YARN简介
Apache Hadoop YARN(Yet Another Resource Negotiator)是Hadoop生态系统中的一个关键组件,负责集群资源管理和作业调度。YARN的引入大大提升了Hadoop的可扩展性和灵活性,使得不同类型的计算框架可以在同一集群上高效运行。

产生背景
Apache Hadoop YARN(Yet Another Resource Negotiator)的产生背景可以追溯到Hadoop早期版本(1.x)中资源管理和调度的局限性。随着大数据处理需求的不断增长,Hadoop 1.x的架构逐渐暴露出一些问题,这些问题促使了YARN的诞生。
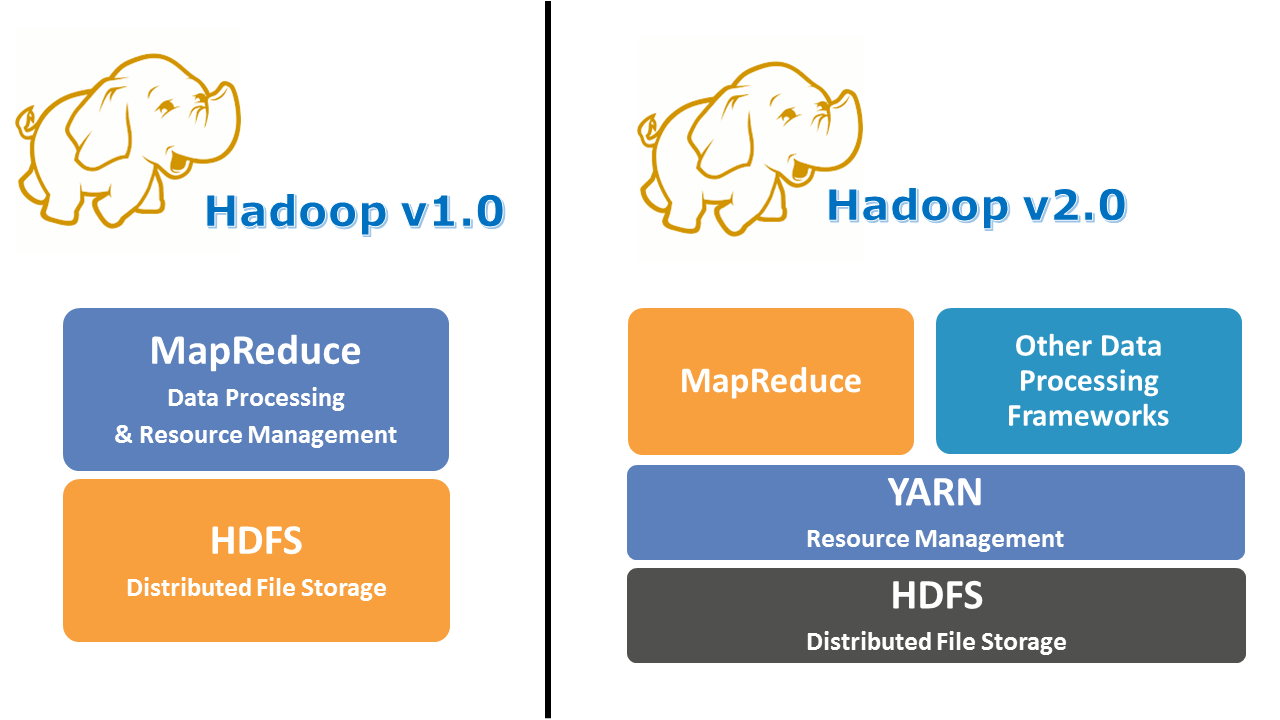
- Hadoop 1.x的局限性
- 单点瓶颈: 在Hadoop 1.x中,JobTracker负责整个集群的资源管理和作业调度。随着集群规模的扩大,JobTracker成为了性能瓶颈,无法高效地管理大量节点和任务。
- 资源利用率低: Hadoop 1.x的资源管理模型较为简单,主要是基于槽位(slot)的概念,无法灵活地分配和管理CPU和内存资源。这导致了资源利用率低下,尤其是在处理不同类型的任务时。
- 单一框架限制: Hadoop 1.x主要支持MapReduce作业,缺乏对其他计算框架的支持。这限制了Hadoop在大数据处理领域的应用范围,无法满足日益多样化的数据处理需求。
- 大数据处理需求的增长
- 多样化的数据处理任务: 随着大数据技术的发展,企业和研究机构需要处理的任务类型越来越多样化,包括批处理、交互式查询、流处理和机器学习等。单一的MapReduce模型已经不能满足这些需求。
- 实时性要求: 数据驱动的决策需要更实时的数据处理能力,传统的批处理模式已经不能满足业务的实时性要求。
- 生态系统的演进
- 多框架共存: 随着Hadoop生态系统的扩展,出现了多种数据处理框架(如Tez、Spark、Flink等)。这些框架需要一个通用的资源管理和调度平台,以便在同一集群上高效运行。
- 资源管理的标准化: 为了提高资源利用率和管理效率,业界需要一个标准化的资源管理框架,能够支持多种计算模型和任务类型。
- 技术创新和社区推动
- 技术创新: Hadoop社区和技术专家们提出了新的资源管理和调度模型,旨在解决Hadoop 1.x的局限性。YARN的设计理念借鉴了分布式计算领域的最新研究成果。
- 社区支持: Hadoop社区的积极参与和贡献,推动了YARN的开发和推广。许多企业和开源项目都参与到YARN的开发和测试中,确保其稳定性和性能。
- 商业需求
- 企业级应用: 大型企业需要一个更加高效、灵活和可靠的资源管理平台,以支持大规模的数据处理和分析任务。YARN的引入为企业级应用提供了更好的支持。
- 成本效益: 通过提高资源利用率和管理效率,YARN帮助企业降低硬件和运维成本,提高投资回报率。
YARN的产生是为了解决Hadoop 1.x在资源管理和调度方面的局限性,满足大数据处理需求的增长,支持多框架共存,以及推动技术创新和社区发展。YARN的引入标志着Hadoop从单一的MapReduce框架向多功能数据处理平台的转变,为Hadoop生态系统的进一步发展奠定了基础。
适用场景
Apache Hadoop YARN是一个强大的资源管理和调度平台,广泛用于大数据处理环境。以下是YARN的优缺点及其适用场景:
优点
- 高效的资源利用 YARN通过灵活的资源调度和分配机制,提高了集群的资源利用率,能够更好地管理CPU和内存等资源。
- 支持多种计算框架 YARN可以支持多种计算框架在同一集群上运行,如MapReduce、Tez、Spark、Flink等。这种多样性使其适合各种数据处理任务。
- 扩展性强 YARN具有良好的扩展性,能够处理从几台到几千台机器的集群规模,适应不同规模的企业需求。
- 弹性和容错性 YARN提供了良好的容错机制,能够在节点故障时自动重新调度任务,确保作业的可靠执行。
- 集成性 YARN与Hadoop生态系统中的其他组件(如HDFS、Hive、Pig)紧密集成,为大数据应用提供了完整的解决方案。
缺点
- 复杂性 YARN的架构和配置相对复杂,需要专业的知识和经验来管理和调优,增加了运维的难度。
- 延迟问题 对于一些需要低延迟的实时应用,YARN的批处理特性可能不够理想,尽管可以通过一些框架(如Spark Streaming)来缓解这一问题。
- 容器化支持有限 虽然YARN支持运行容器化应用,但其容器管理能力相对Kubernetes等现代容器编排系统较弱。
- 资源分配固定 YARN的资源分配机制相对固定,可能导致资源利用不均衡,尤其是在运行多种类型的作业时。
适用场景
- 大规模批处理 YARN非常适合处理大规模的批处理作业,如使用MapReduce进行数据清洗和转换。
- 交互式查询 通过支持Tez和Hive,YARN可以高效地处理交互式查询任务,适用于数据分析和商业智能应用。
- 流处理 尽管YARN主要用于批处理,但通过集成Spark Streaming等框架,也可以用于流处理应用。
- 多框架共存 在需要同时运行多种大数据处理框架的环境中,YARN提供了一个统一的资源管理平台,适合复杂的数据处理管道。
- 企业级数据处理 对于需要在同一集群上运行多种数据处理任务的企业,YARN提供了良好的资源管理和调度能力。
YARN是一个强大的资源管理和调度平台,特别适合大规模数据处理任务和多框架共存的环境。然而,对于需要更灵活的资源管理和低延迟处理的应用,可能需要结合其他技术来实现。选择YARN作为资源管理平台应基于具体的业务需求和技术环境。
YARN的架构
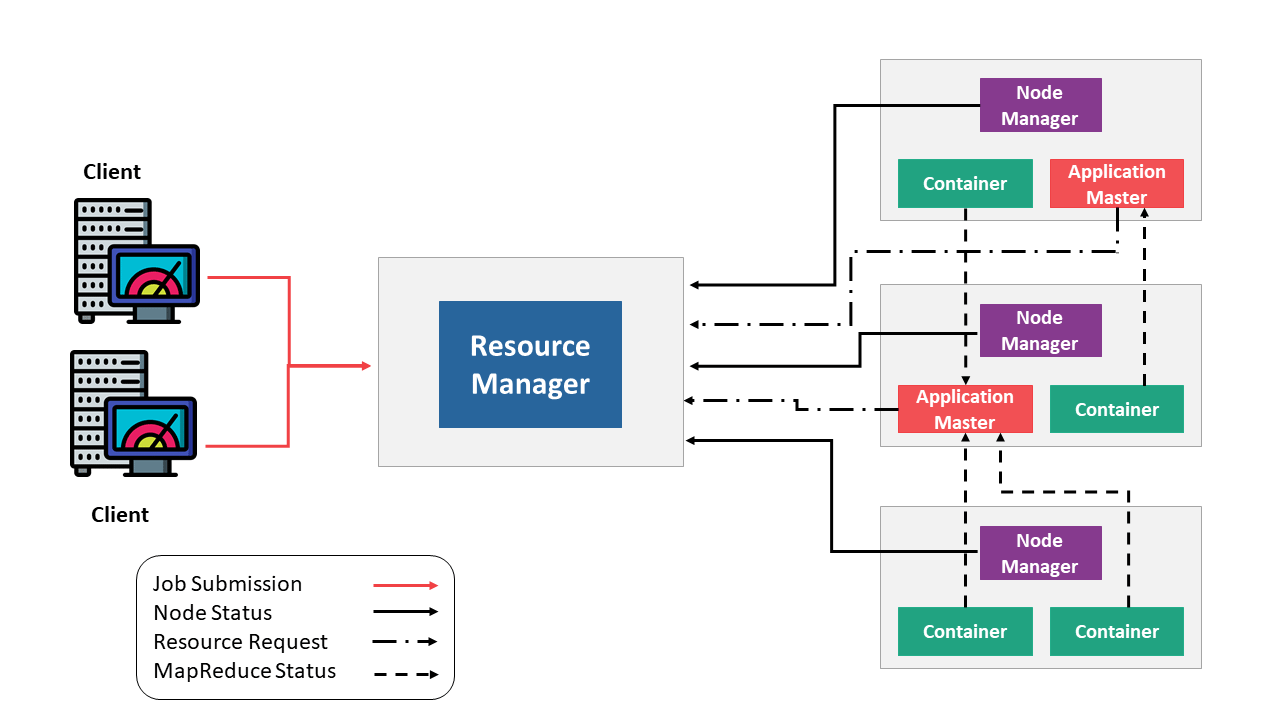
Apache Hadoop YARN(Yet Another Resource Negotiator)是一种强大的资源管理和调度框架,专为大数据处理而设计。YARN的架构设计旨在解决Hadoop 1.x中资源管理和调度的局限性,提高资源利用率和灵活性。以下是YARN的详细架构:
主要组件
- ResourceManager (RM)
- 全局资源管理器: 负责整个集群的资源管理和调度。
- 调度器 (Scheduler): 负责将资源分配给不同的应用程序,确保资源使用的高效性和公平性。
- 应用管理器 (Application Manager): 处理每个应用程序的启动、监控和重试。
- NodeManager (NM)
- 节点级资源管理器: 运行在集群中的每个节点上,负责管理该节点的资源(如 CPU、内存)和容器(Container)。
- 容器管理: 容器是 YARN 中的资源分配单位,NM 负责启动和监控容器。
- ApplicationMaster (AM)
- 应用程序特定管理器: 每个应用程序都有一个 AM,负责应用程序的具体调度和执行。AM 协调 NM 上的容器,确保应用程序的任务顺利完成。
- 容器 (Container)
- 资源分配单位: 容器是 YARN 中的最小资源分配单位,包含了 CPU、内存等资源。应用程序的每个任务都在容器中运行。
工作流程
- 应用提交
- 用户通过客户端提交应用程序到 ResourceManager。
- ResourceManager 接收应用请求并分配一个 ApplicationID。
- AM 启动
- ResourceManager 为应用程序分配第一个容器,并在该容器中启动 ApplicationMaster。
- ApplicationMaster 向 ResourceManager 注册自己,并请求资源。
- 资源请求
- ApplicationMaster 向 ResourceManager 请求更多容器资源,指定所需的资源类型和数量。
- ResourceManager 根据调度策略分配资源给 ApplicationMaster。
- 任务执行
- ApplicationMaster 从 ResourceManager 获取资源后,与相应的 NodeManager 通信,请求启动容器。
- NodeManager 在本地启动容器,并运行应用程序的任务。
- ApplicationMaster 负责监控任务的执行状态,确保任务的顺利进行。
- 监控与完成
- ApplicationMaster 监控任务的执行状态,处理任务失败和重试。
- 任务完成后,ApplicationMaster 向 ResourceManager 注销自己,释放资源。
关键概念
- 资源 YARN 中的资源主要包括 CPU 和内存。每个节点的资源由 NodeManager 管理。
- 容器 (Container) 容器是 YARN 中的资源分配单位,包含了一定数量的 CPU 和内存资源。应用程序的任务在容器中运行。
- 应用程序 (Application) 一个应用程序可以包含多个任务,每个任务运行在一个或多个容器中。应用程序由 ApplicationMaster 管理。
- 调度策略 YARN 支持多种调度策略,如 FIFO、Fair、Capacity 等,可以根据实际需求选择合适的调度策略。
优势
- 高效的资源利用。通过灵活的资源调度和分配机制,提高了集群的资源利用率。
- 支持多种计算框架。YARN 可以支持多种计算框架在同一集群上运行,如 MapReduce、Tez、Spark、Flink 等。
- 扩展性强。YARN 具有良好的扩展性,能够处理从几台到几千台机器的集群规模。
- 弹性和容错性。提供了良好的容错机制,能够在节点故障时自动重新调度任务,确保作业的可靠执行。
YARN 的架构设计使其成为大数据处理领域的强大工具,特别适合需要高效资源管理和调度的场景。通过分离资源管理和应用调度,YARN 提高了 Hadoop 的可扩展性和灵活性,支持多种计算框架在同一集群上运行。
与 Kubernetes 对比
Apache Hadoop YARN 和 Kubernetes(K8s)都是流行的资源管理和调度系统,但它们设计的初衷和应用场景有所不同。以下是 YARN 和 Kubernetes 的详细对比:
| 特性 | Apache Hadoop YARN | Kubernetes (K8s) |
| 设计初衷 | 专为大数据处理而设计,优化 Hadoop 生态系统中的资源管理 | 通用的容器编排平台,适用于广泛的应用场景 |
| 主要用途 | 管理和调度 Hadoop 集群中的大数据作业 | 部署、管理和扩展容器化应用 |
| 资源管理 | 以集群为单位,管理计算框架的任务和资源 | 基于容器的资源管理,支持多租户隔离和资源分配 |
| 调度机制 | 任务调度基于计算框架(如 MapReduce、Tez)的需求 | Pod 调度基于节点资源和策略,支持多种调度策略 |
| 扩展性 | 主要扩展性在于支持多种大数据框架 | 高度可扩展,支持自动扩展、滚动更新、负载均衡等功能 |
| 容器支持 | 原生支持 Hadoop 应用,容器支持有限 | 原生支持容器化应用,广泛支持 Docker 和其他容器技术 |
| 应用场景 | 适合批处理、交互式查询和流处理等大数据任务 | 适合微服务架构、CI/CD 流水线、云原生应用等 |
| 生态系统 | 集成在 Hadoop 生态系统中,与 HDFS、MapReduce 紧密结合 | 丰富的插件和工具生态,支持 Helm、Istio 等 |
| 管理工具 | 提供 Yarn CLI 和 Web UI 管理工具 | 提供 kubectl、Dashboard 和多种第三方管理工具 |
| 社区和支持 | 主要由 Hadoop 社区支持 | 拥有活跃的全球社区和广泛的企业支持 |
YARN 和 Kubernetes 各有其优势和适用场景。YARN 更适合大数据处理任务,特别是在 Hadoop 生态系统中,而 Kubernetes 则是一个通用的容器编排平台,适合广泛的应用场景。选择使用哪种技术应根据具体的应用需求、现有技术栈和团队的技术能力来决定。
参考链接:


