特征选择是特征工程里的一个重要问题,其目标是寻找最优特征子集。特征选择能剔除不相关(irrelevant)或冗余(redundant)的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化模型,协助理解数据产生的过程。并且常能听到”数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已“,由此可见其重要性。但是它几乎很少出现于机器学习书本里面的某一章。然而在机器学习方面的成功很大程度上在于如果使用特征工程。
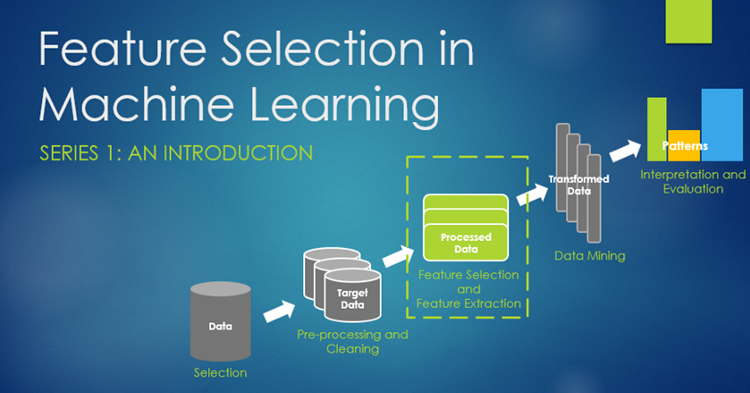
特征选择是一个过程,您可以自动选择数据中您感兴趣的对预测变量或输出贡献(影响)最大的特征。之所以要考虑特征选择,是因为机器学习经常面临过拟合的问题。过拟合的表现是模型参数太贴合训练集数据,模型在训练集上效果很好而在测试集上表现不好,也就是在高方差。简言之模型的泛化能力差。过拟合的原因是模型对于训练集数据来说太复杂,要解决过拟合问题,一般考虑如下方法:
- 收集更多数据
- 通过正则化引入对复杂度的惩罚
- 选择更少参数的简单模型
- 对数据降维(降维有两种方式:特征选择和特征抽取)
其中第1点一般是很难做到的,一般主要采用第2和第4点
特征选择的一般过程:
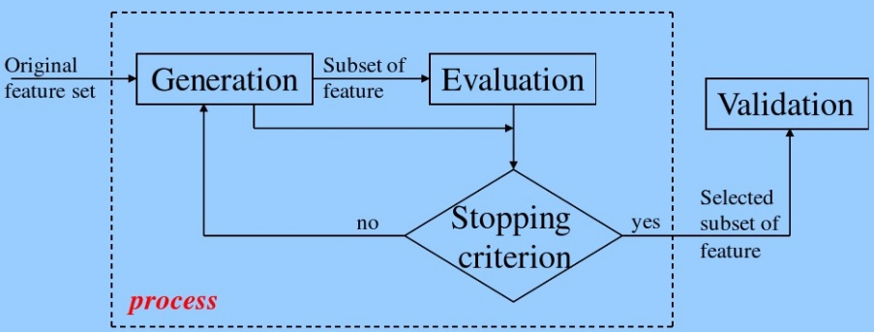
- 生成子集:搜索特征子集,为评价函数提供特征子集
- 评价函数:评价特征子集的好坏
- 停止准则:与评价函数相关,一般是阈值,评价函数达到一定标准后就可停止搜索
- 验证过程:在验证数据集上验证选出来的特征子集的有效性
特征选择算法可以被视为搜索技术和评价指标的结合。前者提供候选的新特征子集,后者为不同的特征子集打分。最简单的算法是测试每个特征子集,找到究竟哪个子集的错误率最低。这种算法需要穷举搜索空间,难以算完所有的特征集,只能涵盖很少一部分特征子集。选择何种评价指标很大程度上影响了算法。而且,通过选择不同的评价指标,可以把特征选择算法分为三类:包装类、过滤类和嵌入类方法:
- 过滤类方法采用代理指标,而不根据特征子集的错误率计分。所选的指标算得快,但仍然能估算出特征集好不好用。常用指标包括互信息、逐点互信息、皮尔逊积矩相关系数、每种分类/特征的组合的帧间/帧内类距离或显著性测试评分。过滤类方法计算量一般比包装类小,但这类方法找到的特征子集不能为特定类型的预测模型调校。由于缺少调校,过滤类方法所选取的特征集会比包装类选取的特征集更为通用,往往会导致比包装类的预测性能更为低下。不过,由于特征集不包含对预测模型的假设,更有利于暴露特征之间的关系。许多过滤类方法提供特征排名,而非显式提供特征子集。要从特征列表的哪个点切掉特征,得靠交叉验证来决定。过滤类方法也常常用于包装方法的预处理步骤,以便在问题太复杂时依然可以用包装方法。
- 包装类方法使用预测模型给特征子集打分。每个新子集都被用来训练一个模型,然后用验证数据集来测试。通过计算验证数据集上的错误次数(即模型的错误率)给特征子集评分。由于包装类方法为每个特征子集训练一个新模型,所以计算量很大。不过,这类方法往往能为特定类型的模型找到性能最好的特征集。
- 嵌入类方法包括了所有构建模型过程中用到的特征选择技术。这类方法的典范是构建线性模型的LASSO方法。该方法给回归系数加入了L1惩罚,导致其中的许多参数趋于零。任何回归系数不为零的特征都会被LASSO算法”选中”。LASSO的改良算法有Bolasso和FeaLect。Bolasso改进了样本的初始过程。FeaLect根据回归系数组合分析给所有特征打分。另外一个流行的做法是递归特征消除(Recursive Feature Elimination)算法,通常用于支持向量机,通过反复构建同一个模型移除低权重的特征。这些方法的计算复杂度往往在过滤类和包装类之间。
上面的介绍看起来很复杂,简单的说:
- Filter(过滤类):按照发散性或相关性对各个特征进行评分,设定阈值或者待选择特征的个数进行筛选
- Wrapper(包装类):根据目标函数(往往是预测效果评分),每次选择若干特征,或者排除若干特征
- Embedded(嵌入类):先使用某些机器学习的模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征(类似于Filter,只不过系数是通过训练得来的)
过滤类方法
过滤类方法的基本思想是:分别对每个特征$x_i$,计算$x_i$相对于类别标签$y$的信息量$S(i)$,得到n个结果。然后将n个$S(i)$按照从大到小排序,输出前k个特征。显然,这样复杂度大大降低。
Pearson相关系数
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关(这个变量下降,那个就会上升),+1表示完全的正相关,0表示没有线性相关性。Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的pearsonr方法能够同时计算相关系数和p-value。(p值越小,说明信赖度越高,合理范围是<0.05)
最简单的示例:
import numpy as np
from scipy.stats import pearsonr
np.random.seed(0)
size = 300
x = np.random.normal(0, 1, size)
print("Lower noise:", pearsonr(x, x + np.random.normal(0, 1, size)))
print("Higher noise:", pearsonr(x, x + np.random.normal(0, 10, size)))
关于如何从众多特征中找出TOP相关特征,可以选择Sklearn中的相关工具:
- SelectKBest:留下topK高分的features
- SelectPercentile:留下百分比的top高分features
- 为每个feature都使用常用的单变量统计检验(univariate statistical tests):
示例代码:
import numpy as np
from scipy.stats import pearsonr
from sklearn.feature_selection import SelectKBest
from sklearn.datasets import load_iris
iris = load_iris()
# 选择K个最好的特征,返回选择特征后的数据
# 第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量
# 输出二元组(评分,P值)的数组
# 数组第i项为第i个特征的评分和P值。在此定义为计算相关系数
# 参数k为选择的特征个数
def multivariate_pearsonr(X, y):
scores, p_values = [], []
for ret in map(lambda x: pearsonr(x, y), X.T):
print(ret) # 输出每列的相关系数和p_value值
scores.append(abs(ret[0]))
p_values.append(ret[1])
return (np.array(scores), np.array(p_values))
transformer = SelectKBest(score_func=multivariate_pearsonr, k=2)
X_new = transformer.fit_transform(iris.data, iris.target)
print(X_new) # 输出具体特征列
Pearson相关系数的一个明显缺陷是,作为特征排序机制,他只对线性关系敏感。如果关系是非线性的,即便两个变量具有一一对应的关系,Pearson相关性也可能会接近0。尽管Pearson相关系统存在这样的问题,同时存在如最大互信息系数、距离相关系数等方法,但当变量之间的关系接近线性相关的时候,Pearson相关系数仍然是不可替代的。
- Pearson相关系数计算速度快,这在处理大规模数据的时候很重要。
- Pearson相关系数的取值区间是[-1,1],而MIC和距离相关系数都是[0,1]。这个特点使得Pearson相关系数能够表征更丰富的关系,符号表示关系的正负,绝对值能够表示强度。当然,Pearson相关性有效的前提是两个变量的变化关系是单调的。
卡方检验
卡方检验是卡方分布为基础的一种检验方法,主要用于分类变量,根据样本数据推断总体的分布与期望分布是否有显著差异,或推断两个分类变量是否相关或相互独立。其原假设为:观察频数与期望频数没有差别。凡是可以应用比率进行检验的资料,都可以用卡方检验。关于卡方检验更多介绍见假设检验之卡方检验。
使用示例:
from sklearn.datasets import load_iris from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 iris = load_iris() X, y = iris.data, iris.target # 选择K个最好的特征,返回选择特征后的数据 X_new = SelectKBest(chi2, k=2).fit_transform(X, y) print(X_new)
最大互信息系数(MIC)
互信息及最大信息系数内容有点绕,已经单独整理了一篇文章,见:深入理解最大互信息系数。
需要注意的是:MIC的统计能力遭到了一些质疑,当零假设不成立时,MIC的统计就会受到影响。在有的数据集上不存在这个问题,但有的数据集上就存在这个问题。
距离相关系数(Distance Correlation)
距离相关系数是为了克服Pearson相关系数的弱点而生的。如果我们在使用Pearson相关系数时得到的值是0,我们夜不能断定两个变量间相互独立,比如$x$与$x^2$之间,但如果聚类相关系数是0,那么我们就可以说这两个变量是独立的。
利用DistanceCorrelation研究两变量u和v的独立性,记为dcorr(u,v)。当dcorr(u,v)=0时,说明u,v相互独立;dcorr(u,v)越大,说明u和v的相关性越强。设$\{(u_i,v_i),i=1,2,..n\}$是总体(u,v)的随机变量,定义两随机变量的u和v的DC样本估计为:
$$\hat{d}\text{corr}(u,v)=\frac{\hat{d}\text{cov}(u,v)}{\sqrt{\hat{d}\text{cov}(u,u)\hat{d}\text{cov}(v,v)}}$$
其中:
$$\hat{d}\text{corr}^2(u,v)=\hat{S_1}+\hat{S_2}-2\hat{S_3}$$
$$\hat{S_1}=\frac{1}{n^2}\sum_{i=1}^{n}\sum_{j=1}^{n}\left\|u_i-u_j\right\|_{d_u}\left\|v_i-v_j\right\|_{d_v}$$
$$\hat{S_2}=\frac{1}{n^2}\sum_{i=1}^{n}\left\|u_i-u_j\right\|_{d_u}\frac{1}{n^2}\sum_{j=1}^{n}\left\|v_i-v_j\right\|_{d_v}$$
$$\hat{S_3}=\frac{1}{n^3}\sum_{i=1}^{n}\sum_{j=1}^{n}\sum_{l=1}^{n}\left\|u_i-u_l\right\|_{d_u}\left\|v_i-v_l\right\|_{d_v}$$
代码:
from scipy.spatial.distance import pdist, squareform
import numpy as np
import copy
def distcorr(Xval, Yval, pval=True, nruns=500):
"""Compute the distance correlation function, returning the p-value."""
