在 Pandas 中,DataFrame.head() 方法默认输出一个格式化的表格,这在 Jupyter Notebook 或终端中查看时通常已经比较可读。但是,如果你希望以更好的文本格式输出,尤其是在需要将输出嵌入到其他文档或日志中时,
需要通过其他方法来提升可读性。
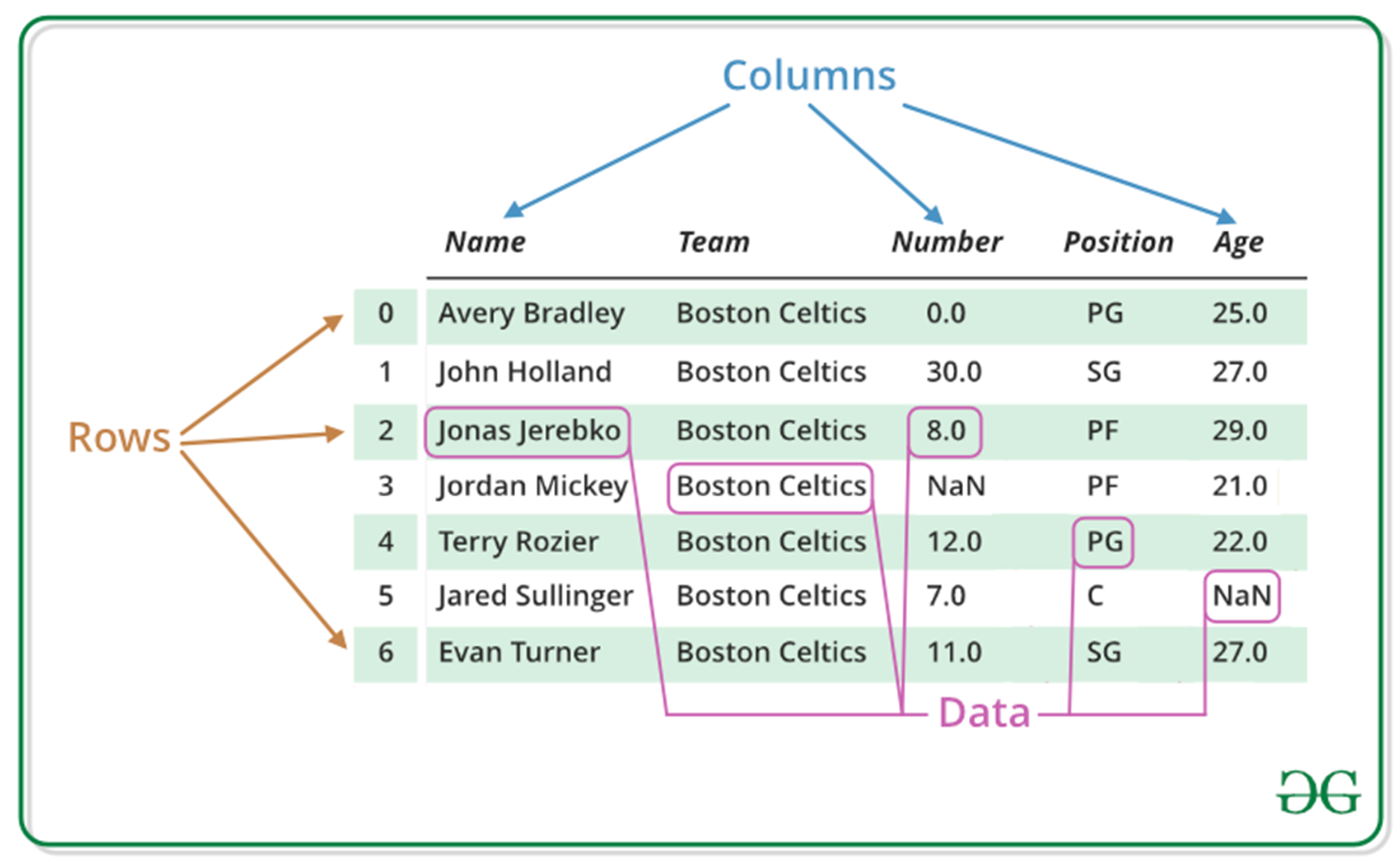
Pandas Dataframe转化为文本输出
使用 to_string 方法
Pandas 的 to_string() 方法可以将 DataFrame 转换为一个格式化的字符串,这样你可以更好地控制输出格式。
import pandas as pd
# 创建一个示例 DataFrame
data = {
'姓名': ['张三', '李四', '王五', '二狗子', '王二麻子'],
'年龄': [24, 19, 22, 32, 44],
'科目': ['语文', '数学', '英语', '物理', '化学'],
'分数': [88, 92, 85, 95, 88]
}
df = pd.DataFrame(data)
# 使用 to_string() 方法
output = df.head().to_string(index=False)
print(output)
输出内容为:
姓名 年龄 科目 分数 张三 24 语文 88 李四 19 数学 92 王五 22 英语 85 二狗子 32 物理 95 王二麻子 44 化学 88
使用csv 格式
如果你希望以 CSV 格式输出,可以使用 to_csv 方法并指定 index=False 以去除索引:
output = df.head().to_csv(index=False) print(output)
输出内容:
姓名,年龄,科目,分数 张三,24,语文,88 李四,19,数学,92 王五,22,英语,85 二狗子,32,物理,95 王二麻子,44,化学,88
使用 .to_markdown() 方法
Pandas 提供了一种简单的方法将 DataFrame 转换为 Markdown 格式,这可以帮助你在 Markdown 文档中嵌入表格。可以使用 to_markdown() 方法来实现这一点。这个方法在 Pandas 1.0.0 及以上版本中可用。
# 将 DataFrame 转换为 Markdown 格式 markdown_output = df.to_markdown(index=False) print(markdown_output)
输出内容为:
| 姓名 | 年龄 | 科目 | 分数 | |:---------|-------:|:-------|-------:| | 张三 | 24 | 语文 | 88 | | 李四 | 19 | 数学 | 92 | | 王五 | 22 | 英语 | 85 | | 二狗子 | 32 | 物理 | 95 | | 王二麻子 | 44 | 化学 | 88 |
备注:
- to_markdown() 方法依赖于 tabulate 库。如果你还没有安装这个库,可以通过以下命令进行安装:pip install tabulate
- to_markdown() 方法支持多个参数,比如控制是否显示索引、列对齐方式等。可以根据需要调整这些参数。
to_markdown() 的参数
- buf:默认值为 None。指定输出的目标。如果为 None,则返回结果字符串;如果为文件对象或类似对象,则将结果写入该对象。
- mode:默认值为 ‘wt’。指定写入模式,仅在 buf 不是 None 时有意义。
- index:默认值为 True。是否包括 DataFrame 的索引列。
- headers:默认值为 ‘keys’。指定列名的来源。可以是 ‘keys’(使用列标签)或 list(自定义列标签)。
- tablefmt:默认值为 ‘pipe’。指定表格格式。在 Markdown 中常用的格式是 ‘pipe’,但也可以使用其他由 tabulate 库支持的格式。
- showindex:默认值为 ‘default’。控制是否显示索引。可以是 True、False 或 ‘default’。
- numalign:默认值为 ‘right’。指定数字的对齐方式,可以是 ‘right’、’center’ 或 ‘left’。
- stralign:默认值为 ‘left’。指定字符串的对齐方式,可以是 ‘right’、’center’ 或 ‘left’。
- missingval:默认值为 ”。指定缺失值的表示形式。
- floatfmt:默认值为 ‘g’。指定浮点数的格式。可以是格式字符串或格式字符串列表。
使用 tabulate 库
tabulate 是一个 Python 库,用于将表格数据格式化为多种文本格式。它非常适合用于将数据打印到控制台或嵌入到文本文件中。tabulate 支持多种输出格式,将 DataFrame 格式化为不同风格的表格(如 plain, grid, pipe, etc.)。
from tabulate import tabulate # 将 DataFrame 转换为表格格式 output = tabulate(df.head(), headers='keys', tablefmt='grid') print(output)
输出内容为:
+----+----------+--------+--------+--------+ | | 姓名 | 年龄 | 科目 | 分数 | +====+==========+========+========+========+ | 0 | 张三 | 24 | 语文 | 88 | +----+----------+--------+--------+--------+ | 1 | 李四 | 19 | 数学 | 92 | +----+----------+--------+--------+--------+ | 2 | 王五 | 22 | 英语 | 85 | +----+----------+--------+--------+--------+ | 3 | 二狗子 | 32 | 物理 | 95 | +----+----------+--------+--------+--------+ | 4 | 王二麻子 | 44 | 化学 | 88 | +----+----------+--------+--------+--------+
输出格式
tabulate 支持多种输出格式,通过 tablefmt 参数指定。常用的格式包括:
- ‘plain’:简单的无边框格式。
- ‘grid’:带有网格线的格式。
- ‘pipe’:Markdown 风格的格式。
- ‘html’:HTML 表格。
- ‘latex’:LaTeX 表格。
- ‘simple’:简化的表格格式。
- ‘github’:GitHub 风格的 Markdown 表格。
输出示例:
#'plain':
姓名 年龄 科目 分数
0 张三 24 语文 88
1 李四 19 数学 92
2 王五 22 英语 85
3 二狗子 32 物理 95
4 王二麻子 44 化学 88
#'grid':
+----+----------+--------+--------+--------+
| | 姓名 | 年龄 | 科目 | 分数 |
+====+==========+========+========+========+
| 0 | 张三 | 24 | 语文 | 88 |
+----+----------+--------+--------+--------+
| 1 | 李四 | 19 | 数学 | 92 |
+----+----------+--------+--------+--------+
| 2 | 王五 | 22 | 英语 | 85 |
+----+----------+--------+--------+--------+
| 3 | 二狗子 | 32 | 物理 | 95 |
+----+----------+--------+--------+--------+
| 4 | 王二麻子 | 44 | 化学 | 88 |
+----+----------+--------+--------+--------+
#'pipe':
| | 姓名 | 年龄 | 科目 | 分数 |
|---:|:---------|-------:|:-------|-------:|
| 0 | 张三 | 24 | 语文 | 88 |
| 1 | 李四 | 19 | 数学 | 92 |
| 2 | 王五 | 22 | 英语 | 85 |
| 3 | 二狗子 | 32 | 物理 | 95 |
| 4 | 王二麻子 | 44 | 化学 | 88 |
#'html':
<table>
<thead>
<tr><th style="text-align:right;"></th><th>姓名</th><th style="text-align:right;">年龄</th><th>科目</th><th style="text-align:right;">分数</th></tr>
</thead>
<tbody>
<tr><td style="text-align:right;">0</td><td>张三</td><td style="text-align:right;">24</td><td>语文</td><td style="text-align:right;">88</td></tr>
<tr><td style="text-align:right;">1</td><td>李四</td><td style="text-align:right;">19</td><td>数学</td><td style="text-align:right;">92</td></tr>
<tr><td style="text-align:right;">2</td><td>王五</td><td style="text-align:right;">22</td><td>英语</td><td style="text-align:right;">85</td></tr>
<tr><td style="text-align:right;">3</td><td>二狗子</td><td style="text-align:right;">32</td><td>物理</td><td style="text-align:right;">95</td></tr>
<tr><td style="text-align:right;">4</td><td>王二麻子</td><td style="text-align:right;">44</td><td>化学</td><td style="text-align:right;">88</td></tr>
</tbody>
</table>
#'latex':
\begin{tabular}{rlrlr}
\hline
& 姓名 & 年龄 & 科目 & 分数 \\
\hline
0 & 张三 & 24 & 语文 & 88 \\
1 & 李四 & 19 & 数学 & 92 \\
2 & 王五 & 22 & 英语 & 85 \\
3 & 二狗子 & 32 & 物理 & 95 \\
4 & 王二麻子 & 44 & 化学 & 88 \\
\hline
\end{tabular}
#'simple':
姓名 年龄 科目 分数
----------------------------
0 张三 24 语文 88
1 李四 19 数学 92
2 王五 22 英语 85
3 二狗子 32 物理 95
4 王二麻子 44 化学 88
#'github':
| | 姓名 | 年龄 | 科目 | 分数 |
|----|----------|--------|--------|--------|
| 0 | 张三 | 24 | 语文 | 88 |
| 1 | 李四 | 19 | 数学 | 92 |
| 2 | 王五 | 22 | 英语 | 85 |
| 3 | 二狗子 | 32 | 物理 | 95 |
| 4 | 王二麻子 | 44 | 化学 | 88 |
参数说明
- tabular_data: 输入的数据,可以是列表、字典或 Pandas DataFrame。
- headers: 指定表头,可以是 ‘firstrow’、’keys’ 或自定义列表。
- tablefmt: 指定输出格式,如 ‘plain’、’grid’、’pipe’ 等。
- floatfmt: 指定浮点数格式,如 ‘.2f’ 表示保留两位小数。
- numalign: 数字对齐方式,选项有 ‘right’、’center’、’left’。
- stralign: 字符串对齐方式,选项有 ‘right’、’center’、’left’。
- missingval: 用于表示缺失值的字符串。
- showindex: 是否显示索引,可以是 True、False 或 range 对象。
进阶用法
tabulate 还可以处理复杂的表格结构和自定义格式。例如,可以处理嵌套的列表、复杂的对齐需求等。其灵活的参数配置可以满足大多数格式化需求。
使用 prettytable 库
prettytable 是一个用于在命令行界面中创建美观 ASCII 表格的 Python 库。它提供了简单且灵活的 API 来格式化和显示表格数据,非常适合用来输出小型数据集、调试信息或日志。
在使用 prettytable 之前,你需要安装它,可以使用以下命令:pip install prettytable
from prettytable import PrettyTable
# 创建 PrettyTable 对象
table = PrettyTable()
table.field_names = df.columns
# 添加行
for row in df.head().itertuples(index=False):
table.add_row(row)
print(table)
输出内容为:
+----------+------+------+------+ | 姓名 | 年龄 | 科目 | 分数 | +----------+------+------+------+ | 张三 | 24 | 语文 | 88 | | 李四 | 19 | 数学 | 92 | | 王五 | 22 | 英语 | 85 | | 二狗子 | 32 | 物理 | 95 | | 王二麻子 | 44 | 化学 | 88 | +----------+------+------+------+
Prettytable 相比 tabulate 没有发现什么特殊的优点,暂不做详细的介绍。
Pandas DataFrame 转化为图片输出
使用 matplotlib
matplotlib 是一个强大的 Python 绘图库,可以用来创建各种静态、动态、交互式的图表。虽然它本身不直接支持将 DataFrame 转换为图像,但我们可以利用它来绘制表格,然后保存为图片。
- 优点:灵活性高,可以自定义表格的样式、字体、颜色等。
- 缺点:代码相对复杂,需要手动设置很多细节。
示例代码:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as patches
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def dataframe_to_image(df, output_path):
fig, ax = plt.subplots(figsize=(len(df.columns)*2, len(df)*0.5)) # 调整图像大小
ax.axis('off') # 隐藏坐标轴
# 创建表格
table = ax.table(cellText=df.values, colLabels=df.columns, loc='center', cellLoc='center')
# 设置表格样式
table.auto_set_font_size(False)
table.set_fontsize(10)
table.scale(1, 1.5) # 调整表格大小
# 添加边框
for (row, col), cell in table.get_celld().items():
cell.set_edgecolor('black')
# 保存图像
plt.savefig(output_path, dpi=120, bbox_inches='tight')
plt.close(fig)
# 将 DataFrame 转换为图像
dataframe_to_image(df, 'dataframe_image_matplotlib.png')
输出内容:
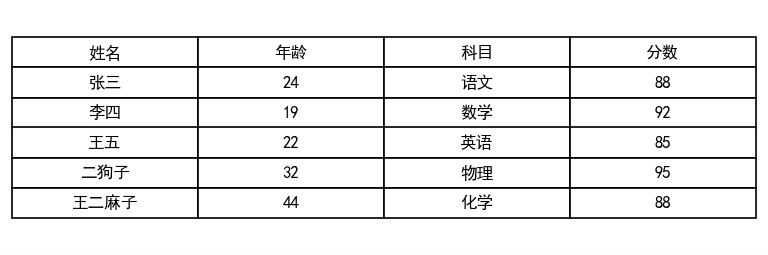
使用 matplotlib 和 pandas.plotting.table
使用 matplotlib 和 pandas.plotting.table 可以将 Pandas DataFrame 或 Series 转换为图像中的表格。这种方法相比直接使用 matplotlib.pyplot.table 更加方便,因为它直接利用了 Pandas 的数据结构。
from pandas.plotting import table
fig, ax = plt.subplots(figsize=(len(df.columns)*2, len(df)*0.4))
ax.axis('off')
tab = table(ax, df, loc='center', cellLoc='center')
tab.auto_set_font_size(False)
tab.set_fontsize(12)
tab.scale(1, 1.2)
for (row, col), cell in tab.get_celld().items():
cell.set_edgecolor('black')
if row == 0:
cell.set_text_props(weight='bold')
plt.savefig('dataframe_table_chinese.png', dpi=144, bbox_inches='tight', pad_inches=0)
plt.close(fig) # 释放资源,防止内存泄漏
输出内容:
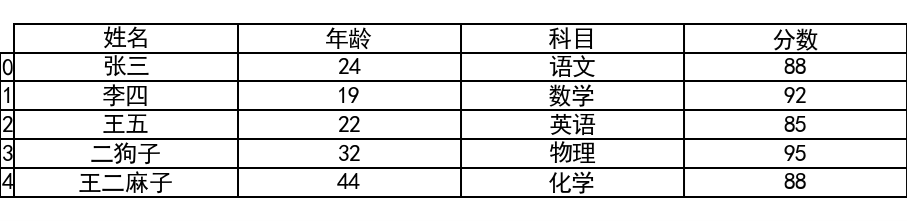
使用 dataframe_image
dataframe_image 是一个专门用于将 DataFrame 转换为图像的库,使用起来非常简单。
- 优点:使用简单,代码简洁。
- 缺点:依赖 Chrome,在 Docker 中无法使用。
安装:pip install dataframe_image
示例代码:
import dataframe_image as dfi # 将 DataFrame 转换为图像 dfi.export(df, 'dataframe_image.png')
输出内容为:

dataframe_image 库在默认情况下使用 Chrome 浏览器来将 Pandas DataFrame 转换为图像,这是因为它内部使用了 selenium 库,而 selenium 可以驱动各种浏览器进行自动化操作,包括渲染网页、截图等。dataframe_image 巧妙地利用了 Chrome 浏览器渲染 HTML 表格的能力,然后通过 selenium 截取渲染后的网页,从而生成图像。
dataframe_image 的工作流程:
- dataframe_image 首先将 Pandas DataFrame 转换为 HTML 表格。
- 然后,它使用 selenium 启动一个 Chrome 浏览器实例(headless 模式,即无界面模式,不会实际显示浏览器窗口)。
- selenium 将生成的 HTML 表格加载到 Chrome 浏览器中进行渲染。
- 最后,selenium 截取浏览器中渲染后的表格图像,并保存为 PNG 或其他图像格式。
table_conversion 参数:
dataframe_image 提供了 table_conversion 参数,用于指定表格转换的方式。默认值为 ‘chrome’,即使用 Chrome 浏览器。如果你的环境中无法使用 Chrome(例如服务器环境没有安装 Chrome),你可以将 table_conversion 设置为 ‘matplotlib’,这样 dataframe_image 就会使用 matplotlib 来生成图像。
import dataframe_image as dfi dfi.export(df, 'dataframe_image_matplotlib.png', table_conversion='matplotlib')
使用 matplotlib 的优点是不需要依赖 Chrome 浏览器,但缺点是生成的图像样式可能不如 Chrome 渲染的精美。
使用 Plot.ly
Plotly 是一个强大的交互式可视化库,虽然其主要优势在于创建动态图表,但它也支持将图表导出为静态图片格式,包括 PNG、JPEG、SVG 和 PDF。
以下是如何使用 Plotly 将 DataFrame 转换为图片的方法:
import pandas as pd import plotly.graph_objects as go import plotly.io as pio fig = go.Figure(data=[go.Table( header=dict(values=list(df.columns), align='left', font=dict(size=14, color='black')), #设置表头字体大小和颜色 cells=dict(values=[df[col] for col in df.columns], align='left', font=dict(size=12, color='grey')) #设置单元格字体大小和颜色 )]) fig.update_layout( title_text='DataFrame表格', #设置表格标题 title_x=0.5, #标题居中 margin=dict(l=0, r=0, b=0, t=0) #设置边距,防止标题被裁剪 ) fig.update_layout(autosize=False) #禁止自动调整大小 fig.update_layout(height=200) #设置宽度 pio.write_image(fig, 'dataframe_plotly.png')
参考链接:


