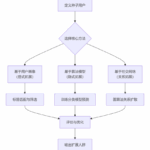
QQ作为中国用户基数最大的即时通讯软件,其背后的通讯协议体系是一个融合了网络编程、数据加密、分布式系统等多种技术的复杂工程。本文将基于公开的技术资料与分析,系统性地剖析QQ协议的核心设计、通信机制、安全…
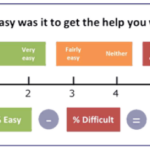
客户费力度(CES)是一个直接衡量客户在与企业互动过程中所付出努力程度的指标,其核心理念在于:客户体验越轻松,他们的满意度和忠诚度往往越高 。 CES 的核心概念与价值 CES 的核心是“减少客户的努力”,强调让…
为什么做比怎么做更重要 为什么做比怎么做更重要。这句话是用户画像项目成败的分水岭。它强调的是一个根本性的思维转变:从“技术驱动”的“我们能做什么”转向“业务驱动”的“我们需要解决什么问题”。 层面一:场…
最近重读腾讯创始人Tony的一篇内部分享,文中关于两家茶餐厅的比喻让我沉思良久。在这个追求增长、追逐流量的时代,"克制"这个看似保守的词,或许正蕴含着产品人最需要的大智慧。 一个发人深省的对比 第…

在纷繁复杂的产品世界中,我们常看到类似的现象:为何网易云音乐的“乐评专列”能引爆社交网络,而其他品牌的UGC广告却反响平平?为何投入巨大的公众号运营,最终只换来惨淡的转化?其根本原因,在于主导产品、营销、…

什么是欺骗性设计模式? 欺骗性设计模式,也被称为“暗黑模式”,是指在网站和应用程序的界面设计中,被用来诱导用户做出非本意行为的花招或陷阱。其核心在于设计并非为了帮助用户,而是为了操纵用户,服务于企业自…
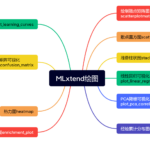
Mlxtend 简介 Mlxtend 是一个Python开源库,全称为 “machine learning extensions”(机器学习扩展)。由 Sebastian Raschka 创建并维护,其核心目标是提供一系列在日常数据科学和机器学习任务中非常实用的工具和扩…
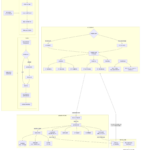
技术背景与挑战 技术背景深度解析 小程序运行环境特殊性 微信小程序基于独特的"双线程"架构运行,这一设计对其网络通信能力产生了根本性影响: 视图层与逻辑层分离: 视图层(WebView)负责页面渲染…

什么是 PU Learning? PU Learning 的全称是 Positive-Unlabeled Learning,即正例-无标记学习。它是一种在半监督学习范畴内的特殊机器学习设定。 与传统的监督学习(数据有明确的“正例”和“负例”标签)不同…
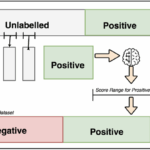
Lookalike简介 Lookalike(相似人群扩展)是一项用于在庞大用户群中寻找与特定“种子用户”相似的新用户的技术。它广泛应用于广告、推荐系统等领域,其核心逻辑可以概括为以下几个步骤: 核心方法解析 Lookali…