什么是Ollama?
Ollama是一个致力于简化和优化机器学习模型使用的开源平台。它的目标是让开发者和数据科学家能够更轻松地使用和部署大型语言模型(LLM),并提供了一系列工具和框架,以支持模型的加载、管理和运行。
以下是Ollama的一些关键特点和功能:
- 简化模型管理:Ollama提供了一个简单的命令行界面,允许用户快速下载和运行各种预训练的语言模型。用户可以通过简单的命令来管理模型的版本和配置。
- 本地运行:Ollama支持在本地计算机上运行模型,避免了将数据上传到云端的需求。这对于保护隐私和数据安全尤为重要。
- 支持多种模型:Ollama可以支持多种不同的模型架构和框架,包括OpenAI的GPT系列、Google的BERT等。用户可以根据需求选择适合的模型。
- 易于集成:Ollama的设计使其易于与现有的开发工具和工作流程集成。它可以与Python、JavaScript等编程语言一起使用,方便开发者将其嵌入到应用程序中。
- 社区支持:作为一个开源项目,Ollama拥有活跃的社区支持,用户可以参与开发、报告问题和贡献代码。
- 灵活性和扩展性:Ollama提供了灵活的API接口,用户可以根据特定需求进行扩展和定制。
Ollama的应用场景广泛,包括但不限于:
- 聊天机器人:利用Ollama部署的LLM可以构建智能聊天机器人,为用户提供自然流畅的对话体验。
- 文本生成:Ollama可以生成各种文本内容,如新闻文章、博客文章、诗歌等,满足内容创作的需求。
- 问答系统:构建基于LLM的问答系统,快速准确地回答用户的问题。
- 代码生成:生成代码片段,如Python、JavaScript等,辅助软件开发和测试工作。
总之, Ollama 是一个基于Go语言开发的简单易用的本地大语言模型运行框架。可以将其类比为docker(同基于cobra包实现命令行交互中的list, pull, push, run等命令),事实上它也的确制定了类docker的一种模型应用标准。在管理模型的同时,它还基于Go语言中的Web框架gin提供了一些Api接口,让你能够像跟OpenAI提供的接口那样进行交互。
同时官方还提供了类似GitHub,DockerHub一般的,可类比理解为ModelHub,用于存放大语言模型的仓库(有llama2,mistral,qwen等模型,同时你也可以自定义模型上传到仓库里来给别人使用)。
Ollama的使用
使用Ollama的基本步骤如下:
安装Ollama
访问Ollama的官方网站下载相应平台的安装包或安装脚本。
Ollama的命令行使用
ollama安装之后,其同时还是一个命令,与模型交互就是通过命令来进行的。
(base) PS C:\Users\biaod> ollama Usage: ollama [flags] ollama [command] Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command Flags: -h, --help help for ollama -v, --version Show version information Use "ollama [command] --help" for more information about a command.
前边提到过,官方提供了一个模型仓库,https://ollama.com/library,在这里你可以找到你想要运行的模型。
官方建议:应该至少有8GB可用RAM来运行7B型号,16GB来运行13B型号,32GB来运行33B型号。
这里使用llama3.1做演示,由于我的笔记本性能有限,只有选了默认的8B版本,在命令行执行如下命令:
ollama run llama3.1
首次运行是会新下载模型文件,下载完后会出现如下提示:
PS C:\Users\biaod> ollama run llama3.1 >>> Send a message (/? for help)
输入问题即可获取答案:
>>> 天空为什么是蓝色的? 答案:这是因为大气中有许多小的气体molecule,像氧气和氮气。当阳光照射到这些气体分子上时,它们会散射出所有颜色,但最终 只剩下蓝色。
模型的管理
默认情况下,模型下载后存放在下面的位置:
- macOS: ~/.ollama/models
- Linux: /usr/share/ollama/.ollama/models #作为系统服务启动时
- Linux: /home/<username>/.ollama/models #当前用户启动时
- Windows: C:\Users\<username>\.ollama\models
如何修改下载模型的默认存放目录?
Windows用户
设置OLLAMA_MODELS
# 只设置当前用户 setx OLLAMA_MODELS "D:\ollama_model" # 为所有用户设置 setx OLLAMA_MODELS "D:\ollama_model" /M
重启终端(setx命令在Windows中设置环境变量时,这个变量的更改只会在新打开的命令提示符窗口或终端会话中生效。)
重启ollama服务Linux一般用户
# 打开下面文件 nano ~/.bashrc # 添加设置 export OLLAMA_MODELS="/path/to/ollama_model"
重启终端
- 重启ollama服务:ollama serve
- 或者直接使用:OLLAMA_MODELS=”/path/to/ollama_model” ollama serve启动服务
Liunx root服务模式
在服务文件中设置环境变量,并且要为新的目录设置ollama用户的读写权限
#打开服务文件 sudo nano /etc/systemd/system/ollama.service #在文件中Service字段后添加 [Service] Environment="OLLAMA_MODELS=/home/xxx/ollama/models" Environment="http_proxy=xxxxxx" #设置目录访问权限(根据反馈做了些调整) sudo chown ollama:ollama /home/xxx/ollama sudo chmod u+w /home/xxx/ollama sudo chown ollama:ollama /home/xxx/ollama/models sudo chmod u+w /home/xxx/ollama/models #重启服务 sudo systemctl daemon-reload sudo systemctl restart ollama.service #确认状态 sudo systemctl status ollama.service
Ollama的Modelfile
在Ollama中,Modelfile是一个关键的工具,用于定制和创建个性化的模型。Modelfile允许用户从现有的模型库中选择基础模型,并通过添加特定的参数和设置来调整模型的行为。
Modelfile的格式
| 指令 | 描述 |
| FROM (必需) | 定义要使用的基础模型。 |
| PARAMETER | 设置Ollama运行模型的参数。 |
| TEMPLATE | 发送给模型的完整提示模板。 |
| SYSTEM | 指定将在模板中设置的系统消息。 |
| ADAPTER | 定义要应用于模型的(Q)LoRA适配器。 |
| LICENSE | 指定法律许可。 |
| MESSAGE | 指定消息历史。 |
FROM (Required)
从现有模型构建
FROM llama3.1
从Safetensors模型构建
FROM <模型目录>
模型目录应包含支持架构的Safetensors权重。
当前支持的模型架构:
- Llama(包括Llama2、Llama3和Llama3.1)
- Mistral(包括Mistral1、Mistral2和Mixtral)
- Gemma(包括Gemma1和Gemma2)
- Phi3
从GGUF文件构建
FROM ./ollama-model.gguf
GGUF文件位置应指定为绝对路径或相对于Modelfile位置的相对路径。
PARAMETER
有效参数及其值:
| 参数 | 描述 | 值类型 | 示例用法 |
| mirostat | 启用Mirostat采样以控制困惑度。(默认值:0,0=禁用,1=Mirostat,2=Mirostat2.0) | int | mirostat 0 |
| mirostat_eta | 影响算法对生成文本反馈的响应速度。较低的学习率会导致调整较慢,而较高的学习率会使算法更具响应性。(默认值:0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的连贯性和多样性之间的平衡。较低的值会产生更集中的连贯文本。(默认值:5.0) | float | mirostat_tau 5.0 |
| num_ctx | 设置用于生成下一个标记的上下文窗口大小。(默认值:2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型回溯以防止重复的距离。(默认值:64,0=禁用,-1=num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置对重复惩罚的强度。较高的值(例如1.5)会更强烈地惩罚重复,而较低的值(例如0.9)则更宽松。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。提高温度会使模型的回答更具创造性。(默认值:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将其设置为特定数字会使模型为相同的提示生成相同的文本。(默认值:0) | int | seed 42 |
| stop | 设置停止序列。当遇到此模式时,LLM将停止生成文本并返回。可以通过在modelfile中指定多个单独的stop参数来设置多个停止模式。 | string | stop “AI assistant:” |
| tfs_z | 使用尾部自由采样来减少不太可能的标记对输出的影响。较高的值(例如2.0)会更大程度地减少影响,而值为1.0则禁用此设置。(默认值:1) | float | tfs_z 1 |
| num_predict | 生成文本时要预测的最大标记数。(默认值:128,-1=无限生成,-2=填充上下文) | int | num_predict 42 |
| top_k | 减少生成无意义文本的概率。较高的值(例如100)会提供更多样化的答案,而较低的值(例如10)则更保守。(默认值:40) | int | top_k 40 |
| top_p | 与top-k一起使用。较高的值(例如0.95)会导致生成更具多样性的文本,而较低的值(例如0.5)则生成更集中的保守文本。(默认值:0.9) | float | top_p 0.9 |
| min_p | top_p的替代方案,旨在确保质量和多样性的平衡。参数p表示相对于最可能标记的概率,标记被考虑的最小概率。例如,当p=0.05且最可能标记的概率为0.9时,logits小于0.045的将被过滤掉。(默认值:0.0) | float | min_p 0.05 |
TEMPLATE
完整提示模板(TEMPLATE)传递给模型。它可以包含(可选)系统消息、用户的提示消息以及模型的响应。注意:语法可能是模型特定的。模板使用Go模板语法。
模板变量
| 变量 | 描述 |
| {{.System}} | 用于指定自定义行为的系统消息。 |
| {{.Prompt}} | 用户提示消息。 |
| {{.Response}} | 模型的响应。在生成响应时,此变量之后的文本将被省略。 |
TEMPLATE """{{if .System}}<|im_start|>system
{{.System}}<|im_end|>
{{end}}{{if .Prompt}}<|im_start|>user
{{.Prompt}}<|im_end|>
{{end}}<|im_start|>assistant
"""
SYSTEM
SYSTEM指令用于在模板中指定系统消息(如果适用)。
SYSTEM """<system message>"""
ADAPTER
ADAPTER指令指定了一个微调的LoRA适配器,该适配器应应用于基础模型。适配器的值应为绝对路径或相对于Modelfile的路径。基础模型应通过FROM指令指定。如果基础模型与适配器所微调的基础模型不同,则行为可能会不稳定。
Safetensor适配器
ADAPTER <path to safetensor adapter>
当前支持的Safetensor适配器:
- Llama(包括Llama2、Llama3和Llama3.1)
- Mistral(包括Mistral1、Mistral2和Mixtral)
- Gemma(包括Gemma1和Gemma2)
GGUF适配器
ADAPTER ./ollama-lora.gguf
LICENSE
LICENSE指令允许您指定与此Modelfile一起使用的模型共享或分发的法律许可。
LICENSE """ <许可证文本> """
MESSAGE
MESSAGE指令允许您指定模型在响应时使用的消息历史。通过多次使用MESSAGE命令来构建对话,这将指导模型以类似的方式回答。
MESSAGE <角色> <消息>
有效角色
| 角色 | 描述 |
| system | 为模型提供SYSTEM消息的另一种方式。 |
| user | 用户可能会问的问题示例。 |
| assistant | 模型应该如何响应的示例消息。 |
示例对话
MESSAGE user Is Toronto in Canada? MESSAGE assistant yes MESSAGE user Is Sacramento in Canada? MESSAGE assistant no MESSAGE user Is Ontario in Canada? MESSAGE assistant yes
Ollama API
Ollama提供了一个RESTful API,允许开发者通过HTTP请求与Ollama服务进行交互。这个API覆盖了所有Ollama的核心功能,包括模型管理、运行和监控。
文本生成
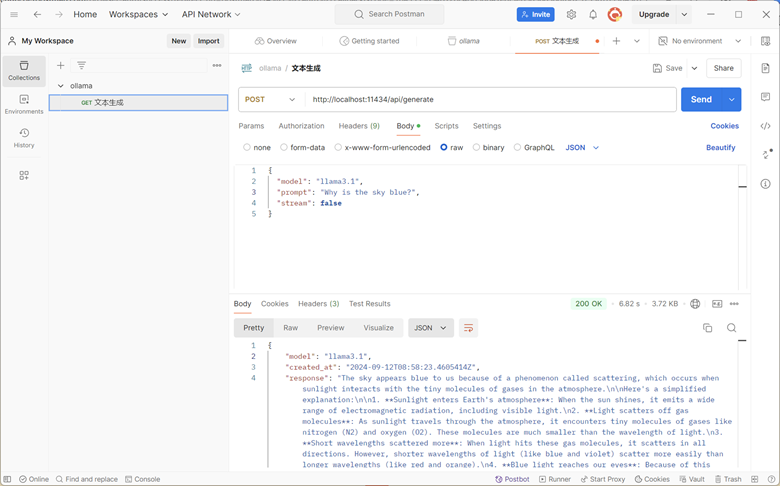
端点:POST /api/generate
基本参数:
- model:(必需)模型名称
- prompt:用于生成响应的提示
- suffix:模型响应后的文本
- images:(可选)一组base64编码的图像(用于多模态模型,如llava)
高级参数(可选):
- format:返回响应的格式。目前唯一接受的值是json
- options:Modelfile文档中列出的其他模型参数
- system:系统消息(覆盖Modelfile中定义的内容)
- template:要使用的提示模板(覆盖Modelfile中定义的内容)
- context:从先前对/generate请求中返回的上下文参数,可用于保持简短的对话记忆
- stream:如果为false,响应将作为单个响应对象返回,而不是一系列对象流
- raw:如果为true,则不会对提示应用任何格式化。如果您在请求API时指定了完整的模板提示,可以选择使用raw参数
- keep_alive:控制请求后模型在内存中保持加载的时间(默认:5分钟)
示例:
生成聊天
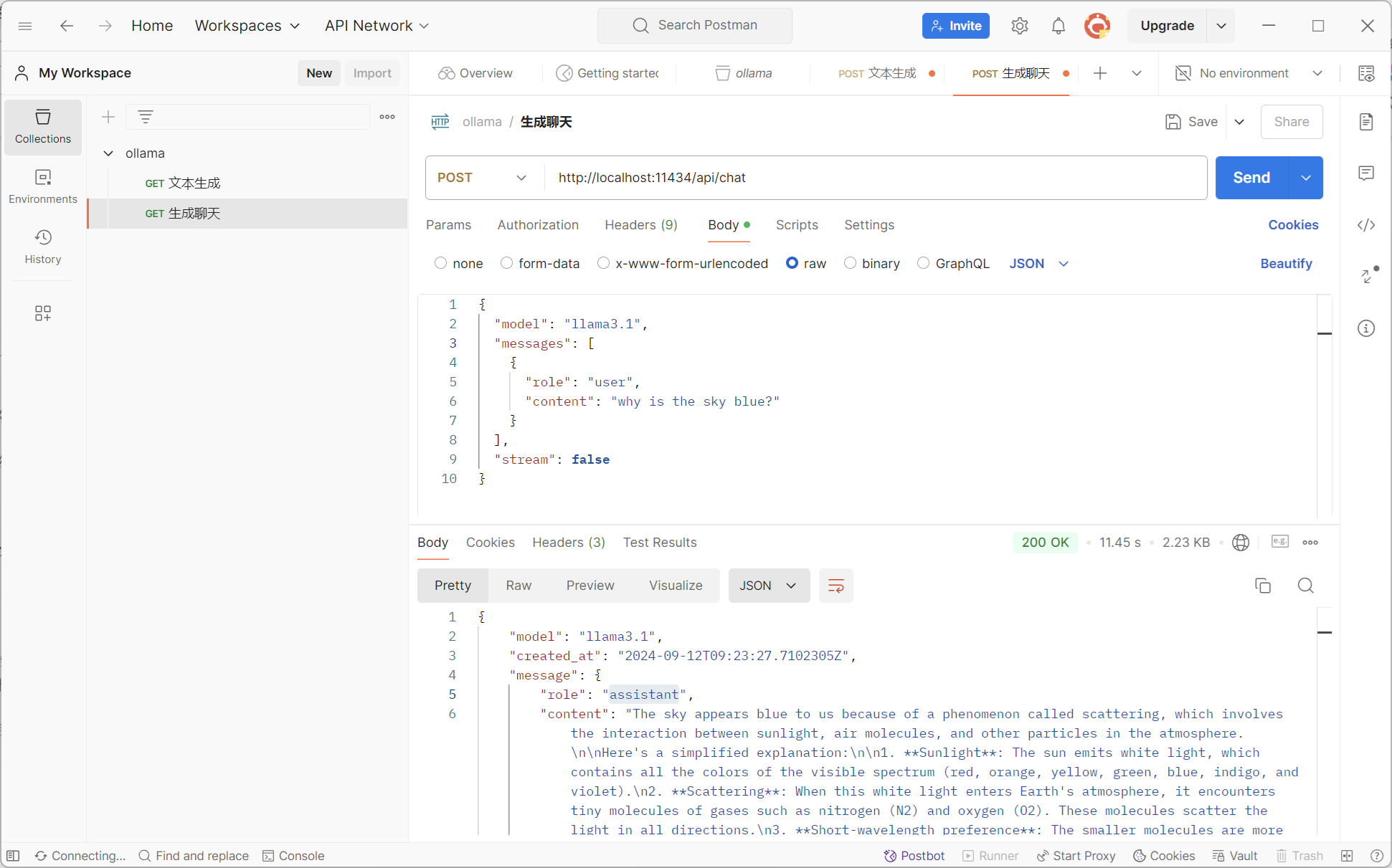
端点:POST /api/chat
使用提供的模型生成聊天中的下一条消息。这是一个流式端点,因此会有一系列响应。最终的响应对象将包括统计数据和请求的附加数据。
基本参数:
- model:(必需)模型名称
- messages:聊天的消息,这可以用来保持聊天记忆
- tools:模型使用的工具(如果支持)。需要将stream设置为false
消息对象包含以下字段:
- role:消息的角色,可以是system、user、assistant或tool
- content:消息的内容
- images(可选):要包含在消息中的图像列表(用于多模态模型,如llava)
- tool_calls(可选):模型想要使用的工具列表
高级参数(可选):
- format:返回响应的格式。目前唯一接受的值是json
- options:Modelfile文档中列出的其他模型参数,如温度
- stream:如果为false,响应将作为单个响应对象返回,而不是一系列对象流
- keep_alive:控制请求后模型在内存中保持加载的时间(默认:5分钟)
 其他接口
其他接口
- 创建模型
- 列出本地模型
- 显示模型信息
- 复制模型
- 删除模型
- 拉取模型
- 推送模型
- 生成嵌入
- 列出正在运行的模型
可视化调用ollama
Ollama的GitHub页面上罗列了很多可视化的工具用于替换命令行工具,这里推荐Msty-Using AI Models made Simple and Easy,主要是界面比较美观,安装也比较方便。
Python调用ollama
Ollama支持调用的语言非常多,这里主要介绍Python。
安装
pip install ollama
使用
import ollama
response = ollama.chat(model='llama3.1', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
可以通过设置stream=True启用响应流
import ollama
stream = ollama.chat(
model='llama3.1',
messages=[{'role': 'user', 'content': 'Why is the sky blue?'}],
stream=True,
)
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
API接口
同Ollama REST API
生成内容
ollama.generate(model='llama3.1', prompt='Why is the sky blue?')
生成聊天
ollama.chat(model='llama3.1', messages=[{'role': 'user', 'content': 'Why is the sky blue?'}])
自定义客户端
可以使用以下字段创建自定义客户端:
- host: 要连接的Ollama主机
- timeout: 请求的超时时间
from ollama import Client
client = Client(host='http://localhost:11434')
response = client.chat(model='llama3.1', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
异步客户端
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': 'Why is the sky blue?'}
response = await AsyncClient().chat(model='llama3.1', messages=[message])
asyncio.run(chat())
设置stream=True将函数修改为返回一个Python异步生成器:
import asyncio
from ollama import AsyncClient
async def chat():
message = {'role': 'user', 'content': 'Why is the sky blue?'}
async for part in await AsyncClient().chat(model='llama3.1', messages=[message], stream=True):
print(part['message']['content'], end='', flush=True)
asyncio.run(chat())
Ollama常用模型介绍
llama3.1
Llama3.1是由Meta公司在2024年7月发布的一款超大型开源语言模型。
模型规模与性能
- 参数量:Llama3.1拥有高达4050亿个参数,这一规模使其在语言处理任务中具有强大的能力。同时,Meta还提供了参数量较小的70B和8B版本,以满足不同场景和需求。
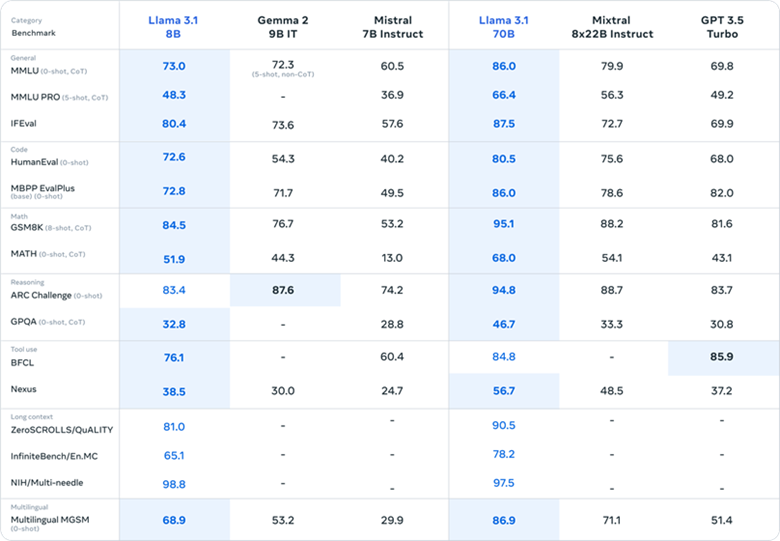
- 准确性:在多个基准测试中,Llama3.1展现出了卓越的性能。例如,在数学能力测试中,其405B版本以8的高分位居榜首;在推理能力测试中,同样以96.9的高分领先。这些成绩证明了Llama3.1在处理复杂任务时的准确性。
- 速度:通过优化算法和并行处理技术,Llama3.1大幅缩短了信息处理时间,提升了用户体验。其轻量级的8B版本几乎可以在任何设备上流畅运行,非常适合资源受限的环境。
多模态能力与多语言支持
- 多模态能力:Llama3.1不仅局限于文本处理,还能理解和生成图像、视频和音频内容,实现了真正的跨媒体交互。这种多模态能力使其在数据分析和内容创作方面具有巨大的潜力。
- 多语言支持:Llama3.1支持包括英语、中文、西班牙语、法语、德语、日语、韩语和阿拉伯语在内的八种语言。这种多语言支持能力显著增强了模型的全球适用性,使其在多语言翻译和跨语言处理方面表现出色。
开源特性与生态系统
- 开源特性:作为开源模型,Llama3.1鼓励全球开发者社区的参与和贡献。这种开放的生态系统促进了技术的快速迭代和创新,使得Llama3.1能够不断进化并满足不断变化的市场需求。
- 生态系统支持:Meta为开发者提供了丰富的工具和资源,包括API访问权限、预置环境以及合成数据生成等功能。这些支持使得开发者能够更轻松地集成和应用Llama3.1模型。
gemma2
Gemma2由谷歌推出,并在2024年5月15日的谷歌I/O开发者大会上首次亮相。该模型属于开放式模型,与谷歌之前推出的Gemini模型采用相同的研究和技术构建。Gemma2旨在用于负责任的AI创新,并为下一代开放模型提供基础。
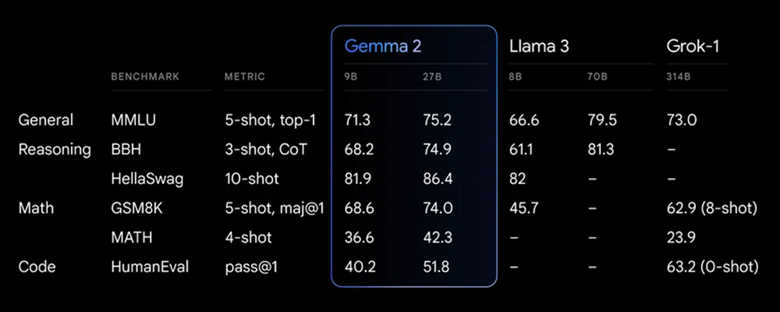
技术特点
- 参数规模与性能。Gemma2提供两种参数规模的模型:90亿参数(9B)和270亿参数(27B)。尽管参数规模相对较小,但Gemma2的性能卓越。特别是27B版本,其性能可与参数规模更大的Llama3 70B相媲美,实现了突破性的性能和效率。
- 高效推理与部署。Gemma2经过优化,可以在单个NVIDIA GPU或TPU主机上实现高效推理,降低了部署成本。该模型还支持广泛的硬件平台,从游戏笔记本电脑到云端环境均可运行。
兼容性与易用性。Gemma 2兼容多种主流AI框架,如 Hugging Face、JAX、PyTorch 和 TensorFlow 等,便于开发者集成到现有工作流程中。谷歌提供了丰富的微调资源和工具,如 Gemma Cookbook 和 Vertex AI 上的轻松部署选项,使得 Gemma 2更易于定制和应用到特定任务中。
Mistral
Mistral模型是一种基于 Transformer 架构的 AI 模型,由欧洲的 AI 研究团队开发并开源。Mistral模型采用了 Transformer 架构,这是自然语言处理领域非常流行的架构设计,特别适用于处理长序列数据。模型由多个 n_layer 组成,具体地,如 Mistral 7B 和 Mixtral 8x7B,这些模型在规模上有所不同,但都遵循 Transformer 的基本架构。
优化策略
- 分组查询注意力(GQA):Mistral模型通过分组查询注意力机制来减少计算量。该机制将查询(query)拆分成多个组,并与 key 的子集进行注意力运算,然后将结果进行拼接。这种方法降低了运算量,提高了查询的吞吐量,使得 Mistral AI 模型在处理大规模数据时能够保持高效的处理速度。
- 滑动窗口注意力(SWA):在推理阶段,Mistral设定一个窗口长度,在该窗口内进行注意力运算,而不是对整个文本进行操作。通过滑动窗口的方式,不同注意力层之间会有所重叠,从而实现对长文本序列的高效处理。这种策略显著提高了计算效率,并使得模型理论上能够处理更长的 token 序列。例如,Mistral AI 模型理论上可以处理长达1万个 token 的文本序列。
- 稀疏混合专家(MoE)架构:Mistral还采用了稀疏混合专家(MoE)架构,这是一种增大模型参数容量但推理时仅采用部分参数进行推理的策略。通过 MoE 架构,模型可以将复杂的任务分割成一系列更小、更容易处理的子任务,每个子任务由特定领域的专家负责处理。这种架构在训练时赋予模型更强的性能,同时降低了推理时的计算成本。
模型特点
- 开源性:Mistral AI 模型最初以开源形式发布,旨在推动 AI 技术的普及和发展。这种开源理念使得更多的研究者和开发者能够参与到模型的改进和优化中来。
- 高性能:通过以上的优化策略和技术,Mistral AI 模型在性能和资源消耗方面表现出色。其性能在某些方面甚至超过了其他竞争对手,如 Meta 的 Llama 2系列和 OpenAI 的 GPT-3.5。具体来说,Mistral 7B 模型在多个自然语言处理基准测试中均取得了优异的性能,如常识推理、世界知识、阅读理解、数学、代码等任务。此外,Mistral Large 模型还支持多种语言,并显示出对不同语言和文化背景的强大理解能力。
- 广泛应用:Mistral AI 模型被广泛应用于各种场景,包括自然语言生成、文本摘要、问题解答、对话系统等。其高性能和低消耗的特点使得它能够为各种应用场景提供强大的支持。
qwen2
Qwen2是由阿里云通义千问团队研发的新一代大型语言模型系列,其在多个方面都实现了技术的显著飞跃和性能的提升。
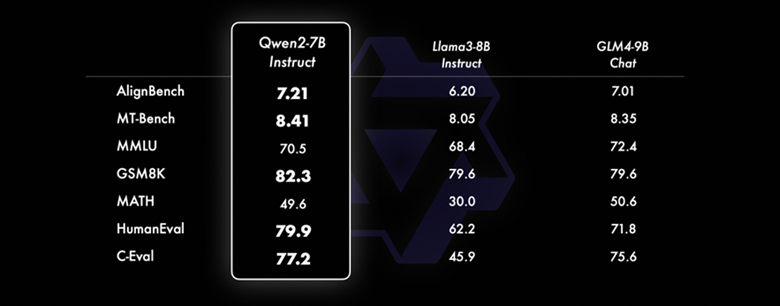
Qwen2系列提供了多个不同规模的模型,包括:
- Qwen2-0.5B
- Qwen2-1.5B
- Qwen2-7B
- Qwen2-57B-A14B(混合专家模型,MoE)
- Qwen2-72B
这些模型在参数数量上从数亿到数百亿不等,为用户提供了丰富的选择,以适应不同的应用场景和资源限制。
性能提升
相比前代模型 Qwen1.5,Qwen2在多个方面实现了性能的显著提升,包括:
- 代码理解与编写:辅助程序员编写代码、理解代码逻辑等。
- 数学推理与问题解决:在数学、物理等领域提供解题思路和答案。
- 多语言支持:新增了27种语言的高质量数据,使模型在多语言处理上更加出色。
- 超长上下文处理:特别是 Qwen2-72B 模型,支持处理长达128K tokens 的上下文,对于大型文档理解和复杂对话处理尤为重要。
技术架构与创新
- Qwen2采用了 Transformer 架构,并引入了多项技术改进点,如 SwiGLU 激活函数、QKV bias 等,以提升模型的性能。
- 所有尺寸的 Qwen2模型都使用了 GQA(分组查询注意力)机制,以降低计算复杂度、提高计算效率,并带来推理加速和显存占用降低的优势。
phi3
Phi-3是微软发布的一系列小型语言模型,以其出色的性能和高效的成本效益在自然语言处理领域引起了广泛关注。
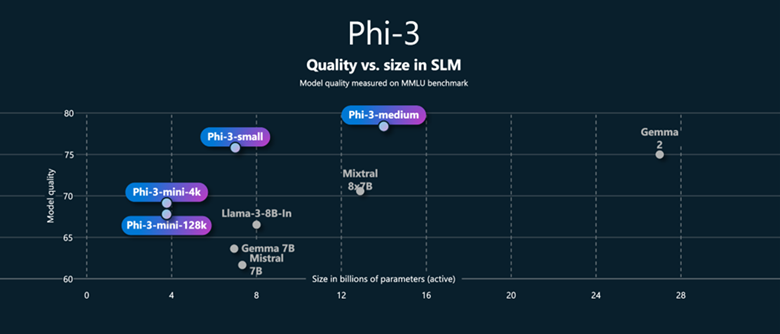
Phi-3系列包括三个不同规模的版本,以适应不同的应用场景和需求:
- Phi-3-mini:参数规模为38亿,是系列中最小的模型,适合在资源受限的设备上运行。
- Phi-3-small:参数规模为70亿,提供了更强的语言理解和推理能力。
- Phi-3-medium:参数规模为140亿,是系列中最大的模型,具有更高的性能表现。
性能特点
- 小型化设计:尽管参数规模较小,但 Phi-3系列模型在多个学术基准测试中展现出了与市场上大型模型相媲美的性能。
- 迅速响应:例如,Phi-3-mini在移动设备上能够实现快速响应,每秒能生成一定数量的 token,如 iPhone 上每秒能生成16个 token。
- 离线可用性:Phi-3模型支持离线运行,无需互联网连接,有助于保护用户隐私并减少对网络带宽的依赖。
- 多语言潜力:Phi-3的 Small 和 Medium 版本在训练中融入了多语言数据,有望扩展对更多语言的支持。
- 资源节省与高效集成:模型内存占用相对较低,能在配置较低的设备上运行,且易于集成到各种应用中。
技术架构与创新
- Phi-3模型采用了 Transformer 解码器架构,并针对移动设备进行了优化,如通过 LongRope 系统显著扩展模型的上下文长度。
- 引入了分组查询和块状稀疏注意力机制,优化了模型处理长期上下文时的检索性能,并降低了内存占用。
- 采用了分阶段数据训练和启发式训练方法,使用网页数据和合成数据进行训练,提升了模型的通用知识和逻辑推理能力。
LLaVA
LLaVA(Large Language Model with Vision and Audio)是由阿里云与斯坦福大学联合研发的一种多模态大模型。LLaVA结合了语言模型与视觉模型的能力,能够在处理文本的同时处理图像和音频信息,从而实现更丰富的交互和理解能力。
模型特点
- 多模态融合。LLaVA结合了语言、视觉和音频三种模态的信息处理能力,能够同时处理文本、图像和音频数据。
- 强大的语言能力。LLaVA在语言处理方面表现出色,能够生成高质量的文本,理解复杂的语言结构。
- 视觉理解。LLaVA能够理解图像内容,识别物体、场景和事件,提供基于图像的描述和解释。
- 音频处理。LLaVA还具备处理音频的能力,能够识别语音、音乐和其他声音信号,并提供相应的解释或反馈。
LLaVA系列目前包括以下几个主要版本:
- LLaVA-7B
- LLaVA-13B
- LLaVA-34B
- LLaVA-70B
Transformer架构
LLaVA基于 Transformer 架构,这是一种广泛应用于自然语言处理的模型架构,非常适合处理序列数据,如文本和音频。
- 多模态编码。LLaVA使用多模态编码技术,将文本、图像和音频信息编码为统一的表示形式,便于模型进行融合处理。
- 多任务学习。LLaVA在训练过程中采用了多任务学习的方法,不仅学习文本生成任务,还学习图像描述、音频识别等多种任务,提升了模型的整体性能。
- 数据增强。LLaVA在训练数据中使用了大量的多模态数据,并通过数据增强技术进一步丰富了训练样本,增强了模型的泛化能力。
跨模态注意力机制。LLaVA引入了跨模态注意力机制,使得模型能够在处理不同模态信息时相互参考和融合,提高整体理解能力。
codellama
Codellama是一种专门针对代码生成和编程任务优化的大型语言模型。它是Meta(Facebook的母公司)发布的LLaMA系列模型的一个分支,专注于代码理解和生成。
Codellama系列包括以下几个主要版本:
- Codellama-7B
- Codellama-13B
- Codellama-34B
- Codellama-70B
性能特点
- 代码生成能力。Codellama在代码生成方面表现出色,能够生成高质量的代码片段,帮助程序员提高工作效率。
- 代码理解能力。Codellama不仅能生成代码,还能理解现有的代码,帮助程序员进行调试、重构和优化。
- 多语言支持。Codellama支持多种编程语言,包括Python、JavaScript、Java、C++、Go、TypeScript等,具备广泛的适用性。
- 高效率。由于模型的优化设计,Codellama在生成代码时速度快、资源占用低,适合在资源有限的环境中运行。
- 上下文感知。Codellama能够理解上下文,根据当前代码环境生成合适的代码片段,确保代码的一致性和正确性。
应用场景
- 自动补全。Codellama可以用于代码编辑器中的自动补全功能,帮助程序员快速完成代码编写。
- 代码生成。Codellama可以生成完整的函数或类定义,帮助程序员快速搭建项目框架。
- 代码理解。Codellama可以解析现有代码,帮助程序员理解复杂的代码逻辑,进行调试和重构。
- 代码优化。Codellama可以提出代码优化建议,帮助程序员提高代码质量和性能。
- 代码文档生成。Codellama可以自动生成代码文档,帮助维护和管理代码库。
CodeGemma
CodeGemma是一款由Google推出的集成多种编程语言的轻量级模型,专注于代码生成、理解和追踪指令。
模型特点
- 多语言能力:支持包括Python、JavaScript、Java、Kotlin、C++、C#、Rust、Go等多种编程语言,适用于不同项目和团队。
- 准确性:基于5000亿令牌的数据进行训练,生成的代码在语法上更加正确,语义上更有意义,减少错误和调试时间。
- 高效性:专为快速代码填充和开放式生成设计,提供代码补全功能,显著提升开发者的生产效率。
- 可扩展性:提供不同规模的模型,包括7B和2B版本,以满足不同需求和资源限制。
模型版本与性能
CodeGemma7B版本:
- 专注于自然语言到代码聊天和指令跟随,具备强大的自然语言理解能力。
- 在数学推理方面表现出色,与其他开放模型的代码能力相匹配。
CodeGemma2B版本:
- 先进的代码补全模型,专为延迟敏感环境中进行快速代码填充设计。
- 在代码完成任务中表现突出,低延迟特性适合需要快速响应的用例。
应用场景
- 代码开发:在各种编程环境中使用CodeGemma生成复杂代码片段,提高编码效率。
- 学习实践:学生可借助CodeGemma辅助编程学习和练习,提升编程技能。
- 软件开发:工程师在开发过程中利用CodeGemma生成代码,提高软件开发效率。
参考链接:


