Scikit-Opt 简介
scikit-opt 是一个封装了多种启发式算法的 Python 代码库,可以用于解决优化问题。虽然它的名字与著名的机器学习库 scikit-learn 相似,但两者并没有直接的隶属关系。
核心特点:
- 多算法支持:scikit-opt 提供了遗传算法、粒子群优化、模拟退火、蚁群算法等多种常见的优化算法。
- 易于扩展:用户可以根据需要轻松地自定义算法或者修改现有的算法。
- 简洁的 API:该库尽量保持接口简洁,使得即使是优化领域的初学者也能够快速上手。
启发式算法
启发式算法(Heuristic Algorithm)是一类用于解决复杂优化问题的算法,这些问题的最优解往往难以在合理时间内通过精确算法找到,或者最优解的计算复杂度过高。启发式算法通过采用一些经验性的规则和策略,在合理的时间内找到问题的近似最优解或满意解。
启发式算法的特点包括:
- 不依赖于严格的数学理论和精确的求解过程。
- 通常利用问题的一些特性和经验规则来指导搜索过程。
- 能够在相对较短的时间内找到一个可行解,虽然可能不是最优的,但在很多实际应用中已经足够好。
启发式算法的优势在于:
- 对于复杂的、大规模的问题,能够快速给出解决方案。
- 可以处理那些难以用精确算法求解或根本无法用精确算法求解的问题。
常见的启发式算法类型
- 局部搜索算法
- 梯度下降法:在连续空间中寻找局部最小值的方法。
- 爬山法:从当前解开始,逐步改进解的质量,直到达到局部最优解。
- 全局搜索算法
- 模拟退火:通过模拟物质冷却过程中的退火现象,允许一定程度的”上坡”移动,从而避免陷入局部最优解。
- 遗传算法:受自然选择和遗传学原理启发,通过选择、交叉和变异操作生成新的解集。
- 粒子群优化 (PSO):模拟鸟群觅食行为,通过粒子之间的相互作用来探索解空间。
- 差分进化 (DE):类似于遗传算法,但使用差分向量来指导搜索方向。
- 其他启发式算法
- 禁忌搜索:通过引入禁忌列表来防止算法过早收敛到局部最优解。
- 蚁群优化 (ACO):模拟蚂蚁寻找食物路径的行为,利用信息素来引导搜索。
- 蜂群算法:模拟蜜蜂群体中的搜索行为,通过蜜蜂之间的信息交流来探索解空间。
应用领域
启发式算法被广泛应用于各种领域,包括但不限于:
- 物流与运输:路线规划、车辆调度等问题。
- 生产调度:工厂生产线的优化调度。
- 网络优化:通信网络的路由优化。
- 机器学习:特征选择、超参数调优等。
- 生物信息学:基因序列比对、蛋白质结构预测等。
Scikit-Opt 中的启发式算法
Scikit-Opt 支持多种启发式算法,包括但不限于以下几种:
- 差分进化算法 (Differential Evolution):通过模拟生物进化过程中的变异和自然选择机制来寻找最优解。
- 遗传算法 (Genetic Algorithm):模拟自然选择和遗传机制,通过种群中个体的变异、交叉和选择来优化问题。
- 粒子群算法 (Particle Swarm Optimization):模拟鸟群或鱼群中个体的群体行为,通过个体间信息共享来搜索最优解。
- 模拟退火算法 (Simulated Annealing):受金属退火过程启发,通过接受状态降低的解的概率来在搜索空间中跳出局部最优解。
- 蚁群算法 (Ant Colony Optimization):模拟蚂蚁寻找食物的行为,通过信息素的沉积和蒸发来寻找优化路径。
- 免疫优化算法 (Immune Optimization Algorithm):基于免疫系统的进化过程,通过模拟抗体的生成和免疫反应来优化问题。
- 人工鱼群算法 (Artificial Fish-Swarm Algorithm):模拟鱼群觅食行为,通过个体之间的位置调整和信息共享来搜索最优解。
这些算法都属于启发式算法的范畴,适用于复杂的优化问题,如函数优化、参数调优等。scikit-opt 提供了这些算法的 Python 实现,并且通常还包括了对不同问题的适应性调整和优化参数的支持,使得用户能够更方便地应用这些算法进行问题求解。
以下表格包含了这些算法的优缺点和适用环境:
| 算法名称 | 优点 | 缺点 | 适用环境 |
| 差分进化算法 | 鲁棒性强,适用于多种优化问题,收敛速度快 | 参数设置对算法性能影响较大,容易陷入局部最优 | 连续优化问题,特别是高维空间的优化问题 |
| 遗传算法 | 具有全局搜索能力,适用于复杂的优化问题 | 参数设置复杂,收敛速度较慢 | 组合优化问题,如旅行商问题、调度问题等 |
| 粒子群算法 | 实现简单,收敛速度快,适用于多模态优化问题 | 易陷入局部最优,参数设置对算法性能影响较大 | 连续优化问题,特别是多模态优化问题 |
| 模拟退火算法 | 具有跳出局部最优的能力,适用于复杂优化问题 | 参数设置复杂,收敛速度较慢 | 组合优化问题,如电路设计、图像处理等 |
| 蚁群算法 | 适用于离散优化问题,具有分布式计算的特点 | 参数设置复杂,收敛速度较慢 | 组合优化问题,如旅行商问题、车辆路径问题等 |
| 免疫优化算法 | 具有较强的鲁棒性和自适应性,适用于动态优化问题 | 算法复杂度较高,参数设置较困难 | 组合优化问题,如特征选择、数据分类等 |
| 鱼群算法 | 实现简单,具有较好的并行性,适用于多目标优化问题 | 易陷入局部最优,参数设置对算法性能影响较大 | 连续优化问题,特别是多目标优化问题 |
启发式算法详解
差分进化算法(Differential Evolution, DE)
差分进化算法(Differential Evolution, DE)是一种全局优化的启发式算法,由 Rainer Storn 和 Kenneth Price 在 1997 年提出。DE 特别适用于连续空间中的优化问题,常用于解决非线性、多模态、带约束的优化问题。它的基本思想源于生物进化论中的遗传变异和自然选择原理,通过迭代过程搜索解空间,寻找问题的最优解或近似最优解。
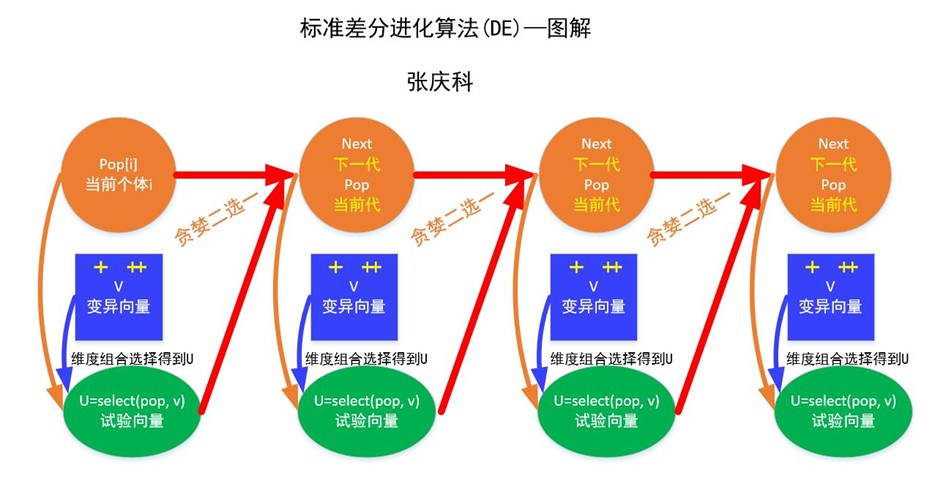
差分进化算法的核心在于其简单而又强大的变异策略,以及高效的群体搜索机制。算法的基本步骤包括初始化、变异、交叉(也称为重组)和选择四个阶段。
- 初始化:首先,随机生成一个初始解群体,每个解代表问题的一个可能解,通常表示为一个向量。
- 变异:对于每一个解(称为目标解),随机选择群体中的另外三个解(称为差分向量)。然后,计算这三个解的加权差分,以此差分向量与目标解相加,生成一个新的试解。差分的计算公式通常为:$V_i = X_{r1} + F \cdot (X_{r2} – X_{r3})$,其中 $V_i$ 是变异个体,$X_{r1}$, $X_{r2}$, $X_{r3}$ 是随机选择的三个不同个体,F 是缩放因子,用于控制变异的幅度。
- 交叉:以一定概率(通常称为交叉率 CR)决定目标解的各个分量是否被试解中的对应分量所替代。具体来说,对于每个分量,如果随机数小于 CR,则该分量取自试解,否则保持不变。这个过程保证了解的多样性。
- 选择:将变异和交叉后得到的新解与原目标解进行比较,根据目标函数值(对于最小化问题,值越小越好;对于最大化问题则相反),保留更好的解进入下一代群体。这个过程体现了“适者生存”的自然选择原则。
DE 算法的主要控制参数包括:
- 种群大小(NP):反映了算法中种群信息量的大小。NP 值越大,种群信息越丰富,但计算量也随之增加;反之,则可能导致种群多样性受限,影响全局寻优能力。
