ORM简介
ORM,即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间作一个映射,ORM为关系型数据库提供了高级的抽象,它使得开发人员不必写SQL,只需写代码就能在数据库中创建、读取、更新和删除数据。开发人员能使用他们熟悉的编程语言来处理数据库,而无需编写SQL语句或存储过程。
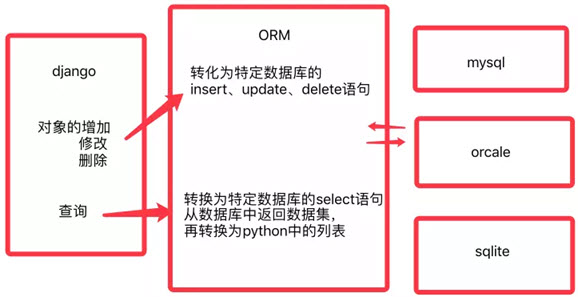
ORM主要任务是:
- 根据对象的类型生成表结构
- 将对象、列表的操作,转换为sql语句
- 将sql查询到的结果转换为对象、列表
ORM的优点:
- 掩藏了数据访问细节,ORM提供了对数据库的映射,不用sql直接编码,能够像操作对象一样从数据库获取数据。
- 提高了开发效率,基本上所有的ORM框架都提供了通过对象模型构造关系数据库结构的功能。
- 实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库。
ORM的缺点:
- 会有一定的性能损耗,自动化意味着映射和关联管理,代价是牺牲性能。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache)。
- 对于复杂的查询有些力不从心,比如分calculated column,case,group,having, order by, exists等。
- 需要消耗更多的内存,使用ORM会将对象的全部数据都提取到内存对象中,然后再进行过滤和加工处理,这样就容易产生性能问题。
- 将复杂性从数据库转移到了应用程序代码中,因其没有在应用程序和数据库存储过程之间将代码进行拆分,从而提高了Python的总代码量。
常见的Python ORM:
- Django ORM:是Django框架自带,适用于简单或中等复杂度的数据库操作。该ORM基于复杂的查询操作转化而成的SQL语句,相比于直接用SQL编写或者用SQLAlchemy产生的语句,更加的繁琐。
- SQLAlchemy:是个广受好评的Python ORM。相比Django ORM,它能简化复杂数据库查询语句的编写工作。
- Peewee:比SQLAlchemy”更简单、更小及更加hackable”。Peewee对于SQLAlchemy,就像SQLite对于PostgreSQL。一个ORM无需适用于所有的使用情况也能被认为是有用的。
Django ORM与SQLAlchemy的比较
ORM两种最常见的实现方式是ActiveRecord和DataMapper,首先这两种持久模式的特点如下:
- ActiveRecord(活动记录模式)是领域模型对象字段和数据表字段之间存储1:1的关系,也就是一个模型字段对应一个数据表字段;然后模型对象提供一个save()方法用来将模型对象持久化到存储层中去;模型是知道数据层的,也就是和数据持久层耦合的。
- DataMapper(数据映射模式)则是将领域模型对象和数据表完全松耦合,领域对象只负责处理业务逻辑,根本不知道数据层,也就是和数据层是解耦的;使用一个实体管理器来将模型对象持久化到存储层中;模型对象的字段可以是任何名称,只要符合业务模型即可,可以映射到数据层数据表的不同字段。
Django ORM 采用活动记录实现—大多数ORM中能看到这种实现。基本上也可以说是数据库中每一行都直接映射到代码中的对象,反之亦然。ORM框架(如Django)不需要为了在代码中使用属性而预先定义架构,只需要使用它们,因为框架可以通过查看数据库架构”理解”结构。此外,也可以只保存记录到数据库,因为它也映射到表中的特定行。
SQLAlchemy 采用数据映射实现—当使用这种方式实现时,数据库结构和对象结构之间存在间隙(它们不像活动记录的实现是1:1)。大多数情况下,必须使用另外的持久层来保持与数据库的交互(例如保存对象)。因此当采用活动记录实现的时候不能只调用save()方法,但另一方面,代码不需要知道数据库中整个关系结构的运行,因为代码和数据库之间没有直接关系。
很显然,ActiveRecord比较简单,但是不够灵活,而DataMapper则是很灵活,但是多了一个实体管理器,增加了复杂性。如果你的应用程序大多是CRUD(创建、读取、更新、删除)程序,而在不同数据实体之间没有使用困难且复杂规则,那么应该采用活动记录实现(Django)。如果有许多”业务规则”和限制条件,最好采用数据映射模型,因为它不会捆绑并强迫严格遵照活动记录来考量。
- 使用复杂查询在某些情况下,Django和SQLAlchemy可以同时使用。现实环境中可以见到主用例是Django用于所有常规CRUD操作,而SQLAlchemy用于更复杂的查询,通常是只读查询。
- 主键自动生成两个框架之间的另一个不同是Django能为表自动创建主键,SQLAlchemy却做不到。必须手动为每张表创建主键。
- 自动提交默认情况下,Django会自动提交,SQLAlchemy却不行。自动提交会影响使用框架的方式(事务、回滚等)。
- 支持的数据库都能用于MySQL、PostgreSQL、Oracle和SQLite。如果你正在使用MSSQL,则应该使用SQLAlchemy,因为它完全支持MSSQL,并且也可以找到更多相关的信息和文档。
- 学习曲线Django更容易学习。由于它通常都用在没有特别复杂的用例上。
- 社区规模在Python ORM框架中SQLAlchemy拥有最大的社区。如果社区对你至关重要,SQLAlchemy该是你的选择。
- 性能使用框架特性的方式,会对应用程序中数据层的整体性能产生极大影响。因此不要通过性能来选择框架,而是应该学习如何合理利用框架。
Django的Model驱动对数据库层面上的实现细节关注的非常少,开发者定义模型的过程非常接近声明式而非过程式,对于新项目来说,可能是这个原因让Django Model比SQLAlchemy讨人喜欢。传统的SQLAlchemy的使用方法是不入侵模型,在单独的地方定义表结构、映射规则,然后用SQLAlchemy驱动注入到模型类里去,这种方法可以完全避免模型与数据库的耦合,但是定义繁琐,要求开发者完全明白engine、metadata、table、column、mapper等概念。现在SQLAlchemy提供了declarative的方式,和Django Model很像,但是和声明式模型还是有一定的距离。对比Django Model和SQLAlchemy declarative,Django Model还是更简洁一些。例如对于类关联,Django只要直接声明外键,就自动产生关联对象,而SQLAlcyhemy要定义外键、relationship对象,如果有多个外键还要自己指定join规则。
Django支持的数据库
Django自带的数据库引擎有:
- ‘django.db.backends.postgresql’
- ‘django.db.backends.mysql’
- ‘django.db.backends.sqlite3’
- ‘django.db.backends.oracle’
另外支持的第三方数据库有:
参考链接:
- https://docs.djangoproject.com/en/2.0/ref/databases/
- https://docs.djangoproject.com/en/2.0/ref/settings/
- https://docs.djangoproject.com/en/2.0/topics/db/multi-db/
Django模型之模型类定义
使用Django模型开发的首要任务就是定义模型类及其属性。每个模型类都可以被映射为数据库中的一个数据表,而类属性被映射数据字段,除此之外,数据库表的主键、外键、约束等也通过类属性完成定义。
模型定义的基本结构如下:
from django.db import models
class ModelName(models.Model):
field1 = models.XXField(...)
field2 = models.XXField(...)
...
class Meta:
db_table = ...
other_metas = ...
- 所有Django模型继承自db.models.Model类
- 类属性定义模型字段,模型字段必须是某种XXField类型
- 类中的Meta子类定义模型的元数据,比如数据库表名、数据库默认排序等
Meta的属性名由Django预定义,常用的Meta属性如下:
- abstract:True或False,标识此类是否为抽象类
- app_label:定义本类所属的应用,比如app_label=’myapp’
- base_manager_name:自定义模型的_base_manager管理器的名字。模型管理器是Django为模型提供的API所在。
- db_table:映射的数据库表名,如果不提供,会自动数据库表名,格式为“应用名_模型名”
- db_tablespace:映射的表空间名,只在某些有表空间概念的数据库中有用(比如Oracle),否则会被忽视
- default_manager_name:模型的_default_manager用到的管理器的名称。
- default_related_name:定义本模型的反向关系引用名称,默认与模型名一致。这个名字会默认被用于一个关联对象到当前对象的关系。默认为<model_name>_set
- get_latest_by:定义按哪个字段值排列以获得模型的开始或结束记录,本属性通常执行一个日期或整形的模型字段。
- managed:True或False,定义Django的py命令行工具是否管理本模型。默认为True。如果设置为False,则运行python manage.py migrate时将不会在数据库中生成本模型的数据库表。
- order_with_respect_to:定义本模型可以按照某外键引用的关系排序。
- ordering:本模型记录的默认排序字段,可以设置多个字段,默认为升序排序,如果按照降序排序在字段名前加入“负号”
- permissions:设置创建对象时权限表中额外的权限。它是一个包含二元组的元组或者列表,格式为(permission_code,human_readable_permission_name)。
- default_permissions:模型操作权限,默认为(‘add’,’change’,’delete’)
- proxy:True或False,本模型及所有继承自本模型的子模型是否为代理模型。
- required_db_features:定义底层数据库所必须具备的特性。比如required_db_features=[‘gis_enabled’],只将本数据模型生成在满足gis_enabled的数据库中。
- required_db_vendor:定义底层数据库的类型,比如SQLite、PostgreSQL、MySQL、Oracle。如果定义了本属性,则模型只能在其声明的数据库中被维护。
- select_on_save:该选项决定了Django是否采用6之前的django.db.models.Model.save()算法。旧的算法使用SELECT来判断是否存在需要更新的行。而新式的算法直接尝试使用UPDATE。在一些小概率的情况中,一个已存在的行的UPDATE操作并不对Django可见。比如PostgreSQL的ON UPDATE触发器会返回NULL。这种情况下,新式的算法会在最后执行INSERT操作,即使这一行已经在数据库中存在。通常这个属性不需要设置。默认为False。
- indexes:要在模型上定义的索引的列表。
- unique_together:设置联合唯一索引unique_together=((“driver”,”restaurant”),)
- index_together:设置联合索引index_together=[[“pub_date”,”deadline”],]
- verbose_name:指明一个易于理解和表述的单数形式的对象名称。如果此项没有设置,Django会把类名拆分开来作为自述名,比如CamelCase会变成camel case,
- verbose_name_plural:指明一个易于理解和表述的复数形式的对象名称。如果此项没有设置,Django会使用verbose_name+”s”。
只读Meta属性:
- label:对象的表示,返回object_name,例如’polls.Question’。
- label_lower:模型的表示,返回model_name,例如’polls.question’。
参考链接:https://docs.djangoproject.com/en/2.0/ref/models/options/
Django模型之普通字段类型
所有的字段类型都必须继承自django.db.models.Field,开发者可以定义自己的继承自该类的字段类型,也可以使用Django预定义的一系列Field子类。
Django预定义子类
- AutoField
- BigAutoField
- SmallIntegerField
- PositiveSmallIntegerField
- IntegerField
- PositiveIntegerField
- BigIntegerField
- FloatField
- DecimalField:传入参数max_digits, decimal_places必传。
- DateField
- TimeField
- DateTimeField
- DurationField:存储时间周期,使用Python的timedelta类型构建。
- BooleanField
- NullBooleanField:类似BooleanField,但是比起多了None选项。
- CharField
- SlugField:只能包含字母、数字、下划线和连字符的输入字段,通常用于 url 中。
- URLField
- EmailField
- GenericIPAddressField
- UUIDField
- BinaryField:二进制数据字段,只能通过 bytes 对其进行赋值。
- FilePathField
- FileField:一个文件上传字段,在定义本字段时必须传入参数 upload_to,用于保存上载文件的服务器文件系统的路径。
- ImageField:类似 FileField,同时验证上传的是否是一个合法的图片。有两个可选参数 height_field 和 width_field,如果提供这 2 个参数,则图片会按提供的宽度和高度保存。该字段要求安装 Python Imaging 库。
TextField
参考地址:https://docs.djangoproject.com/en/2.0/ref/models/fields/#model-field-types
Django 模型之常用字段参数
- null:定义是否允许数据库字段为 null,默认为 False。
- blank:定义字段是否可以为空,用于表单验证,确定是否可以不输入数据,默认为 False。
- choices:定义字段的可选值,该字段为二维元素的元组,每个元素的第一个值为实际存储值,第二个值是 html 中选择时显示的值。
- db_column:数据库中用来表示该字段的名称。如果未指定,那么 Django 将会使用 Field 名作为字段名
- db_index:若为 True,将为此字段创建索引。
- db_tablespace:如果该字段有索引的话,数据库表空间的名称将作为该字段的索引名。如果 DEFAULT_INDEX_TABLESPACE 已经设置,则默认值是由 DEFAULT_INDEX_TABLESPACE 指定,如果没有设置则由 db_tablespace 指定,如果后台数据库不支持表空间,或者索引,则该选项被忽略
- default:设定的默认值
- editable:如果设为 False,这个字段将不会出现在 admin 或者其他他们也会跳过模型验证,默认是 True
- error_messages:error_messages 参数能够让你重写默认抛出的错误信息。通过指定 key 来确认你要重写的错误信息。
- help_text:HTML 页面输入控件的帮助字符串
- primary_key:定义字段是否为主键,True 或 False
- unique:是否为字段定义的唯一约束
- unique_for_date
- unique_for_month
- unique_for_year
- verbose_name:一个字段的可读性更高的名称。如果用户没有设定冗余名称字段,Django 会自动将该字段属性名中的下划线转换为空格,并用它来创建冗余名称。可以参照Verbose field names.
- validators:该字段将要运行的一个 Validator 的列表。更多信息参见Validators 的文档。
- 无名参数:设置该字段在 HTML 页面中的人性化名称
参考链接:https://docs.djangoproject.com/en/2.0/ref/models/fields/
Django 模型之自定义字段
Django 的官方提供了很多的 Field,但是有时候还是不能满足我们的需求,不过 Django 提供了自定义 Field 的方法。由于不常用,这里不做详细介绍。
示例代码:https://djangosnippets.org/snippets/2865/
参考链接:https://docs.djangoproject.com/en/2.0/howto/custom-model-fields/
Django 模型之关系设置
利用数据表之间的关系进行数据建模和业务开发是关系数据库最主要的功能。Django 模型的 3 种关系模型(1:1、1:N、M:N)都有强大的支持。
一对一关系
在 SQL 语言中,一对一关系通过在两个表之间相同的主键来完成。在 Django 模型层可以任意一个模型中定义 OneToOneField 字段。
from django.db import models
class Account(models.Model):
user_name = models.CharField(max_length=80)
password = models.CharField(max_length=255)
reg_date = models.DateField()
class Contact(models.Model):
account = models.OneToOneField(
Account,
on_delete=models.CASCADE,
primary_key=True
)
zip_code = models.CharField(max_length=10)
address = models.CharField(max_length=80)
mobile = models.CharField(max_length=20)
生成的 SQL 为:
BEGIN;
--
-- Create model Account
--
CREATE TABLE "app_account" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "user_name" varchar(80) NOT NULL, "password" varchar(255) NOT NULL, "reg_date" date NOT NULL);
--
-- Create model Contact
--
CREATE TABLE "app_contact" ("account_id" integer NOT NULL PRIMARY KEY REFERENCES "app_account" ("id") DEFERRABLE INITIALLY DEFERRED, "zip_code" varchar(10) NOT NULL, "address" varchar(80) NOT NULL, "mobile" varchar(20) NOT NULL);
COMMIT;
通过上面的代码可以看到:
- 两个模型关系通过 Contact 模型中的 account 字段进行定义
- OneToOneField 参数定义为:class OneToOneField(to, on_delete, parent_link=False, **options)
- 第一个参数为关联的类名
- 第二个 on_delete 的值由 db.models.deletion 定义,具体有:
- CASCADE:模拟 SQL 语言中的 ON DELETE CASCADE 约束,将定义有外键的模型对象同时删除(默认操作,且最常用)
- DO_NOTHING:啥都不干
- PROTECT: 阻止删除操作,执行删除时,会抛出 ProtectedError 异常
- SET:设置为一个传递给 SET() 的值或者一个回调函数的返回值。
SET_DEFAULT: 将外键字段设为默认值。只有当字段设置了 default 参数时,方可使用。
- SET_NULL:将外键字段设为 null,只有当字段设置了 null=True 时,方可使用该值。
一对多关系
在 SQL 语言中,1:N 关系通过在“附表”中设置到“主表”的外键引用来完成。在 Django 模型层可以用 models.ForeignKey 类型的字段定义外键。
上面的案例中,如果是 Account 与 Concact 是一对多的关系,则只需修改代码为:
from django.db import models
class Account(models.Model):
user_name = models.CharField(max_length=80)
password = models.CharField(max_length=255)
reg_date = models.DateField()
class Contact(models.Model):
account = models.ForeignKey(
Account,
on_delete=models.CASCADE
)
zip_code = models.CharField(max_length=10)
address = models.CharField(max_length=80)
mobile = models.CharField(max_length=20)
生成的 SQL 语句如下:
BEGIN;
--
-- Create model Account
--
CREATE TABLE "app_account" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "user_name" varchar(80) NOT NULL, "password" varchar(255) NOT NULL, "reg_date" date NOT NULL);
--
-- Create model Contact
--
CREATE TABLE "app_contact" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "zip_code" varchar(10) NOT NULL, "address" varchar(80) NOT NULL, "mobile" varchar(20) NOT NULL, "account_id" integer NOT NULL REFERENCES "app_account" ("id") DEFERRABLE INITIALLY DEFERRED);
CREATE INDEX "app_contact_account_id_64f8cb42" ON "app_contact" ("account_id");
COMMIT;
多对多关系
在 SQL 语言中,M:N 关系通过建立一个中间关系表来完成,该中间表中定义了到两个主表的外键。所以在 Django 的模型中,开发者也可以选择用来两个 1:N 关系来定义 M:N 关系。同时 Django 模型定义了一种更直接的 M:N 关系建模方式,即在两个模型中的任意一个中定义 models.ManyToManyField 类型的字段。
上面的案例中,如果是 Account 与 Concact 是多对多的关系,则只需修改代码为:
from django.db import models
class Account(models.Model):
user_name = models.CharField(max_length=80)
password = models.CharField(max_length=255)
reg_date = models.DateField()
class Contact(models.Model):
account = models.ManyToManyField(Account)
zip_code = models.CharField(max_length=10)
address = models.CharField(max_length=80)
mobile = models.CharField(max_length=20)
生成的 SQL 为:
BEGIN;
--
-- Create model Account
--
CREATE TABLE "app_account" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "user_name" varchar(80) NOT NULL, "password" varchar(255) NOT NULL, "reg_date" date NOT NULL);
--
-- Create model Contact
--
CREATE TABLE "app_contact" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "zip_code" varchar(10) NOT NULL, "address" varchar(80) NOT NULL, "mobile" varchar(20) NOT NULL);
CREATE TABLE "app_contact_account" ("id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "contact_id" integer NOT NULL REFERENCES "app_contact" ("id") DEFERRABLE INITIALLY DEFERRED, "account_id" integer NOT NULL REFERENCES "app_account" ("id") DEFERRABLE INITIALLY DEFERRED);
CREATE UNIQUE INDEX app_contact_account_contact_id_account_id_17ac7ce6_uniq ON "app_contact_account" ("contact_id", "account_id");
CREATE INDEX "app_contact_account_contact_id_f253b307" ON "app_contact_account" ("contact_id");
CREATE INDEX "app_contact_account_account_id_fed8aab3" ON "app_contact_account" ("account_id");
COMMIT;
Django 模型之面向对象 ORM
Django 模型层 ORM 的一个强大之处是对模型继承的支持,该技术将 Python 面向对象编程方法与数据库面向关系表的数据结构有机的结合。Django 支持三种风格的模型继承:
- 抽象类继承:父类继承字 Model,但不会在底层数据库中生成相应的数据表。父类的属性列存储在其子类的数据表中。
- 多表继承:多表继承的每个模型类都在底层数据库中生成相应的数据表管理数据。
- 代理模式继承:父类用于在底层数据库中管理数据表,而子类不定义数据列,只定义查询数据库集的排序方式等元数据。
抽象类继承
抽象基类的定义通过在模型的 Meta 中定义属性 abstract=True 来实现。
from django.db import models
class MessageBase(models.Model):
id = models.AutoField(primary_key=True)
content = models.CharField(max_length=100)
user_name = models.CharField(max_length=80)
pub_date = models.DateField()
class Meta:
abstract = True
class Moment(MessageBase):
headline = models.CharField(max_length=50)
class Comment(MessageBase):
score = models.IntegerField()
本例在数据库中实际生成 2 个数据表:
- 数据表 moment:有 id、content、user_name、pub_date、headline 五个字段
数据表 comment:有 id、content、user_name、pub_date、score 五个字段
多表继承
在多表继承中,无论是父表还是子表都会用数据库中的相对应的数据表维护模型数据,父类的字段不会重复地在多个子类的相关数据表中定义。多表继承不需要特殊的关键字。
from django.db import models
class MessageBase(models.Model):
id = models.AutoField(primary_key=True)
content = models.CharField(max_length=100)
user_name = models.CharField(max_length=80)
pub_date = models.DateField()
class Moment(MessageBase):
headline = models.CharField(max_length=50)
class Comment(MessageBase):
score = models.IntegerField()
本例在数据库中实际生成 3 个数据表:
- 数据表 messagebase:有 id、content、user_name、pub_date 四个字段
- 数据表 monent:有 messagebase_ptr_id、headline 两个字段
- 数据表 comment:有 messagebase_ptr_id、score 两个字段
代理模型继承
代理模型继承中子类只用于管理父类的数据,而不实际存储数据。代理模型继承通过在子类的 Meta 中定义 proxy=True 属性来实现。
from django.db import models
class Moment(models.Model):
id = models.AutoField(primary_key=True)
headline = models.CharField(max_length=50)
content = models.CharField(max_length=100)
user_name = models.CharField(max_length=80)
pub_date = models.DateField()
class OrderedMoment(Moment):
class Meta:
proxy = True
ordering = ["-pub_date"]
使用代理模型继承的原因是子类中的新特征不会影响父类型模型机器已有代码的行为。


