Flume简介
Flume是一个分布式、可靠且高效的系统,主要用于大规模日志数据的收集、聚合和传输。它是Apache软件基金会的一个开源项目,特别适合将大量日志数据从不同的数据源转移到一个集中式的数据存储系统,比如Hadoop的HDFS(Hadoop Distributed File System)。
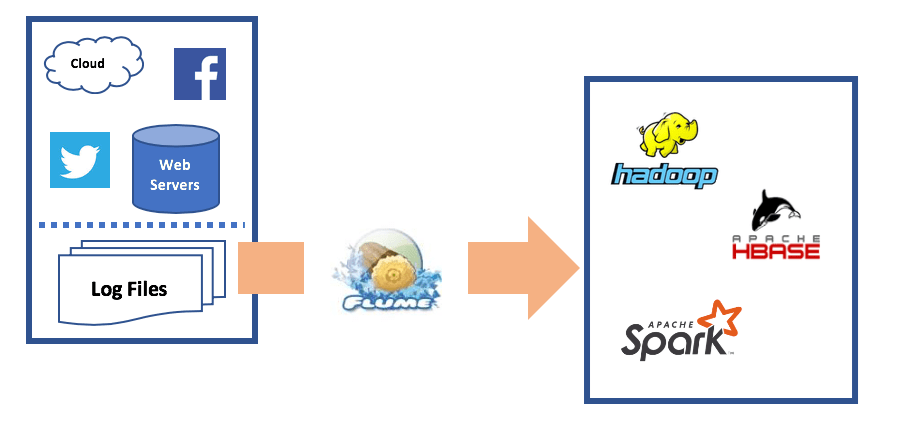
关键特性
- 可扩展性:Flume可以轻松扩展以处理大规模的数据流,支持水平扩展。
- 可靠性:通过事务机制保证数据从源到目的地的可靠传输,避免数据丢失。
- 多源支持:Flume支持多种数据源,包括日志文件、网络流等,能够灵活地从不同的源收集数据。
- 数据传输灵活性:支持多种传输方式和协议,可以适应不同的网络环境和数据类型。
- 容错性:Flume具备良好的容错能力,可以在节点故障时自动恢复。
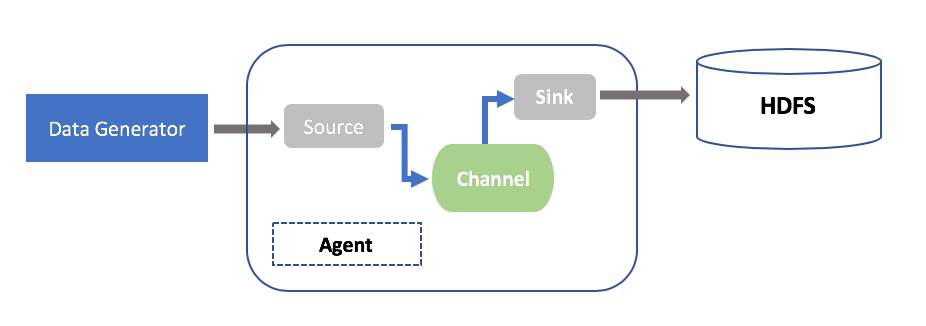
工作流程
Flume的工作流程通常如下:
- 数据收集:Source从数据源获取事件数据,并将其传输到Channel。
- 数据缓冲:Channel作为数据的暂存地,确保数据的可靠传输。
- 数据传输:Sink从Channel获取数据,并将其发送到指定的目的地。
使用场景
- 日志数据收集:Flume可以从服务器、应用程序等不同来源收集日志数据。
- 实时分析:结合其他实时分析工具,Flume可以用于流式数据的实时处理和分析。
- 数据备份和迁移:Flume可以用于将数据从一个存储系统迁移到另一个系统。
Flume是一个强大的工具,特别适合需要处理大规模、分布式数据收集和传输的场景。通过其灵活的架构和丰富的插件支持,Flume能够适应各种不同的应用需求。
Flume的架构
Apache Flume的架构设计简单而灵活,旨在有效地收集、聚合和传输大规模的数据流。Flume的架构主要由以下几个核心组件组成:Agent、Source、Channel和Sink。每个组件都有特定的角色和功能,下面详细介绍这些组件及其相互作用。
Flume架构组件
- Agent
- 定义:Agent是Flume的基本运行单元,通常部署在数据源所在的服务器上。
- 功能:每个Agent由一个或多个Source、Channel和Sink组成,负责管理这些组件的协作。
- Source
- 定义:Source是Flume的数据入口,负责从外部数据源收集事件数据。
- 类型:支持多种Source类型,如Avro Source、Syslog Source、HTTP Source、Spooling Directory Source等。
- 功能:Source接收到的数据被封装成事件,并推送到Channel。
- Channel
- 定义:Channel是数据的临时存储区,连接Source和Sink。
- 类型:常用的Channel类型有Memory Channel和File Channel。
- Memory Channel:速度快,但易失,适合对数据可靠性要求不高的场景。
- File Channel:可靠性高,适合对数据持久性要求较高的场景。
- 功能:Channel提供了数据的缓冲功能,确保数据能够被可靠地传输到Sink。
- Sink
- 定义:Sink是Flume的数据出口,负责将数据传输到目标存储系统。
- 类型:支持多种Sink类型,如HDFS Sink、HBase Sink、Kafka Sink等。
- 功能:Sink从Channel中消费数据,并将其写入到指定的目的地。
- Sink Processor
- 定义:Sink Processor管理多个Sink的调度和容错。
- 功能:支持多种策略,如负载均衡、故障转移等,确保数据传输的高可用性。
- Interceptors
- 定义:Interceptors是可选组件,用于在数据进入Channel之前对事件进行修改或过滤。
- 功能:可以实现数据清洗、格式转换、字段添加等操作。
Flume的部署
Apache Flume的部署过程相对灵活,可以根据具体的需求和环境进行调整。以下是Flume部署的一般步骤和考虑因素:
部署准备
环境准备:
- 确保服务器上安装了Java(Flume需要Java运行环境)。
- 下载并解压Flume的发行包,可以从Apache Flume官方网站获取。
网络配置:
- 确保Flume各个节点之间的网络通信正常。
- 配置必要的防火墙规则以允许Flume所需的端口通信。
部署架构
Flume的部署可以是单节点,也可以是多节点的复杂架构。常见的部署架构包括:
单节点部署:
- 在单个服务器上运行Flume Agent,适用于简单的日志收集任务。
- 配置文件中定义一个Source、Channel和Sink。
多节点部署:
- 分布式部署多个Flume Agent,适合大规模日志收集。
- 各个Agent可以在不同的服务器上运行,负责不同的数据源或目的地。
- 可以配置多级Flume流,以实现数据的聚合和转发。
配置文件
Flume的核心是其配置文件(通常是.conf文件),该文件定义了Flume Agent的行为,包括Source、Channel和Sink的配置。
Source配置:
定义数据的来源,比如Avro、Syslog、Spooling Directory等。
示例:
agent.sources=source1 agent.sources.source1.type=spooldir agent.sources.source1.spoolDir=/var/log/flume
Channel配置:
定义用于暂存数据的通道,比如Memory Channel或File Channel。
示例:
agent.channels=channel1 agent.channels.channel1.type=memory agent.channels.channel1.capacity=1000 agent.channels.channel1.transactionCapacity=100
Sink配置:
定义数据的目的地,比如HDFS、HBase、Kafka等。
示例:
agent.sinks=sink1 agent.sinks.sink1.type=hdfs agent.sinks.sink1.hdfs.path=hdfs://namenode/flume/logs agent.sinks.sink1.hdfs.fileType=DataStream
将Source、Channel和Sink关联:
将Source、Channel和Sink连接起来,形成完整的数据流。
示例:
agent.sources.source1.channels=channel1 agent.sinks.sink1.channel=channel1
启动Flume
启动命令:
使用Flume提供的脚本启动Agent,指定配置文件。
示例命令:
bin/flume-ng agent --conf conf --conf-file example.conf --name agent -Dflume.root.logger=INFO,console
日志和监控:
- 检查Flume的日志文件以确保Agent正常启动并工作。
- 使用Flume的监控接口或日志分析工具监控Flume的性能和健康状态。
高可用性和容错
- 配置多级Agent:使用多个Agent级联以实现数据的冗余和容错。
- 使用可靠的Channel:在需要高可靠性的场景中,使用FileChannel代替MemoryChannel。
- 负载均衡和故障转移:配置多个Sink和SinkProcessor,以实现负载均衡和故障转移。
通过以上步骤,您可以成功部署和配置Apache Flume,以满足不同的日志收集和传输需求。根据具体的使用场景,您可能需要进一步调整配置以优化性能和可靠性。
Flume的展望
Apache Flume并没有被正式淘汰,但其使用和关注度在某些场景下确实有所下降。这主要是因为数据收集和处理领域有了更多的替代方案和技术,这些新工具可能在特定方面提供了更高的性能或更丰富的功能。
以下是一些影响Flume使用情况的因素:
- 新技术的兴起:随着技术的发展,像Apache Kafka、Logstash、Fluentd等工具在数据流处理、日志收集和传输方面提供了更高的灵活性、可扩展性和实时处理能力。这些工具可能更适合某些特定的应用场景。
- 生态系统的集成:一些新工具(如Logstash和Filebeat)与流行的数据分析平台(如Elasticsearch)有更好的集成,用户可能更倾向于使用这些更易于集成的解决方案。
- 社区活跃度:虽然Flume仍然是Apache软件基金会的一个项目,但其社区的活跃度和更新频率相对较低。相比之下,像Kafka和Elastic Stack等项目有更活跃的社区和更频繁的更新。
- 特定需求的变化:随着数据处理需求的演变,用户可能需要更复杂的数据解析、路由和实时处理功能,这些功能可能在其他工具中更容易实现。
尽管如此,Flume仍然是一个稳定、可靠的工具,特别是在需要简单、稳定的日志收集和传输解决方案的场景下。它在某些大规模日志数据收集的场合仍然被广泛使用,特别是与Hadoop生态系统结合使用时。
最终,是否选择Flume取决于具体的需求、现有的技术栈和团队的熟悉程度。如果您当前的系统中Flume工作良好且满足需求,没有特别的理由一定要替换它。然而,如果您正在设计一个新的系统,值得考虑其他可能更适合您特定需求的现代工具。


