RiskLoc简介 RiskLoc 是一种通过 量化多维风险权重 和 动态概率融合 实现故障根因定位的方法,其核心思想是将系统异常视为多个潜在因素(如硬件、软件、网络等)的加权风险组合,通过概率模型计算各因素成为根因的…
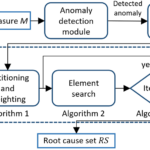
AutoRoot 简介 AutoRoot 是一种基于 自动化机器学习(AutoML) 和 因果推理 的多维故障根因定位方案,旨在通过智能化分析高维监控数据(如指标、日志、链路追踪等),快速、精准地识别复杂系统中的故障根源。其核…
Scikit-Learn 提供了多种特征选择方法,主要分为以下几类,结合具体场景和算法特性进行选择: 过滤法 (Filter Methods) 基于统计指标评估特征重要性,独立于模型。 方差阈值 (Variance Threshold) 方差阈值…

Squeeze简介 Squeeze是一种面向多维监控数据的通用根因定位算法,旨在从海量维度组合中快速、鲁棒地识别导致KPI(关键性能指标)异常的根本原因。其核心思想是通过分析多维指标的异常分布差异,逐步缩小可能触发异…

Hotspot是一款来自百度的多维异常定位方法,以下内容是根据其发布的论文梳理得出,仅供参考。 问题背景与挑战 目标:在具有多维属性(如“数据中心、服务类型、客户端OS”)的加法型KPI(如请求量、错误数)中,快…
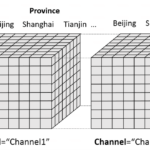
sklearn.datasets 是 scikit-learn 中用于加载和生成数据集的工具模块,内置了多种经典数据集和灵活的数据生成方法,适合快速实验和算法验证。 内置数据集类型 模块中的数据集分为三类,通过不同函数加载: …

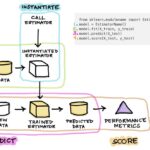
scikit-learn 的核心 API 设计以一致性和模块化为核心,所有功能模块遵循统一的接口规范,使得数据预处理、模型训练、评估和部署流程高度标准化。 API 设计原则 一致性接口:所有估计器(模型、预处理工具)均…
Scikit-Learn 的 sklearn.preprocessing 模块提供了一系列数据预处理工具,帮助将原始数据转换为适合机器学习模型的形式。 缺失值处理 在 scikit-learn 中,缺失值处理是数据预处理的关键步骤之一。大多数机器学…

Channel Attribution 简介 Channel Attribution 是一个用于解决市场营销渠道归因问题的 Python 包。它通过数据驱动的方法(如马尔可夫链模型)和启发式模型(如首次点击、末次点击)来量化不同营销渠道对转化的贡献…

BTYD模型简介 BTYD(Buy Till You Die)模型是一类用于预测客户未来购买行为的统计模型,其核心假设是:客户在“活跃”状态下持续购买,直到永久流失(“死亡”)。模型通过历史交易数据,估算客户的购买频率、流失概…