美国国家标准局1973年开始研究除国防部外的其它部门的计算机系统的数据加密标准,于1973年5月15日和1974年8月27日先后两次向公众发出了征求加密算法的公告。加密算法要达到的目的(通常称为DES密码算法要求)主要为以下四点:
- 提供高质量的数据保护,防止数据未经授权的泄露和未被察觉的修改;
- 具有相当高的复杂性,使得破译的开销超过可能获得的利益,同时又要便于理解和掌握;
- DES密码体制的安全性应该不依赖于算法的保密,其安全性仅以加密密钥的保密为基础;
- 实现经济,运行有效,并且适用于多种完全不同的应用。
1977年1月,美国政府颁布:采纳IBM公司设计的方案作为非机密数据的正式数据加密标准(DES Data Encryption Standard)。
DES全称为Data Encryption Standard,即数据加密标准,是一种使用密钥加密的块算法,1977年被美国联邦政府的国家标准局确定为联邦资料处理标准(FIPS),并授权在非密级政府通信中使用,随后该算法在国际上广泛流传开来。它基于使用56位密钥的对称算法。这个算法因为包含一些机密设计元素,相对短的密钥长度以及怀疑内含美国国家安全局(NSA)的后门而在开始时有争议,DES因此受到了强烈的学院派式的审查,并以此推动了现代的块密码及其密码分析的发展。
DES现在已经不是一种安全的加密方法,主要因为它使用的56位密钥过短。1999年1月,distributed.net与电子前哨基金会合作,在22小时15分钟内即公开破解了一个DES密钥。也有一些分析报告提出了该算法的理论上的弱点,虽然在实际中难以应用。为了提供实用所需的安全性,可以使用DES的派生算法3DES来进行加密,虽然3DES也存在理论上的攻击方法。在2001年,DES作为一个标准已经被高级加密标准(AES)所取代。另外,DES已经不再作为国家标准科技协会(前国家标准局)的一个标准。
对称密码算法
网络安全通信中要用到两类密码算法,一类是对称密码算法,另一类是非对称密码算法。对称密码算法的加密密钥能够从解密密钥中推算出来,反过来也成立。在大多数对称算法中,加密解密密钥是相同的。它要求发送者和接收者在安全通信之前,商定一个密钥。对称算法的安全性依赖于密钥,泄漏密钥就意味着任何人都能对消息进行加密解密。只要通信需要保密,密钥就必须保密。
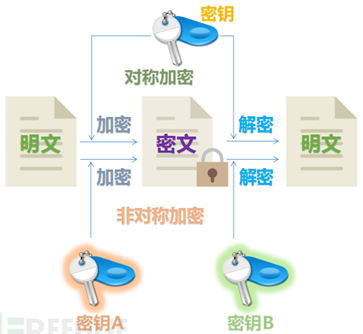
对称算法又可分为两类。一次只对明文中的单个位(有时对字节)运算的算法称为序列算法或序列密码。另一类算法是对明文的一组位进行运算,这些位组称为分组,相应的算法称为分组算法或分组密码。现代计算机密码算法的典型分组长度为64位――这个长度既考虑到分析破译密码的难度,又考虑到使用的方便性。后来,随着破译能力的发展,分组长度又提高到128位或更长。
常用的采用对称密码术的加密方案有5个组成部分:
- 明文:原始信息。
- 加密算法:以密钥为参数,对明文进行多种置换和转换的规则和步骤,变换结果为密文。
- 密钥:加密与解密算法的参数,直接影响对明文进行变换的结果。
- 密文:对明文进行变换的结果。
- 解密算法:加密算法的逆变换,以密文为输入、密钥为参数,变换结果为明文。
对称密码当中有几种常用到的数学运算。这些运算的共同目的就是把被加密的明文数码尽可能深地打乱,从而加大破译的难度。
- 移位和循环移位:移位就是将一段数码按照规定的位数整体性地左移或右移。循环右移就是当右移时,把数码的最后的位移到数码的最前头,循环左移正相反。例如,对十进制数码12345678循环右移1位(十进制位)的结果为81234567,而循环左移1位的结果则为23456781。
- 置换:就是将数码中的某一位的值根据置换表的规定,用另一位代替。它不像移位操作那样整齐有序,看上去杂乱无章。这正是加密所需,被经常应用。
- 扩展:就是将一段数码扩展成比原来位数更长的数码。扩展方法有多种,例如,可以用置换的方法,以扩展置换表来规定扩展后的数码每一位的替代值。
- 压缩:就是将一段数码压缩成比原来位数更短的数码。压缩方法有多种,例如,也可以用置换的方法,以表来规定压缩后的数码每一位的替代值。
- 异或:这是一种二进制布尔代数运算。也可以简单地理解为,参与异或运算的两数位如相等,则结果为0,不等则为1。异或的数学符号为⊕。
- 迭代:迭代就是多次重复相同的运算,这在密码算法中经常使用,以使得形成的密文更加难以破解。
DES算法简介
DES是一种典型的分组密码—一种将固定长度的明文通过一系列复杂的操作变成同样长度的密文的算法。对DES而言,块长度为64位。同时,DES使用密钥来自定义变换过程,因此算法认为只有持有加密所用的密钥的用户才能解密密文。密钥表面上是64位的,然而只有其中的56位被实际用于算法,其余8位可以被用于奇偶校验,并在算法中被丢弃。因此,DES的有效密钥长度仅为56位。
DES设计中使用了分组密码设计的两个原则:混淆(confusion)和扩散(diffusion),其目的是抗击敌手对密码系统的统计分析。混淆是使密文的统计特性与密钥的取值之间的关系尽可能复杂化,以使密钥和明文以及密文之间的依赖性对密码分析者来说是无法利用的。扩散的作用就是将每一位明文的影响尽可能迅速地作用到较多的输出密文位中,以便在大量的密文中消除明文的统计结构,并且使每一位密钥的影响尽可能迅速地扩展到较多的密文位中,以防对密钥进行逐段破译。
DES加密的算法框架如下:
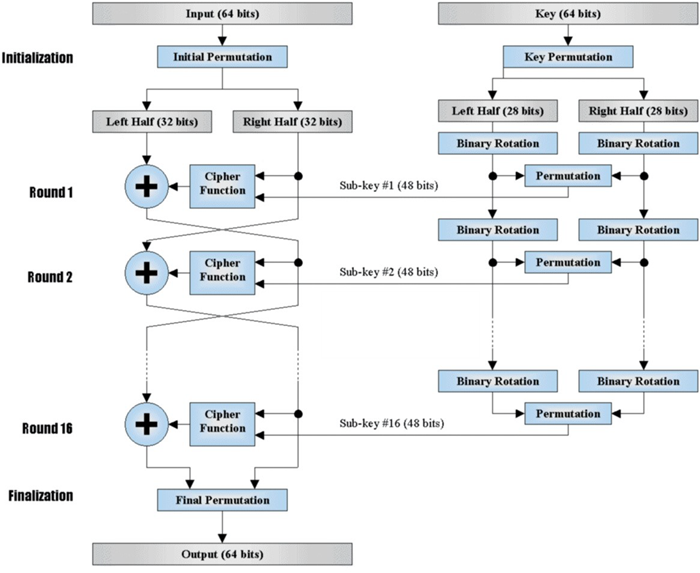
- 首先要生成一套加密密钥,从用户处取得一个64位长的密码口令,然后通过等分、移位、选取和迭代形成一套16个加密密钥,分别供每一轮运算中使用。
- DES对64位(bit)的明文分组M进行操作,M经过一个初始置换IP,置换成m0。将m0明文分成左半部分和右半部分m0=(L0,R0),各32位长。然后进行16轮完全相同的运算(迭代),这些运算被称为函数f,在每一轮运算过程中数据与相应的密钥结合。
- 在每一轮中,密钥位移位,然后再从密钥的56位中选出48位。通过一个扩展置换将数据的右半部分扩展成48位,并通过一个异或操作替代成新的48位数据,再将其压缩置换成32位。这四步运算构成了函数f。然后,通过另一个异或运算,函数f的输出与左半部分结合,其结果成为新的右半部分,原来的右半部分成为新的左半部分。将该操作重复16次。
- 经过16轮迭代后,左,右半部分合在一起经过一个末置换(数据整理),这样就完成了加密过程。
分组加密中的工作模式
分组加密算法是按分组大小来进行加解密操作的,如DES算法的分组是64位,而AES是128位,但实际明文的长度一般要远大于分组大小,这样的情况如何处理呢?这正是”mode of operation”即工作模式要解决的问题:明文数据流怎样按分组大小切分,数据不对齐的情况怎么处理等等。早在1981年,DES算法公布之后,NIST在标准文献FIPS81中公布了4种工作模式:
- 电子密码本:Electronic CodeBook Mode (ECB)
- 密码分组链接:Cipher Block Chaining Mode (CBC)
- 密文反馈:Cipher Feedback Mode (CFB)
- 输出反馈:Output Feedback Mode (OFB)
2001年又针对AES加入了新的工作模式:
- 计数器模式:Counter Mode (CTR)
后来又陆续引入其它新的工作模式。在此仅介绍几种常用的:
ECB:电子密码本模式(electronic codebook mode)
ECB模式只是将明文按分组大小切分,然后用同样的密钥正常加密切分好的明文分组。
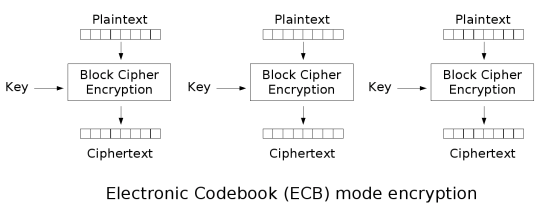 ECB的理想应用场景是短数据(如加密密钥)的加密。此模式的问题是无法隐藏原明文数据的模式,因为同样的明文分组加密得到的密文也是一样的。举例来说明:
ECB的理想应用场景是短数据(如加密密钥)的加密。此模式的问题是无法隐藏原明文数据的模式,因为同样的明文分组加密得到的密文也是一样的。举例来说明:

从ECB的工作原理可以看出,如果明文数据在等分后,两块数据相同则会产生相同的加密数据块,这会辅助攻击者快速判断加密算法的工作模式,而将攻击资源聚集在破解某一块数据即可,一旦成功则意味着全文破解,大大提升了攻击效率。为了解决这一缺陷,设计者提出了更多的分组密码工作模式,这些模式下各组数据的加密过程彼此产生关联,尽最大可能混淆数据。
CBC:密码分组链接模式(cipher block chaining Triple)
此模式是1976年由IBM所发明,引入了IV(初始化向量:Initialization Vector)的概念。IV是长度为分组大小的一组随机,通常情况下不用保密,不过在大多数情况下,针对同一密钥不应多次使用同一组IV。CBC要求第一个分组的明文在加密运算前先与IV进行异或;从第二组开始,所有的明文先与前一分组加密后的密文进行异或。(原理有没有和区块链(blockchain)一致,可以算是区块链的鼻祖)
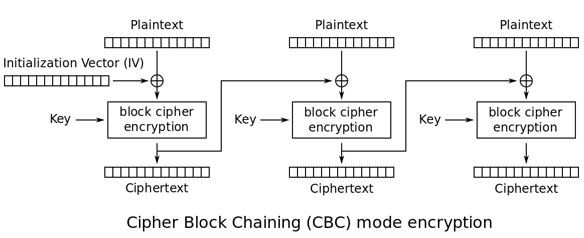
CBC模式相比ECB实现了更好的模式隐藏,但因为其将密文引入运算,加解密操作无法并行操作。同时引入的IV向量,还需要加、解密双方共同知晓方可。
CFB:密文反馈模式(Cipher FeedBack)
与CBC模式类似,但不同的地方在于,CFB模式先生成密码流字典,然后用密码字典与明文进行异或操作并最终生成密文。后一分组的密码字典的生成需要前一分组的密文参与运算。
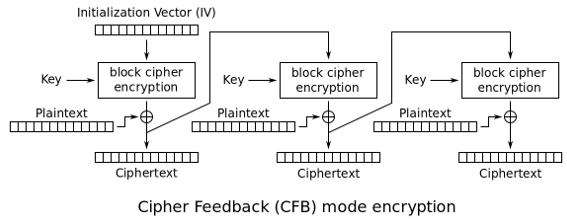
CFB模式是用分组算法实现流算法,明文数据不需要按分组大小对齐。
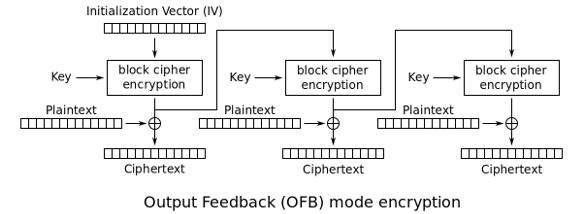
OFB:输出反馈模式(Output Feedbaek)
OFB模式与CFB模式不同的地方是:生成字典的时候会采用明文参与运算,CFB采用的是密文。
CTR:计数器模式(counter mode)
上面的几种工作模式都存在一个共性:数据块彼此之间关联,当前块的解密依赖前面的密文块,因此不能随机访问任意加密块。这样会使得用户为了获取其中一点数据而不得不解密所有数据,当数据量大时效率较低。
CTR模式同样会产生流密码字典,但同是会引入一个计数,以保证任意长时间均不会产生重复输出。
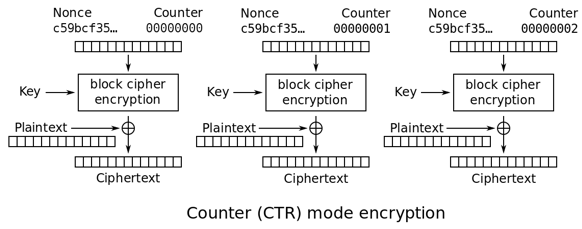
CTR模式只需要实现加密算法以生成字典,明文数据与之异或后得到密文,反之便是解密过程。CTR模式可以采用并行算法处理以提升吞量,另外加密数据块的访问可以是随机的,与前后上下文无关。
CCM:Counter with CBC-MAC
CCM模式,全称是Counter with Cipher Block Chaining-Message Authentication Code,是CTR工作模式和CMAC认证算法的组合体,可以同时数据加密和鉴别服务。
明文数据通过CTR模式加密成密文,然后在密文后面再附加上认证数据,所以最终的密文会比明文要长。具体的加密流程如下描述:先对明文数据认证并产生一个tag,在后续加密过程中使用此tag和IV生成校验值U。然后用CTR模式来加密原输入明文数据,在密文的后面附上校验码U。
GCM:伽罗瓦计数器模式
类型CCM模式,GCM模式是CTR和GHASH的组合,GHASH操作定义为密文结果与密钥以及消息长度在GF(2^128)域上相乘。GCM比CCM的优势是在于更高并行度及更好的性能。TLS1.2标准使用的就是AES-GCM算法,并且Intel CPU提供了GHASH的硬件加速功能补充信息
与分组密码相对应的便是序列密码,又称流密码,是指利用密钥通过复杂的密码算法产生大量的伪随机位流,对明文数据流进行加密。在进行解密时,用同样的密钥和算法产生相同的伪随机位流,用以还原明文数据流。目前,公开的序列密码算法主要有RC4、SEAL等。序列密码以一个元素(一个字母或一个比特)作为基本的处理单元,具有转换速度快、低错误传播的优点,硬件实现简单;但加密结果混淆度低、且数据的小幅度变化敏感性低,即插入修改较少的数据,加密结果不会发生大幅变化,这样会给攻击者提供较多分析素材。
总结
ECB是不推荐的方式,Key相同时,相同的明文在不同的时候产生相同的明文,容易遭到字典攻击,CBC由于加入了向量参数,一定程度上抵御了字典工具,但缺点也随之而来,一旦中间一个数据出错或丢失,后面的数据将受到影响,CFB与CBC类似,好处是明文和密文不用是8bit的整数倍,中间一个数据出错,只影响后面的几个块的数据,OFB比CFB方式,一旦一个数据出错,不会影响后面的数据,但安全性降低;因此,推荐使用CFB方式,但每个数据包单独加密,否则一个数据包丢失,需要做很多容错处理;当然,具体问题也要具体分析,对于只需要“特定安全性”,不需要“计算安全性”以上的软件,也可以使用ECB模式,与其它块密码相似,DES自身并不是加密的实用手段,而必须以某种工作模式进行实际操作。
参考链接:
分组加密中的填充算法
在分组加密算法中(例如DES),我们首先要将原文进行分组,然后每个分组进行加密,然后组装密文。其中有一步是分组。如何分组?假设我们现在的数据长度是24字节,BlockSize是8字节,那么很容易分成3组,一组8字节,如果现有的待加密数据不是BlockSize的整数倍,那该如何分组?
例如,有一个17字节的数据,BlockSize是8字节,怎么分组?我们可以对原文进行填充(padding),将其填充到8字节的整数倍。假设使用PKCS#5进行填充(以下都是以PKCS#5为示例),BlockSize是8字节(64bit):
待加密数据原长度为1字节:0x41 填充后:0x41 0x07 0x07 0x07 0x07 0x07 0x07 0x07 待加密数据原长度为2字节:0x41 0x41 填充后:0x41 0x41 0x06 0x06 0x06 0x06 0x06 0x06 待加密数据原长度为3字节:0x41 0x41 0x41 填充后:0x41 0x41 0x41 0x05 0x05 0x05 0x05 0x05 待加密数据原长度为4字节:0x41 0x41 0x41 0x41 填充后:0x41 0x41 0x41 0x41 0x04 0x04 0x04 0x04 待加密数据原长度为5字节:0x41 0x41 0x41 0x41 0x41 填充后:0x41 0x41 0x41 0x41 0x41 0x03 0x03 0x03 待加密数据原长度为6字节:0x41 0x41 0x41 0x41 0x41 0x41 填充后:0x41 0x41 0x41 0x41 0x41 0x41 0x02 0x02 待加密数据原长度为7字节:0x41 0x41 0x41 0x41 0x41 0x41 0x41 填充后:0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x01 待加密数据原长度为8字节:0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41 填充后:0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x41 0x08 0x08 0x08 0x08 0x08 0x08 0x08 0x08
为啥当为整数倍时,还是要多增加8个0x08?假设当x是8的整数倍时,不多填充8个0x08:当解密后时,我看到了解密后的数据的末尾的最后一个字节,这个字节恰好是0x01,那你说,这个字节是填充上去的呢?还是实际的数据呢?
PKCS5Padding 与PKCS7Padding的区别
PKCS5Padding与PKCS7Padding基本上是可以通用的。在PKCS5Padding中,明确定义Block的大小是8位,而在PKCS7Padding定义中,对于块的大小是不确定的,可以在1-255之间,填充值的算法都是一样的:
pad = k - (l mod k) //k=块大小,l=数据长度,如果k=8,l=9,则需要填充额外的7个byte的7
可以得出:Pkcs5是Pkcs7的特例(Block的大小始终是8位)。当Block的大小始终是8位的时候,Pkcs5和Pkcs7是一样的。
DES与3DES
3DES(即TripleDES)是DES向AES过渡的加密算法,它使用3条56位的密钥对数据进行三次加密。是DES的一个更安全的变形。它以DES为基本模块,通过组合分组方法设计出分组加密算法。比起最初的DES,3DES更为安全。
该方法使用两个密钥,执行三次DES算法,加密的过程是加密-解密-加密,解密的过程是解密-加密-解密。
- 3DES加密过程为:C = Ek3(Dk2(Ek1(P)))
- 3DES解密过程为:P = Dk1(EK2(Dk3(C)))
采用两个密钥进行三重加密的好处有:
- 两个密钥合起来有效密钥长度有112bit,可以满足商业应用的需要,若采用总长为168bit的三个密钥,会产生不必要的开销。
- 加密时采用加密-解密-加密,而不是加密-加密-加密的形式,这样有效的实现了与现有DES系统的向后兼容问题。因为当K1=K2时,三重DES的效果就和原来的DES一样,有助于逐渐推广三重DES。
- 三重DES具有足够的安全性,目前还没有关于攻破3DES的报道。
使用pyCrypto进行DES加密解密
# -*- coding: utf-8 -*-
import base64
from Crypto.Cipher import DES3
from Crypto import Random
class AESCipher:
def __init__(self, key):
self.key = key
def encrypt(self, raw):
iv = Random.new().read(8)
# iv = ['\x01','\x02','\x03','\x04','\x05','\x06','\x07','\x08']
cipher = DES3.new(self.key, DES3.MODE_CFB, iv)
return base64.b64encode(iv + cipher.encrypt(raw))
def decrypt(self, enc):
enc = base64.b64decode(enc)
iv = enc[:8]
cipher = DES3.new(self.key, DES3.MODE_CFB, iv)
return cipher.decrypt(enc[8:])
if __name__ == "__main__":
import os
key = os.urandom(16)
text = 'tobeencrypted'
cipher = AESCipher(key)
encrypted = cipher.encrypt(text)
print(encrypted.hex())
decrypted = cipher.decrypt(encrypted)
print(decrypted.decode("utf-8"))
参考文档:


