现在再写这篇文章感觉有些不合时宜,目前,貌似很少人再讨论大数据,也很少人再讨论Hadoop。整理这篇文章,是为了探寻最新的技术方向。
新技术替代的组件
Hadoop技术栈的许多组件已经被功能更强、性能更高的新技术所取代。以下是Hadoop主要组件及其替代技术的简要分析:
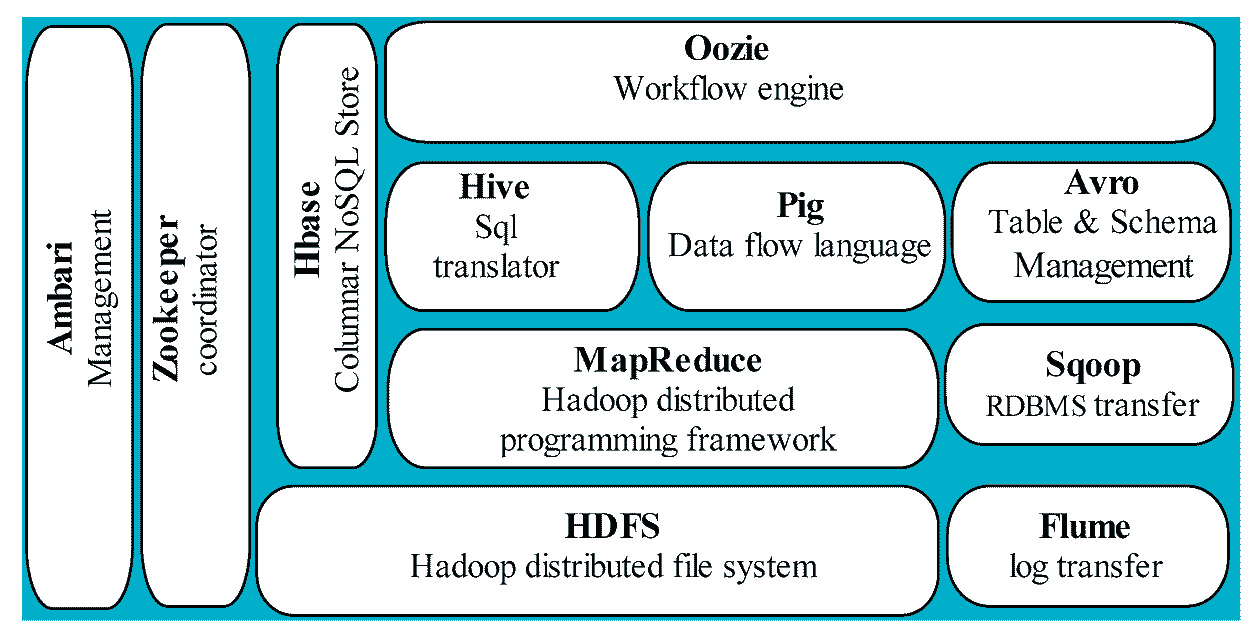
HDFS(Hadoop分布式文件系统)
- 角色:分布式存储系统,用于存储大规模数据。
- 替代技术:
- Apache Hudi、Delta Lake、Apache Iceberg:这些新兴的数据湖框架提供了高效的数据管理、事务支持和数据版本控制功能,是构建现代数据湖的关键。
- 云存储:如Amazon S3、Google Cloud Storage和Azure Data Lake Storage等云存储解决方案支持更灵活的存储扩展,且无需运维。
- 分布式文件系统:Ceph、GlusterFS等也在特定场景下作为替代方案。
MapReduce
- 角色:Hadoop的核心计算框架,采用批处理模式。
- 替代技术:
- Apache Spark:提供内存计算、批处理和流处理能力,性能远超MapReduce。
- Apache Flink:专注于实时流处理,同时支持批处理任务。
- Presto/Trino:支持快速的分布式SQL查询,尤其适合交互式分析。
- Google Dataflow:在云计算中提供高效的批处理和流式数据处理。
YARN(资源管理器)
- 角色:负责集群资源调度和任务管理。
- 替代技术:
- Kubernetes:成为通用的资源调度和管理平台,不仅支持大数据计算任务,还能运行机器学习模型和其他容器化工作负载。
- Apache Mesos:更灵活的资源管理框架,适用于混合工作负载。
- Databricks和云端服务:许多新平台直接内置资源管理功能,无需用户单独部署YARN。
Hive(数据仓库工具)
- 角色:基于HDFS的数据仓库工具,支持SQL查询。
- 替代技术:
- Amazon Redshift、Google BigQuery、Snowflake:云原生数据仓库,性能和功能更强大。
- Apache Impala:专注于高性能的交互式查询。
- Presto/Trino:支持跨多种数据源的高效查询,取代了Hive在交互式查询场景中的地位。
- Databricks SQL:专为云数据湖优化的查询引擎。
Pig(数据流脚本语言)
- 角色:用于处理复杂数据流任务的高级语言。
- 替代技术:
- Apache Spark:通过简洁的API实现相同功能,Python/Scala等语言的广泛应用也降低了Pig的吸引力。
- SQL工具:随着SQL在大数据领域的广泛支持,Pig的需求减少。
HBase(NoSQL数据库)
- 角色:HDFS之上的列式NoSQL数据库,适合随机读写。
- 替代技术:
- Apache Cassandra:更成熟的分布式NoSQL数据库,性能和易用性更强。
- Google Bigtable:云原生列式存储系统,具有高可用性和扩展性。
- Amazon DynamoDB:强大的云端NoSQL解决方案。
ZooKeeper(协调服务)
- 角色:为分布式系统提供协调服务。
- 替代技术:
- Kubernetes:不仅用于资源管理,还能解决部分分布式协调问题。
- etcd、Consul:现代分布式系统的协调服务,功能更强大,部署更简单。
Oozie(工作流调度)
- 角色:用于调度Hadoop作业的工作流调度工具。
- 替代技术:
- Apache Airflow:现代化的工作流调度工具,支持多种任务类型和云环境。
- Luigi:轻量级调度工具,适合复杂依赖任务的管理。
- Dagster:更注重任务的实时监控和数据依赖管理。
Sqoop(数据迁移工具)
- 角色:用于在 HDFS 和关系型数据库之间传输数据。
- 替代技术:
- Apache Nifi:更灵活的数据集成工具,支持实时流式和批量数据传输。
- StreamSets:提供强大的数据管道构建能力。
- 云服务集成工具:如 AWS Glue、Google Cloud Dataflow,直接集成关系型数据库和云存储。
Flume(日志采集工具)
- 角色:用于日志和事件的收集与传输。
- 替代技术:
- Apache Kafka:成为事实上的流式数据传输标准,功能更强大且可扩展。
- Logstash:与 Elasticsearch 和 Kibana(ELK 堆栈)配合使用的日志采集工具。
Hadoop 技术栈的大多数组件已被性能更高、功能更全面、开发体验更好的工具和平台所取代。特别是在云计算和实时处理需求快速增长的背景下,传统的 Hadoop 技术栈难以适应现代化数据处理的需求。
Hadoop 被取代的原因
Hadoop 技术栈虽然在大数据领域有过辉煌时期,但随着新技术的出现,其劣势逐渐显现,导致被一些更先进的技术所取代。以下是主要原因:
- 架构复杂性
- Hadoop 的劣势:Hadoop 的分布式架构(如 HDFS 和 MapReduce)过于复杂,需要协调多个服务(如 YARN、HDFS、MapReduce、ZooKeeper 等),配置和维护工作量大。
- 新技术的优势:新技术(如 Apache Spark、Snowflake)简化了架构。例如,Spark 集成了内存计算和批处理功能,无需像 Hadoop 那样依赖多个独立的组件。
- 性能问题
- Hadoop 的劣势:Hadoop MapReduce 采用基于磁盘的计算模型,任务调度和 I/O 操作频繁,导致性能较低。
- 新技术的优势:Apache Spark 利用内存计算,大大提高了处理速度,特别是在迭代计算(如机器学习)和实时数据处理场景中。
- 实时计算能力不足
- Hadoop 的劣势:Hadoop 的设计主要面向批处理任务,对于实时流数据(如物联网、金融交易)支持不足。
- 新技术的优势:如 Apache Flink 和 Spark Streaming 专为流处理优化,可以更高效地处理实时数据。
- 开发效率较低
- Hadoop 的劣势:开发 MapReduce 任务需要编写大量样板代码,导致开发效率低下。
- 新技术的优势:如 Spark 提供更简洁的 API,支持 Scala、Python 和 SQL 等多种语言,极大提高了开发效率。
- 存储和计算紧耦合
- Hadoop 的劣势:Hadoop 的 HDFS 和计算资源是绑定的,扩展计算能力时往往需要增加存储能力,资源利用率不高。
- 新技术的优势:现代云原生数据平台(如 Snowflake 和 Databricks)将存储与计算解耦,允许独立扩展,资源分配更灵活。
- 生态系统的转变
- Hadoop 的劣势:Hadoop 生态虽然庞大,但技术栈较旧,新功能的开发缓慢,适应性逐渐降低。
- 新技术的优势:许多新技术(如 Delta Lake、Iceberg 等)是为现代化数据需求(如数据湖、实时查询、数据治理)设计的,生态系统更为灵活和现代化。
- 云计算的崛起
- Hadoop 的劣势:Hadoop 的设计偏向于本地部署,而在云端部署时并不高效。
- 新技术的优势:云原生技术(如 Google BigQuery、Amazon Redshift)对云环境进行了深度优化,更易于使用和扩展。
- 成本问题
- Hadoop 的劣势:Hadoop 集群需要大量物理资源,维护成本较高。
- 新技术的优势:新一代大数据技术通常更高效,能够以较少的资源处理更多数据,从而降低成本。
虽然 Hadoop 仍在某些特定场景下(如批量数据处理、离线分析)有一定应用,但随着数据处理需求向实时性、高效率、云原生方向发展,Hadoop 技术栈显得不再适合主流大数据场景,逐渐被更现代化的工具所取代。
Hadoop 的抉择
Hadoop 与 Google
Hadoop 与 Google 的GFS、GMR 和BigTable 有密切的关系,主要是因为 Hadoop 的设计思想和技术架构深受它们的启发。以下是它们之间的详细关系:
GFS 和 Hadoop HDFS
- GFS (Google File System) 是 Google 设计的分布式文件系统,用于存储大规模数据并支持高吞吐量访问。Hadoop 的文件系统 HDFS (Hadoop Distributed File System) 直接基于 GFS 的论文设计。
- 相似之处:
- 块存储:HDFS 和 GFS 都将文件分成较大的数据块(典型为 64MB 或更大),并分布存储在集群中的节点上。
- 主从架构:两者都采用主从结构(GFS 使用 Master,HDFS 使用 NameNode)来管理元数据和存储位置。
- 容错性:通过多副本(通常为 3 份)存储数据,确保容灾能力。
- 不同之处:
- HDFS 更适配开源社区需求,运行于廉价硬件上。
- HDFS 的具体实现加入了对 Java 生态的支持,而 GFS 在 Google 内部是专有技术。
GMR 和 Hadoop MapReduce
- Google MapReduce (GMR) 是 Google 于 2004 年发表的分布式计算框架,用于处理大规模数据。Hadoop 的 MapReduce 直接基于 GMR 的论文实现。
- 相似之处:
- 任务划分:MapReduce 将计算任务分成两个阶段:Map(映射)和 Reduce(归约),以并行方式处理数据。
- 容错机制:两者都通过任务失败时的自动重试和任务调度来保证计算的可靠性。
- 数据本地化:尽可能将计算任务分配到存储数据的节点,减少网络开销。
- 不同之处:
- Google MapReduce 在 Google 内部运行,与 GFS 高度耦合。
- Hadoop MapReduce 是开源实现,灵活性更高,支持多种数据存储系统(如 HDFS、Amazon S3 等)。
BigTable 和 Hadoop HBase
- BigTable 是 Google 开发的分布式列式数据库,旨在处理结构化数据并支持快速随机读写。Hadoop 生态系统中的 HBase 是受 BigTable 启发的开源实现。
- 相似之处:
- 列式存储:两者都以列为单位存储数据,适合宽表设计和稀疏数据。
- 可扩展性:支持大规模数据存储和横向扩展。
- 分布式架构:数据按键值范围划分并存储在不同的节点上,支持高并发访问。
- 不同之处:
- BigTable 使用 Google 的专有技术(如 GFS、Spanner)支持,而 HBase 运行在 HDFS 之上,依赖于 Hadoop 生态。
- BigTable 提供更强的一致性保证,而 HBase 通过协处理器扩展功能实现近似的能力。
Google 的自我革新
Google 的GFS (Google File System)、GMR (Google MapReduce) 和BigTable 在其内部的替代技术发展上,主要受到大数据处理需求和云原生架构的驱动。随着技术的进步,Google 不断优化其基础设施和大数据平台,许多新技术逐渐取代了这些原始系统的功能。以下是 Google 内部对这些技术的替换和改进:
GFS (Google File System) 替代技术
Google File System (GFS) 设计为支持大规模数据存储和分布式计算,但随着技术的进步,特别是在云计算和分布式存储领域,Google 已逐步过渡到以下技术:
- Colossus:
- Colossus 是 GFS 的继任者,是 Google 内部的下一代分布式文件系统。Colossus 设计了更高效、更可靠的存储架构,支持大规模的文件存储和管理。
- 它提供了更高的容错性、更强的数据一致性和更灵活的数据访问控制,优化了存储性能并支持更复杂的应用场景。
- Colossus 广泛应用于 Google 的各种云服务,包括 Google Cloud Storage。
- Google Cloud Storage (GCS):Google Cloud Storage 是 Google 为外部客户提供的云存储服务。它基于 Google 内部的 Colossus 技术,支持对象存储,提供高可用性、低延迟和弹性扩展能力,是现代云原生应用的理想选择。
GMR (Google MapReduce) 替代技术
Google MapReduce 作为 Google 早期的分布式数据处理框架,虽然在其时代非常成功,但随着技术进步和对实时数据处理的需求增加,它被更先进的框架所取代:
- Apache Flume 和Apache Beam:
- Apache Flume 是一个流数据采集工具,专注于从各种数据源(如日志)收集数据并进行分布式传输。
- Apache Beam 是一个统一的大数据处理框架,支持批处理和流处理,它提供了比 MapReduce 更灵活和高效的编程模型。Google 通过 Dataflow(一个完全托管的 Apache Beam 服务)支持 Beam 的执行。
- Google Cloud Dataflow:
- Google Cloud Dataflow 是基于 Apache Beam 构建的流处理和批处理服务。Dataflow 支持大规模的数据处理任务,提供更高效的数据管道管理功能,且支持实时流数据和批数据的无缝整合。
- Google Cloud Dataproc:
- Google Cloud Dataproc 是一个托管的 Hadoop 和 Spark 服务,可以运行在 Google Cloud 上,用于大规模数据分析。Dataproc 支持 Hadoop 的 MapReduce 计算模型,但更加灵活,并且可以与 Google Cloud 的其他服务(如 BigQuery、Cloud Storage)集成。
BigTable 替代技术
BigTable 是 Google 为存储和查询大规模结构化数据而设计的分布式列式数据库。它为许多 Google 内部的应用提供支持,如搜索、YouTube 和 Gmail。随着时间的推移,Google 在这方面也做出了改进:
- Spanner:
- Spanner 是 Google 的下一代分布式数据库,它结合了关系型数据库的 ACID 特性和 NoSQL 的可扩展性。Spanner 广泛用于 Google 内部和外部的业务应用中,支持全球分布式事务和强一致性。
- 它通过全球同步时钟(TrueTime API)实现分布式一致性,是 Google 的一项关键创新,广泛用于金融、电商等对事务一致性要求高的场景。
- Bigtable 的云原生替代 – Google Cloud Bigtable:
- Google Cloud Bigtable 是一个由 Google 提供的完全托管的 NoSQL 列式数据库,基于内部的 Bigtable 架构,适用于大规模的数据存储和分析。它特别适合高吞吐量、低延迟的数据访问,如物联网(IoT)应用和用户行为分析。
- 作为 BigTable 的托管版,Google Cloud Bigtable 提供了高可用性、弹性扩展和与 Google Cloud 平台其他服务(如 BigQuery、Dataflow)的紧密集成。
- Firestore 和 Cloud Datastore:
- Firestore 是 Google Cloud 上的 NoSQL 文档数据库,适合存储和查询结构化数据,尤其适合开发现代应用。与 BigTable 相比,Firestore 更侧重于文档存储和更细粒度的查询。
- Cloud Datastore 提供分布式、可扩展的 NoSQL 数据库服务,主要用于结构化数据存储。
Google 已经逐步用更现代和灵活的技术替代了 GFS、GMR 和 BigTable,主要通过以下几个核心技术:
- Colossus 替代 GFS,提供更高效的分布式文件存储。
- Cloud Dataflow(基于 Apache Beam)和 Apache Flink 替代 GMR,支持实时流处理和批处理。
- Cloud Spanner 替代 BigTable,提供强一致性的分布式数据库服务,支持事务处理。
- Cloud Bigtable 保持与 BigTable 类似的列式存储,但提供更高的云集成性和可管理性。
这些替代技术不仅改进了性能,还为现代的云原生应用提供了更强的支持,尤其是在分布式数据存储、处理效率和全球一致性方面。
Hadoop 为何不改进自己?
Hadoop 没有显著”改进自己”以适应新的大数据需求,主要因为以下几个原因:
技术架构的局限性
Hadoop 的核心架构设计于 2000 年代初,面向当时的数据需求和硬件环境。随着技术进步,其架构限制逐渐显现:
MapReduce 局限性:
- MapReduce 模型虽然适合批量处理,但对实时性和低延迟场景不友好。
- 现代计算框架(如 Apache Spark、Flink)通过内存加速和多模式处理(批处理+流处理)已经显著优化。
HDFS 缺乏灵活性:
- HDFS 主要设计用于大文件的顺序读写,缺乏对小文件和随机读写的支持。
- 云存储(如 Amazon S3、Google Cloud Storage)以更好的扩展性和灵活性取代了它。
新技术的快速崛起
- 随着 Apache Spark、Presto、Trino、Snowflake 等新技术的兴起,企业开始转向性能更高、使用更方便的替代方案。
- 新技术提供了对现代化需求(如实时处理、多数据源支持、云原生架构)的更好适配,削弱了 Hadoop 继续改进的意义。
社区开发与投入减少
Hadoop 是开源项目,依赖社区推动发展:
- 开发者和资源转移:开发者和社区力量逐渐转移到更新的开源项目(如 Spark、Flink、Kafka)。
企业支持下降:如 Cloudera、Hortonworks 等曾支持 Hadoop 的企业,现在也更多专注于云端产品和现代大数据框架。
云计算和数据湖的兴起
- 云优先策略:现代企业更倾向于使用云原生解决方案(如 BigQuery、Redshift、Databricks),减少了对 Hadoop 本地部署的需求。
- 数据湖架构的替代:现代数据湖(如 Delta Lake、Apache Iceberg)以更灵活的存储和元数据管理替代了 Hadoop 的传统架构。
改进成本与性价比
Hadoop 的改进成本高,但市场需求逐渐萎缩:
- 技术债务:Hadoop 的核心模块(如 MapReduce 和 HDFS)需要重写以实现重大改进,但这会与已有生态系统不兼容。
- ROI 问题:相比于持续改进 Hadoop,开发者和企业更倾向于投资在全新、具备竞争优势的技术上。
Hadoop 生态仍有特定场景价值
尽管如此,Hadoop 仍在以下场景中有一定应用:
- 批处理场景:如大规模日志分析和历史数据处理。
- 低成本解决方案:在已有 Hadoop 集群的企业中,仍然是低成本选项。
Hadoop 在设计和市场定位上已经不适合现代大数据需求。面对云计算、实时分析和内存计算的技术浪潮,它的架构改进需要巨大投入,且市场需求不足以支持这些改动。因此,Hadoop 的发展逐渐趋于稳定,开发者和企业更多将资源投入到更先进的技术平台中。
Hive 为什么还广泛应用?
尽管许多新技术已经取代了 Hadoop 生态的一些组件,Apache Hive依然在许多场景中被广泛使用。这是因为 Hive 具备以下优势和独特性,使其在一些特定环境中与 Hadoop 生态的紧密集成
- HDFS 支持:Hive 直接运行在 Hadoop 分布式文件系统(HDFS)之上,可以高效处理存储在 HDFS 中的海量数据。
- MapReduce 兼容性:虽然性能上不如 Spark 等新技术,Hive 仍然适合某些批处理任务,尤其是在已有 Hadoop 集群的场景下。
适用场景:传统 Hadoop 集群中的大规模批量数据分析。
类 SQL 接口(HiveQL)
- Hive 提供了 SQL 风格的查询语言(HiveQL),降低了数据工程师和分析师学习和使用的门槛。
- 相比于低层次的 MapReduce 编程,Hive 使数据查询更加直观和高效。
适用场景:数据分析团队希望在熟悉的 SQL 语法下操作大数据,而不愿意直接接触低级代码。
高性价比的数据仓库解决方案
- 对于需要构建大规模数据仓库但预算有限的企业,Hive 可以作为低成本的解决方案,尤其是在已有 Hadoop 集群的情况下。
- 与昂贵的云原生数据仓库(如 Snowflake、BigQuery)相比,Hive 部署成本较低(特别是在本地化环境中)。
适用场景:中小企业希望在已有基础设施上扩展数据分析能力,而无需投资昂贵的新技术。
与现代查询引擎的兼容性
Hive 作为元数据管理系统(Metastore)被许多现代化查询引擎使用:
- Presto/Trino:直接读取 Hive Metastore 的元数据,用于高效的交互式查询。
- Apache Spark SQL:可以与 Hive 集成,实现更高效的 SQL 查询。
- Impala:与 Hive 共享存储和元数据,提供低延迟查询。
适用场景:需要结合不同查询引擎实现多样化数据处理和分析的场景。
社区成熟与丰富的工具支持
- Hive 在大数据领域的应用已经有多年历史,工具支持丰富(如 Apache Oozie、Sqoop 等),社区成熟且文档齐全。
- 对于传统 Hadoop 用户,Hive 生态相对稳定,迁移成本较低。
适用场景:已经广泛使用 Hadoop 技术栈的企业。
适合离线数据处理
- Hive 的批处理性能尽管较慢,但对于某些不需要实时性的离线任务(如日志归档分析、数据清洗和大规模数据统计)依然可以胜任。
- Hive 支持复杂的 ETL 任务和数据管道构建。
适用场景:离线数据处理和历史数据归档。
持续改进与性能优化
新版本的 Hive 已经支持 Apache Tez 和 Apache LLAP 等高性能计算引擎,极大改善了传统 MapReduce 的低效问题。
随着 Hive 3.x 版本的发布,性能和功能都有显著改进:
- 支持事务处理(ACID)。
- 提升并发查询性能。
- 支持复杂数据类型和动态分区。
适用场景:需要 ACID 事务支持的大规模数据处理场景。
数据湖架构中的关键角色
- Hive Metastore 作为数据湖的元数据管理层,被多个现代数据湖框架(如 Delta Lake、Iceberg、Hudi)使用。
- Hive 不仅可以用作传统数据仓库,还可以作为数据湖的一部分,在分布式存储系统中管理和查询数据。
适用场景:数据湖场景中需要兼容多种存储格式(如 Parquet、ORC)和查询引擎的环境。
数据迁移与历史兼容性
- 在已有 Hadoop 和 Hive 系统的企业中,直接替换 Hive 需要耗费大量时间和成本。
- Hive 提供的兼容性和工具链(如 Sqoop、Flume)可以帮助企业逐步向现代化数据架构迁移。
适用场景:数据迁移过渡期,Hive 作为现有系统的核心组件依然被保留。
总结
Hive 并未完全被淘汰,而是在现代数据架构中发挥着以下作用:
- 传统 Hadoop 生态中的数据仓库工具。
- 元数据管理系统,为新引擎提供兼容支持。
- 高性价比的离线数据处理工具。
- 数据湖架构中的关键角色。
对于已经部署了 Hadoop 的企业,Hive 依然是可靠的选择,而在现代化改造过程中,Hive 的兼容性和丰富工具链也为迁移提供了便利。


