Scikit-Learn的Pipeline是一个工具,可以将多个数据预处理和建模步骤连接起来,形成一个完整的机器学习工作流。它允许用户通过链式执行多个转换步骤并最终拟合一个模型,从而使代码更加简洁。
流水线的基本结构
在scikit-learn中,Pipeline由多个步骤组成,每个步骤都是一个元组(name, transform),其中name为步骤名称,transform为要执行的转换对象。这些元组按照顺序组成了流水线,最后一个元组的transform对象是一个机器学习模型。
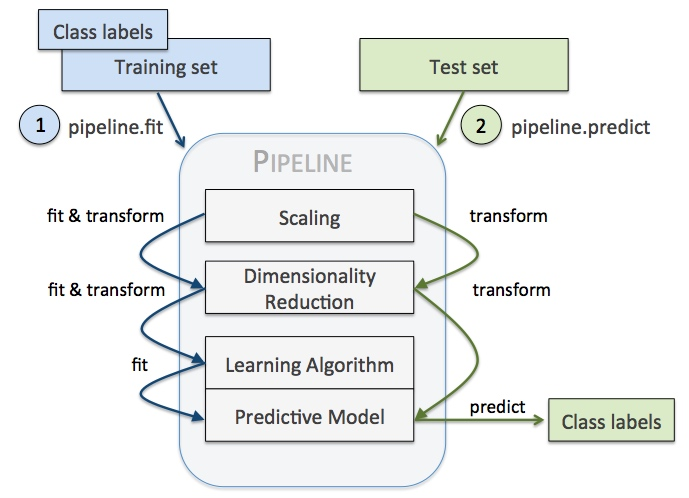
例如我们需要做如下操作,可以看出有很多重复代码:
vect = CountVectorizer() tfidf = TfidfTransformer() clf = SGDClassifier() vX = vect.fit_transform(Xtrain) tfidfX = tfidf.fit_transform(vX) predicted = clf.fit_predict(tfidfX) # Now evaluate all steps on test set vX = vect.fit_transform(Xtest) tfidfX = tfidf.fit_transform(vX) predicted = clf.fit_predict(tfidfX)
利用pipeline,上面代码可以抽象为:
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', SGDClassifier()),
])
predicted = pipeline.fit(Xtrain).predict(Xtrain)
predicted = pipeline.predict(Xtest)
注意,pipeline最后一步如果有predict()方法我们才可以对pipeline使用fit_predict(),同理,最后一步如果有transform()方法我们才可以对pipeline使用fit_transform()方法。
Pipeline 的核心优势
避免数据泄露(Data Leakage)
问题:若预处理步骤(如标准化、填充缺失值)直接在完整数据集上进行,会导致测试集信息“泄露”到训练过程,模型评估结果虚高。
Pipeline 的解决:在交叉验证或训练集/测试集划分后,自动确保预处理步骤仅在训练数据上拟合(fit),再应用到测试数据(transform),避免泄露。
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 错误做法:先标准化整个数据集再划分训练测试集
# X_scaled = StandardScaler().fit_transform(X) # 泄露测试集信息!
# 正确做法:Pipeline 封装标准化和模型
pipeline = Pipeline([
('scaler', StandardScaler()),
('model', LogisticRegression())
])
scores = cross_val_score(pipeline, X, y, cv=5) # 自动正确处理数据分割
代码简洁性与可维护性
问题:手动管理多个步骤(如缺失值填充 → 编码 → 标准化 → 训练模型)导致代码冗长且易出错。
Pipeline 的解决:将多步骤封装为单一对象,简化代码逻辑。
# 未使用Pipeline的代码(繁琐)
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
model = LogisticRegression().fit(X_train_scaled, y_train)
X_test_scaled = scaler.transform(X_test)
y_pred = model.predict(X_test_scaled)
# 使用Pipeline后的代码(简洁)
pipeline = Pipeline([('scaler', StandardScaler()), ('model', LogisticRegression())])
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
统一调参:优化全流程超参数
问题:预处理参数(如标准化是否带均值)和模型参数(如 SVM 的 C)需分别调优,无法联合优化。
Pipeline 的解决:通过 GridSearchCV 或 RandomizedSearchCV 同时调优所有步骤的参数。
from sklearn.model_selection import GridSearchCV
param_grid = {
'scaler__with_mean': [True, False], # 标准化器参数
'model__C': [0.1, 1, 10] # 模型参数
}
grid_search = GridSearchCV(pipeline, param_grid, cv=5)
grid_search.fit(X_train, y_train)
支持复杂特征处理流程
问题:数据包含数值型、分类型、文本型特征,需对不同类型列应用不同预处理。
Pipeline 的解决:结合 ColumnTransformer 分别处理各列,确保流程自动化。
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
preprocessor = ColumnTransformer([
('num', StandardScaler(), ['age', 'income']),
('cat', OneHotEncoder(), ['gender', 'city'])
])
pipeline = Pipeline([
('preprocessor', preprocessor),
('model', RandomForestClassifier())
])
便捷的中间结果访问与调试
问题:多步骤流程中,需验证某一步骤的输出(如编码后的特征是否符合预期)。
Pipeline 的解决:通过 named_steps 属性直接访问任意中间步骤。
pipeline.fit(X_train, y_train) encoded_features = pipeline.named_steps['preprocessor'].transform(X_train) # 获取预处理后的数据
Pipeline 的适用场景
端到端模型部署
将预处理和模型打包为单一对象,简化部署代码:
import joblib
joblib.dump(pipeline, 'model.pkl') # 保存完整流程
loaded_pipeline = joblib.load('model.pkl') # 加载后直接使用
自动化机器学习(AutoML)
在 AutoML 框架中,Pipeline 可自动组合不同预处理和模型算法。
学术研究与可复现性
通过固定随机种子(random_state)和 Pipeline 步骤,确保实验可复现。
Pipeline 的核心价值
| 优势 | 解决的问题 | 应用效果 |
| 避免数据泄露 | 交叉验证或测试集中的信息污染 | 提升模型评估的可靠性 |
| 简化代码逻辑 | 多步骤手动管理的复杂性 | 代码更简洁、易读、易维护 |
| 统一超参数调优 | 预处理与模型参数无法联合优化 | 提升模型性能 |
| 处理复杂特征类型 | 混合类型特征需差异化处理 | 确保每列处理逻辑正确 |
| 支持部署与调试 | 中间结果难以访问或验证 | 方便调试和结果分析 |
何时不需要使用 Pipeline?
- 单一步骤任务:若仅需单一模型(如直接调用fit(X, y)),无需预处理。
- 非结构化数据:如图像、语音等需自定义处理流程的数据,可能需结合其他工具(如 TensorFlow Data API)。
Pipeline 的使用
Pipeline实例讲解
以下代码创建了一个简单的Pipeline,该流水线首先对输入数据进行特征缩放,然后使用支持向量机算法进行分类:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
pipeline = Pipeline([
('scaler', StandardScaler()),
('svm', SVC())
])
在上面的代码中,StandardScaler和SVC均为scikit-learn提供的预定义类。第一个步骤将输入数据进行标准化处理,第二个步骤则调用支持向量机算法进行分类。注意,每个步骤的名称’scaler’和’svm’可以随意指定,但必须唯一。
步骤:Transformers和Estimators
在scikit-learn中,流水线中的每个步骤都必须是一个Transformer或Estimator对象。
- Transformer对象接受输入,并对其进行某种形式的转换,生成输出;例如,StandardScaler用于将数据集的每个特征缩放到零均值和单位方差。其他常见的变换包括对数据进行编码(例如one-hot编码)和填充缺失值。
- Estimator对象通过拟合数据集来生成一个预测模型,即机器学习模型;例如,SVC就是一个Estimator,可以通过训练数据来生成支持向量机分类器。
![]()
流水线的参数
对于每个步骤,可以使用以下语法设置参数:
(name, Transformer(**params))
其中params是一个字典,包含要传递给Transformer的超参数。例如:
from sklearn.impute import SimpleImputer
pipeline = Pipeline([
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler()),
('svm', SVC(C=1.0))
])
在上述代码中,SimpleImputer被添加为流水线的第一个步骤,并且带有一个名为strategy的超参数,它的值为’median’。这告诉SimpleImputer使用中位数填充缺失值。
将流水线应用于数据
流水线的主要目的是使模型开发者能够轻松地将多个步骤组合在一起,以便进行数据预处理、特征提取和模型拟合等操作。当流水线构建好后,可以调用其fit()方法将其应用于数据,如下所示:
pipeline.fit(X_train, y_train)
在上述代码中,X_train是输入特征变量的训练集,y_train是相应的训练标签。调用fit()方法将沿着流水线执行每个步骤,直到最后一个步骤完成模型拟合。
对于测试数据,可以使用predict()方法进行预测:
y_pred = pipeline.predict(X_test)
流水线的交叉验证
Pipeline结合cross_val_score和GridSearchCV等函数,可实现快速有效的模型选择和调参。例如,以下代码展示了如何使用交叉验证选择最佳正则化超参数C:
from sklearn.model_selection import GridSearchCV
param_grid = {
'svm__C': [0.1, 1, 10],
}
grid_search = GridSearchCV(pipeline, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(grid_search.best_params_)
在上述代码中,网格搜索通过遍历不同的正则化超参数值[0.1,1,10],选择在交叉验证期间得分最高的超参数值。此处需要注意的是,由于正则化参数C定义在流水线的svm步骤中,因此在param_grid中需要将超参数命名为’svm__C’。
Pipeline与ColumnTransformer结合
当需要针对不同列应用不同预处理时,需结合ColumnTransformer:
示例:混合类型数据处理
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
# 定义不同列的预处理
preprocessor = ColumnTransformer(
transformers=[
('num', SimpleImputer(strategy='median'), ['age', 'income']), # 数值列填充中位数
('cat', OneHotEncoder(), ['gender', 'city']) # 分类型列做One-Hot编码
])
# 整合到Pipeline
pipeline = Pipeline([
('preprocessor', preprocessor),
('scaler', StandardScaler()),
('model', RandomForestClassifier())
])
Pipeline自定义转换器
我们可以如下自定义transformer(来自Using Pipelines and FeatureUnions in scikit-learn – Michelle Fullwood)
from sklearn.base import BaseEstimator, TransformerMixin
class SampleExtractor(BaseEstimator, TransformerMixin):
def __init__(self, vars):
self.vars = vars # e.g. pass in a column name to extract
def transform(self, X, y=None):
return do_something_to(X, self.vars) # where the actual feature extraction happens
def fit(self, X, y=None):
return self # generally does nothing
另外,我们也可以对每个feature单独处理,例如下面的这个比较大的流水线(来自Using scikit-learn Pipelines and FeatureUnions (zacstewart.com)),我们可以发现作者的pipeline中,首先是一个叫做features的FeatureUnion,其中,每个特征分别以一个pipeline来处理,这个pipeline首先是一个ColumnExtractor提取出这个特征,后续进行一系列处理转换,最终这些pipeline组合为特征组合,再喂给一系列ModelTransformer包装的模型来predict,最终使用KNeighborsRegressor预测(相当于两层stacking)。
pipeline = Pipeline([
('features', FeatureUnion([
('continuous', Pipeline([
('extract', ColumnExtractor(CONTINUOUS_FIELDS)),
('scale', Normalizer())
])),
('factors', Pipeline([
('extract', ColumnExtractor(FACTOR_FIELDS)),
('one_hot', OneHotEncoder(n_values=5)),
('to_dense', DenseTransformer())
])),
('weekday', Pipeline([
('extract', DayOfWeekTransformer()),
('one_hot', OneHotEncoder()),
('to_dense', DenseTransformer())
])),
('hour_of_day', HourOfDayTransformer()),
('month', Pipeline([
('extract', ColumnExtractor(['datetime'])),
('to_month', DateTransformer()),
('one_hot', OneHotEncoder()),
('to_dense', DenseTransformer())
])),
('growth', Pipeline([
('datetime', ColumnExtractor(['datetime'])),
('to_numeric', MatrixConversion(int)),
('regression', ModelTransformer(LinearRegression()))
]))
])),
('estimators', FeatureUnion([
('knn', ModelTransformer(KNeighborsRegressor(n_neighbors=5))),
('gbr', ModelTransformer(GradientBoostingRegressor())),
('dtr', ModelTransformer(DecisionTreeRegressor())),
('etr', ModelTransformer(ExtraTreesRegressor())),
('rfr', ModelTransformer(RandomForestRegressor())),
('par', ModelTransformer(PassiveAggressiveRegressor())),
('en', ModelTransformer(ElasticNet())),
('cluster', ModelTransformer(KMeans(n_clusters=2)))
])),
('estimator', KNeighborsRegressor())
])
class HourOfDayTransformer(TransformerMixin):
def transform(self, X, **transform_params):
hours = DataFrame(X['datetime'].apply(lambda x: x.hour))
return hours
def fit(self, X, y=None, **fit_params):
return self
class ModelTransformer(TransformerMixin):
def __init__(self, model):
self.model = model
def fit(self, *args, **kwargs):
self.model.fit(*args, **kwargs)
return self
def transform(self, X, **transform_params):
return DataFrame(self.model.predict(X))
FeatureUnion
sklearn.pipeline.FeatureUnion—scikit-learn 0.19.1 documentation和pipeline的序列执行不同,FeatureUnion指的是并行地应用许多transformer在input上,再将结果合并,所以自然地适合特征工程中的增加特征,而FeatureUnion与pipeline组合可以方便的完成许多复杂的操作,例如:
pipeline = Pipeline([
('extract_essays', EssayExractor()),
('features', FeatureUnion([
('ngram_tf_idf', Pipeline([
('counts', CountVectorizer()),
('tf_idf', TfidfTransformer())
])),
('essay_length', LengthTransformer()),
('misspellings', MispellingCountTransformer())
])),
('classifier', MultinomialNB())
])
整个features是一个FeatureUnion,而其中的ngram_tf_idf又是一个包括两步的pipeline。
下面的例子中,使用FeatureUnion结合PCA降维后特征以及选择原特征中的几个作为特征组合再喂给SVM分类,最后用grid_search做了pca的n_components、SelectKBest的k以及SVM的C的CV。
from sklearn.pipeline import Pipeline, FeatureUnion
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
iris = load_iris()
X, y = iris.data, iris.target
print(X.shape, y.shape)
# This dataset is way too high-dimensional. Better do PCA:
pca = PCA()
# Maybe some original features where good, too?
selection = SelectKBest()
# Build estimator from PCA and Univariate selection:
svm = SVC(kernel="linear")
# Do grid search over k, n_components and C:
pipeline = Pipeline([("features",
FeatureUnion([("pca", pca), ("univ_select", selection)])), ("svm", svm)])
param_grid = dict(
features__pca__n_components=[1, 2, 3],
features__univ_select__k=[1, 2],
svm__C=[0.1, 1, 10])
grid_search = GridSearchCV(pipeline, param_grid=param_grid, verbose=10)
grid_search.fit(X, y)
grid_search.best_estimator_
grid_search.best_params_
grid_search.best_score_
类别型和数值型数据的处理
import pandas as pd
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
df = pd.dataframe()
numeric_features = ['salary', 'zone_count', 'staff_count']
categorical_features = ['rank', 'district']
categorical_feature_mask = df.dtypes == object
categorical_features = df.columns[categorical_feature_mask].tolist()
numeric_feature_mask = df.dtypes != object
numeric_features = df.columns[numeric_feature_mask].tolist()
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore')),
])
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler()),
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)
clf = Pipeline([
('preprocessor', preprocessor),
('clf', RandomForestClassifier())
])
实战案例:房价预测(回归任务)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# 加载数据
data = pd.read_csv('housing.csv')
X = data.drop('price', axis=1)
y = data['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 定义预处理步骤(假设数值列和分类列已标识)
numeric_features = ['area', 'bedrooms']
categorical_features = ['district']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
# 构建完整Pipeline
pipeline = Pipeline([
('preprocessor', preprocessor),
('regressor', GradientBoostingRegressor())
])
# 训练与评估
pipeline.fit(X_train, y_train)
y_pred = pipeline.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差: {mse:.2f}")
最佳实践与注意事项
- 命名步骤:为每个步骤指定清晰的名称(如scaler、model),便于调试和参数调优。
- 避免数据泄露:确保fit仅在训练数据上执行,transform应用于训练和测试数据。
- 轻量化步骤:避免在Pipeline中包含数据保存、可视化等非必要操作。
- 版本控制:当使用自定义转换器时,确保依赖库版本一致。
- 数据顺序:预处理步骤的顺序需符合逻辑(如先填充缺失值再标准化)。
- 稀疏矩阵:某些转换器(如 OneHotEncoder)会生成稀疏矩阵,需确保后续步骤兼容。
- 内存管理:大型数据集可设置 memory 参数缓存中间结果。
参考链接:


