什么是目标编码?
目标编码(Target Encoding),又称均值编码、似然编码,是一种将分类变量转换为数值特征的技术,通过利用目标变量的统计信息来捕捉类别与目标之间的关系。
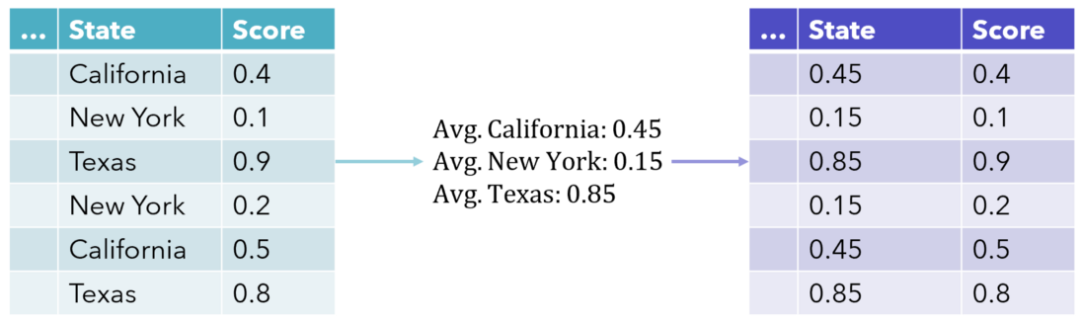
核心思想
目标编码用目标变量的统计量(如均值、中位数、出现概率等)替代每个分类变量的类别。例如,在二分类任务中,可将每个类别替换为该类别下正例的比例;在回归任务中,则可能使用目标变量的均值。
具体步骤
- 统计量计算:对每个类别$x_i$,计算目标变量Y 的统计量(如均值 $E(Y|X=x_i)$)。
- 处理未见类别:测试集中未出现的类别,用全局统计量(如全体训练数据的Y 均值)替代。
- 防止数据泄露:在训练时仅使用训练集数据计算统计量,验证/测试集使用训练集统计量,避免信息泄露。
- 平滑处理(可选):引入平滑因子平衡小类别的噪声,公式为:$\text{编码值}=\frac{n\cdot\text{类别均值}+m\cdot\text{全局均值}}{n+m}$,其中n 为类别样本数,m 为平滑参数(超参数)。
优缺点分析
优点:
- 高效降维:避免独热编码的高维问题,适合高基数(类别多)特征。
- 保留语义信息:编码后的数值反映类别与目标的关系,提升模型表现。
缺点:
- 过拟合风险:尤其当类别样本较少时,需通过平滑或交叉验证缓解。
- 信息泄露:需严格分割训练与测试数据,防止目标信息泄露。
应用场景
- 高基数特征:如用户ID、地区等,独热编码不适用时。
- 非树模型:线性模型、神经网络等无法直接处理类别特征,目标编码提供有效转换。
实践建议
- 平滑技术:对低频类别,结合全局统计量提升鲁棒性。
- 交叉验证:在训练过程中分折计算编码,避免泄露。
- 库实现:Python的 category_encoders 库提供 TargetEncoder,支持平滑和未知类别处理。
变体与扩展
- 多分类目标:对每个目标类别生成单独编码特征,或使用多维统计量(如期望值)。
- 时间序列数据:需按时间顺序计算滚动统计量,避免使用未来信息。
注意事项
- 模型选择:树模型(如随机森林)可能对目标编码不敏感,优先考虑其他编码方式。
- 评估验证:通过交叉验证检查编码效果,避免过拟合。
category_encoders库简介
category_encoders 是一个强大的 Python 库,专门用于将分类变量(Categorical Features)转换为数值特征,支持多种编码方法,适用于机器学习和数据分析任务。
概述
- 功能:提供超过15种分类变量编码方法,涵盖从经典的独热编码到复杂的目标编码。
- 兼容性:与 scikit-learn 无缝集成,支持管道(Pipeline)和交叉验证。
- 优势:
- 支持高基数(High-Cardinality)分类变量(如用户ID、地址等)。
- 处理缺失值和未知类别。
- 提供灵活的编码策略,适应不同模型需求(如线性模型、树模型)。
支持的编码方法
以下是常用的编码方法及适用场景:
独热编码(One-Hot Encoding)
方法:为每个类别生成一个二值(0/1)特征。
适用场景:类别数量少(低基数)的特征。
代码示例:
from category_encoders import OneHotEncoder encoder = OneHotEncoder(cols=['city']) X_encoded = encoder.fit_transform(X)
目标编码(Target Encoding)
方法:用目标变量的均值替代类别(支持平滑处理)。
适用场景:高基数特征,适用于非树模型(如线性回归、神经网络)。
参数:
- smoothing:平滑因子,平衡类别均值和全局均值。
- min_samples_leaf:控制小类别的平滑强度。
from category_encoders import TargetEncoder encoder = TargetEncoder(cols=['city'], smoothing=10) X_encoded = encoder.fit_transform(X, y)
计数编码(Count Encoding)
方法:用类别在训练集中的出现频次替代类别。
适用场景:捕捉类别的常见程度。
from category_encoders import CountEncoder encoder = CountEncoder(cols=['city']) X_encoded = encoder.fit_transform(X)
序数编码(Ordinal Encoding)
方法:为类别分配有序整数(如”小/中/大”→1/2/3)。
适用场景:有序分类变量(如评级、等级)。
from category_encoders import OrdinalEncoder
encoder = OrdinalEncoder(cols=['size'], mapping=[{'col':'size','mapping':{'小':1,'中':2,'大':3}}])
X_encoded = encoder.fit_transform(X)
CatBoost编码
方法:基于目标变量的排序编码,避免目标泄露。
适用场景:高基数特征,适用于树模型(如XGBoost、LightGBM)。
from category_encoders import CatBoostEncoder encoder = CatBoostEncoder(cols=['city']) X_encoded = encoder.fit_transform(X, y)
留一法编码(LeaveOneOut Encoding)
方法:在计算类别均值时排除当前样本,防止过拟合。
适用场景:小数据集或高基数特征。
from category_encoders import LeaveOneOutEncoder encoder = LeaveOneOutEncoder(cols=['city']) X_encoded = encoder.fit_transform(X, y)
其他编码方法
- WOE编码(Weight of Evidence):用于二分类任务,衡量类别与目标的相关性。
- James-Stein编码:基于统计收缩的编码,适用于高基数特征。
- GLMM编码:基于广义线性混合模型的编码。
高级功能
处理未知类别
- 库会自动将未见过的测试集类别替换为训练集的统计量(如全局均值)。
- 可通过 handle_unknown=’value’ 或 handle_missing=’value’ 参数自定义。
管道集成
与 scikit-learn 的 Pipeline 结合:
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
pipeline = Pipeline([
('encoder', TargetEncoder(cols=['city'])),
('model', LogisticRegression())
])
pipeline.fit(X_train, y_train)
多列同时编码
通过 cols 参数指定需要编码的列:
encoder = TargetEncoder(cols=['city','gender'])
编码方法选择指南
| 编码方法 | 适用场景 | 优点 | 缺点 |
| One-Hot | 低基数特征,线性模型 | 无信息损失 | 高维稀疏,不适合高基数 |
| Target | 高基数特征,非树模型 | 保留类别与目标关系 | 需防止过拟合和数据泄露 |
| CatBoost | 高基数特征,树模型 | 避免目标泄露 | 计算成本较高 |
| Ordinal | 有序分类变量 | 保留顺序信息 | 不适用于无序类别 |
| Count | 捕捉类别频率信息 | 简单快速 | 可能引入噪声 |
注意事项
- 过拟合风险:目标编码、CatBoost编码等方法需通过交叉验证或平滑处理避免过拟合。
- 数据泄露:确保在训练集上拟合编码器,测试集仅调用transform。
- 类别顺序:序数编码需手动定义映射关系,避免错误排序。
手撕版目标编码
代码内容
class TargetEncoder(BaseEstimator, TransformerMixin):
"""
目标编码器(Target Encoding)
该编码器用于将类别变量转换为数值变量,计算每个类别对应的目标变量的加权均值,并进行平滑处理,以减少过拟合。
参数:
- smooth: 平滑参数,用于调整类别均值与全局均值之间的平衡,默认值为0.5。
属性:
- encodings_: 存储类别变量的目标编码映射。
- global_mean_: 存储目标变量的全局均值(所有类别整体的均值)。
"""
def __init__(self, smooth=0.5):
self.smooth = smooth # 平滑参数,防止小样本类别的编码值过拟合
self.encodings_ = None # 存储类别到目标均值的映射
self.global_mean_ = None # 存储目标变量的全局均值
def fit(self, X, y, sample_weight=None):
"""
训练目标编码器,计算每个类别的加权均值,并存储编码映射。
参数:
- X: 类别变量(1D数组或Pandas Series)。
- y: 目标变量(1D数组)。
- sample_weight: 样本权重(可选),用于加权计算类别均值。
返回:
- self(返回自身,以便支持scikit-learn兼容接口)。
"""
X = X.ravel() # 将输入转换为一维数组
df = pd.DataFrame({'category': X, 'target': y}) # 创建DataFrame以便处理类别数据
# 如果未提供样本权重,则默认为1
if sample_weight is None:
sample_weight = np.ones(len(X))
df['weight'] = sample_weight # 将样本权重添加到DataFrame
# 计算全局加权均值(用于平滑处理和未知类别填充)
total_weight = df['weight'].sum()
if total_weight <= 1e-7: # 避免除零错误
self.global_mean_ = 0.0
else:
self.global_mean_ = (df['target'] * df['weight']).sum() / total_weight
# 计算每个类别的加权目标均值
grouped = df.groupby('category').agg(
sum_product=pd.NamedAgg(column='target', aggfunc=lambda x: (x * df.loc[x.index, 'weight']).sum()),
sum_weight=pd.NamedAgg(column='weight', aggfunc='sum'),
count=pd.NamedAgg(column='target', aggfunc='size')
)
# 计算平滑后的目标编码值
numerator = grouped['sum_product'] + self.smooth * self.global_mean_ # 平滑处理
denominator = grouped['sum_weight'] + self.smooth
self.encodings_ = numerator / denominator # 计算最终的目标编码值
return self # 返回自身,符合scikit-learn规范
def transform(self, X):
"""
使用训练好的目标编码器将类别变量转换为数值变量。
参数:
- X: 类别变量(1D数组或Pandas Series)。
返回:
- 转换后的目标编码值(NumPy数组,形状为(n_samples, 1))。
"""
category = pd.Series(X.ravel()) # 转换为Pandas Series以便映射
encoded = category.map(self.encodings_).fillna(self.global_mean_) # 缺失类别用全局均值填充
return encoded.values.reshape(-1, 1) # 保持scikit-learn兼容性,返回二维数组
代码解读
与 category_encoders.TargetEncoder的对比:
| 特性 | category_encoders.TargetEncoder | 手写 TargetEncoder |
| 直接支持 Pandas DataFrame | ✅ | ❌(手写版要求 X 是 NumPy 数组) |
| 平滑处理 | ✅(smoothing 参数) | ✅(smooth 参数) |
| 兼容 Scikit-learn Pipeline | ✅ | ✅ |
| 处理未知类别 | ✅(可以指定 handle_unknown) | ✅(用全局均值填充) |
| 处理数据权重 | ❌(默认不支持) | ✅(手写版支持 sample_weight) |
- 如果你的数据没有权重要求,直接使用 TargetEncoder 更方便。
- 如果需要加权目标均值(考虑样本权重),则仍需使用自定义 TargetEncoder。
- 两者都支持平滑处理,防止小样本类别的过拟合。
平滑系数计算逻辑:
numerator = grouped['sum_product'] + self.smooth * self.global_mean_ denominator = grouped['sum_weight'] + self.smooth self.encodings_ = numerator / denominator
- 分子: 类别的加权目标值 + 平滑因子 × 全局均值
- 分母: 类别的总权重 + 平滑因子
- 平滑编码公式: $\text{编码值}=\frac{\sum(y\times w)+\text{smooth}\times\text{全局均值}}{\sum(w)+\text{smooth}}$
- 作用:
- 若类别样本多,则编码值接近该类别的加权均值。
- 若类别样本少,则编码值趋向全局均值。
类别特征的分组
代码内容
def category_feature_binning(df, category_col='category_feature', target_col='target_feature', max_bins=10, min_group_ratio=0.01):
"""
对类别变量进行分箱(Binning),使用目标编码(TargetEncoding)和决策树(DecisionTree)进行分类。
该函数动态调整 min_samples_frac,确保在不同数据量下合理设置最小样本数,避免过度分裂或合并。
参数:
df: pandas.DataFrame
输入数据集,包含类别特征和目标变量。
category_col: str
需要进行分箱的类别特征列名。
target_col: str
目标变量列名。
max_bins: int, optional
最大分箱数量,默认值为 10。
返回:
list
经过分箱后的类别列表,每个列表中的元素属于同一个分箱。
"""
# 取出类别特征和目标变量
category_data = df[category_col]
target = df[target_col].astype('category').cat.codes
total_samples = len(df)
# 动态调整 min_samples_frac
if total_samples < 10000:
min_samples_frac = 0.001 # 小数据集
elif total_samples < 100000:
min_samples_frac = 0.0005 # 中等数据集
else:
min_samples_frac = 0.0001 # 大数据集
# 计算类别出现次数(用于后续排序)
category_counts = category_data.value_counts().to_dict()
# 计算目标变量的类别分布,防止样本不均衡
class_counts = df[target_col].value_counts()
class_weights = {k: total_samples / (len(class_counts) * v) for k, v in class_counts.items()}
# 目标变量的权重映射
sample_weights = df[target_col].map(class_weights).fillna(1).values
# 存储分组
groups = []
stack = [(category_data, target, sample_weights)]
current_bins = 0 # 当前分箱数量
while stack:
if current_bins >= max_bins:
break # 达到最大分箱数,停止
curr_category, curr_target, curr_weights = stack.pop()
unique_category = curr_category.unique()
# 如果类别数量小于 2,则直接归入一组
if len(unique_category) < 2:
groups.append(list(set(unique_category)))
continue
# 目标编码
try:
encoder = TargetEncoder()
encoded = encoder.fit_transform(
curr_category.to_numpy().reshape(-1, 1),
curr_target.to_numpy(),
sample_weight=curr_weights
)
except:
groups.append(list(set(unique_category)))
continue # 目标编码失败,直接加入分组
# 训练决策树
try:
tree = DecisionTreeClassifier(
max_depth=1, # 仅允许一次分裂
min_impurity_decrease=0.001,
min_weight_fraction_leaf=max(min_samples_frac * 0.1, 0.001) # 动态调整最小权重
)
tree.fit(encoded, curr_target, sample_weight=curr_weights)
except:
groups.append(list(set(unique_category)))
continue # 决策树训练失败,直接加入分组
# 确保分裂有效
if tree.tree_.node_count <= 1:
groups.append(list(set(unique_category)))
continue # 分裂无效,直接加入分组
# 获取分裂阈值
threshold = tree.tree_.threshold[0]
left_mask = np.squeeze(encoded) <= threshold
# 计算左右分组的样本总权重
min_weight = total_samples * min_samples_frac
left_weight = curr_weights[left_mask].sum()
right_weight = curr_weights[~left_mask].sum()
# 确保左右分支样本数足够,否则不分裂
if left_weight < min_weight or right_weight < min_weight:
groups.append(list(set(unique_category)))
continue
current_bins += 1 # 计数分箱数
# 递归处理左右分支
stack.append((curr_category[~left_mask], curr_target[~left_mask], curr_weights[~left_mask]))
stack.append((curr_category[left_mask], curr_target[left_mask], curr_weights[left_mask]))
# 处理未分箱类别
while stack:
remaining_cities, _, _ = stack.pop()
groups.append(list(set(remaining_cities.unique())))
# 合并小类别
merged_groups = []
for group in groups:
if not merged_groups:
merged_groups.append(group)
continue
# 计算类别的占比
group_ratio = category_data.isin(group).mean()
if group_ratio < min_group_ratio:
merged_groups[-1].extend(group) # 直接合并
merged_groups[-1] = list(set(merged_groups[-1])) # 去重
else:
merged_groups.append(group)
# 控制最终分箱数量
if len(merged_groups) > max_bins:
# 按类别出现频率排序
sorted_groups = sorted(
merged_groups,
key=lambda g: -sum(category_counts.get(c, 0) for c in g),
reverse=True
)
# 只保留前 max_bins-1 组
merged_groups = sorted_groups[:max_bins - 1]
remaining = [c for group in sorted_groups[max_bins - 1:] for c in group] # 其他类别归为一组
if remaining:
merged_groups.append(remaining)
# 最终排序
final_groups = []
for group in merged_groups:
sorted_group = sorted(
list(set(group)),
key=lambda x: (-category_counts.get(x, 0), x) # 先按频率降序,再按字母序
)
final_groups.append(sorted_group)
return final_groups[:max_bins] # 限制最大分箱数
代码解读
这段代码实现了对类别特征进行分箱的功能,结合目标编码(TargetEncoding)和决策树(DecisionTree)的方法,动态调整分箱策略以确保合理性。以下是对代码的详细解读和关键点总结:
核心逻辑
- 动态参数调整。根据数据量调整最小样本比例 min_samples_frac,避免小数据集过拟合或大数据集欠拟合):
-
- 小数据集(<10k 样本):min_samples_frac=0.001
中数据集(10k-100k):min_samples_frac=0.0005
-
- 大数据集(>100k):min_samples_frac=0.0001
- 目标编码与决策树分箱
- 目标编码:将类别特征转换为目标变量的统计量(如均值),生成连续值用于分裂。
- 单层决策树:使用max_depth=1 的决策树寻找最佳分裂点,确保每次分裂有意义(min_impurity_decrease=0.001)。
- 递归分裂与终止条件
- 利用栈(Stack)递归处理每个子集,分裂左右分支直至达到max_bins 或无法有效分裂。
- 检查分裂后的样本权重是否足够(min_weight=total_samples*min_samples_frac),否则放弃分裂。
- 后处理与合并
- 合并小分箱:全局占比小于1%的组合并到前一个分箱。
- 控制分箱数:按类别频率排序,保留高频分箱,剩余类别归为“其他”。


