Pandera简介 Pandera是一个用于验证、清理和文档化Pandas数据框架(DataFrame和Series)的Python库。它提供了基于类型注释的方式来定义数据验证规则,确保数据符合预期格式和约束。这对于数据管道的构建、数据清理…
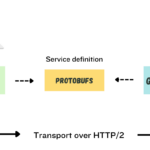
gRPC简介 gRPC是一个现代化的、高性能的远程过程调用(Remote Procedure Call, RPC)框架,由Google开发并开源。它基于HTTP/2协议,使用Protocol Buffers(protobuf)作为接口定义语言(IDL)和数据序列化工具,是…
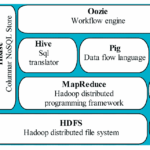
现在再写这篇文章感觉有些不合时宜,目前,貌似很少人再讨论大数据,也很少人再讨论Hadoop。整理这篇文章,是为了探寻最新的技术方向。 新技术替代的组件 Hadoop技术栈的许多组件已经被功能更强、性能更高的新技术…
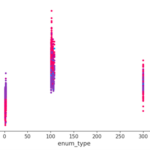
在使用SHAP对模型特征进行可视化输出的时候,会遇到输出的图形格式与预期的不符。以下面的图为例,比如是类别型特征时,默认的展示方式可能有些怪。 比较方便的解决方案是将数据导出为Pandas的DataFrame,然后自…
平时在使用LightGMB,需要保存训练好的模型。以下是梳理的几种方式: 使用LightGBM 自带的save_model 方法 import lightgbm as lgb # 假设已经训练好的模型是 model model = lgb.LGBMClassifier() model.fit(X_t…

PySpark简介 PySpark是Apache Spark的Python API,它使得Python开发者能够使用Spark的分布式计算能力进行大规模数据处理和分析。PySpark提供了与Scala和Java API类似的功能,并且与Python生态系统(如Pandas、NumPy…

Flume简介 Flume是一个分布式、可靠且高效的系统,主要用于大规模日志数据的收集、聚合和传输。它是Apache软件基金会的一个开源项目,特别适合将大量日志数据从不同的数据源转移到一个集中式的数据存储系统,比如Ha…
ClickHouse简介 ClickHouse是一个开源的列式数据库管理系统(Column-Oriented DBMS),专为实时大数据分析而设计。它支持实时查询,能够处理PB级别的数据,并且在大多数情况下提供了非常高的查询性能。ClickHouse由…

Altair简介 Python包Altair是一个基于Vega和Vega-Lite构建的声明式数据可视化库。它通过简洁的语法和直观的API,使得创建具有交互性的统计图表变得简单而直观。 主要特点 声明式语法:Altair使用声明式语法来…

在SQL中,IN和EXISTS(以及它们的否定形式NOT IN和NOT EXISTS)是常用的子查询条件,用于检查某个值是否在子查询结果集中存在。虽然它们可以实现类似的功能,但在语法、性能和行为上存在一些差异。 IN IN 用于检…






