项目简介:针对一标识的文本信息,抽取文本中的关键词,最后以词云的方式暂时关键词。数据集更有2列:text、flag。其中text是文本内容, flag样本标识(0或1)。 步骤一:对文本内容进行分词处理 这里采用的是结…

“Lies, damned lies, and statistics” 是一句广为人知的谚语,常被用来批判对统计数据的滥用或误导性使用。 出处与背景 起源争议:这句话的确切出处尚无定论,但普遍认为它源于19世纪的英国政坛。常被…

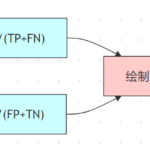
先前按照Scikit-Learn的文档整理了一份评估指标,回头看下梳理的非常的技术化,整理完有种自己都不太想看的感觉。今天抽时间再做一次重新的梳理。 分类任务评估指标 混淆矩阵(Confusion Matrix) 分类任务的基…
自2022年11月推出以来,ChatGPT 一直备受关注。其根据输入内容和上下文提供类似于人类的回应能力,给一些重视原创内容的领域带来了困扰,包括教育、内容营销、出版、新闻和法律等领域。他们最大的问题是“我们如何区…

ColumnTransformer 是 scikit-learn 中用于对数据的不同列应用不同预处理步骤的工具,特别适用于处理包含混合类型特征(如数值型、分类型、文本型)的数据集。 ColumnTransformer核心功能与使用场景 核心功能…
超参数调优是机器学习模型开发的核心步骤,直接影响模型性能。scikit-learn 提供多种工具帮助高效优化参数。 GridSearchCV Scikit-Learn 的 GridSearchCV 是一种通过穷举参数组合并交叉验证评估性能的超参数…

类别不平衡是分类任务中常见的问题,即某些类别的样本数量显著少于其他类别。除了前面介绍的imbalanced-learn库以外,还能使用class_weight参数进行处理。 class_weight与imbalanced-learn的对比 核心定义与…

CMMD简介 CMMD(Cross-Metric Multidimensional Diagnosis)是一种面向 复杂系统多源异构数据 的根因定位框架,其核心思想是通过 跨指标关联性分析 和 多维时空模式挖掘,在 无监督或半监督 场景下快速定位故障根…
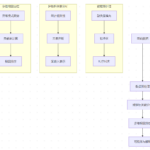
imbalanced-learn(通常简称为 imblearn)是一个专门用于处理类别不平衡数据的 Python 库。它与 Scikit-learn 兼容,提供了多种方法来解决分类任务中类别样本数量差异过大的问题。 为什么需要 imbalanced-lear…

什么是大数据杀熟? 大数据杀熟(Big Data Price Discrimination)是指企业利用用户的历史行为数据、消费习惯、设备信息、地理位置等个人隐私数据,通过算法分析对不同用户实施差异化定价的行为。其核心在于利用数…






