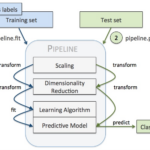
Scikit-Learn的Pipeline是一个工具,可以将多个数据预处理和建模步骤连接起来,形成一个完整的机器学习工作流。它允许用户通过链式执行多个转换步骤并最终拟合一个模型,从而使代码更加简洁。 流水线的基本结构 …
在 scikit-learn 中,要对一个拟合好的模型进行评估,有三种方法: 使用各种 estimator 自带的 score 方法。一般来说,分类器的默认评估指标是正确率(accuracy),回归器的是拟合优度(R 方)。 使用模型评估工…
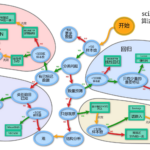
交叉验证方法盘点 在机器学习中,常见有的交叉验证方法有留出法(Holdout cross validation)和k折交叉验证(k-fold cross validation)等,除此之外还有留一法(Leave-One-Out,LOO)、留P法(Leave-P-Out,LPO)…

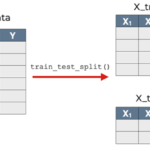
监督机器学习的关键方面之一是模型评估和验证。当您评估模型的预测性能时,过程必须保持公正。为了制作训练数据(training samples)和测试数据(testing samples),常使用 sklearn 里面的 sklearn.model_selectio…