Apache Pig 简介
Apache Pig 是一个用于处理和分析大型数据集的高层数据流脚本平台,主要运行在 Hadoop 集群上。Pig 提供了一种称为 Pig Latin 的语言,允许用户以更高的抽象层次来编写数据分析程序,而无需直接使用复杂的 MapReduce 编程模型。

Apache Pig 是用来处理大规模数据的高级查询语言,配合 Hadoop 使用,可以在处理海量数据时达到事半功倍的效果,比使用 Java,C++ 等语言编写大规模数据处理程序的难度要小 N 倍,实现同样的效果的代码量也小 N 倍。Apache Pig 为大数据集的处理提供了更高层次的抽象,为 mapreduce 算法(框架)实现了一套类 SQL 的数据处理脚本语言的 shell 脚本,在 Pig 中称之为 Pig Latin,在这套脚本中我们可以对加载出来的数据进行排序、过滤、求和、分组(group by)、关联(Joining),Pig 也可以由用户自定义一些函数对数据集进行操作,也就是传说中的 UDF(user-defined functions)。
核心概念
- Pig Latin
- Pig Latin 是一种脚本语言,专为处理大规模数据集而设计。它提供了一种简洁且强大的方式来描述数据转换和分析任务。
- Pig Latin 语言支持常见的数据操作,如过滤、排序、连接、分组和聚合。
- Pig 运行模式
- 本地模式: 在单机上运行 Pig 作业,适用于开发和测试。
- MapReduce 模式: 在 Hadoop 集群上运行,利用集群的分布式计算能力来处理大规模数据。
- 数据模型
- Pig 使用一种灵活的数据模型,支持原始数据类型(如 int、long、float)和复杂数据类型(如 tuple、bag、map)。
- 架构组件
- Pig Scripts: 用户编写的 Pig Latin 脚本,用于定义数据处理逻辑。
- Pig Compiler: 将 Pig Latin 脚本编译成一系列 MapReduce 作业。
- Execution Engine: 执行编译后的 MapReduce 作业,通常是 Hadoop。
特性和优势
- 简化编程模型。Pig Latin 提供了比原生 MapReduce 更高层次的编程抽象,简化了复杂数据处理任务的编写。
- 可扩展性。Pig 能够处理 PB 级别的数据集,适用于大规模数据分析任务。
- 灵活性。支持自定义函数(UDF),用户可以用 Java、Python 等语言编写自定义逻辑,以扩展 Pig 的功能。
- 易于调试。Pig Latin 脚本更接近数据流描述,便于理解和调试。
- 数据流优化。Pig 的执行引擎能够自动优化数据流,提升作业的执行效率。
适用场景
- ETL 过程。Pig 非常适合用于提取、转换和加载(ETL)过程,处理从不同数据源获取的大量数据。
- 数据分析。支持复杂的数据分析和统计计算,适用于需要对大规模数据集进行深入分析的场景。
- 数据准备。在进行机器学习或数据挖掘之前,Pig 可以用于准备和清洗数据。
- 快速原型开发。Pig Latin 脚本的简洁性使得开发者能够快速开发和测试数据处理逻辑。
Apache Pig 的架构
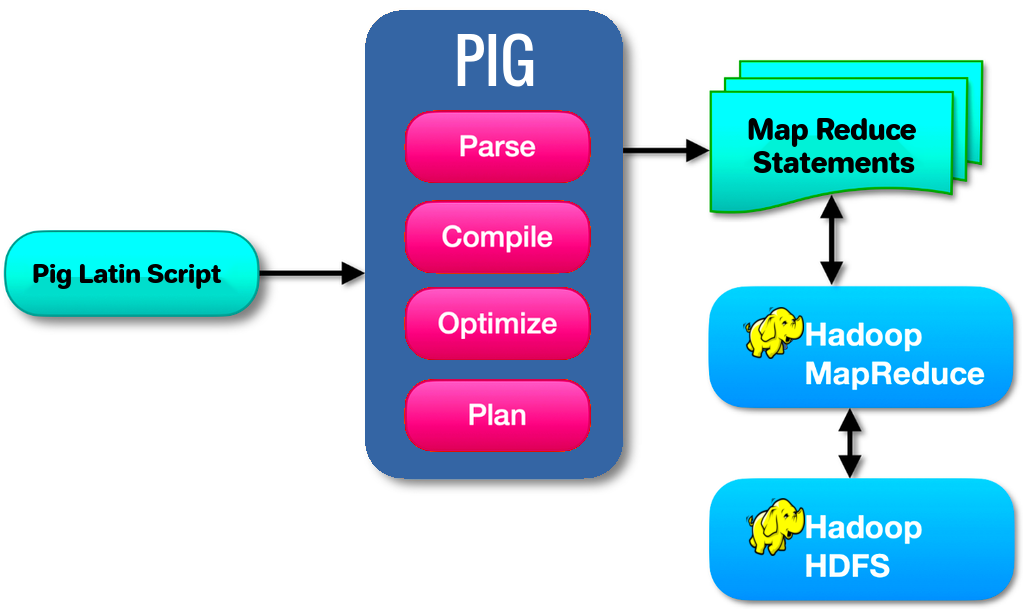
Apache Pig 的架构设计旨在为用户提供一种高效、灵活且易于使用的方式来处理大规模数据集。其架构由多个组件组成,这些组件协同工作,将用户编写的 Pig Latin 脚本转换为可在 Hadoop 上执行的 MapReduce 作业。以下是 Apache Pig 的主要架构组件及其功能:
- Pig Latin Script
- 用户接口: 用户通过编写 Pig Latin 脚本来定义数据处理逻辑。这些脚本描述了数据的加载、转换、处理和存储过程。
- Pig Compiler
- 解析和优化: Pig Compiler 将 Pig Latin 脚本解析成逻辑计划,然后进行优化以提高执行效率。
- 生成物理计划: 经过优化的逻辑计划会被转换为物理计划,这个计划具体描述了如何执行数据处理操作。
- Execution Engine
- 执行引擎: Pig 的执行引擎负责将物理计划转换为可在 Hadoop 上运行的 MapReduce 作业。
- 任务调度: 执行引擎将生成的 MapReduce 作业提交到 Hadoop 集群中,并管理其执行。
- Hadoop
- 分布式计算: Pig 的执行依赖于 Hadoop 的分布式计算能力,利用 Hadoop 的 HDFS 存储数据,并使用 MapReduce 框架进行计算。
- 数据模型
- 灵活的数据类型: Pig 支持多种数据类型,包括基本数据类型(int、long、float 等)和复杂数据类型(tuple、bag、map 等),以适应多样化的数据处理需求。
- 自定义功能
- 用户自定义函数(UDF): Pig 支持用户编写自定义函数,以扩展其内置功能。这些函数可以用 Java、Python 等语言编写,并在 Pig Latin 脚本中使用。
- 执行模式
- 本地模式: 在单机上执行 Pig 脚本,适用于开发和调试。
- MapReduce 模式: 在 Hadoop 集群上执行,适用于处理大规模数据集。
Pig 的工作流程
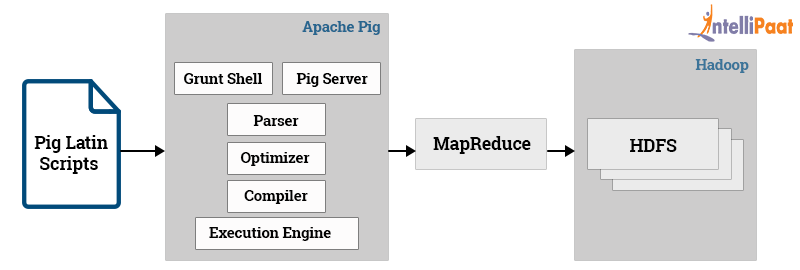
- 编写 Pig Latin 脚本: 用户定义数据处理逻辑。
- 解析和优化: Pig Compiler 解析脚本,生成逻辑计划,并进行优化。
- 生成物理计划: 将优化后的逻辑计划转换为物理计划。
- 生成 MapReduce 作业: Pig 将物理计划转换为一系列 MapReduce 作业。
- 提交和执行: 执行引擎将作业提交到 Hadoop 集群,并监控其执行。
输出结果:处理结果存储在 HDFS 或其他指定的存储系统中。
Apache Pig 的架构通过一系列组件协同工作,实现了从高层次数据流描述到分布式数据处理作业的转换。Pig 的设计目标是简化大规模数据集的处理,降低编程复杂性,同时利用 Hadoop 的分布式计算能力,实现高效的数据处理和分析。通过灵活的数据模型和扩展能力,Pig 成为大数据处理领域的重要工具之一。
Pig Latin 语言
Pig Latin 是 Apache Pig 提供的一种高级数据流语言,专为大规模数据处理而设计。它简化了复杂的数据处理任务,使得用户能够在不直接编写 MapReduce 程序的情况下,对大规模数据集进行分析和转换。以下是对 Pig Latin 语言的详细介绍:
基本概念
- 数据流语言: Pig Latin 是一种数据流语言,类似于 SQL,但更灵活。它允许用户以声明性的方式描述数据处理任务。
- 面向数据处理: 语言的设计目标是简化大规模数据集的处理,支持常见的数据操作,如过滤、排序、连接、聚合等。
数据模型
- 原始数据类型: 支持基本数据类型,如 int、long、float、double、chararray(字符串)、bytearray(字节数组)和 boolean。
- 复杂数据类型:
- Tuple: 有序字段的集合,类似于数据库中的一行。
- Bag: 无序的 tuple 集合,类似于关系数据库中的表。
- Map: 键值对的集合,键是唯一的字符串,值可以是任何数据类型。
Pig Latin 语法
# 加载数据: 使用 LOAD 语句从存储系统(如 HDFS)中加载数据。
data = LOAD 'input_data.txt' USING PigStorage(',') AS (name:chararray, age:int, salary:float);
# 过滤数据: 使用 FILTER 语句过滤数据。
filtered_data = FILTER data BY age > 25;
# 分组数据: 使用 GROUP 语句对数据进行分组。
grouped_data = GROUP filtered_data BY name;
# 聚合操作: 使用 FOREACH...GENERATE 语句进行数据转换和聚合。
average_salary = FOREACH grouped_data GENERATE group, AVG(filtered_data.salary);
# 连接数据: 使用 JOIN 语句连接多个数据集。
joined_data = JOIN data1 BY id, data2 BY id;
# 排序数据: 使用 ORDER 语句对数据进行排序。
sorted_data = ORDER data BY salary DESC;
# 存储数据: 使用 STORE 语句将结果数据存储到指定的存储系统中。
STORE average_salary INTO 'output_data.txt' USING PigStorage(',');
扩展能力
- 用户自定义函数(UDF): Pig Latin 支持用户编写自定义函数来扩展其功能。这些函数可以用 Java、Python 等语言编写,并在 Pig Latin 脚本中使用。
示例脚本
以下是一个完整的 Pig Latin 脚本示例,展示如何加载数据、过滤、分组、聚合和存储结果:
-- 加载数据
data = LOAD 'input_data.txt' USING PigStorage(',') AS (name:chararray, age:int, salary:float);
-- 过滤数据
filtered_data = FILTER data BY age > 25;
-- 按名字分组
grouped_data = GROUP filtered_data BY name;
-- 计算每组的平均工资
average_salary = FOREACH grouped_data GENERATE group, AVG(filtered_data.salary);
-- 存储结果
STORE average_salary INTO 'output_data.txt' USING PigStorage(',');
优势
- 简洁性: Pig Latin 语法简洁,易于学习和使用,适合数据科学家和分析师。
- 灵活性: 支持复杂的数据处理逻辑和用户自定义扩展。
- 抽象性: 提供高层次的抽象,用户无需了解底层的 MapReduce 细节。
Pig Latin 是一种功能强大且灵活的数据流语言,专为处理大规模数据集而设计。通过简化数据处理流程,Pig Latin 使得用户能够高效地进行数据分析和转换,同时利用 Hadoop 的分布式计算能力来处理大规模数据。其灵活的数据模型和扩展能力使得 Pig Latin 成为大数据处理领域的重要工具之一。
Apache Pig 与 Hive 的对比
Apache Pig 和Apache Hive 是两个常用于大数据处理的工具,它们都建立在Hadoop 生态系统之上,并提供了高层次的抽象来简化数据处理和分析任务。尽管它们在功能上有一些重叠,但也有显著的区别和适用场景。以下是对 Apache Pig 和 Hive 的详细对比:
以下是 Apache Pig 和 Apache Hive 的对比,以表格形式呈现:
| 特性 | Apache Pig | Apache Hive |
| 设计目的 | 为数据工程师提供灵活的数据处理工具,适合 ETL 任务 | 为数据分析师提供 SQL-like 查询工具,适合数据仓库应用 |
| 编程模型 | 数据流语言 Pig Latin,过程化编程 | SQL-like 查询语言 HiveQL,声明式编程 |
| 数据处理 | 适合处理半结构化和非结构化数据 | 专注于结构化数据分析 |
| 执行模式 | 通常用于批处理,支持本地模式和 MapReduce 模式 | 支持批处理和交互式查询,运行在 MapReduce、Tez、Spark 上 |
| 扩展性 | 支持用户自定义函数(UDF),灵活扩展数据处理逻辑 | 支持用户定义的函数(UDF),轻量级扩展 HiveQL |
| 性能和优化 | 提供基本优化功能,手动优化复杂脚本 | 提供查询优化器,支持分区、桶、索引等优化功能 |
| 适用场景 | 复杂数据处理和转换,ETL 过程 | 数据仓库和商业智能应用,结构化数据查询 |
| 用户群体 | 数据工程师和程序员 | 数据分析师和业务用户 |
总结
- Apache Pig 更加灵活,适合复杂的数据处理任务,特别是在需要处理半结构化和非结构化数据时。
- Apache Hive 提供了熟悉的 SQL-like 查询语言,适合结构化数据分析和数据仓库应用。
参考链接:


