Redpanda简介
Redpanda是一种现代流处理平台,旨在提供高性能、低延迟的消息流处理能力。它是一个Kafka API兼容的流处理引擎,专为云原生环境设计,提供了许多改进的特性和功能。

基础特性
- 兼容性:Redpanda与Apache Kafka API兼容,这使得Kafka用户可以无缝迁移或与Redpanda集成,无需修改代码。
- 高性能:Redpanda专为高吞吐量和低延迟而设计。它使用Seastar异步框架和Raft共识算法,可以将平均延迟降低10倍,同时提高Kafka事务速度6倍。
- 简单性:作为单个二进制文件运行,Redpanda简化了部署和管理。它还提供用户友好的Web控制台和命令行界面(Redpanda Keeper),用于集群管理和监控。
- 可扩展性:Redpanda可以轻松水平扩展,允许用户无缝扩展其集群以适应不断增长的工作负载和数据量。
- 可靠性:凭借分布式架构和内置容错机制,Redpanda即使在节点故障的情况下也能确保数据的持久性和可用性。
使用场景与优势
- 实时流处理:Redpanda适用于需要实时处理和分析数据的应用程序,如实时分析、欺诈检测和金融交易。其高性能和可扩展性使其能够处理大量实时数据流,同时保持低延迟。
- 事件驱动架构:Redpanda通过解耦生产者(数据发布者)与消费者(数据订阅者),实现异步通信和可扩展性,从而支持事件驱动的架构。这使得应用程序能够通过交换消息(事件)进行通信,提高了系统的灵活性和响应速度。
- 与其他技术的集成:Redpanda可以与其他技术无缝集成,如Hazelcast和RisingWave等。这种集成使得用户可以构建更加强大和高效的数据处理和分析解决方案。
Redpanda作为一个开源的流数据平台,凭借其高性能、简单性、可扩展性和可靠性等特性,在现代数据密集型应用程序中发挥着重要作用。它提供了与Kafka兼容的API,使得用户能够轻松迁移和集成,同时其独特的架构和设计使得它在处理实时数据流时具有显著优势。
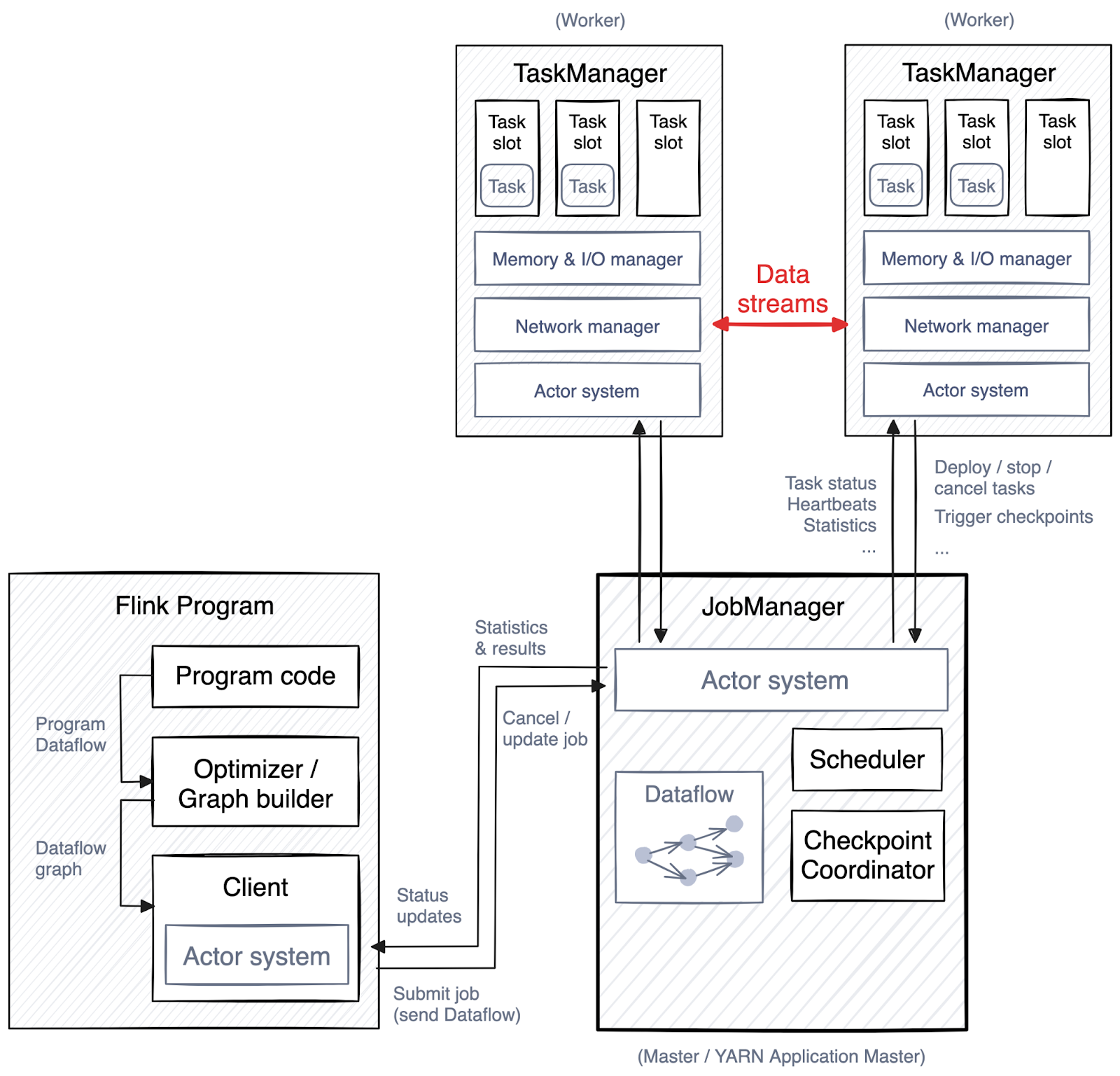
Redpanda与Kafka的对比
Redpanda和Apache Kafka都是流行的流处理平台,用于构建实时数据流和事件驱动的应用程序。尽管它们在功能上有许多相似之处,但在架构、性能和运维等方面存在一些显著的区别。以下是Redpanda和Kafka的详细对比:
| 特性 | Redpanda | Apache Kafka |
| 编程语言 | 使用C++编写,旨在利用现代硬件特性 | 使用Java和Scala编写 |
| 依赖性 | 单二进制文件,不依赖JVM或ZooKeeper | 依赖JVM和ZooKeeper(或KRaft模式) |
| 性能 | 高性能,优化的内存管理和I/O操作,低延迟和高吞吐量 | 性能优秀,但可能需要精心调优JVM和ZooKeeper设置 |
| 部署和管理 | 简化的部署和管理,适合云原生环境,支持Kubernetes | 传统部署需要管理多个组件,ZooKeeper是一个主要依赖项 |
| 存储引擎 | 内置优化的存储引擎,专为快速写入和读取设计 | 基于日志的存储引擎,依赖于磁盘I/O性能 |
| 扩展性 | 水平扩展,通过自动分片和重平衡提高扩展性 | 水平扩展良好,但需要手动配置分区和副本 |
| 生态系统兼容性 | 与Kafka API兼容,支持现有Kafka客户端和工具 | 拥有广泛的生态系统和工具支持,如Kafka Streams和Connect |
| 云原生支持 | 专为云环境设计,支持Kubernetes和容器化部署 | 支持云部署,但需要额外的配置和管理 |
| 多租户支持 | 支持命名空间和ACL,实现多租户环境中的数据隔离 | 支持多租户,但需要配置ACL和授权 |
| 故障恢复 | 内置自动故障恢复和重新平衡机制 | 依赖ZooKeeper(或KRaft)进行元数据管理和故障恢复 |
| 社区和支持 | 开源项目,活跃的社区,提供商业支持和服务 | 大型开源社区,广泛应用于生产环境,企业支持良好 |
Apache Kafka:作为行业标准的流处理平台,Kafka拥有成熟的生态系统和广泛的社区支持。它适合需要复杂集成和生态系统支持的场景,如与Kafka Streams和Kafka Connect的集成。
Redpanda:适合希望简化部署和管理的组织,特别是在云原生环境中。它通过高效的内存和I/O管理提供了卓越的性能,并消除了对ZooKeeper的依赖,从而降低了操作复杂性。
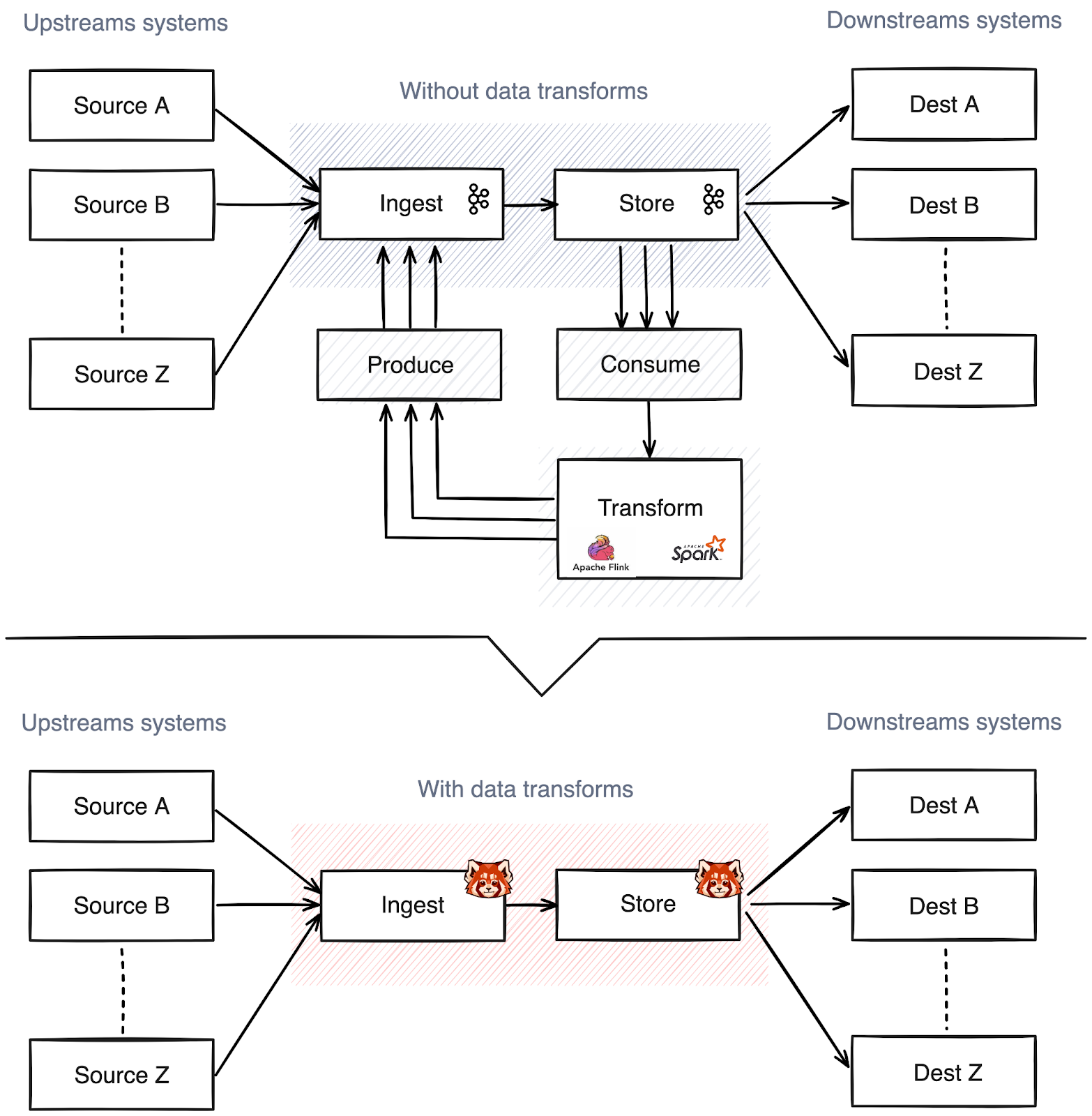
Redpanda的使用
Java环境使用Redpanda
Redpanda是一个Kafka API兼容的流处理平台,因此可以使用与Apache Kafka相同的客户端库来编写代码。以下是如何使用Java编写一个简单的生产者和消费者程序,以与Redpanda交互的示例。
设置环境
- 安装Java:确保安装了Java 8或更高版本。
- 安装Maven:用于管理项目依赖和构建。
- 安装Redpanda:可以在本地或云环境中部署Redpanda。Redpanda的安装非常简单,可以参考Redpanda官方文档。
创建Maven项目
创建一个新的Maven项目,添加Kafka客户端依赖:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>redpanda-example</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.0.0</version> </dependency> </dependencies> </project>
编写生产者代码
创建一个生产者类,用于将消息发送到Redpanda:
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class RedpandaProducer{
public static void main(String[] args){
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String,String> producer = new KafkaProducer<>(props);
try{
for(int i=0;i<10;i++){
String key = "key-"+i;
String value = "value-"+i;
ProducerRecord<String,String> record = new ProducerRecord<>("test-topic",key,value);
RecordMetadata metadata = producer.send(record).get();
System.out.printf("Sent record(key=%s value=%s) meta(partition=%d, offset=%d)\n",
key,value,metadata.partition(),metadata.offset());
}
}catch(Exception e){
e.printStackTrace();
}finally{
producer.close();
}
}
}
编写消费者代码
创建一个消费者类,用于从Redpanda接收消息:
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class RedpandaConsumer{
public static void main(String[] args){
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG,"test-group");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("test-topic"));
try{
while(true){
ConsumerRecords<String,String> records = consumer.poll(Duration.ofMillis(100));
for(ConsumerRecord<String,String> record:records){
System.out.printf("Consumed record(key=%s value=%s) meta(partition=%d, offset=%d)\n",
record.key(),record.value(),record.partition(),record.offset());
}
}
}finally{
consumer.close();
}
}
}
运行代码
- 启动Redpanda实例。
- 运行生产者程序,将消息发送到Redpanda。
- 运行消费者程序,从Redpanda接收消息。
Redpanda的KafkaAPI兼容性允许使用现有的Kafka客户端库与其交互。这意味着你可以使用熟悉的Kafka工具和库来构建流处理应用程序,而无需修改现有代码。这使得Redpanda成为一个易于集成的高性能替代方案,特别适合需要快速部署和高性能的应用场景。
Python环境使用Redpanda
Redpanda是KafkaAPI兼容的流处理平台,因此你可以使用Python的Kafka客户端库来与Redpanda进行交互。一个常用的Python客户端库是confluent-kafka-python,它是Confluent提供的高性能Kafka客户端。下面是如何使用Python与Redpanda交互的步骤:
安装依赖
首先,确保你的Python环境中安装了confluent-kafka库。你可以使用pip进行安装:pip install confluent-kafka编写生产者代码以下是一个简单的Python生产者示例,用于将消息发送到Redpanda:
from confluent_kafka import Producer
def delivery_report(err, msg):
"""Called once for each message produced to indicate delivery result.
Triggered by poll() or flush()."""
if err is not None:
print(f'Message delivery failed: {err}')
else:
print(f'Message delivered to {msg.topic()} [{msg.partition()}] @ {msg.offset()}')
# 配置生产者
conf = {
'bootstrap.servers': 'localhost:9092', # Redpanda的地址和端口
}
producer = Producer(**conf)
# 发送消息
topic = 'test-topic'
for i in range(10):
key = f'key-{i}'
value = f'value-{i}'
producer.produce(topic, key=key, value=value, callback=delivery_report)
producer.poll(0)
# 确保所有消息都已发送
producer.flush()
编写消费者代码
以下是一个简单的Python消费者示例,用于从Redpanda接收消息:
from confluent_kafka import Consumer, KafkaError
# 配置消费者
conf = {
'bootstrap.servers': 'localhost:9092',
'group.id': 'test-group',
'auto.offset.reset': 'earliest',
}
consumer = Consumer(**conf)
# 订阅主题
consumer.subscribe(['test-topic'])
try:
while True:
msg = consumer.poll(1.0) # 超时时间为1秒
if msg is None:
continue
if msg.error():
if msg.error().code() == KafkaError._PARTITION_EOF:
# 已到达分区末尾
continue
else:
print(msg.error())
break
print(f'Received message: {msg.key().decode("utf-8")}: {msg.value().decode("utf-8")}')
finally:
# 关闭消费者
consumer.close()
运行代码
- 确保Redpanda实例正在运行,并且监听在localhost:9092(或你的配置中指定的其他地址和端口)。
- 运行生产者脚本,将消息发送到Redpanda。
- 运行消费者脚本,从Redpanda中消费消息。
通过使用confluent-kafka-python库,你可以轻松地使用Python与Redpanda进行交互。由于Redpanda与KafkaAPI兼容,你可以使用现有的Kafka客户端库和工具,这使得Redpanda成为一个灵活且高性能的流处理解决方案,适合在多种应用场景中使用。