X = np.atleast_1d(Xval)
Y = np.atleast_1d(Yval)
if np.prod(X.shape) == len(X):
X = X[:, None]
if np.prod(Y.shape) == len(Y):
Y = Y[:, None]
X = np.atleast_2d(X)
Y = np.atleast_2d(Y)
n = X.shape[0]
if Y.shape[0] != X.shape[0]:
raise ValueError('Number of samples must match')
a = squareform(pdist(X))
b = squareform(pdist(Y))
A = a - a.mean(axis=0)[None, :] - a.mean(axis=1)[:, None] + a.mean()
B = b - b.mean(axis=0)[None, :] - b.mean(axis=1)[:, None] + b.mean()
dcov2_xy = (A * B).sum() / float(n * n)
dcov2_xx = (A * A).sum() / float(n * n)
dcov2_yy = (B * B).sum() / float(n * n)
dcor = np.sqrt(dcov2_xy) / np.sqrt(np.sqrt(dcov2_xx) * np.sqrt(dcov2_yy))
if pval:
greater = 0
for i in range(nruns):
Y_r = copy.copy(Yval)
np.random.shuffle(Y_r)
if distcorr(Xval, Y_r, pval=False) > dcor:
greater += 1
return (dcor, greater / float(nruns))
else:
return dcor
更简单的使用方式:
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import dcor
iris = load_iris()
iris_df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns=iris['feature_names'] + ['target'])
print("dcor distance correlation={:.3f}".format(
dcor.distance_correlation(iris_df['sepal length (cm)'], iris_df['petal length (cm)'])))
方差选择法(VarianceThreshold)
过滤特征选择法还有一种方法不需要度量特征$x_i$和类别标签y的信息量。这种方法先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
例如,假设我们有一个具有布尔特征的数据集,并且我们要删除超过80%的样本中的一个或零(开或关)的所有特征。布尔特征是伯努利随机变量,这些变量的方差由下式给出:
$$Var[X]=p(1-p)$$
VarianceThreshold是特征选择的简单基线方法。它删除方差不符合某个阈值的所有特征。默认情况下,它会删除所有零差异特征,即所有样本中具有相同值的特征。代码如下:
from sklearn.feature_selection import VarianceThreshold X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]] #方差选择法,返回值为特征选择后的数据 #参数threshold为方差的阈值 sel = VarianceThreshold(threshold=(.8 * (1 - .8))) print(sel.fit_transform(X)
输出结果:array([[0, 1], [1, 0], [0, 0], [1, 1], [1, 0], [1, 1]])如预期的那样,VarianceThreshold已经删除了第一列,其具有p=5/6>0.8包含零的概率。
方差选择的逻辑并不是很合理,这个是基于各特征分布较为接近的时候,才能以方差的逻辑来衡量信息量。但是如果是离散的或是仅集中在几个数值上,如果分布过于集中,其信息量则较小。而对于连续变量,由于阈值可以连续变化,所以信息量不随方差而变。实际使用时,可以结合cross-validate进行检验。
使用iris数据的示例:
from sklearn.feature_selection import VarianceThreshold from sklearn.datasets import load_iris iris = load_iris() X_new = VarianceThreshold(threshold=2).fit_transform(iris.data) print(X_new)
包装类方法
包装类方法的基本思想:基于hold-out方法,对于每一个待选的特征子集,都在训练集上训练一遍模型,然后在测试集上根据误差大小选择出特征子集。需要先选定特定算法,通常选用普遍效果较好的算法,例如RandomForest,SVM,kNN等等。包装法其实就是一个关于特征空间的搜索问题,但它的计算可能需要耗费大量时间空间。常用的包装法包括了前向选择法,后向剔除法,迭代剔除法等。
- 前向选择法:这是一种基于循环的方法,开始时我们训练一个不包含任何特征的模型,而后的每一次循环我们都持续放入能最大限度提升模型的变量,直到任何变量都不能提升模型表现。
- 后向剔除法:该方法先用所有特征建模,再逐步剔除最不显著的特征来提升模型表现。同样重复该方法直至模型表现收敛。
- 迭代剔除法:这是一种搜索最优特征子集的贪心优化算法。它会反复地训练模型并剔除每次循环的最优或最劣特征。下一次循环,则使用剩余的特征建模直到所有特征都被剔除。之后,按照剔除的顺序给所有特征排序作为特征重要性的度量。
前向选择法和后向剔除法存在的比较大的问题是计算复杂度比较大。时间复杂度为:$O(n+(n-1)+(n-2)+…+1)=O(n^2)$。所以我们通常使用迭代剔除法,也称递归特征消除法。
递归特征消除法(Recursive feature elimination)
递归特征消除(RFE)通过递归减少考察的特征集规模来选择特征。首先,预测模型在原始特征上训练,每项特征指定一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。
Sklearn的feature_selection库下RFE类可以用来选择特征,具体代码如下:
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression from sklearn.datasets import load_iris iris = load_iris() #递归特征消除法,返回特征选择后的数据 #参数estimator为基模型 #参数n_features_to_select为选择的特征个数 X_new = RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target) print(X_new)
嵌入类方法
嵌入法综合了过滤法和包装法的特点,它要借助那些自带特征选择方法的算法。过滤法和包装法的不同:
- 过滤法测量特征和被解释变量的相关性,包装法则是基于模型测量特征的有效性。
- 过滤法由于不依赖于模型,速度更快。
- 过滤法基于统计检验选择特征,包装法基于交叉验证。
- 过滤法时常失效,但包装法常常被发现很有用。
- 使用包装法筛选的特征更容易导致模型过拟合。
基于惩罚项的特征选择
最常用的嵌入法实例是 LASSO 和岭回归,他们的优化目标都带有惩罚项来减弱过拟合。LASSO 使用 L1 正则,也就是对系数的绝对值大小加以惩罚。岭回归使用 L2 正则也就是对系数的平方值加以惩罚。关于 LASSO 和岭回归的更多细节,可以参考岭回归、Lasso 回归和 ElasticNet 回归。
SelectFromModel 是一个元转换器(meta-transformer),可以用在任何在 fitting 后具有 coef_ 或 feature_importances_ 属性的 estimator。如果相应的 coef_ 或 feature_importances_ 值在提供的参数 threshold 之下,那么这些不重要的 features 将被移除。除了指定一个数值型的 threshold,还内置了些 string 参数作为阀值的探索法(heuristics)。这些 heuristics 方法有:“mean”, “median” 以及浮点乘法(比如:“0.1*mean”)
使用 L1 范数的线性模型有一个稀疏解:许多估计系数都为 0。当降维的目的是为了使用其他分类器,他们能和 feature_selection.SelectFromModel 一起使用选择非零系数。特别地,稀疏估计量对于回归中的 linear_model.Lasso、分类中的 linear_model.LogisticRegression 和 svm.LinearSVC 都很有用。
from sklearn.svm import LinearSVC from sklearn.datasets import load_iris from sklearn.feature_selection import SelectFromModel iris = load_iris() X, y = iris.data, iris.target lsvc = LinearSVC(C=0.01, penalty="l1", dual=False).fit(X, y) model = SelectFromModel(lsvc, prefit=True) X_new = model.transform(X) print(X_new) 在 SVM 和 Logistic 回归中,参数 C 控制着稀疏性,C 越小选择的特征越少。在 Lasso 中,参数 alpha 越大,选择的特征越少。 from sklearn.linear_model import LogisticRegression from sklearn.feature_selection import SelectFromModel from sklearn.datasets import load_iris iris = load_iris() # 带 L1 惩罚项的逻辑回归作为基模型的特征选择 X_new = SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target) print(X_new)
实际上,L1 惩罚项降维的原理在于保留多个对目标值具有同等相关性的特征中的一个,所以没选到的特征不代表不重要。故,可结合 L2 惩罚项来优化。具体操作为:若一个特征在 L1 中的权值为 1,选择在 L2 中权值差别不大且在 L1 中权值为 0 的特征构成同类集合,将这一集合中的特征平分 L1 中的权值,故需要构建一个新的逻辑回归模型:
from sklearn.linear_model import LogisticRegression
from sklearn.feature_selection import SelectFromModel
from sklearn.datasets import load_iris
iris = load_iris()
class LR(LogisticRegression):
def __init__(self, threshold=0.01, dual=False, tol=1e-4, C=1.0,
fit_intercept=True, intercept_scaling=1, class_weight=None,
random_state=None, solver='liblinear', max_iter=100,
multi_class='ovr', verbose=0, warm_start=False, n_jobs=1):
# 权值相近的阈值
self.threshold = threshold
LogisticRegression.__init__(self, penalty='l1', dual=dual, tol=tol, C=C,
fit_intercept=fit_intercept, intercept_scaling=intercept_scaling,
class_weight=class_weight,
random_state=random_state, solver=solver, max_iter=max_iter,
multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
# 使用同样的参数创建 L2 逻辑回归
self.l2 = LogisticRegression(penalty='l2', dual=dual, tol=tol, C=C, fit_intercept=fit_intercept,
intercept_scaling=intercept_scaling, class_weight=class_weight,
random_state=random_state, solver=solver, max_iter=max_iter,
multi_class=multi_class, verbose=verbose, warm_start=warm_start, n_jobs=n_jobs)
def fit(self, X, y, sample_weight=None):
# 训练 L1 逻辑回归
super(LR, self).fit(X, y, sample_weight=sample_weight)
self.coef_old_ = self.coef_.copy()
# 训练 L2 逻辑回归
self.l2.fit(X, y, sample_weight=sample_weight)
cntOfRow, cntOfCol = self.coef_.shape
# 权值系数矩阵的行数对应目标值的种类数目
for i in range(cntOfRow):
for j in range(cntOfCol):
coef = self.coef_[i][j]
# L1 逻辑回归的权值系数不为 0
if coef != 0:
idx = [j]
# 对应在 L2 逻辑回归中的权值系数
coef1 = self.l2.coef_[i][j]
for k in range(cntOfCol):
coef2 = self.l2.coef_[i][k]
# 在 L2 逻辑回归中,权值系数之差小于设定的阈值,且在 L1 中对应的权值为 0
if abs(coef1-coef2) < self.threshold and j != k and self.coef_[i][k] == 0:
idx.append(k)
# 计算这一类特征的权值系数均值
mean = coef / len(idx)
self.coef_[i][idx] = mean
return self
# 带 L1 和 L2 惩罚项的逻辑回归作为基模型的特征选择
# 参数 threshold 为权值系数之差的阈值
X_new = SelectFromModel(LR(threshold=0.5, C=0.1)).fit_transform(iris.data, iris.target)
print(X_new)
随机稀疏模型 (Randomized sparse models)
就特征选择而言,在回归和分类中使用 L1 正则有众所周知的局限。例如,Lasso 将从一组高度相关的特征中选择一个;此外,即使特征间的相关性并不强,L1 正则仍然会从中选出一个“好”的特征。为了减轻该问题的影响可以使用随机化技术,通过多次重新估计稀疏模型来扰乱设计矩阵,或通过多次下采样数据来统计一个给定的回归量被选中的次数。
为了解决这个问题,可以使用 sklearn.linear_model 中的稳定性选择(stability selection)这种随机化方法。在稳定性选择中,使用数据的子集去拟合模型,系数的随机子集的罚项将被缩小。
$$\hat{w}_{I} = \arg \min_{w} \frac{1}{2n_{I}} \sum_{i \in I} (y_{i} – x_{i}^{T} w)^{2} + \alpha \sum_{j=1}^{p} \frac{|w_{j}|}{s_{j}}$$
其中 $s_{j} \in \{s, 1\}$ 是公平伯努利随机变量的独立试验,0 < s < 1 是缩小因子。通过重复不同的随机子样本和伯努利实验组合,可以统计每个特征被随机过程所选中的概率,然后用这些概率去选择特征。
备注:linear_model.RandomizedLogisticRegression 和 linear_model.RandomizedLasso 已经在 scikit-learn 0.21 被移除。
它的主要思想是在不同的数据子集和特征子集上运行特征选择算法,不断的重复,最终汇总特征选择结果,比如可以统计某个特征被认为是重要特征的频率(被选为重要特征的次数除以它所在的子集被测试的次数)。
基于树的特征选择 (Tree-based feature selection)
树模型在学习时,是以纯度为评价基准,选择最好的分裂属性进行分裂,这本身也可以看作一个特征选择的过程。以随机森林为例,其提供了两种特征选择的方法:平均不纯度减少 (mean decrease impurity) 和平均精确度减少(mean decrease accuracy)。
平均不纯度减少 (Mean Decrease Impurity)
随机森林由多个决策树构成。决策树中的每一个节点都是关于某个特征的条件,为的是将数据集按照不同的响应变量一分为二。利用不纯度可以确定节点(最优条件),对于分类问题,通常采用基尼不纯度或者信息增益,对于回归问题,通常采用的是方差或者最小二乘拟合。当训练决策树的时候,可以计算出每个特征减少了多少树的不纯度。对于一个决策树森林来说,可以算出每个特征平均减少了多少不纯度,并把它平均减少的不纯度作为特征选择的值。
下面的例子是 sklearn 中基于随机森林的特征重要度度量方法:
from sklearn.ensemble import RandomForestRegressor
from sklearn.datasets import load_iris
iris = load_iris()
X = iris["data"]
Y = iris["target"]
names = iris["feature_names"]
rf = RandomForestRegressor()
rf.fit(X, Y)
print("Features sorted by their score:")
print(sorted(zip(map(lambda x: "%.4f" % x, rf.feature_importances_), names), reverse=True))
这里特征得分实际上采用的是 Gini Importance。使用基于不纯度的方法的时候,要记住:
- 这种方法存在偏向,对具有更多类别的变量会更有利;
- 对于存在关联的多个特征,其中任意一个都可以作为指示器(优秀的特征),并且一旦某个特征被选择之后,其他特征的重要度就会急剧下降(因为不纯度已经被选中的那个特征降下来了,其他的特征就很难再降低那么多不纯度了,这样一来,只有先被选中的那个特征重要度很高,其他的关联特征重要度往往较低)。在理解数据时,这就会造成误解,导致错误的认为先被选中的特征是很重要的,而其余的特征是不重要的,但实际上这些特征对响应变量的作用确实非常接近的(这跟 Lasso 是很像的)。特征随机选择方法稍微缓解了这个问题,但总的来说并没有完全解决。
平均精确率减少 (Mean Decrease Accuracy)
另一种常用的特征选择方法就是直接度量每个特征对模型精确率的影响。主要思路是打乱每个特征的特征值顺序,并且度量顺序变动对模型的精确率的影响。很明显,对于不重要的变量来说,打乱顺序对模型的精确率影响不会太大,但是对于重要的变量来说,打乱顺序就会降低模型的精确率。这个方法 sklearn 中没有直接提供,但是很容易实现:
from sklearn.model_selection import ShuffleSplit
from sklearn.metrics import r2_score
from collections import defaultdict
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
X = iris["data"]
Y = iris["target"]
names = iris["feature_names"]
rf = RandomForestRegressor()
scores = defaultdict(list)
# cross validate the scores on a number of different random splits of the data
for train_idx, test_idx in ShuffleSplit(len(X), 100, .3).split(X):
X_train, X_test = X[train_idx], X[test_idx]
Y_train, Y_test = Y[train_idx], Y[test_idx]
r = rf.fit(X_train, Y_train)
acc = r2_score(Y_test, rf.predict(X_test))
for i in range(X.shape[1]):
X_t = X_test.copy()
np.random.shuffle(X_t[:, i])
shuff_acc = r2_score(Y_test, rf.predict(X_t))
scores[names[i]].append((acc - shuff_acc) / acc)
print("Features sorted by their score:")
print(sorted([(float('%.4f' % np.mean(score)), feat) for
feat, score in scores.items()], reverse=True))
注意,尽管这些我们是在所有特征上进行了训练得到了模型,然后才得到了每个特征的重要性测试,这并不意味着我们扔掉某个或者某些重要特征后模型的性能就一定会下降很多,因为即便某个特征删掉之后,其关联特征一样可以发挥作用,让模型性能基本上不变。
树模型中 GBDT 也可用来作为基模型进行特征选择,使用 feature_selection 库的 SelectFromModel 类结合 GBDT 模型,来选择特征的代码如下:
from sklearn.ensemble import ExtraTreesClassifier from sklearn.ensemble import GradientBoostingClassifier from sklearn.datasets import load_iris from sklearn.feature_selection import SelectFromModel iris = load_iris() # X_new = SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target) X, y = iris.data, iris.target clf = ExtraTreesClassifier() # clf = GradientBoostingClassifier() clf = clf.fit(X, y) print(clf.feature_importances_) model = SelectFromModel(clf, prefit=True) X_new = model.transform(X) print(X_new)
降维
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
主成分分析(PCA)
主成分分析(Principal Component Analysis或PCA)使用线性代数将数据集转换为压缩格式。通常这被称为数据压缩技术。PCA的一个属性是可以在转换结果中选择维数或主成分。
from sklearn.decomposition import PCA from sklearn.datasets import load_iris iris = load_iris() # 主成分分析法,返回降维后的数据 # 参数n_components为主成分数目 X_new = PCA(n_components=2).fit_transform(iris.data) print(X_new)
线性判别分析法(LDA)
使用lda库的LDA类选择特征的代码如下:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.datasets import load_iris iris = load_iris() # 线性判别分析法,返回降维后的数据 # 参数n_components为降维后的维数 X_new = LinearDiscriminantAnalysis(n_components=2).fit_transform(iris.data, iris.target) print(X_new)
总结
- 对于理解数据、数据的结构、特点来说,单变量特征选择是个非常好的选择。尽管可以用它对特征进行排序来优化模型,但由于它不能发现冗余(例如假如一个特征子集,其中的特征之间具有很强的关联,那么从中选择最优的特征时就很难考虑到冗余的问题)。
- 正则化的线性模型对于特征理解和特征选择来说是非常强大的工具。L1正则化能够生成稀疏的模型,对于选择特征子集来说非常有用;相比起L1正则化,L2正则化的表现更加稳定,由于有用的特征往往对应系数非零,因此L2正则化对于数据的理解来说很合适。由于响应变量和特征之间往往是非线性关系,可以采用basis expansion(基展开)的方式将特征转换到一个更加合适的空间当中,在此基础上再考虑运用简单的线性模型。
- 随机森林是一种非常流行的特征选择方法,它易于使用,一般不需要feature engineering、调参等繁琐的步骤,并且很多工具包都提供了平均不纯度下降方法。它的两个主要问题,1是重要的特征有可能得分很低(关联特征问题),2是这种方法对特征变量类别多的特征越有利(偏向问题)。尽管如此,这种方法仍然非常值得在你的应用中试一试。
- 特征选择在很多机器学习和数据挖掘场景中都是非常有用的。在使用的时候要弄清楚自己的目标是什么,然后找到哪种方法适用于自己的任务;当选择最优特征以提升模型性能的时候,可以采用交叉验证的方法来验证某种方法是否比其他方法要好;当用特征选择的方法来理解数据的时候要留心,特征选择模型的稳定性非常重要,稳定性差的模型很容易就会导致错误的结论;数据进行二次采样然后在子集上运行特征选择算法能够有所帮助,如果在各个子集上的结果是一致的,那就可以说在这个数据集上得出来的结论是可信的,可以用这种特征选择模型的结果来理解数据。


