DeltaLake 简介
DeltaLake 是一个开源的存储层,构建在 Apache Spark 之上,旨在实现可靠的、可扩展的、高性能的数据湖。它通过引入 ACID 事务、版本控制和 schema 演化等功能,解决了传统数据湖的一些固有问题,如数据一致性、可靠性和管理复杂性。

DeltaLake 产生的背景
DeltaLake 的产生背景可以追溯到大数据生态系统的发展和企业在数据管理过程中面临的一些挑战。
以下是 DeltaLake 产生的背景和原因:
- 数据湖的局限性
- 数据一致性问题: 传统数据湖通常基于分布式文件系统(如 HDFS 或云存储)构建,缺乏事务支持。这导致在数据写入过程中可能出现不一致的数据状态,特别是在并发写入或失败恢复的情况下。
- 数据质量和管理复杂性: 在数据湖中,数据可能来自多种来源,格式各异,缺乏统一的 schema 管理和数据质量保证机制。这使得数据治理和管理变得复杂。
- 缺乏实时数据处理能力: 传统的数据湖主要用于批处理工作流,缺乏对实时数据流的高效支持。企业需要在批处理和流处理之间进行复杂的转换。
- 对 ACID 事务的需求
- 数据可靠性和一致性: 随着企业数据量的增长和使用场景的复杂化,数据的可靠性和一致性变得尤为重要。ACID 事务可以确保在多用户环境下,数据操作的原子性和一致性。
- 多用户并发访问: 企业通常需要多个用户同时访问和操作数据,缺乏事务支持的数据湖难以处理并发读写操作。
- 增强的查询性能需求
- 大规模数据分析: 企业需要对海量数据进行快速分析,以支持业务决策。传统数据湖的查询性能常常不尽如人意,需要更高效的存储和索引机制来提升性能。
- 增量数据处理: 需要支持增量更新和查询,以便在不重新处理所有数据的情况下,只处理新增或更新的数据。
- 云计算和大数据技术的发展
- 云存储的普及: 随着云计算的普及,企业越来越多地将数据存储在云上。云存储的低成本和高可扩展性推动了数据湖的采用,但也带来了管理和一致性方面的挑战。
- Apache Spark 的流行: Apache Spark 作为一个强大的分布式计算引擎,广泛用于大数据处理。DeltaLake 的设计充分利用了 Spark 的计算能力,提供了一种高效的数据管理解决方案。
- 统一数据处理需求
DeltaLake 的产生是为了解决传统数据湖在一致性、管理、性能和实时处理能力等方面的不足。通过引入 ACID 事务、版本控制和 schema 管理等功能,DeltaLake 提供了一种可靠、高效的数据存储层,满足了现代企业对数据管理和分析的多样化需求。其与 Apache Spark 的紧密集成使其能够在大规模数据处理环境中发挥重要作用。
DeltaLake 的优缺点
DeltaLake 作为一个构建在 Apache Spark 之上的开源存储层,提供了一系列增强功能来解决传统数据湖的一些不足。
优点
- ACID 事务支持:
- DeltaLake 提供了 ACID 事务支持,确保数据的一致性和可靠性。这使得在并发读写和系统故障恢复的情况下,数据仍然保持一致。
- Schema 演化和强制:
- 支持 schema 演化,允许数据表结构的动态更新,而不会影响现有的数据。
- 强制 schema 可以防止错误或不完整的数据写入,提高数据质量。
- 时间旅行和版本控制:
- 支持数据版本控制和“时间旅行”功能,允许用户查询历史数据版本。这对于数据审计、调试和回滚非常有用。
- 高性能查询:
- 通过数据跳跃(Data Skipping)和文件压缩等优化技术,DeltaLake 提高了数据查询的性能。
- 利用 Spark 的分布式计算能力,DeltaLake 能够高效地处理大规模数据集。
- 统一的批处理和流处理:
- DeltaLake 提供统一的 API 来支持批处理和流处理,这简化了数据架构,并提高了处理效率。
- 数据质量保障:
- 通过约束和检查机制,DeltaLake 确保了数据的完整性和准确性。
- 与云存储的兼容性:
- 支持与多种云存储系统(如 AWS S3、Azure Blob Storage 和 Google Cloud Storage)的集成,灵活性高。
缺点
- 依赖 Apache Spark: DeltaLake 主要依赖于 Apache Spark 进行数据处理,这意味着如果企业的技术栈不包括 Spark,则需要额外的学习和整合成本。
- 初始设置和管理复杂性: 尽管 DeltaLake 提供了许多功能,但它的设置和管理可能会比较复杂,特别是在配置事务日志和优化查询性能时。
- 社区支持和生态系统: 作为一个相对较新的开源项目,DeltaLake 的社区支持和生态系统可能不如一些成熟的技术广泛。
- 额外的存储开销: 由于 DeltaLake 需要存储事务日志和元数据,这可能会导致额外的存储开销,特别是在数据更新频繁的情况下。
- 功能局限性: 虽然 DeltaLake 提供了许多增强功能,但在某些特定场景下,可能无法替代专用的数据库系统(如关系型数据库或 NoSQL 数据库)提供的特定功能。
DeltaLake 的使用场景
DeltaLake 是一个功能强大的存储层,适用于各种数据处理和分析场景。以下是一些常见的 DeltaLake 使用场景:
- 数据湖管理。可靠的数据湖存储: DeltaLake 为数据湖提供了一种可靠的存储层,通过 ACID 事务支持,确保数据一致性和可靠性,适合用于大规模数据存储和管理。
- 实时数据分析。流式数据处理: 支持流式数据摄取和处理,允许用户在数据流入的同时进行实时分析。这对于需要实时监控和决策的应用场景非常有用。
- 批处理和流处理的融合。统一数据处理平台: DeltaLake 支持在同一平台上进行批处理和流处理,简化了数据架构。这种融合适用于需要同时处理历史数据和实时数据的场景。
- 增量数据处理。高效的增量更新: DeltaLake 支持增量数据更新和查询,使得在不重新处理所有数据的情况下,只处理新增或更新的数据。这对于需要频繁更新的数据集尤其有用。
- 数据版本控制和审计。时间旅行功能: 支持数据的版本控制和“时间旅行”,允许用户查询历史版本的数据。这对于数据审计、调试和回滚操作非常有用。
- 数据质量和治理。数据一致性和质量保证: 通过 schema 强制和数据验证机制,DeltaLake 确保了数据的结构一致性和质量。这适用于需要严格数据治理的场景。
- 机器学习和高级分析。大规模数据处理: DeltaLake 的高性能查询和数据管理能力使其适合用于机器学习模型的训练和评估,特别是在大规模数据集上。
- 数据集成和 ETL。高效的 ETL 处理: DeltaLake 提供高效的 ETL(Extract, Transform, Load)处理能力,支持从各种数据源提取、转换并加载到数据湖中。
- 合规性和数据回溯
- 数据合规和法规遵从: 通过时间旅行和版本控制功能,Delta Lake 可以帮助企业满足数据合规性和法规要求,支持数据的审计和历史追溯。
- 云环境中的应用: 与云存储的集成: Delta Lake 可以无缝集成到云存储解决方案中,如 AWS S3、Azure Blob Storage 和 Google Cloud Storage,适用于基于云的分析和存储应用。
Delta Lake 的架构
Delta Lake 是一个构建在 Apache Spark 之上的开源存储层,其架构设计旨在为数据湖提供可靠的 ACID 事务支持、版本控制和高性能查询能力。
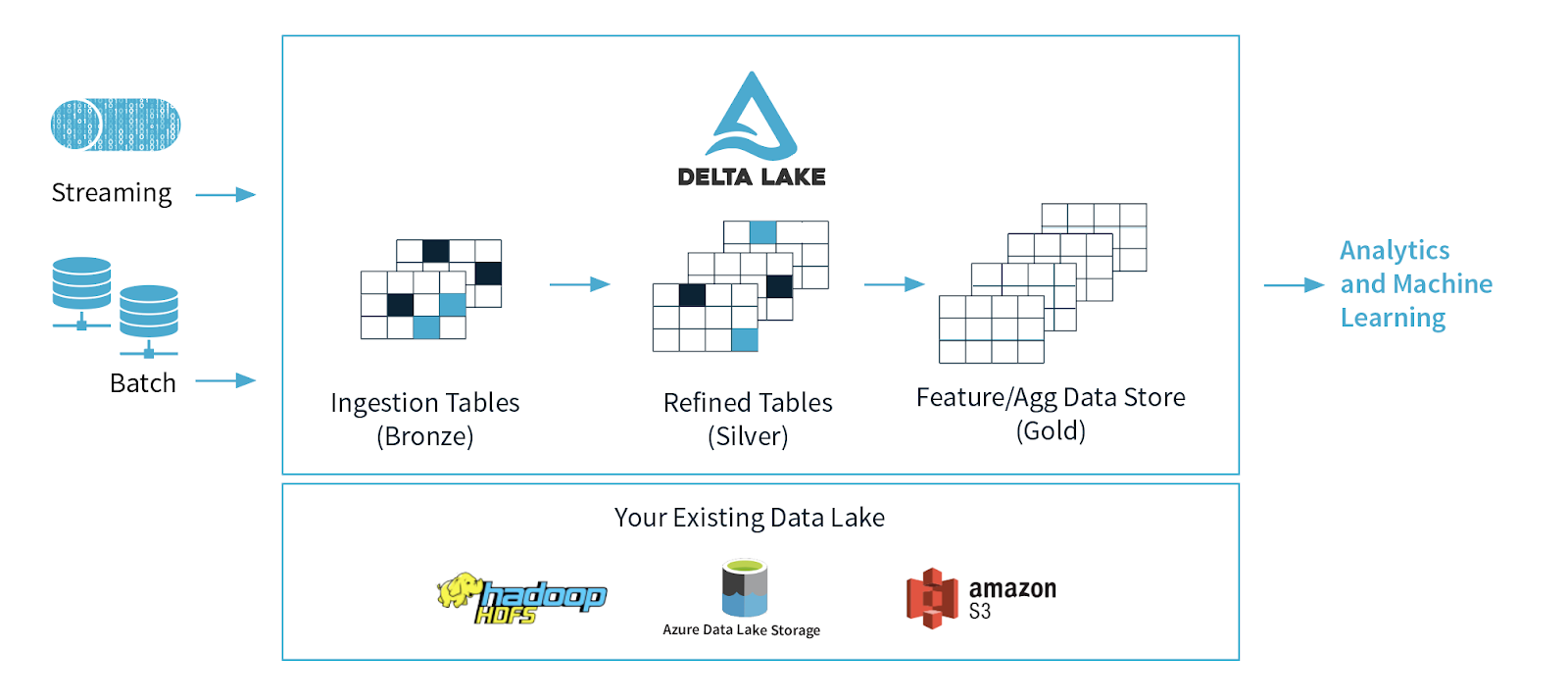
核心组件
- Delta 表(Delta Table):
- Delta 表是 Delta Lake 的基本存储单元,数据以 Parquet 格式存储,并附带事务日志和元数据。
- 每个 Delta 表由多个数据文件和一个事务日志组成,这些文件和日志共同维护数据的一致性和版本信息。
- 事务日志(Transaction Log):
- 事务日志是 Delta Lake 的核心,用于记录对 Delta 表的所有变更操作。
- 事务日志以 JSON 格式存储在 _delta_log 目录中,每个 JSON 文件代表一次事务提交。
- 通过读取事务日志,Delta Lake 可以重建表的当前状态,并支持时间旅行和版本控制。
- 元数据(Metadata):
- 包含表的 schema 信息、分区信息、统计信息等,存储在事务日志中。
- 元数据用于优化查询执行,支持数据跳跃(Data Skipping)和动态分区修剪。
数据操作
- 写操作:
- 所有写操作(如插入、更新、删除)都是通过事务来实现的。写操作会生成新的数据文件,并更新事务日志。
- Delta Lake 使用乐观并发控制机制,允许多个事务并发执行。在提交阶段,如果检测到冲突,会自动进行重试。
- 读操作:
- 读操作通过读取最新的事务日志来获取表的当前状态。
- 支持谓词下推和列剪裁,以提高查询性能。
时间旅行和版本控制
- 时间旅行: 通过事务日志,Delta Lake 支持查询历史版本的数据。这对于数据审计和调试非常有用。
- 版本控制: 每次写操作都会生成一个新的版本,用户可以根据版本号或时间戳来访问特定版本的数据。
高性能查询
- 数据跳跃(Data Skipping): 利用统计信息和索引技术,Delta Lake 可以跳过不相关的数据块,从而加速查询执行。
- 动态分区修剪: 在查询时,自动识别和跳过不相关的分区,提高查询效率。
与 Apache Spark 的集成
- Spark API 支持: Delta Lake 提供了与 Spark 的无缝集成,用户可以使用 Spark SQL、DataFrame 和 Dataset API 来操作 Delta 表。
- 流处理支持: 支持 Spark Structured Streaming,可以在流处理中使用 Delta Lake,实现实时数据分析。
Delta Lake 的架构通过引入事务日志和元数据管理,实现了数据湖的 ACID 事务支持和高效的数据处理能力。其与 Apache Spark 的紧密集成,使得 Delta Lake 能够在大规模数据环境中提供高性能、可靠的数据存储和处理解决方案。企业可以利用 Delta Lake 的这些特性,构建灵活、可扩展的数据湖架构。
Delta Lake 的替代方案
Delta Lake 的出现解决了许多传统数据湖在一致性、性能和管理方面的不足,但在市场上也存在一些替代方案,提供类似或不同的功能。这些替代方案各有优劣,适用于不同的使用场景。
Apache Hudi
Apache Hudi(Hadoop Upserts Deletes and Incrementals)是一个用于大数据平台的数据湖存储层,支持高效的数据更新和删除操作。
核心功能:
- 提供 ACID 事务支持,支持插入、更新、删除和增量数据处理。
- 支持时间旅行查询和数据版本控制。
- 与 Apache Spark 和 Apache Flink 集成,支持批处理和流处理。
使用场景:
- 适用于需要频繁更新数据集的场景,如用户活动日志和订单数据管理。
Apache Iceberg
Apache Iceberg 是一个高性能的表格式,旨在解决大规模数据集的管理和查询问题。
核心功能:
- 提供 ACID 事务支持,支持复杂的数据操作。
- 支持大规模数据集的高效查询和版本控制。
- 与 Apache Spark、Apache Hive 和 Presto 等查询引擎集成良好。
使用场景:
- 适用于需要在大规模数据集上进行复杂查询和管理的场景,如数据仓库和分析平台。
参考链接:


