Airflow简介
Apache Airflow是一个用于编排和调度复杂工作流的开源平台,广泛应用于数据工程和数据科学领域。它提供了一种灵活的方式来定义、调度和监控数据管道。
Airflow是一个编排、调度和监控 workflow 的平台,由 Airbnb 公司 2014 年 10 月开源,2019 年 1 月从 Apache 基金会毕业,成为新的 Apache 顶级项目。Airflow 将 workflow 编排为 tasks 组成的 DAGs,调度器在一组 workers 上按照指定的依赖关系执行 tasks。同时,Airflow 提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,并且 Airflow 提供了监控和报警系统。Airflow 使用 DAG (有向无环图) 来定义工作流,配置作业依赖关系非常方便,从管理方便和使用简单角度来讲,Airflow 远超过其他的任务调度工具。
- 编排:任务间的依赖关系
- 调度:时间调度和任务调度;通过控制 Broker 不同 Queue,来分发任务执行
- 监控:DAGs 和 Task 的状态
核心概念
- DAG(有向无环图):DAG 是 Airflow 中的核心概念,表示一组有依赖关系的任务。每个 DAG 是一个 Python 脚本,定义了任务及其执行顺序。
- 任务(Task):任务是 DAG 中的一个节点,表示一个具体的操作。Airflow 使用 Operator 来定义任务的类型,例如 BashOperator、PythonOperator、EmailOperator 等。
- Operator(操作符):Operator 是 Airflow 中的构建块,用于定义任务的具体行为。Airflow 提供了多种内置 Operator 来执行不同类型的任务。
- 执行器(Executor):执行器决定了任务的执行方式。Airflow 支持多种执行器,包括本地执行器、Celery 执行器和 Kubernetes 执行器,分别适用于不同的并行执行需求。
- 调度器(Scheduler):调度器负责按照定义的计划(如时间间隔、特定时间点)触发 DAG 的执行。
- Web UI:Airflow 提供了一个直观的 Web 用户界面,用于监控和管理 DAG 的执行状态。用户可以查看 DAG 的拓扑结构、任务状态、日志等。
特点和优势

- 灵活性:由于 DAG 是用 Python 编写的,用户可以利用 Python 的强大功能和库来定义复杂的工作流逻辑。
- 可扩展性:Airflow 支持分布式调度和执行,适合大规模任务的并行处理。通过不同的执行器,Airflow 可以在多台机器上运行任务。
- 可视化:Web UI 提供了对工作流的可视化管理,用户可以直观地查看任务依赖关系、执行历史和性能指标。
- 丰富的社区和插件:Airflow 拥有活跃的社区和丰富的插件生态,支持与各种外部系统和服务的集成,如 AWS、GCP、Hadoop、Spark 等。
- 动态 DAG 生成:Airflow 允许动态生成 DAG,使得在运行时可以根据外部条件动态调整任务。
使用场景
- ETL 管道:通过 Airflow 编排数据提取、转换和加载(ETL)过程,确保数据在不同系统之间的流动。
- 数据科学工作流:调度和管理机器学习模型的训练、测试和部署任务。
- 定时任务:执行定时的批处理任务,如数据备份、报告生成等。
- 依赖任务管理:管理复杂的任务依赖关系,确保任务按照预定的顺序执行。
部署与架构
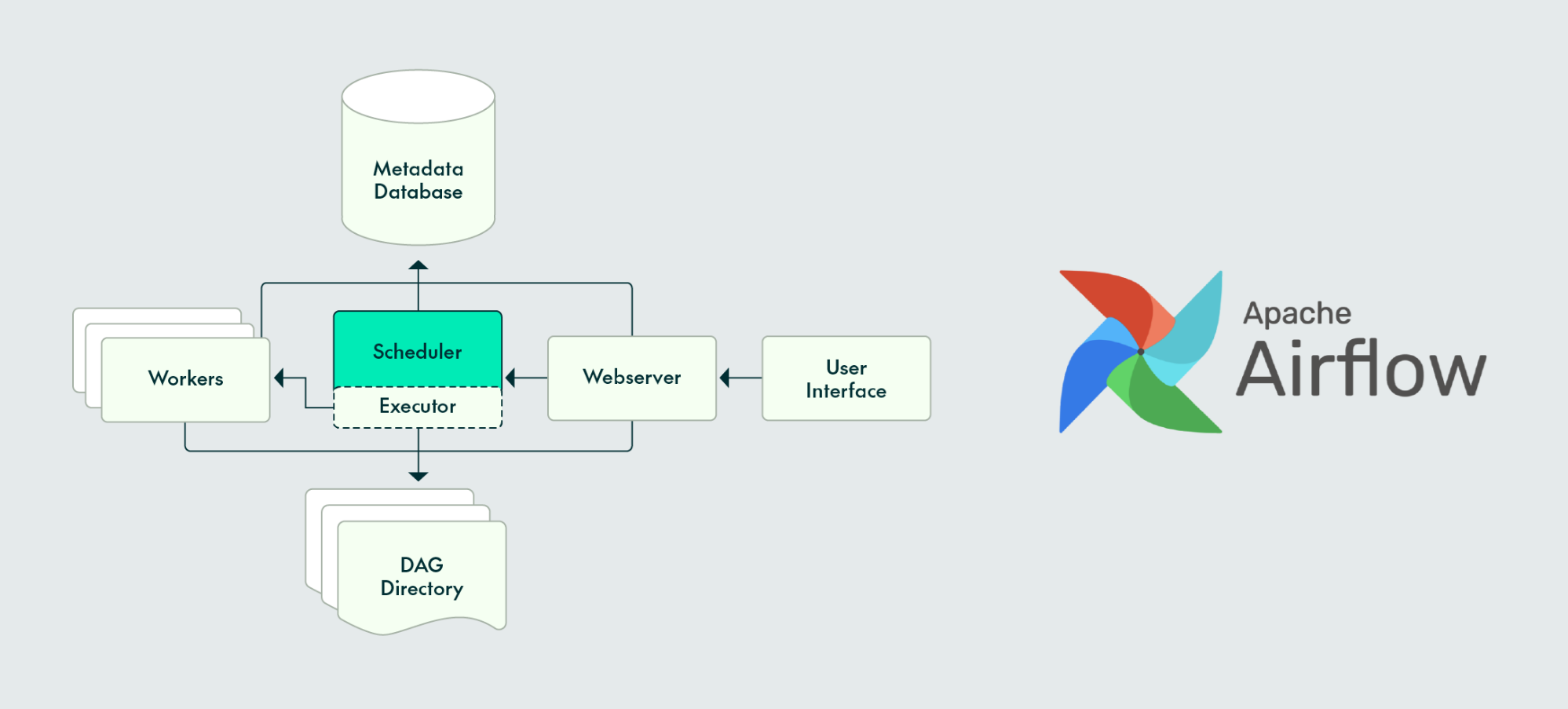
- 组件:Airflow 的架构由几个关键组件组成:Web Server、Scheduler、Worker 和 Metadata Database。Web Server 提供用户界面,Scheduler 负责调度任务,Worker 执行任务,Metadata Database 存储 DAG 和任务的状态信息。
- 部署方式:Airflow 可以在单机上运行以进行开发和测试,也可以通过 Celery 或 Kubernetes 执行器进行分布式部署以处理大规模工作流。
- 可扩展性:通过添加更多的 Worker 节点,Airflow 可以水平扩展以支持更多并发任务。
安全性
- 身份认证:Airflow 支持多种身份认证机制,如 LDAP、OAuth 和密码认证,以控制用户访问。
- 权限管理:通过基于角色的访问控制(RBAC),可以对用户和角色分配不同的权限级别。
- 日志和审计:Airflow 记录详细的任务执行日志和用户操作日志,便于监控和审计。
Apache Airflow 的灵活性和强大功能使其成为数据工程师和数据科学家构建和管理复杂工作流的首选工具之一。通过其模块化和可扩展的架构,Airflow 可以适应各种规模和复杂度的任务调度需求。
Airflow架构详解
- scheduler,它处理触发计划的工作流,并将任务提交给 executor 运行。
- executor,处理正在运行的任务。在默认的 Airflow 安装中,它运行在 scheduler 中,但大多数适合生产的 executor 实际上将任务执行推送给 workers。
- webserver,它提供了一个方便的用户界面来检查、触发和调试 DAG 和任务的行为。
- DAG Directory,由 scheduler 和 executor(以及 executor 所有的 worker)读取
- Metadata Database,供 scheduler, executor 和 webserver 用来存储状态。
Scheduler
基础概念
- JOB:最上层的工作。分为 SchedulerJob、BackfillJob 和 LocalTaskJob。SchedulerJob 由 Scheduler 创建,BackfillJob 由 Backfill 创建,LocalTaskJob 由前面两种 Job 创建。
- DAG:有向无环图,用来表示工作流。
- DAGRun:工作流实例,表示某个工作流的一次运行(状态)。
- Task:任务,工作流的基本组成部分。
- TaskInstance:任务实例,表示某个任务的一次运行(状态)。
heartbeat
在 airflow 中,heartbeat 是相当重要的一个概念,heartbeat 不能简单的理解成“心跳”,heartbeat 是 airflow 中各个组件协同、通信、交互、工作的一种方式, 在 shceduler 中,有下面几种重要的 heatbeat
| heartbeat | 作用 |
| scheduler->executor | 触发运行的 task, 并更新 task 状态 |
| scheduler->DagFileProcessorAgent | 检测 DagFileProcessorManager 的存活状态,并处理 manager 返回的消息 |
| scheduler-> scheduler | 检查 scheduler 是否存在问题,更新 schedulerjob 数据库的信息 |
功能逻辑调度器实际上就是一个 airflow.jobs.SchedulerJob 实例 job 持续运行 run 方法。job.run() 在开始时将自身的信息加入到 job 表中,并维护状态和心跳,预期能够正常结束,将结束时间也更新到表中。但是实际上往往因为异常中断,导致结束时间为空。不管是如何进行的退出,SchedulerJob 退出时会关闭所有子进程。
这里简单介绍下 Scheduler 的功能逻辑:
- 遍历 dags 路径下的所有 dag 文件,启动一定数量的进程(进程池),并且给每个进程指派一个 dag 文件。每个 DagFileProcessor 解析分配给它的 dag 文件,并根据解析结果在 DB 中创建 DagRuns 和 TaskInstance。
- 在 scheduler_loop 中,检查与活动 DagRun 关联的 TaskInstance 的状态,解析 TaskInstance 之间的任何依赖,标识需要被执行的 TaskInstance,然后将它们添加至 executor 队列,将新排列的 TaskInstance 状态更新为 QUEUED 状态。
- 每个可用的 executor 从队列中取一个 TaskInstance,然后开始执行它,将此 TaskInstance 的数据库记录更新为 SCHEDULED。
- 当一个 TaskInstance 完成运行,关联的 executor 就会报告到队列并更新数据库中的 TaskInstance 的状态(例如“完成”、“失败”等)。
- 一旦所有的 dag 处理完毕后,就会进行下一轮循环处理。这里还有一个细节就是上一轮的某个 dag 的处理时间可能很长,导致到下一轮处理的时候这个 dag 还没有处理完成。Airflow 的处理逻辑是在这一轮不为这个 dag 创建进程,这样就不会阻塞进程去处理其余 dag
启动过程
scheduler 在启动时,通过airflow/__main__.py入口方法传入参数 “scheduler” 启动,启动时会创建 Job 对象,Job 的概念在上面有描述,开始执行 job.run() 方法后进入核心逻辑,核心步骤如下
- 打印关键日志:”Starting the scheduler”,表示开始启动
- 启动 DagFileProcessorAgent
- 扫描文件,导入模块
- dag 定义文件中的搜集 dag
- 创建 dagrun
- 创建任务实例
- 进入核心的 _run_scheduler_loop 方法,循环调用,主要功能如下
- .通过 DagFileProcessorAgent 获取 DAG 解析结果
- 查找和排队可执行任务
- 更改数据库中的 TaskInstance 状态
- 把任务放在 executor 中排队
- 心跳检测 executor
- 异步执行 executor 中排队的任务
- 同步运行任务的状态
- 执行 _do_scheduling,dag 级别的调度的决策,TaskInstance 状态管理,task 同步到 executor 等功能,后面会详解
- 开启心跳检查
- Executor 心跳
- DagFileProcessorAgent 心跳
- Scheduler 心跳
Executor
Airflow 本身是一个综合平台,它兼容多种组件,所以在使用的时候有多种方案可以选择。比如最关键的执行器就有四种选择:
- SequentialExecutor:单进程顺序执行任务,默认执行器,通常只用于测试
- LocalExecutor:多进程本地执行任务
- CeleryExecutor:分布式调度,生产常用
- DaskExecutor:动态任务调度,主要用于数据分析
在当前项目使用 CeleryExecutor 作为执行器。
celery 是一个分布式调度框架,其本身无队列功能,需要使用第三方组件,比如 redis 或者 rabbitmqCeleryExecutor
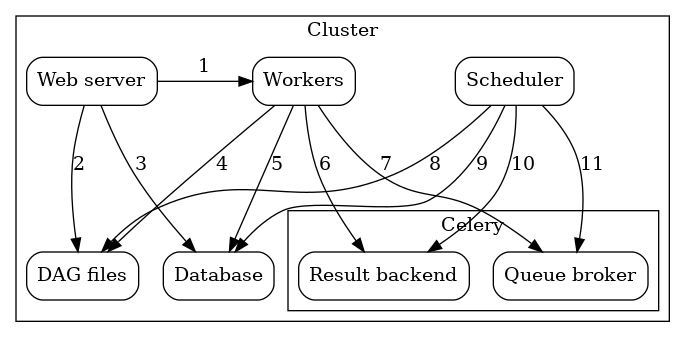
- Worker-执行分配的任务
- Scheduler——负责将必要的任务添加到队列中
- WebServer-HTTP 服务器提供对 DAG/任务状态信息的访问
- Database-包含有关任务、DAG、变量、连接等状态的信息。
- Celery-队列机制
Celery 的队列由两个部分组成:
- Broker-存储要执行的命令
- Result backend-存储已完成命令的状态
上图组件在很多地方相互通信
- [1]Webserver –> Workers -拉取任务执行日志
- [2]Webserver –> DAG files -解析展示 DAG 结构
- [3]Webserver –> Database -拉取任务状态
- [4]Workers –> DAG files -解析 DAG 结构并执行 task
- [5]Workers –> Database -获取和存储有关连接配置、变量
- [6]Workers –> Celery’s result backend -存储 task 运行状态
- [7]Workers –> Celery’s broker -存储要执行的命令
- [8]Scheduler –> DAG files -解析 DAG 结构并执行 task
- [9]Scheduler –> Database -存储 dagrun 和相关 task
- [10]Scheduler –> Celery’s result backend -获取已经执行完成的 task 信息
- [11]Scheduler –> Celery’s broker -put 要执行的命令
任务执行流程
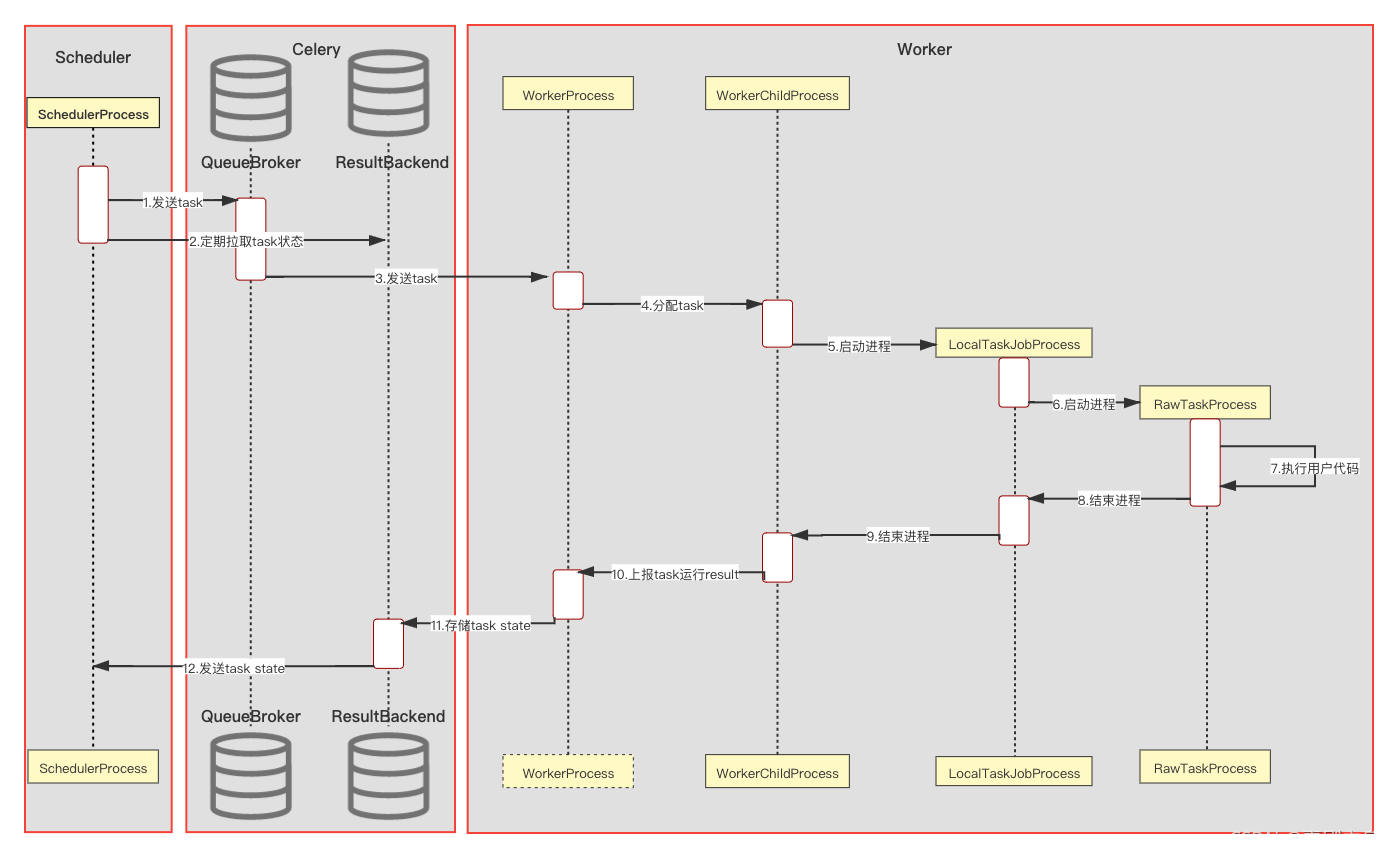
初始状态有两个进程运行:
- Scheduler Process-处理 tasks 并使用 CeleryExecutor 运行
- Worker Process-观察队列等待新的 tasks 出现
两个抽象的数据库,使用 celery:
- Queue Broker
- Result Backend
在运行 task 过程中,创建了两个进程:
- LocalTaskJob Process-它的逻辑由 LocalTaskJob 描述,同时监控 RawTaskProcess 的状态,新的进程将由 TaskRunner 启动.
- RawTask Process-它用来处理用户实际的代码,比如用户执行的一行 shell
[1] SchedulerProcess 处理任务,当它发现需要完成的任务时,将其发送到 QueueBroker。 [2] SchedulerProcess 也会周期性的查询 ResultBackend 以获取任务的状态。 [3] QueueBroker 当它意识到有新任务产生时,会将有关它的信息发送到 WorkerProcess [4] WorkerProcess 将单个任务分配给一个 WorkerChildProcess。 [5] WorkerChildProcess 执行适当的任务处理功能 - 关键方法:execute_command()。并创建个新的进程 - LocalTaskJobProcess。 [6] LocalTaskJobProcess 逻辑由 LocalTaskJob 类描述。它使用 TaskRunner 启动的新进程。 [7] RowTaskProcess 执行用户实际的代码,这一步是最底层真正执行 task 的操作 [8][9] ProcessRawTaskProcess 和 LocalTaskJobProcess 在完成 task 后停止。 [10] WorkerChildProcess 通知主进程 - WorkerProcess 任务结束以及后续任务的可用性。 [11] WorkerProcess 将状态信息保存在 ResultBackend 中。 [12] 当 SchedulerProcess 再次询问 ResultBackend 状态时,将会获取到任务状态的信息。
Scheduler 源码分析
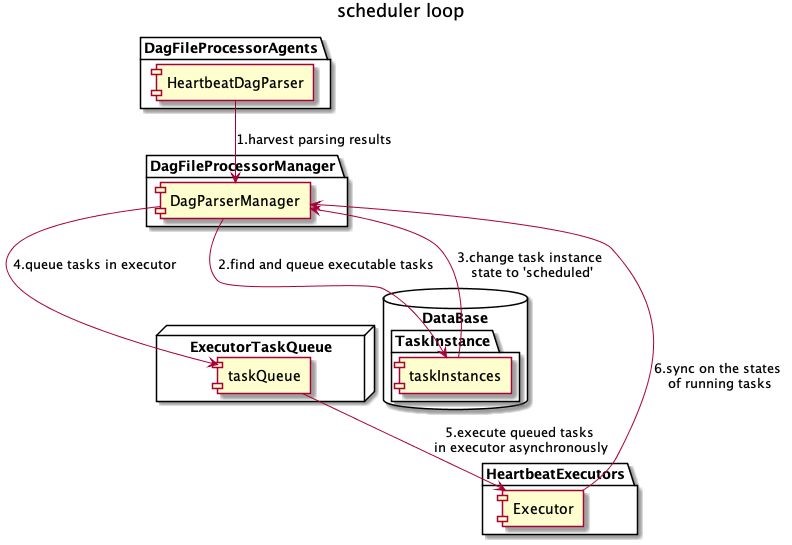
_run_scheduler_loop
调度的核心逻辑在airflow.jobs.scheduler_job.SchedulerJob._run_scheduler_loop(), 从方法名可以知道是一个循环,基础逻辑是从数据库找出需要调度的 dag,创建 dagrun,创建 TaskInstance,管理生命周期状态等等功能。我们一步步深入研究它内部的最主要逻辑
def _run_scheduler_loop(self) -> None:
"""
The actual scheduler loop. The main steps in the loop are:
#. Harvest DAG parsing results through DagFileProcessorAgent
#. Find and queue executable tasks
#. Change task instance state in DB
#. Queue tasks in executor
#. Heartbeat executor
#. Execute queued tasks in executor asynchronously
#. Sync on the states of running tasks
Following is a graphic representation of these steps.
.. image:: ../docs/apache-airflow/img/scheduler_loop.jpg
:rtype: None
"""
if not self.processor_agent:
raise ValueError("Processor agent is not started.")
is_unit_test: bool = conf.getboolean('core', 'unit_test_mode')
#1. 创建 timer,scheduler 自身的定时器,与用户代码无关
timers = EventScheduler()
# Check on startup, then every configured interval
self.adopt_or_reset_orphaned_tasks()
timers.call_regular_interval(
conf.getfloat('scheduler', 'orphaned_tasks_check_interval', fallback=300.0),
self.adopt_or_reset_orphaned_tasks,
)
timers.call_regular_interval(
conf.getfloat('scheduler', 'pool_metrics_interval', fallback=5.0),
self._emit_pool_metrics,
)
timers.call_regular_interval(
conf.getfloat('scheduler', 'clean_tis_without_dagrun_interval', fallback=15.0),
self._clean_tis_without_dagrun,
)
for loop_count in itertools.count(start=1):
with Stats.timer() as timer:
if self.using_sqlite:
self.processor_agent.run_single_parsing_loop()
# For the sqlite case w/1 thread, wait until the processor
# is finished to avoid concurrent access to the DB.
self.log.debug("Waiting for processors to finish since we're using sqlite")
self.processor_agent.wait_until_finished()
with create_session() as session:
#2. 执行调度 dag 相关的关键步骤,返回 queued 状态的 task instance 个数
num_queued_tis = self._do_scheduling(session)
#3. executor 通过 heartbeat 实际触发执行 command 的步骤
self.executor.heartbeat()
session.expunge_all()
num_finished_events = self._process_executor_events(session=session)
#4. 检测 DagFileProcessorManager 的存活状态,并处理 manager 返回的消息
self.processor_agent.heartbeat()
# Heartbeat the scheduler periodically
#5. 通过 heartbeat 更新 job 的条目,检查时间戳判断 scheduler 是否有问题
self.heartbeat(only_if_necessary=True)
# Run any pending timed events
next_event = timers.run(blocking=False)
self.log.debug("Next timed event is in %f", next_event)
self.log.debug("Ran scheduling loop in %.2f seconds", timer.duration)
if not is_unit_test and not num_queued_tis and not num_finished_events:
# If the scheduler is doing things, don't sleep. This means when there is work to do, the
# scheduler will run "as quick as possible", but when it's stopped, it can sleep, dropping CPU
# usage when "idle"
time.sleep(min(self._processor_poll_interval, next_event))
if loop_count >= self.num_runs > 0:
self.log.info(
"Exiting scheduler loop as requested number of runs (%d - got to %d) has been reached",
self.num_runs,
loop_count,
)
break
if self.processor_agent.done:
self.log.info(
"Exiting scheduler loop as requested DAG parse count (%d) has been reached after %d"
"scheduler loops",
self.num_times_parse_dags,
loop_count,
)
break
- 创建 timer,scheduler 自身的定时器,与用户代码无关
- 执行调度 dag 相关的关键步骤,返回 queued 状态的 task instance 个数
- executor 通过 heartbeat 实际触发执行 command 的步骤
- 检测 DagFileProcessorManager 的存活状态,并处理 manager 返回的消息
- 通过 heartbeat 更新 scheduler 在数据库的信息,检查时间戳判断 scheduler 是否有问题
_do_scheduling
上面代码中,_do_scheduling() 是_run_scheduler_loop() 的核心调用方法,(对于 Dag,DagRun,Task,TaskInstance 等概念已在前面说明,需了解清楚)。所有数据库的操作,都由 session 对象维护。描述中以 airflow 自带到 demoexample_bash_operator 举例说明,DAG 图如下
核心逻辑功能如下:
- 为需要被调度的 Dag 创建 DagRun,表示当前 Dag 需要被执行一次
- 更新数据库中 Dag 的状态,把 queued 状态的 Dag 改成 running 状态

- 检查 DAG 的正确性,包含 db 是否存在、是否序列化,以决定当前 DagRun 是否可以被执行
- 修改数据库数据,把 Task 的状态更改为 Scheduled 状态

- 更新数据库后发送回调给 DagFileProcessor,以确保 context 运行时是最新的
- 检查 Executor 中 slot 是否有剩余可用,计算公式为:slots_available = parallelism – running – queued_tasks,如果不可用,直接退出,甚至不会有重试,会打印 log:”Executor full, skipping critical section“
- 第 6 步中检查发现 Executor 中 slot 有剩余可用时,会把数据库中标记为 scheduled 状态的 task 标记为 queued 状态,其中涉及 3 个细节
- 在没有超过 max_active_runs 或 pool 的限制的情况下会根据 TaskInstance 的优先级决定执行顺序
- 根据池限制、dag 并发性、执行程序状态和优先级查找准备好执行的 TaskInstance
- log 中会打印 ”xx tasks up for execution“,也打印了所有 TaskInstance 到名称,此时真正物理到 task 还未被真正执行
- 紧接着会经过一系列的资源检查,如 pool、dag 并发数、task 并发数,确保 TaskInstance 能被调度,检查成功后,也会更新 metrics 如:starving_tasks、scheduler.tasks.starving、scheduler.tasks.running、scheduler.tasks.executable
- 更改 TaskInstance 的状态,把数据库里面 scheduled 状态更改为 queued,返回要执行的 TaskInstance 个数
- 将 TaskInstance 放入 Executor 中
- 其余 task 级别的逻辑和状态维护均在 executor 中维护
状态转移追踪
任务状态
DAG 级别状态:
| 状态 | 释义 |
| QUEUED | 已排队 |
| SUCCESS | 成功 |
| RUNNING | 运行中 |
| FAILED | 失败 |
TASK 级别状态:
| 状态 | 释义 |
| NONE | 无 |
| REMOVED | 已移除 |
| RUNNING | 运行中 |
| SCHEDULED | 已调度 |
| QUEUED | 已排队 |
| SHUTDOWN | 关闭 |
| UP_FOR_RETRY | 等待重试 |
| UP_FOR_RESCHEDULE | 等待被重新调度 |
| UPSTREAM_FAILED | 上游失败 |
| SKIPPED | 已跳过 |
| SENSING | – |
状态转移
以 airlow 自带的 demo example_bash_operator 为例,描述 dag 的生命周期,状态类别可参考上面列表,状态分为 DagRun 级别和 TaskInstance 级别
查询 DagRun 和 TaskInstance 的状态有两种方法:
- 查询 airflow 的元数据库,分别对应 dag_run 和 task_instance 表
- 查询 airflow 的 webui,可以清晰的看到 DagRun 和 TaskInstance 的当前状态
step1
手动运行 dag 或定时触发
| 上一次状态 | 当前状态 | 状态关键日志 | 查询状态 sql(airflow 元数据库) | |
| DagRun | 无 | QUEUED | 无 | select * from dag_run where dag_id=”example_bash_operator” and state=”queued” |
| TaskInstance | 无 | NONE | 无 | select * from task_instance where dag_id=”example_bash_operator” state=null |
step2
| 上一次状态 | 当前状态 | 状态关键日志 | 查询状态 sql(airflow 元数据库) | |
| DagRun | QUEUED | RUNNING | 无 | select * from dag_run where dag_id=”example_bash_operator” and state=”running” |
| TaskInstance | NONE | SCHEDULED | 无 | select * from task_instance where dag_id=”example_bash_operator” and state=”scheduled” |
step3
| 上一次状态 | 当前状态 | 状态关键日志 | 查询状态 sql(airflow 元数据库) | DagRun | RUNNING | RUNNING | 无 | select * from dag_run where dag_id=”example_bash_operator” and state=”running” |
| TaskInstance | SCHEDULED | QUEUED | {scheduler_job.py:517} INFO – Sending TaskInstanceKey(dag_id=’example_bash_operator’, task_id=’runme_0′, execution_date=datetime.datetime(2021, 9, 13, 12, 42, 38, 886807, tzinfo=Timezone(‘UTC’)), try_number=1) to executor with priority 3 and queue default | select * from task_instance where dag_id=”example_bash_operator” and state=”queued” |
step4
| 上一次状态 | 当前状态 | 状态关键日志 | 查询状态sql(airflow元数据库) | |
| DagRun | RUNNING | RUNNING | 无 | select * from dag_run where dag_id=”example_bash_operator” and state=”running” |
| TaskInstance | QUEUED | RUNNING | [2021-09-13 23:21:28, 217] {standard_task_runner.py:52} INFO – Started process 5894 to run task
[2021-09-13 23:23:32, 590] {standard_task_runner.py:76} INFO – Running: [‘airflow’, ‘tasks’…… [2021-09-13 23:23:33, 772] {standard_task_runner.py:77} INFO – Job 448: Subtask runme_0 |
select * from task_instance where dag_id=”example_bash_operator” and state=”running” |
step5
| 上一次状态 | 当前状态 | 状态关键日志 | 查询状态sql(airflow元数据库) | |
| DagRun | RUNNING | SUCCESS | [2021-09-14 09:25:45, 976] {dagrun.py:434} INFO – Marking run <DagRun example_bash_operator@2021-09-14 01:25:39.909845+00:00: manual__2021-09-14T01:25:39.909845+00:00, externally triggered: True> successful | select * from dag_run where dag_id=”example_bash_operator” and state=”success” |
| TaskInstance | RUNNING | SUCCESS |
|
select * from task_instance where dag_id=”example_bash_operator” and state=”success” |
日志记录和监控架构
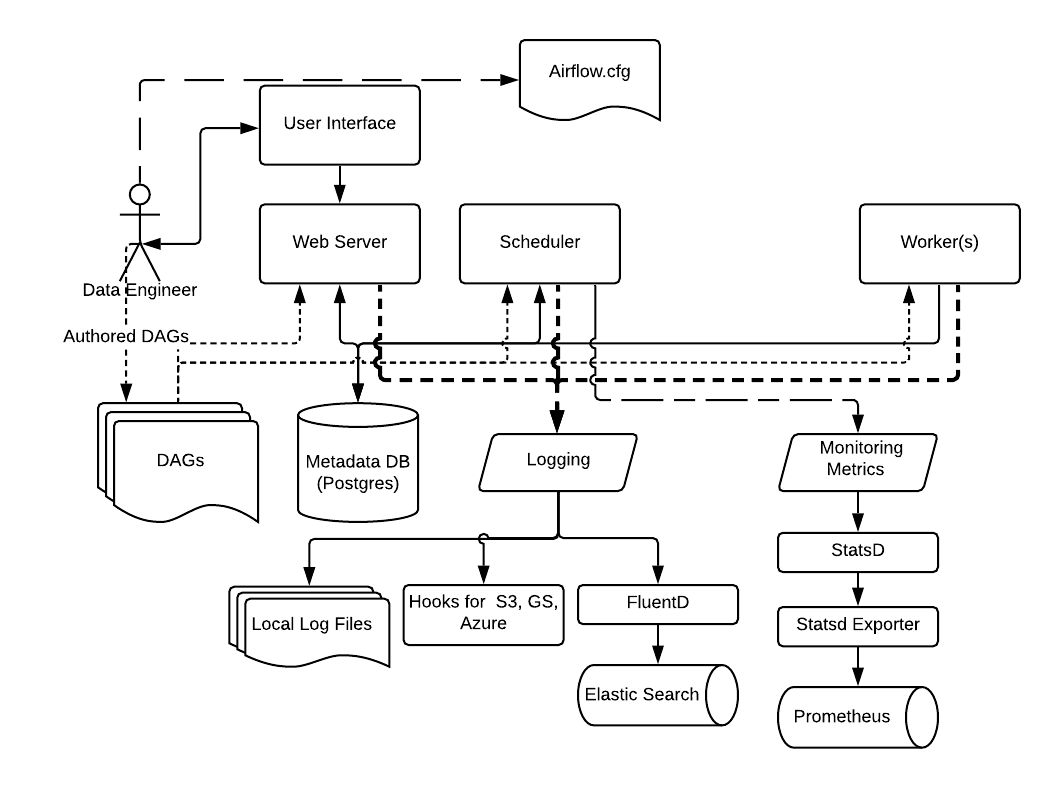
- logging配置参考:Logging for Tasks — Airflow Documentation
- metric信息参考:Metrics — Airflow Documentation
参考链接:


