Kubeflow简介
Kubeflow是一个开源的机器学习平台,旨在简化在Kubernetes上部署、管理和扩展机器学习工作流的过程。它提供了一整套工具和组件,帮助数据科学家和工程师从数据准备、模型训练到部署和监控,构建完整的机器学习管道。
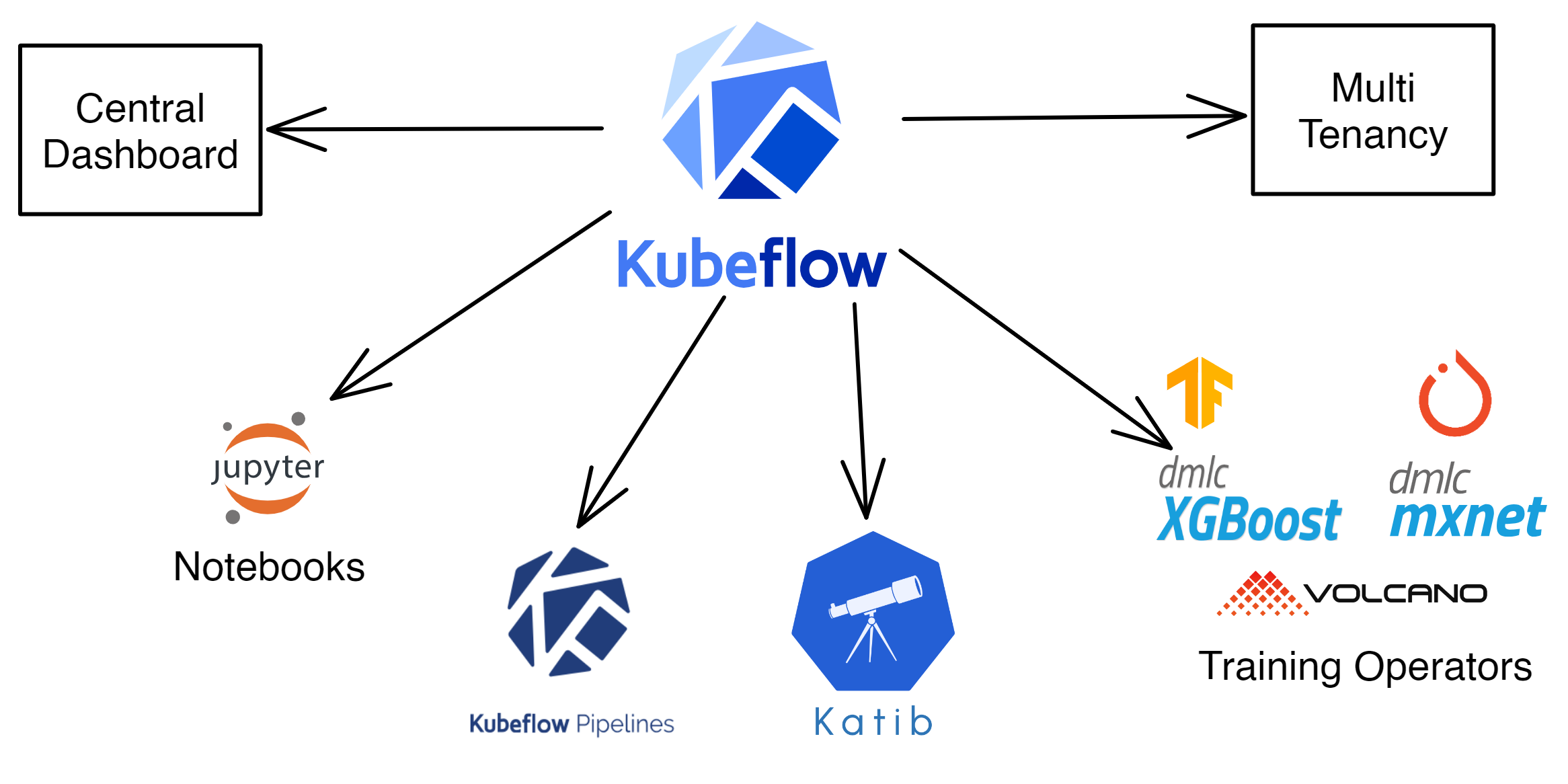
核心组件
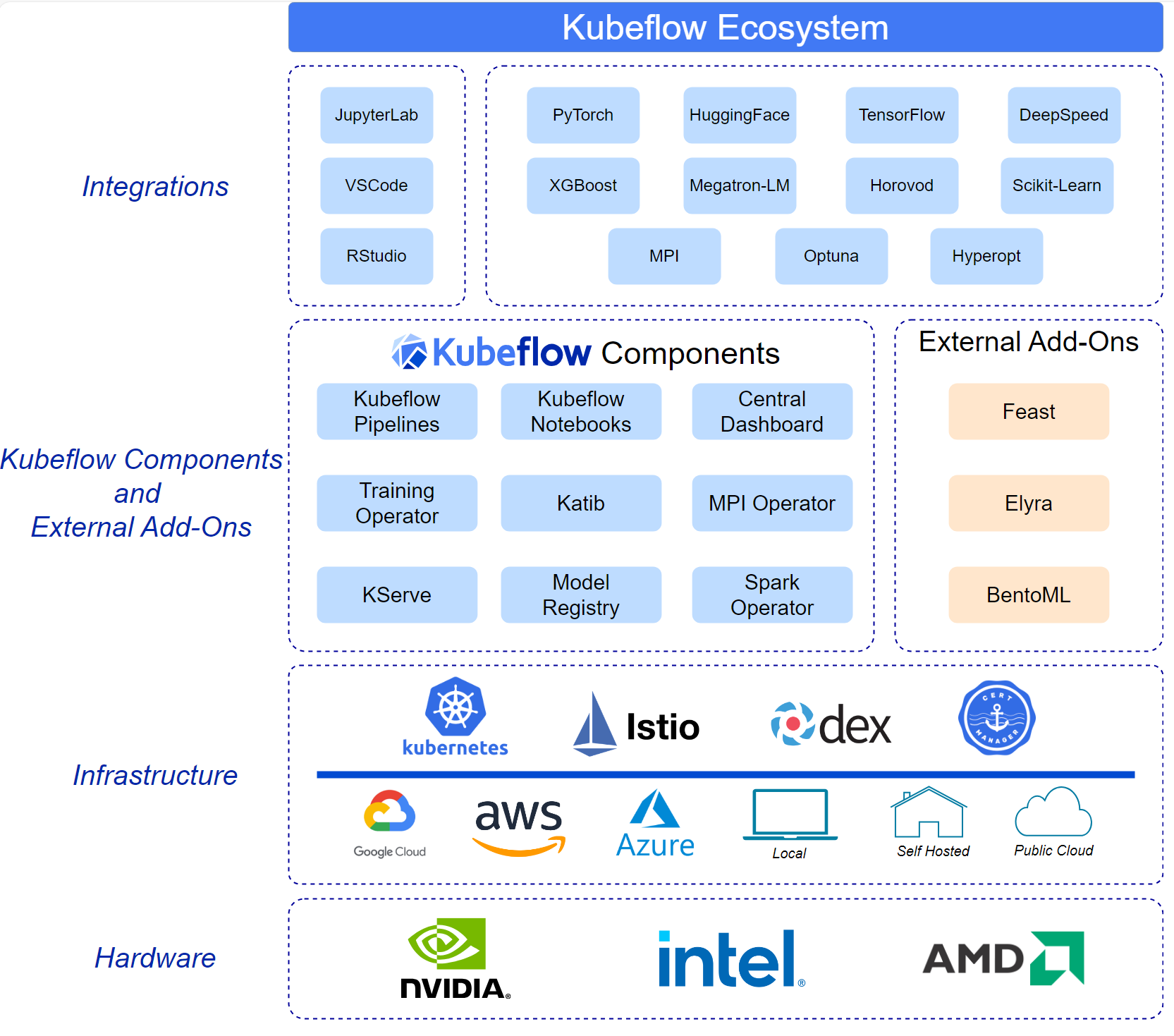
- Kubernetes:Kubeflow构建在Kubernetes之上,利用Kubernetes的容器编排能力来管理机器学习工作流的资源和调度。
- Jupyter Notebooks:提供集成的JupyterHub环境,允许用户在Kubernetes上创建和管理Jupyter Notebooks实例,支持交互式数据科学和模型开发。
- Kubeflow Pipelines:用于构建、部署和管理端到端机器学习工作流。支持工作流的可视化、参数化和版本控制。
- TFJob:支持在Kubernetes上运行分布式TensorFlow训练作业,允许用户定义和管理大规模的模型训练。
- Katib:一个自动化超参数调优系统,支持多种优化算法,帮助用户优化模型性能。
- KFServing:提供了一种标准化的方式来部署和管理机器学习模型的推理服务,支持多种框架(如TensorFlow、PyTorch、XGBoost)。
- Argo Workflows:用于定义和管理复杂的工作流,支持并行和有条件的任务执行。
功能特点
- 可扩展性:通过Kubernetes的自动扩展和资源管理能力,Kubeflow可以根据工作负载需求动态分配计算资源。
- 可移植性:支持在不同的Kubernetes环境中运行,包括本地集群、云服务(如GKE、EKS)等。
- 可重复性:通过Kubeflow Pipelines和版本控制,确保工作流的可重复性和可审计性。
- 多框架支持:除了TensorFlow,Kubeflow还支持其他流行的机器学习框架,如PyTorch、MXNet、XGBoost等。
- 社区支持:Kubeflow拥有活跃的开源社区,定期更新和扩展其功能集。
使用案例
- 机器学习模型训练:在Kubernetes上运行大规模分布式训练作业,支持自动化超参数调优和模型版本管理。
- 模型部署与推理:使用KFServing部署高效的在线推理服务,支持自动扩展和滚动更新。
- 数据科学协作:通过JupyterHub和Kubeflow Pipelines,团队可以协作开发和共享机器学习工作流。
Kubeflow的使用
使用Kubeflow来管理和部署机器学习工作流包括几个关键步骤,从安装和配置到构建、训练、部署模型,再到监控和优化。以下是使用Kubeflow的基本指南:
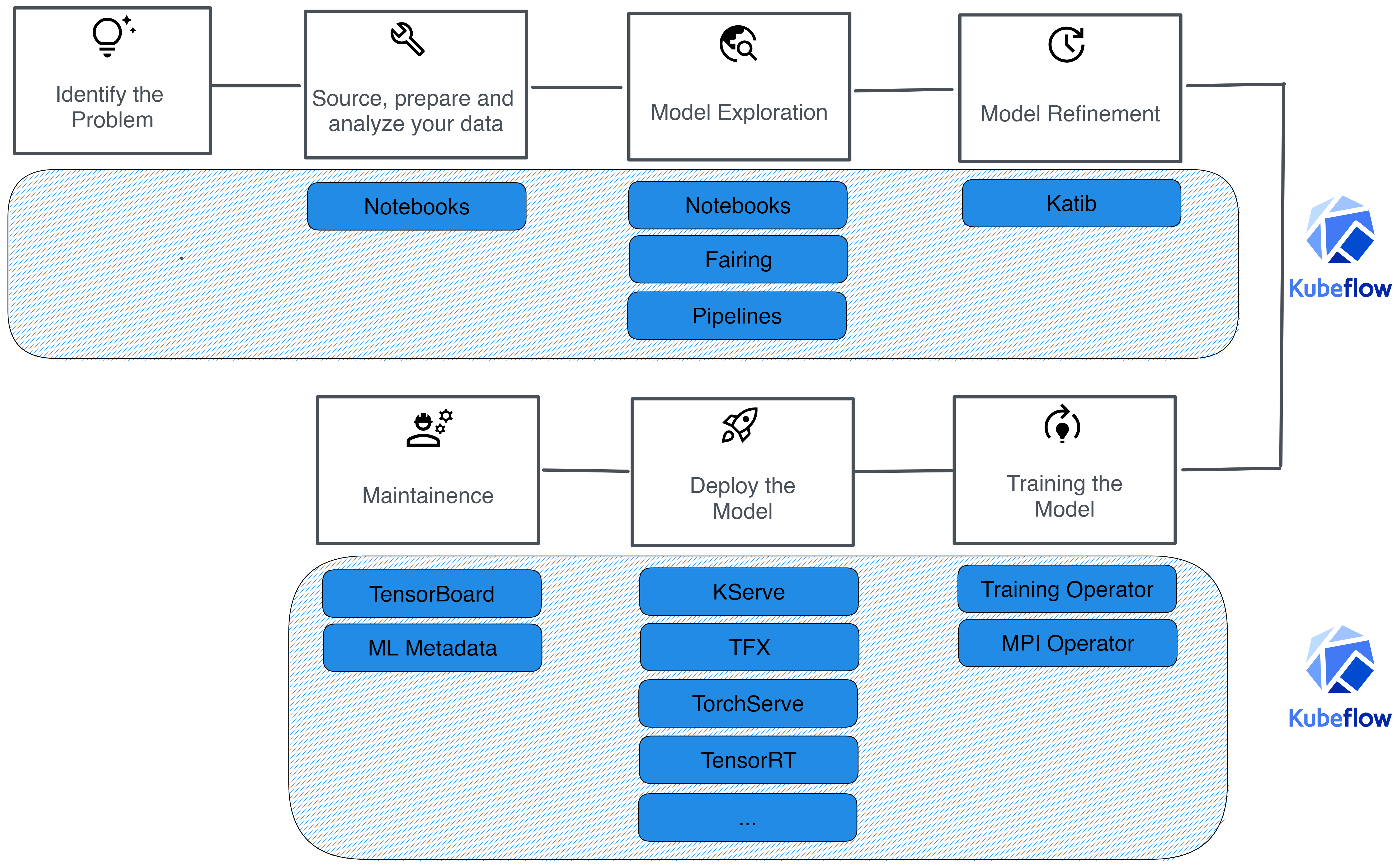
Kubeflow运行在Kubernetes之上,因此首先需要一个Kubernetes集群。可以使用Minikube、MicroK8s或在云上(如Google Kubernetes Engine, Amazon EKS, Azure AKS)创建一个集群。
安装Kubernetes集群
Minikube(适合本地测试):
minikube start --cpus=4 --memory=8192 --disk-size=30g
云端Kubernetes集群:根据各云服务商的文档创建。
安装Kubeflow
使用kfctl工具安装
下载kfctl:根据操作系统下载对应的 kfctl 二进制文件,并将其添加到 PATH。
设置环境变量:
export KF_NAME=my-kubeflow
export BASE_DIR=/path/to/your/directory
export KF_DIR=${BASE_DIR}/${KF_NAME}
export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/master/kfdef/kfctl_k8s_istio.v1.2.0.yaml"
mkdir -p ${KF_DIR}
cd ${KF_DIR}
安装Kubeflow,使用kfctl安装Kubeflow:
kfctl apply -V -f ${CONFIG_URI}
验证安装,检查所有组件是否正常运行:
bash复制代码
kubectl get pods -n kubeflow
使用Jupyter Notebooks
- 访问Kubeflow Dashboard:通常通过浏览器访问Kubeflow Dashboard,可以通过Kubernetes的端口转发或负载均衡器获取访问地址。
- 创建Jupyter Notebook实例:在Dashboard中,导航到Jupyter Notebooks,创建一个新的实例以进行数据探索和模型开发。
构建和运行Kubeflow Pipelines
- 使用Kubeflow Pipelines UI:
- 在Dashboard中,访问Pipelines部分。
- 创建一个新的Pipeline,上传定义好的工作流YAML文件或使用现有的示例。
- 定义Pipeline:
- 使用Python SDK定义Pipeline,示例:
from kfp import dsl
@dsl.pipeline(
name='My Pipeline',
description='An example pipeline.'
)
def my_pipeline():
step1 = dsl.ContainerOp(
name='Step1',
image='python:3.7',
command=['python', '-c'],
arguments=['print("Hello Kubeflow")']
)
提交Pipeline运行:在UI中,选择Pipeline,提交运行并监控其状态。
模型部署和服务
使用KFServing,创建一个InferenceService资源,定义模型的推理服务。
apiVersion: "serving.kubeflow.org/v1beta1"
kind: "InferenceService"
metadata:
name: "my-model"
namespace: "kubeflow"
spec:
predictor:
tensorflow:
storageUri: "gs://my-bucket/my-model"
部署模型,使用 kubectl 命令应用配置:
kubectl apply -f my-model.yaml
访问模型服务:获取模型服务的URL,通过HTTP请求进行推理。
监控和优化
- 监控运行状态:使用Kubeflow Dashboard查看工作流的执行状态、日志和结果。
- 调优模型:使用Katib进行自动化超参数调优,定义实验并运行。
Kubeflow vs Metaflow
Kubeflow和Metaflow都是用于构建和管理机器学习工作流的框架,但它们的设计理念、使用场景和功能侧重点有所不同。以下是对这两个框架的对比分析:
| 特性/维度 | Kubeflow | Metaflow |
| 基础架构 | 基于Kubernetes,适用于容器化和云环境 | 主要为本地和AWS云环境设计 |
| 部署要求 | 需要Kubernetes集群 | 支持本地运行,AWS上可扩展 |
| 扩展性 | 利用Kubernetes的自动扩展和资源管理 | 通过AWS Batch在云端扩展 |
| 用户界面 | 丰富的Web UI(Kubeflow Dashboard) | 命令行工具和AWS上的Web UI |
| 学习曲线 | 对Kubernetes不熟悉的用户可能较陡峭 | 对Python用户较为友好,入门简单 |
| 组件化 | 丰富的组件,如Pipelines、Katib、KFServing | 集成AWS服务,专注于数据存储和版本控制 |
| 框架支持 | 支持多种框架(TensorFlow、PyTorch等) | 框架支持不如Kubeflow广泛 |
| 自动化 | 强调工作流的自动化和可移植性 | 提供简单的API,专注于快速迭代 |
| 适用场景 | 适合需要Kubernetes环境的复杂工作流 | 适合快速开发和实验,尤其是AWS用户 |
| 社区支持 | 活跃的开源社区,定期更新和扩展功能 | 由Netflix开发,AWS上有良好支持 |
总结
- Kubeflow适合已经在使用Kubernetes的组织,特别是需要在云端大规模部署和管理机器学习工作流的企业。它的组件化设计和丰富的功能适合构建复杂的机器学习管道。
- Metaflow更适合需要快速迭代和实验的团队,特别是那些已经在利用AWS资源的团队。其易用性和对数据存储的良好支持使其成为快速开发的好选择。
参考链接:


