协程简介
在了解协程、异步之前,我们首先得了解一些基础概念:,如阻塞和非阻塞、同步和异步、多进程和协程。
阻塞和非阻塞
- 阻塞:阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续干别的事情,则称该程序在该操作上是阻塞的。常见的阻塞形式有:网络I/O阻塞、磁盘I/O阻塞、用户输入阻塞等。阻塞是无处不在的,包括CPU切换上下文时,所有的进程都无法真正干事情,它们也会被阻塞。如果是多核CPU则正在执行上下文切换操作的核不可被利用。
- 非阻塞:程序在等待某操作过程中,自身不被阻塞,可以继续运行干别的事情,则称该程序在该操作上是非阻塞的。非阻塞并不是在任何程序级别、任何情况下都可以存在的。仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时与效率低下,我们才要把它变成非阻塞的。
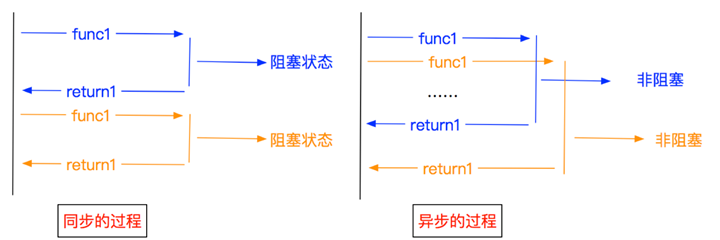
同步和异步
- 同步:不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,称这些程序单元是同步执行的。例如购物系统中更新商品库存,需要用”行锁”作为通信信号,让不同的更新请求强制排队顺序执行,那更新库存的操作是同步的。简言之,同步意味着有序。
- 异步:为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相互通知协调。这些异步操作的完成时刻并不确定。简言之,异步意味着无序。
进程和线程
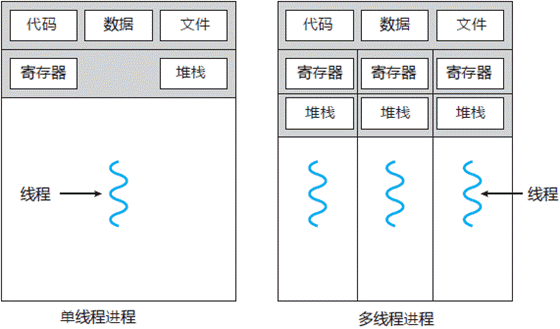
- 进程(Process)是应用程序启动的实例,拥有代码、数据和文件和独立的内存空间,是操作系统最小资源管理单元。每个进程下面有一个或者多个线程(Thread),来负责执行程序的计算,是最小的执行单元。操作系统会负责进程的资源的分配;控制权主要在操作系统。
- 线程做为任务的执行单元,有新建、可运行runnable(调用start方法,进入调度池,等待获取cpu使用权)、运行running(得到cpu使用权开始执行程序)阻塞blocked(放弃了cpu使用权,再次等待)死亡dead5中不同的状态。线程的转态也是由操作系统进行控制。线程如果存在资源共享的情况下,就需要加锁,比如生产者和消费者模式,生产者生产数据多共享队列,消费者从共享队列中消费数据。
线程和进程在得到和放弃cpu使用权时,cpu使用权的切换都需损耗性能,因为某个线程为了能够在再次获得cpu使用权时能继续执行任务,必须记住上一次执行的所有状态。另外线程还有锁的问题。
并行和并发
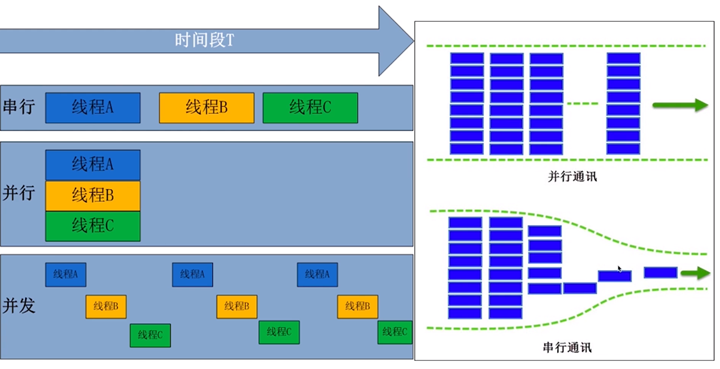
并行和并发,听起来都像是同时执行不同的任务。但是这个同时的含义是不一样的。
- 并行(Parallelism):多核CPU才有可能真正的同时执行,就是独立的资源来完成不同的任务,没有先后顺序。
- 并发(concurrent):是看上去的同时执行,实际微观层面是顺序执行,是操作系统对进程的调度以及cpu的快速上下文切换,每个进程执行一会然后停下来,cpu资源切换到另一个进程,只是切换的时间很短,看起来是多个任务同时在执行。要实现大并发,需要把任务切成小的任务。
上面说的多核cpu可能同时执行,这里的可能是和操作系统调度有关,如果操作系统调度到同一个cpu,那就需要cpu进行上下文切换。当然多核情况下,操作系统调度会尽可能考虑不同cpu。这里的上下文切换可以理解为需要保留不同执行任务的状态和数据。所有的并发处理都有排队等候,唤醒,执行三个这样的步骤。
协程背景与定义
GIL: 全局解释器锁(英语:Global Interpreter Lock,缩写GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。由于GIL的存在,导致Python多线程性能甚至比单线程更糟。
协程,英文叫做Coroutine,又称微线程,纤程,协程是一种用户态的轻量级线程。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。协程本质上是个单进程,协程相对于多进程来说,无需线程上下文切换的开销,无需原子操作锁定及同步的开销,编程模型也非常简单。我们可以使用协程来实现异步操作,比如在网络爬虫场景下,我们发出一个请求之后,需要等待一定的时间才能得到响应,但其实在这个等待过程中,程序可以干许多其他的事情,等到响应得到之后才切换回来继续处理,这样可以充分利用CPU和其他资源,这就是异步协程的优势。
如果你还无法理解协程的概念,那么可以这么简单的理解:
- 进程/线程:操作系统提供的一种并发处理任务的能力。
- 协程:程序员通过高超的代码能力,在代码执行流程中人为的实现多任务并发,是单个线程内的任务调度技巧。
多进程和多线程体现的是操作系统的能力,而协程体现的是程序员的流程控制能力。
协程的概念很早就提出来了,但直到最近几年才在某些语言(如Lua)中得到广泛应用。
子程序,或者称为函数,在所有语言中都是层级调用,比如A调用B,B在执行过程中又调用了C,C执行完毕返回,B执行完毕返回,最后是A执行完毕。所以子程序调用是通过栈实现的,一个线程就是执行一个子程序。子程序调用总是一个入口,一次返回,调用顺序是明确的。而协程的调用和子程序不同。协程看上去也是子程序,但执行过程中,在子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。
注意,在一个子程序中中断,去执行其他子程序,不是函数调用,有点类似CPU的中断。比如子程序A、B:
def A():
print('1')
print('2')
print('3')
def B():
print('x')
print('y')
print('z')
假设由协程执行,在执行A的过程中,可以随时中断,去执行B,B也可能在执行过程中中断再去执行A,结果可能是:
1 2 x y 3 z
但是在A中是没有调用B的,所以协程的调用比函数调用理解起来要难一些。看起来A、B的执行有点像多线程,但协程的特点在于是一个线程执行,那和多线程比,协程有何优势?
- 协程极高的执行效率。因为子程序切换不是线程切换,而是由程序自身控制,因此,没有线程切换的开销,和多线程比,线程数量越多,协程的性能优势就越明显。
- 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。
Python对协程的支持是通过generator实现的。在generator中,我们不但可以通过for循环来迭代,还可以不断调用next()函数获取由yield语句返回的下一个值。但是Python的yield不但可以返回一个值,它还可以接收调用者发出的参数。
传统的生产者-消费者模型是一个线程写消息,一个线程取消息,通过锁机制控制队列和等待,但一不小心就可能死锁。如果改用协程,生产者生产消息后,直接通过yield跳转到消费者开始执行,待消费者执行完毕后,切换回生产者继续生产,效率极高:
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
r = '200 OK'
def produce(c):
c.send(None)
n = 0
while n< 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
c = consumer()
produce(c)
执行结果:
[PRODUCER] Producing 1... [CONSUMER] Consuming 1... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 2... [CONSUMER] Consuming 2... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 3... [CONSUMER] Consuming 3... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 4... [CONSUMER] Consuming 4... [PRODUCER] Consumer return: 200 OK [PRODUCER] Producing 5... [CONSUMER] Consuming 5... [PRODUCER] Consumer return: 200 OK
注意到consumer函数是一个generator,把一个consumer传入produce后:
- 首先调用send(None)启动生成器
- 然后,一旦生产了东西,通过send(n)切换到consumer执行
- consumer通过yield拿到消息,处理,又通过yield把结果传回
- produce拿到consumer处理的结果,继续生产下一条消息
- produce决定不生产了,通过close()关闭consumer,整个过程结束
整个流程无锁,由一个线程执行,produce和consumer协作完成任务,所以称为"协程",而非线程的抢占式多任务。
Python对协程的支持
生成器(Generator)
我们这里主要讨论yield和yield from这两个表达式,这两个表达式和协程的实现息息相关。
方法中包含yield表达式后,Python会将其视作generator对象,不再是普通的方法。
yield表达式的使用
最早的时候,Python提供了yield关键字,用于制造生成器。也就是说,包含有yield的函数,都是一个生成器!
yield的语法规则是:在yield这里暂停函数的执行,并返回yield后面表达式的值(默认为None),直到被next()方法再次调用时,从上次暂停的yield代码处继续往下执行。当没有可以继续next()的时候,抛出异常,该异常可被for循环处理。
我们先来看该表达式的具体使用:
def test():
print("generator start")
n = 1
while True:
yield_expression_value = yield n
print("yield_expression_value = %d" % yield_expression_value)
n += 1
# 创建generator对象
generator = test()
# 启动generator
next_result = generator.__next__()
print("next_result = %d" % next_result)
# 发送值给yield表达式
send_result = generator.send(666)
print("send_result = %d" % send_result)
执行结果:
generator start next_result = 1 yield_expression_value = 666 send_result = 2
方法说明:
- __next__()方法: 作用是启动或者恢复generator的执行,相当于send(None)
- send(value)方法:每个生成器都可以执行send()方法,作用是发送值给yield表达式。启动generator则是调用send(None)。此时yield语句不再只是yield xxxx的形式,还可以是var = yield xxxx的赋值形式。它同时具备两个功能,一是暂停并返回函数,二是接收外部send()方法发送过来的值,重新激活函数,并将这个值赋值给var变量。
执行结果的说明:
- 创建generator对象:包含yield表达式的函数将不再是一个函数,调用之后将会返回generator对象
- 启动generator:使用生成器之前需要先调用__next__或者send(None),否则将报错。启动generator后,代码将执行到yield出现的位置,也就是执行到yield n,然后将n传递到__next__()这行的返回值。(注意,生成器执行到yield n后将暂停在这里,直到下一次生成器被启动)
- 发送值给yield表达式:调用send方法可以发送值给yield表达式,同时恢复生成器的执行。生成器从上次中断的位置继续向下执行,然后遇到下一个yield,生成器再次暂停,切换到主函数打印出send_result。
理解这个demo的关键是:生成器启动或恢复执行一次,将会在yield处暂停。上面的第2步仅仅执行到了yield n,并没有执行到赋值语句,到了第3步,生成器恢复执行才给yield_expression_value赋值。
协程可以处于下面四个状态中的一个。当前状态可以导入inspect模块,使用inspect.getgeneratorstate()方法查看,该方法会返回下述字符串中的一个。
- GEN_CREATED:等待开始执行
- GEN_RUNNING:协程正在执行
- GEN_SUSPENDED:在yield表达式处暂停
- GEN_CLOSE:协程执行结束
示例代码:
from inspect import getgeneratorstate
def simple_coro():
print("generator start")
n = 1
while True:
yield_expression_value = yield n
print("yield_expression_value = %d" % yield_expression_value)
n += 1
my_coro = simple_coro()
print(getgeneratorstate(my_coro))
next(my_coro)
print(getgeneratorstate(my_coro))
my_coro.send(28)
print(getgeneratorstate(my_coro))
my_coro.close()
print(getgeneratorstate(my_coro))
输出:
GEN_CREATED generator start GEN_SUSPENDED yield_expression_value = 28 GEN_SUSPENDED GEN_CLOSED
因为 send() 方法的参数会成为暂停的 yield 表达式的值,所以,仅当协程处于暂停状态时才能调用 send() 方法。不过,如果协程还没激活(状态是 'GEN_CREATED'),就立即把 None 之外的值发给它,会出现 TypeError。因此,始终要先调用 next(my_coro) 激活协程,这一过程被称作预激活。
除了 send() 方法,其实还有 throw() 和 close() 方法:
- throw(exc_type[, exc_value[, traceback]]):使生成器在暂停的 yield 表达式处抛出指定的异常。如果生成器处理了抛出的异常,代码会向前执行到下一个 yield 表达式,而产出的值会成为调用 generator.throw() 方法得到的返回值。如果生成器没有处理抛出的异常,异常会向上冒泡,传到调用方的上下文中。
- close():使生成器在暂停的 yield 表达式处抛出 GeneratorExit 异常。如果生成器没有处理这个异常,或者抛出了 StopIteration 异常(通常是指运行到结尾),调用方不会报错。如果收到 GeneratorExit 异常,生成器一定不能产出值,否则解释器会抛出 RuntimeError 异常。生成器抛出的其他异常会向上冒泡,传给调用方。
yield from 表达式
Python 3.3 版本新增 yield from 语法,新语法用于将一个生成器部分操作委托给另一个生成器。此外,允许子生成器(即 yield from 后的“参数”)返回一个值,该值可供委派生成器(即包含 yield from 的生成器)使用。并且在委派生成器中,可对子生成器进行优化。
我们先来看最简单的应用,例如:
# 子生成器
def test(n):
i = 0
while i < n:
yield i
i += 1
# 委派生成器
def test_yield_from(n):
print("test_yield_from start")
yield from test(n)
print("test_yield_from end")
for i in test_yield_from(3):
print(i)
输出:
test_yield_from start 0 1 2 test_yield_from end
如果上面的 test_yield_from 函数中有两个 yield from 语句,将串行执行。比如将上面的 test_yield_from 函数改写成这样:
# 子生成器
def test(n):
i = 0
while i < n:
yield i
i += 1
# 委派生成器
def test_yield_from(n):
print("test_yield_from start")
yield from test(n)
print("test_yield_from doing")
yield from test(n)
print("test_yield_from end")
for i in test_yield_from(3):
print(i)
则输出:
test_yield_from start 0 1 2 test_yield_from doing 0 1 2 test_yield_from end
协程 (Coroutine)
- Python 3.4 开始,新增了 asyncio 相关的 API,语法使用 @asyncio.coroutine 和 yield from 实现协程
- Python 3.5 中引入 async/await 语法,参见PEP 492
@asyncio.coroutine
Python 3.4 中,使用 @asyncio.coroutine 装饰的函数称为协程。不过没有从语法层面进行严格约束。
对于 Python 原生支持的协程来说,Python 对协程和生成器做了一些区分,便于消除这两个不同但相关的概念的歧义:
- 标记了 @asyncio.coroutine 装饰器的函数称为协程函数, iscoroutinefunction() 方法返回 True
- 调用协程函数返回的对象称为协程对象, iscoroutine() 函数返回 True
举例:
import asyncio
def test(n):
i = 0
while i < n:
yield i
i += 1
@asyncio.coroutine
def test_yield_from(n):
print("test_yield_from start")
yield from test(n)
print("test_yield_from end")
if __name__ == "__main__":
# 是否是协程函数
print(asyncio.iscoroutinefunction(test_yield_from))
# 是否是协程对象
print(asyncio.iscoroutine(test_yield_from(3)))
可以看下 @asyncio.coroutine 的源码中查看其做了什么,将其源码简化下,大致如下:
import functools
import types
import inspect
def coroutine(func):
# 判断是否是生成器
if inspect.isgeneratorfunction(func):
coro = func
else:
# 将普通函数变成 generator
@functools.wraps(func)
def coro(*args, **kw):
res = func(*args, **kw)
res = yield from res
return res
# 将 generator 转换成 coroutine
wrapper = types.coroutine(coro)
# For iscoroutinefunction().
wrapper._is_coroutine = True
return wrapper
将这个装饰器标记在一个生成器上,就会将其转换成 coroutine。然后,我们来实际使用下 @asyncio.coroutine 和 yield from:
import asyncio
@asyncio.coroutine
def compute(x, y):
print("Compute %s + %s..." % (x, y))
yield from asyncio.sleep(1.0)
return x + y
@asyncio.coroutine
def print_sum(x, y):
result = yield from compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
print("start")
# 中断调用,直到协程执行结束
loop.run_until_complete(print_sum(1, 2))
print("end")
loop.close()
执行结果:
start Compute 1 + 2... 1 + 2 = 3 end
print_sum 这个协程中调用了子协程 compute,它将等待 compute 执行结束才返回结果。这个 demo 点调用流程如下图:
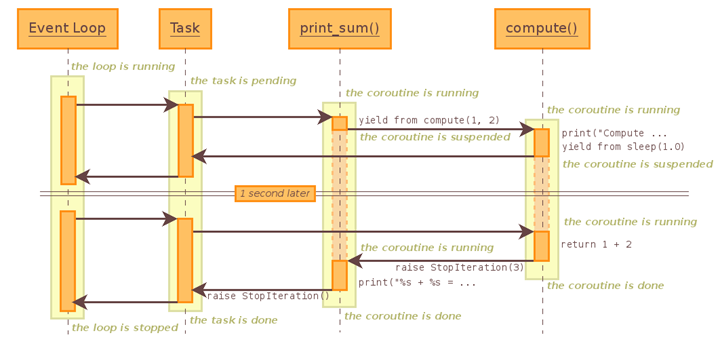 EventLoop 将会把 print_sum 封装成 Task 对象
EventLoop 将会把 print_sum 封装成 Task 对象
流程图展示了这个 demo 的控制流程,不过没有展示其全部细节。比如其中“暂停”的 1s,实际上创建了一个 future 对象,然后通过 BaseEventLoop.call_later() 在 1s 后唤醒这个任务。
注意 @asyncio.coroutine 将在 Python 3.10 版本中移除。
async/await
Python 3.5 开始引入 async/await 语法(PEP 492),用来简化协程的使用并且便于理解。
async/await 实际上只是 @asyncio.coroutine 和 yield from 的语法糖:
- 把 @asyncio.coroutine 替换为 async
- 把 yield from 替换为 await
import asyncio
async def compute(x, y):
print("Compute %s + %s..." % (x, y))
await asyncio.sleep(1.0)
return x + y
async def print_sum(x, y):
result = await compute(x, y)
print("%s + %s = %s" % (x, y, result))
loop = asyncio.get_event_loop()
print("start")
loop.run_until_complete(print_sum(1, 2))
print("end")
loop.close()
我们再来看一个 asyncio 中 Future 的例子:
import asyncio
future = asyncio.Future()
async def coro1():
print("wait 1 second")
await asyncio.sleep(1)
print("set_result")
future.set_result('data')
async def coro2():
result = await future
print(result)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait([coro1(), coro2()]))
loop.close()
输出结果:
wait 1 second set_result data
这里 await 后面跟随的 future 对象,协程中 yield from 或者 await 后面可以调用 future 对象,其作用是:暂停协程,直到 future 执行结束或者返回 result 或抛出异常。
在例子中,await future 必须要等待 future.set_result('data') 后才能够结束。将 coro2() 作为第二个协程可能体现得不够明显,可以将协程的调用改成这样:
loop = asyncio.get_event_loop() loop.run_until_complete(asyncio.wait([coro2(), coro1()])) loop.close()
输出的结果仍旧与上面相同。
其实,async 这个关键字的用法不止能用在函数上,还有 async with 异步上下文管理器,async for 异步迭代。
asyncio 详解
关于 asyncio 的一些关键字的说明:
- event_loop 事件循环:程序开启一个无限循环,把一些函数注册到事件循环上,当满足事件发生的时候,调用相应的协程函数
- coroutine 协程:协程对象,指一个使用 async 关键字定义的函数,它的调用不会立即执行函数,而是会返回一个协程对象。协程对象需要注册到事件循环,由事件循环调用。
- task 任务:一个协程对象就是一个原生可以挂起的函数,任务则是对协程进一步封装,其中包含了任务的各种状态
- future: 代表将来执行或没有执行的任务的结果。它和 task 上没有本质上的区别
- async/await 关键字:5 用于定义协程的关键字,async 定义一个协程,await 用于挂起阻塞的异步调用接口。
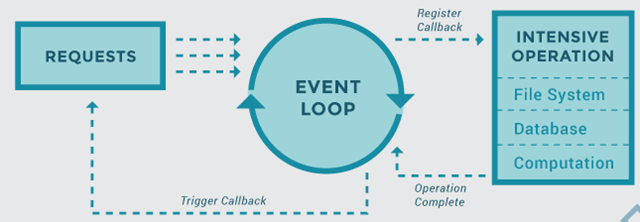
asyncio 模块最大特点就是,只存在一个线程,跟 JavaScript 一样。由于只有一个线程,就不可能多个任务同时运行。asyncio 是"多任务合作"模式(cooperative multitasking),允许异步任务交出执行权给其他任务,等到其他任务完成,再收回执行权继续往下执行,这跟 JavaScript 也是一样的。
由于代码的执行权在多个任务之间交换,所以看上去好像多个任务同时运行,其实底层只有一个线程,多个任务分享运行时间。表面上,这是一个不合理的设计,明明有多线程多进程的能力,为什么放着多余的 CPU 核心不用,而只用一个线程呢?但是就像前面说的,单线程简化了很多问题,使得代码逻辑变得简单,写法符合直觉。
asyncio 模块在单线程上启动一个事件循环(event loop),时刻监听新进入循环的事件,加以处理,并不断重复这个过程,直到异步任务结束。事件循环的内部机制,和 JavaScript 的模型是一样的。
创建协程
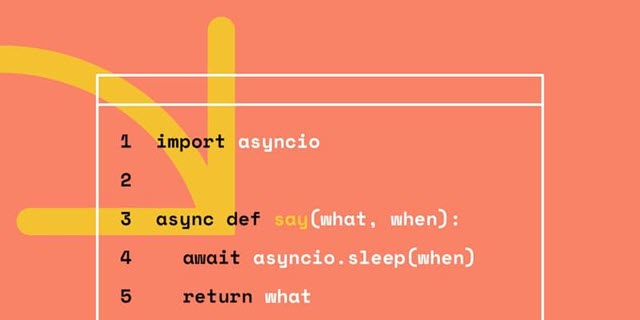
通过 async 关键字定义一个协程(coroutine),协程也是一种对象。下面 say_after,main 就是一个协程:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print("started")
s_time = time.time()
await say_after(1, 'hello')
await say_after(2, 'world')
print("runtime:", time.time() - s_time)
print("finished")
asyncio.run(main())
asyncio.run() 函数用来运行一个协程对象,这里我们将 main() 作为入口函数。await 等待一个协程。上面代码段会在等待 1 秒后打印"hello",然后再次等待 2 秒后打印"world"。asyncio.sleep 表示阻塞多少秒,运行结果如下:
started hello world runtime: 3.001490592956543 finished
可以观察到上面的代码,是同步运行的,两个 await say_after 之间遇到了阻塞。因为 asyncio.run() 只是单纯的运行一个协程,并不会并发运行。
运行协程
运行协程对象的方法主要有:
- 通过 run(main) 运行一个协程,同步的方式,主要用于运行入口协程(实际上参考源码 asyncio.run 本质也是获取 loop,运行协程,即协程依靠 loop 运行)
- 在另一个已经运行的协程中用 `await` 等待它,比如上面运行了 main 协程,其中等待的 say_after 协程也会运行
- 将协程封装成 task 或 future 对象,然后挂到事件循环 loop 上,使用 loop 来运行。主要方法为 run_until_complete。此方法可以异步的并发运行
并发协程
asyncio.create_task()函数用来并发运行多个协程:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print("started")
task1 = asyncio.create_task(say_after(1, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
s_time = time.time()
await task1
await task2
print("runtime:", time.time() - s_time)
print("finished")
asyncio.run(main())
运行输出,比上面快一秒。这里我们使用create_task将协程封装成task对象(会自动的添加到事件循环中),然后我们在main这个入口协程中挂起task1和task2。使用run运行main入口协程,它会自动检测循环事件,并将等待task1和task2两个task执行完成
started hello world runtime: 2.0008769035339355 finished
运行输出,比上面快一秒。这里我们使用create_task将协程封装成task对象(会自动的添加到事件循环中),然后我们在main这个入口协程中挂起task1和task2。使用run运行main入口协程,它会自动检测循环事件,并将等待task1和task2两个task执行完成
asyncio.create_task方法实际是封装了获取事件循环asyncio.get_running_loop()与创建循环任务loop.create_task(coro)的一种高级方法。
可等待对象
await关键字用于将程序控制权移交给事件循环并中断当前协程的执行。它有以下几个使用规则:
- 只能用在由async def修饰的函数中,在普通函数中使用会抛出异常
- 调用一个协程函数后,就必须等待其执行完成并返回结果
- await func()中的func()必须是一个awaitable对象。即一个协程函数或者一个在内部实现了__await__()方法的对象,该方法会返回一个生成器
Awaitable对象包含协程、Task和Future:
- 协程对象:async def的函数对象
- task任务:将协程包装成的一个任务(task)对象,用于注册到事件循环上
- Future:是一种特殊的低层级可等待对象,表示一个异步操作的最终结果
可等待的意思就是跳转到等待对象,并将当前任务挂起。当等待对象的任务处理完了,才会跳回当前任务继续执行。实际上与yield from功能相同,不同的是await后面是awaitable,yield from后面是生成器对象。
对于协程中进行阻塞(Blocking)操作(如IO时)会阻塞掉整个程序,如下面我们使用time.sleep()替代asyncio.sleep(),会发现在time.sleep()协程时程序阻塞,最后时间为4s。
import asyncio
import time
async def say_after(delay, what):
await timesleep(delay)
return what
async def timesleep(delay):
time.sleep(delay)
async def main():
print("started")
task1 = asyncio.create_task(say_after(2, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
s_time = time.time()
await task1
await task2
print(task1.result(), task2.result())
print("runtime:", time.time() - s_time)
print("finished")
asyncio.run(main())
输出:
started hello world runtime: 4.001659870147705 finished
修改如下:
async def timesleep(delay):
await asyncio.sleep(delay)
输出:
started hello world runtime: 2.0003907680511475 finished
一个需要4秒,一个只要2秒。这是因为asyncio.sleep()不同于time.sleep(),它其实在内部实现了一个future对象,事件循环会异步的等待这个对象完成。所以,在事件循环中,使用await可以针对耗时的操作进行挂起,就像生成器里的yield一样,函数让出控制权。对于task与future对象,await可以将他们挂在事件循环上,由于他们相比于协程对象增加了运行状态(Pending、Running、Done、Cancelled等),事件循环则可以读取他们的状态,实现异步的操作,比如上面并发的示例。同时对于阻塞的操作(没有实现异步的操作,如request就会阻塞,aihttp则不会),由于协程是单线程,会阻塞整个程序。
事件循环
事件循环是每个asyncio应用的核心。事件循环会运行异步任务和回调,执行网络IO操作,以及运行子程序。
简单说我们将协程任务(task)注册到事件循环(loop)上,事件循环(loop)会循环遍历任务的状态,当任务触发条件发生时就会执行对应的任务。类似JavaScript事件循环,当onclick被触发时,就会执行对应的js脚本或者回调。同时当遇到阻塞,事件循环回去查找其他可运行的任务。所以事件循环被认为是一个循环,因为它在不断收集事件并遍历它们从而找到如何处理该事件。
通过以下伪代码理解:
while(1){
events = getEvents();
for(e in events)
processEvent(e);
}
所有的时间都在while循环中捕捉,然后经过事件处理者处理。事件处理的部分是系统唯一活跃的部分,当一个事件处理完成,流程继续处理下一个事件。如果遇到阻塞,循环会去执行其他任务,当阻塞任务完成后再回调(具体如何实现不太清楚,应该是将阻塞任务标记状态或者放进其它列来实现)
asyncio中主要的事件循环方法有:
- get_running_loop():返回当前OS线程中正在运行的事件循环对象。
- get_event_loop():获取当前事件循环。如果当前OS线程没有设置当前事件循环并且set_event_loop()还没有被调用,asyncio将创建一个新的事件循环并将其设置为当前循环。
- new_event_loop():创建一个新的事件循环。
- run_until_complete():运行直到future(Future的实例)被完成。如果参数是coroutine object,将被隐式调度为asyncio.Task来运行。返回Future的结果或者引发相关异常。
- create_future():创建一个附加到事件循环中的asyncio.Future对象。
- create_task(coro):安排一个协程的执行。返回一个Task对象。
- run_forever():运行事件循环直到stop()被调用。
- stop():停止事件循环
- close():关闭事件循环。
上面的并发例子就可以改成下面形式:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
def main():
print("started")
s_time = time.time()
loop = asyncio.get_event_loop() # 获取一个事件循环
tasks = [
asyncio.ensure_future(say_after(1, "hello")), # asyncio.ensure_future()包装协程或可等待对象在将来等待。如果参数是Future,则直接返回。
asyncio.ensure_future(say_after(2, "world")),
loop.create_task(say_after(1, "hello")), # loop.create_task()包装协程为task。
loop.create_task(say_after(2, "world"))
]
loop.run_until_complete(asyncio.wait(tasks))
print("runtime:", time.time() - s_time)
print("finished")
main()
asyncio.get_event_loop方法可以创建一个事件循环,然后使用run_until_complete将协程注册到事件循环,并启动事件循环。asyncio.ensure_future(coroutine)和loop.create_task(coroutine)都可以创建一个task,run_until_complete的参数是一个futrue对象。当传入一个协程,其内部会自动封装成task,task是Future的子类。asyncio.wait类似与await不过它可以接受一个list,asyncio.wait()返回的是一个协程。
Task对象
Asyncio是用来处理事件循环中的异步进程和并发任务执行的。它还提供了asyncio.Task()类,可以在任务中使用协程。它的作用是,在同一事件循环中,运行某一个任务的同时可以并发地运行多个任务。当协程被包在任务中,它会自动将任务和事件循环连接起来,当事件循环启动的时候,任务自动运行。这样就提供了一个可以自动驱动协程的机制。
如果被包裹的协程要等待一个future对象,那么任务会被挂起,等待future的计算结果。当future计算完成,被包裹的协程将会拿到future返回的结果或异常(exception)继续执行。另外,需要注意的是,事件循环一次只能运行一个任务,除非还有其它事件循环在不同的线程并行运行,此任务才有可能和其他任务并行。当一个任务在等待future执行的期间,事件循环会运行一个新的任务。
即Task对象封装协程(async标记的函数),将其挂到事件循环上运行,如果遇到等待 future对象(await后面等待的),那么该事件循环会运行其他Task、回调或执行IO操作
相关的主要方法有:
- create_task():高层级的方法,创建Task对象,并自动添加进loop,即get_running_loop()和loop.create_task(coro)的封装
- Task():打包一个协程为Task对象
- current_task(loop=None):返回当前运行的Task实例,如果没有正在运行的任务则返回None。如果loop为None则会使用get_running_loop()获取当前事件循环
- all_tasks(loop=None):返回事件循环所运行的未完成的Task对象的集合。
- cancel():请求取消Task对象。这将安排在下一轮事件循环中抛出一个CancelledError异常给被封包的协程。
- result():返回Task的结果。如果Task对象已完成,其封包的协程的结果会被返回(或者当协程引发异常时,该异常会被重新引发。)。如果Task对象被取消,此方法会引发一个CancelledError异常。如果Task对象的结果还不可用,此方法会引发一个InvalidStateError异常。
通过task.result()获取返回的结果:
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
return what
async def main():
print("started")
task1 = asyncio.create_task(say_after(1, 'hello'))
task2 = asyncio.create_task(say_after(2, 'world'))
s_time = time.time()
await task1
await task2
print(task1.result(), task2.result())
print("runtime:", time.time() - s_time)
print("finished")
asyncio.run(main())
建议使用高层级的asyncio.create_task()函数来创建Task对象,也可用低层级的loop.create_task()或ensure_future()函数。不建议手动实例化asyncio.Task()对象。
Future对象
Future如它的名字一样,是一种对未来的一种抽象,代表将来执行或没有执行的任务的结果。它和task上没有本质上的区别,task是Future的子类。实际上Future包裹协程,添加上各种状态,而task则是在Future上添加一些特性便于挂在事件循环上执行,所以Future就是一个内部底层的对象,平时我们只要关注task就可以了。Future可以通过回调函数处理结果
相关的主要方法有:
- isfuture(obj):判断对象是不是future对象
- ensure_future(obj, loop=None):接收一个协程或者future或者task对象,如果是future则直接返回future,其它则返回task
- result():返回future结果
- set_result(result):将Future标记为完成并设置结果
- add_done_callback(callback, *, context=None):添加一个在Future完成时运行的回调函数。调用callback时,Future对象是它的唯一参数。
官网的一个例子,体现的是Future的四个状态:Pending、Running、Done、Cancelled。创建future的时候,task为pending,事件循环调用执行的时候当然就是running,调用完毕自然就是done。
import asyncio
async def set_after(fut, delay, value):
# Sleep for *delay* seconds.
await asyncio.sleep(delay)
# Set *value* as a result of *fut* Future.
fut.set_result(value)
async def main():
# Get the current event loop.
loop = asyncio.get_running_loop()
# Create a new Future object.
fut = loop.create_future()
# Run "set_after()" coroutine in a parallel Task.
# We are using the low-level "loop.create_task()" API here because
# we already have a reference to the event loop at hand.
# Otherwise we could have just used "asyncio.create_task()".
loop.create_task(
set_after(fut, 1, '...world'))
print('hello...')
# Wait until *fut* has a result (1 second) and print it.
print(await fut)
asyncio.run(main())
如果注释掉 fut.set_result(value),那么 future 永远不会 done。
绑定回调,future 与 task 都可以使用 add_done_callback 方法,因为 task 是 future 子类
import asyncio
async def say_after(delay, what):
await asyncio.sleep(delay)
return what
def callback(future):
print('Callback:', future.result())
coroutine = say_after(2, "hello")
loop = asyncio.get_event_loop()
task = asyncio.ensure_future(coroutine)
task.add_done_callback(callback)
loop.run_until_complete(task)
协程实战:网页抓取
绑定回调
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
def callback(task):
print('Status:', task.result())
coroutine = request()
task = asyncio.ensure_future(coroutine)
task.add_done_callback(callback)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
我们定义了一个 request() 方法,请求了百度,返回状态码,但是这个方法里面我们没有任何 print() 语句。随后我们定义了一个 callback() 方法,这个方法接收一个参数,是 task 对象,然后调用 print() 方法打印了 task 对象的结果。这样我们就定义好了一个 coroutine 对象和一个回调方法,我们现在希望的效果是,当 coroutine 对象执行完毕之后,就去执行声明的 callback() 方法。那么它们二者怎样关联起来呢?很简单,只需要调用 add_done_callback() 方法即可,我们将 callback() 方法传递给了封装好的 task 对象,这样当 task 执行完毕之后就可以调用 callback() 方法了,同时 task 对象还会作为参数传递给 callback() 方法,调用 task 对象的 result() 方法就可以获取返回结果了。运行结果:
Task: <Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5> cb=[callback() at D:/CodeHub/LearnPython/t1.py:11]> Status: <Response [200]> Task: <Task finished coro=<request() done, defined at D:/CodeHub/LearnPython/t1.py:5> result=<Response [200]>>
实际上不用回调方法,直接在 task 运行完毕之后也可以直接调用 result() 方法获取结果:
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
coroutine = request()
task = asyncio.ensure_future(coroutine)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
print('Task Result:', task.result())
运行结果:
Task: <Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5>> Task: <Task finished coro=<request() done, defined at D:/CodeHub/LearnPython/t1.py:5> result=<Response [200]>> Task Result: <Response [200]>
多任务协程
上面的例子我们只执行了一次请求,如果我们想执行多次请求应该怎么办呢?我们可以定义一个 task 列表,然后使用 asyncio 的 wait() 方法即可执行:
import asyncio
import requests
async def request():
url = 'https://www.baidu.com'
status = requests.get(url)
return status
tasks = [asyncio.ensure_future(request()) for _ in range(5)]
print('Tasks:', tasks)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
for task in tasks:
print('Task Result:', task.result())
这里我们使用一个 for 循环创建了五个 task,组成了一个列表,然后把这个列表首先传递给了 asyncio 的 wait() 方法,然后再将其注册到时间循环中,就可以发起五个任务了。最后我们再将任务的运行结果输出出来,运行结果如下:
Tasks: [<Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5>>, <Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5>>, <Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5>>, <Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5>>, <Task pending coro=<request() running at D:/CodeHub/LearnPython/t1.py:5>>] Task Result: <Response [200]> Task Result: <Response [200]> Task Result: <Response [200]> Task Result: <Response [200]> Task Result: <Response [200]>
可以看到五个任务被顺次执行了,并得到了运行结果。
使用 aiohttp
aiohttp 是一个支持异步请求的库,利用它和 asyncio 配合我们可以非常方便地实现异步请求操作。
import asyncio
import aiohttp
import time
start = time.time()
async def get(url):
session = aiohttp.ClientSession()
response = await session.get(url)
result = await response.text()
session.close()
return result
async def request():
url = 'https://www.baidu.com'
print('Waiting for', url)
result = await get(url)
print('Get response from', url)
tasks = [asyncio.ensure_future(request()) for _ in range(5)]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.time()
print('Cost time:', end - start)
参考链接:



写的很好,非常全面,感谢博主