预测结果。
限制仅监督学习模型和部分聚类模型(如 KMeans)支持。
score() 方法
作用:返回模型的评估分数(如分类器的准确率、回归器的 R²)。
自定义评分:
from sklearn.metrics import make_scorer custom_scorer = make_scorer(my_custom_metric)
常用属性
模型参数
- 获取参数:get_params()
- 设置参数:set_params(n_estimators=200)
训练结果
- 线性模型权重:coef_
- 树模型特征重要性:feature_importances_
- 聚类中心:cluster_centers_
实用工具
数据工具
数据集加载:
from sklearn.datasets import load_iris iris = load_iris() X, y = iris.data, iris.target
数据拆分
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
模型持久化
保存/加载模型:
import joblib
joblib.dump(model, 'model.pkl')
loaded_model = joblib.load('model.pkl')
自定义估计器
通过继承 BaseEstimator 和 TransformerMixin 创建自定义转换器:
from sklearn.base import BaseEstimator, TransformerMixin
class MyTransformer(BaseEstimator, TransformerMixin):
def __init__(self, param=1):
self.param = param
def fit(self, X, y=None):
#计算必要参数
return self
def transform(self, X):
#应用转换
return X_transformed
#在 Pipeline 中使用
pipeline = Pipeline([('custom', MyTransformer()), ('model', LogisticRegression())])
最佳实践
- 统一接口优势:快速切换不同模型/预处理方法,代码高度可复用。
- 避免数据泄露:始终在训练集上调用 fit(),测试集仅用 transform() 或 predict()。
- 调试 Pipeline:通过 set_params 或 named_steps 访问中间步骤:
pipeline.named_steps['scaler'].mean_ #获取标准化器的均值
通过掌握这些核心 API,你可以高效构建机器学习流程,快速实验不同算法组合,并确保代码的简洁与可维护性。