- 缩放因子(F):影响算法的全局搜索能力。F 值越大,算法越能跳出局部极小点,但收敛速度会变慢;F 值越小,算法的局部搜索能力更好。
- 交叉概率(CR):反映了交叉操作中信息交换的程度。CR 值越大,信息量交换的程度越大,有助于增加种群的多样性;反之,则可能导致种群多样性快速减小。
差分进化算法的基本流程可以概括为以下几个步骤:
- 确定差分进化算法的控制参数和适应度函数。
- 随机产生初始种群,并进化代数计数器置为 1。
- 对初始种群中的每个个体计算适应度值。
- 判断是否达到终止条件(如最大进化代数)或满足其他停止准则。若否,则执行下一步;若是,则输出最优解并终止算法。
- 对当前种群进行变异和交叉操作,生成试验种群。
- 对试验种群中的每个个体计算适应度值,并与相应的目标个体进行比较,执行选择操作。
- 将选出的个体作为下一代种群,进化代数计数器加 1,回到步骤 4 继续执行。
差分进化算法的优点包括:
- 简单易实现:算法的原理相对简单,易于理解和实现。
- 全局搜索能力:能够在搜索空间中进行全局搜索,找到较优的解。
- 鲁棒性:对初始种群的要求较低,对噪声和异常值具有一定的鲁棒性。
- 多模态搜索:适用于具有多个最优解的问题,可以同时搜索多个最优区域。
然而,差分进化算法也存在一些局限性:
- 搜索效率:在某些情况下,算法可能会陷入局部最优,而不是找到全局最优解。
- 控制参数:需要选择合适的控制参数,如缩放因子、变异因子等,以获得较好的性能。
- 计算复杂度:随着问题规模的增加,算法的计算复杂度可能会增加。
Scikit-Opt 实现:提供了 DE 类的 Python 实现,并支持通过参数设置调整算法的行为,以适应不同问题的需要。
# pip install scikit-opt
import numpy as np
from sko.DE import DE
# 定义目标函数,这里使用 Sphere 函数作为示例
def sphere_function(x):
return sum(x**2)
# 设置差分进化算法的参数
population_size = 50 # 种群大小
dimension = 5 # 变量维度
max_iter = 100 # 最大迭代次数
lb = [-5.12] * dimension # 每个变量的下界
ub = [5.12] * dimension # 每个变量的上界
# 创建差分进化算法的实例
de = DE(func=sphere_function, n_dim=dimension, size_pop=population_size, max_iter=max_iter, lb=lb, ub=ub)
# 执行优化
best_x, best_y = de.run()
# 输出结果
print('Best solution:', best_x)
print('Best objective value:', best_y)
# 可视化收敛过程
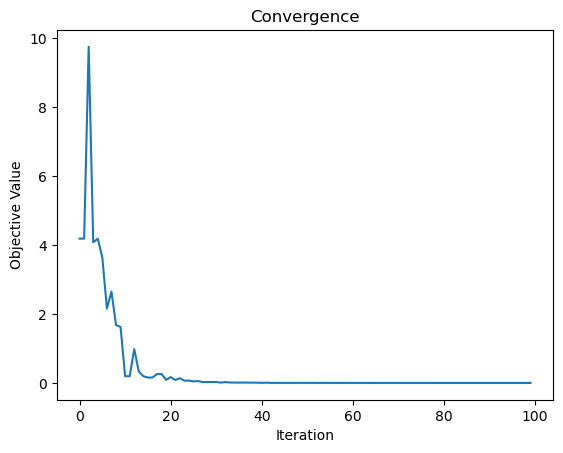
import matplotlib.pyplot as plt
plt.plot(de.generation_best_Y)
plt.xlabel('Iteration')
plt.ylabel('Objective Value')
plt.title('Convergence')
plt.show()
遗传算法(Genetic Algorithm, GA)
遗传算法(Genetic Algorithm, GA)是一种基于自然选择和遗传学原理的优化算法。它是一种搜索和优化技术,主要用于解决复杂的优化问题。遗传算法模拟了生物进化的过程,通过选择、交叉、变异等操作逐步逼近最优解。

基本概念
- 个体(Individual):在遗传算法中,一个个体代表一个可能的解。通常用一个字符串(可以是二进制、实数、符号等)来表示。
- 种群(Population):一组个体组成一个种群。算法通过在种群中寻找最优解来进行优化。
- 适应度函数(Fitness Function):用于评价个体优劣的函数。适应度函数为每个个体分配一个适应度值,表示其解决问题的能力。
- 选择(Selection):选择过程根据个体的适应度值来决定哪些个体能够参与繁殖。常见的选择方法有轮盘赌选择、锦标赛选择和排名选择。
- 交叉(Crossover):也称为重组,两个个体交换部分基因以生成新个体。交叉操作模拟了自然界中的生物繁殖过程。
- 变异(Mutation):对个体的基因进行随机修改,以引入多样性。变异操作防止种群陷入局部最优。
- 迭代(Iteration):遗传算法通过多次迭代逐步接近最优解。在每次迭代中,种群经历选择、交叉和变异,产生新一代的个体。
遗传算法的基本思想是将解空间中的每一个可能解表示为一个“个体”,这些个体构成一个“种群”。通过模拟自然选择的过程,优秀的个体有更大的机会被选中进行繁殖,从而产生下一代个体。
遗传算法通常包含以下几个步骤:
- 初始化种群:随机生成一定数量的个体(解决方案),形成初始种群。
- 适应度评估:根据适应度函数(目标函数)评估每个个体的优劣。适应度函数用于衡量个体的“好坏”,通常与优化目标直接相关。
- 选择:根据个体的适应度,选择出优秀的个体以进行繁殖。常用的选择方法包括轮盘赌选择、锦标赛选择等。
- 交叉:选择的个体通过交叉操作(也称为重组)产生新的个体。交叉操作模拟了生物的遗传过程,通常涉及将两个父代个体的基因组合成一个或多个子代个体。
- 变异:对新生成的个体进行小概率的变异,以增加种群的多样性,避免陷入局部最优解。变异操作可以是随机改变个体基因的一部分。
- 替换:用新生成的个体替换旧的个体,形成新的种群。
- 终止条件:检查是否满足终止条件(如达到最大迭代次数、适应度达到某一阈值等),如果满足则停止算法,否则返回步骤 2。
优点
- 全局搜索能力强:遗传算法通过种群搜索和多样性维护,能够有效避免陷入局部最优。
- 适应性强:适用于各种类型的优化问题,包括连续和离散问题。
- 无需梯度信息:遗传算法不依赖于问题的梯度信息,因此可以应用于非连续或不可微的函数。
缺点
- 计算量大:由于涉及大量个体的适应度评估,计算成本较高。
- 收敛速度慢:在某些问题上,遗传算法可能需要较多代数才能找到最优解。
- 参数选择敏感:交叉率、变异率等参数的选择对算法性能影响较大,需要根据具体问题进行调优。
遗传算法已被广泛应用于工程优化、机器学习、经济调度、神经网络训练等领域。通过与其他算法结合(如粒子群优化、模拟退火等),可以进一步提高其效率和效果。
注意事项
- 参数选择:遗传算法的性能对选择的参数(如种群规模、交叉率、变异率等)敏感,需要根据具体问题进行调试。
- 适应度函数设计:适应度函数的设计直接影响算法的效果,需要根据优化目标合理设置。
早熟收敛:在某些情况下,遗传算法可能会过早收敛到局部最优解,因此需要合理设计变异和选择策略,以保持种群的多样性。
Scikit-Opt实现:提供GA类实现遗传算法,用户可以配置交叉、变异和选择操作的相关参数。
import numpy as np
from sko.GA import GA
# 定义目标函数,这里使用Rastrigin函数作为示例
def rastrigin_function(x):
A = 10
return A * len(x) + sum([(xi ** 2 - A * np.cos(2 * np.pi * xi)) for xi in x])
# 设置遗传算法的参数
population_size = 50 # 种群大小
dimension = 5 # 变量维度
max_iter = 100 # 最大迭代次数
lb = [-5.12] * dimension # 每个变量的下界
ub = [5.12] * dimension # 每个变量的上界
# 创建遗传算法的实例
ga = GA(func=rastrigin_function, n_dim=dimension, size_pop=population_size, max_iter=max_iter, lb=lb, ub=ub, prob_mut=0.01)
# 执行优化
best_x, best_y = ga.run()
# 输出结果
print('Best solution:', best_x)
print('Best objective value:', best_y)
# 可视化收敛过程
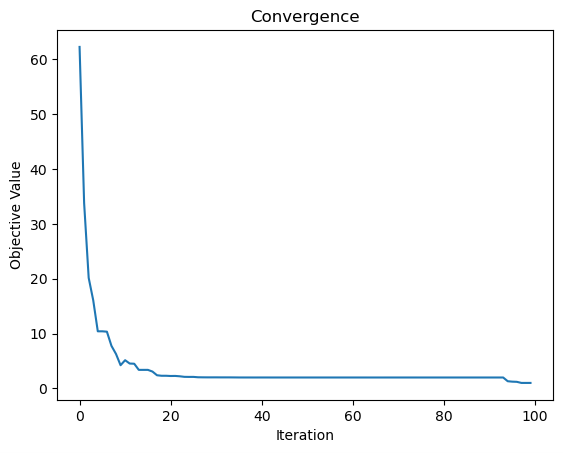
import matplotlib.pyplot as plt
plt.plot(ga.generation_best_Y)
plt.xlabel('Iteration')
plt.ylabel('Objective Value')
plt.title('Convergence')
plt.show()
粒子群算法(Particle Swarm Optimization, PSO)
粒子群优化算法(Particle Swarm Optimization, PSO)是一种基于群体智能的优化算法,由Kennedy和Eberhart于1995年提出。它受自然界中鸟群或鱼群行为的启发,模拟了个体之间的信息共享和协作,从而在问题的搜索空间中寻找最优解。

首先讲个小故事,说一说通俗理解:一群分散的鸟儿在随机地飞行觅食,它们不知道食物所在的具体位置,在觅食过程中,每只小鸟都会记录自己飞行位置。突然,其中某一只小鸟A发现好多玉米,于是就喊:”快来,我这里有好多食物!”,然而,其他小鸟都只发现了零零星星的几个玉米粒。于是,每个小鸟在飞行的时候就有了一个指导的方向(往小鸟A的位置飞),但是,每个小鸟都有不忍心放弃当前努力搜寻过的位置(小鸟们心想:我这里刚才也找到点玉米粒,再继续找找说不定比你还要多)。因此,它们最终决定结合自身的经验和整个群体的经验,调整自己的飞行速度和所在位置,不断地寻找更加接近食物的位置,最终使得群体聚集到食物位置。
PSO算法通过模拟一群粒子在搜索空间中移动来找到最优解。每个粒子代表一个潜在的解,它具有位置和速度两个属性。粒子通过不断更新其位置和速度来搜索最优解,更新的过程依赖于三个主要因素:
- 个体记忆(Cognitive Component):粒子自身的历史最佳位置。
- 社会影响(Social Component):群体中的全局最佳位置。
- 惯性权重(Inertia Weight):粒子之前的速度。
粒子群算法的基本概念
- 粒子:每个粒子代表一个潜在解,具有位置和速度两个属性。位置表示粒子在搜索空间中的当前解,速度决定了粒子在下一次迭代中的移动方向和距离。
- 种群:由多个粒子组成的群体,整个群体在搜索空间中共同工作,以寻找最优解。
- 适应度:每个粒子的适应度是通过目标函数评估的,适应度越高,表示该解越优。
算法原理
粒子群算法中,每个优化问题的潜在解都被视为搜索空间中的一个”粒子”。每个粒子具有一个位置和一个速度,这些粒子在解空间中移动以寻找最优解。每个粒子都有以下属性:
- 位置(Position):表示解空间中的一个点,即当前的潜在解。
- 速度(Velocity):控制粒子移动的方向和距离。
- 个体最优(Pbest):粒子在迄今为止搜索过程中遇到的最好位置。
- 全局最优(Gbest):整个群体中所有粒子遇到的最好位置。
算法步骤
- 初始化:在问题的搜索空间中随机生成一群粒子,每个粒子有一个随机的初始位置和速度。
- 评估:计算每个粒子的适应度(即目标函数值),并更新个体最佳位置和全局最佳位置。
- 更新速度和位置:
- 更新粒子的速度:结合个体记忆、社会影响和惯性权重来计算新的速度。
- 更新粒子的位置:根据新的速度调整粒子的位置。
- 迭代:重复评估和更新过程,直到达到停止条件(如达到最大迭代次数或找到满意的解)。
数学公式
- 速度更新公式:$v_{i}(t+1)=w \cdot v_{i}(t)+c_1 \cdot r_1 \cdot (p_{i}-x_{i}(t))+c_2 \cdot r_2 \cdot (g-x_{i}(t))$其中:
- $v_{i}(t)$是粒子$i$在时间$t$的速度。
- $w$是惯性权重。
- $c_1,c_2$是学习因子,通常为常数。
- $r_1,r_2$是[0,1]之间的随机数。
- $p_{i}$是粒子$i$的个体最佳位置。
- $g$是全局最佳位置。
- $x_{i}(t)$是粒子$i$在时间$t$的位置。
- 位置更新公式:$x_{i}(t+1)=x_{i}(t)+v_{i}(t+1)$
算法特点:
优点
- 简单易实现:算法原理直观,代码实现相对简单。
- 全局寻优能力:通过全局最优和局部最优的结合,具有较强的全局搜索能力。
- 参数较少:相较于其他优化算法,PSO的参数较少,易于调整。
缺点
- 容易早熟收敛:在搜索过程中可能会过早地收敛到局部最优解。
- 参数敏感:某些参数(如惯性权重)的选择对算法性能影响较大,需要仔细调整。
Scikit-Opt实现:提供了PSO类用于粒子群算法的Python实现,包括位置更新、速度计算和适应度评估等功能。
```python
import numpy as np
from sko.PSO import PSO
# 定义目标函数,这里使用 Sphere 函数作为示例
def sphere_function(x):
return sum(x**2)
# 设置粒子群算法的参数
population_size = 50 # 粒子数量
dimension = 5 # 变量维度
max_iter = 100 # 最大迭代次数
lb = [-5.12] * dimension # 每个变量的下界
ub = [5.12] * dimension # 每个变量的上界
# 创建粒子群算法的实例
pso = PSO(func=sphere_function, n_dim=dimension, pop=population_size, max_iter=max_iter, lb=lb, ub=ub, w=0.8, c1=0.5, c2=0.5)
# 执行优化
best_x, best_y = pso.run()
# 输出结果
print('Best solution:', best_x)
print('Best objective value:', best_y)
# 可视化收敛过程
import matplotlib.pyplot as plt
plt.plot(pso.gbest_y_hist)
plt.xlabel('Iteration')
plt.ylabel('Objective Value')
plt.title('Convergence')
plt.show()
模拟退火算法(Simulated Annealing, SA)
模拟退火算法(Simulated Annealing,SA)是一种用于全局优化问题的随机搜索算法,灵感来源于金属退火过程。在物理学中,退火是一种通过加热和缓慢冷却来减少材料内部缺陷的过程,从而使材料达到最低能量状态。
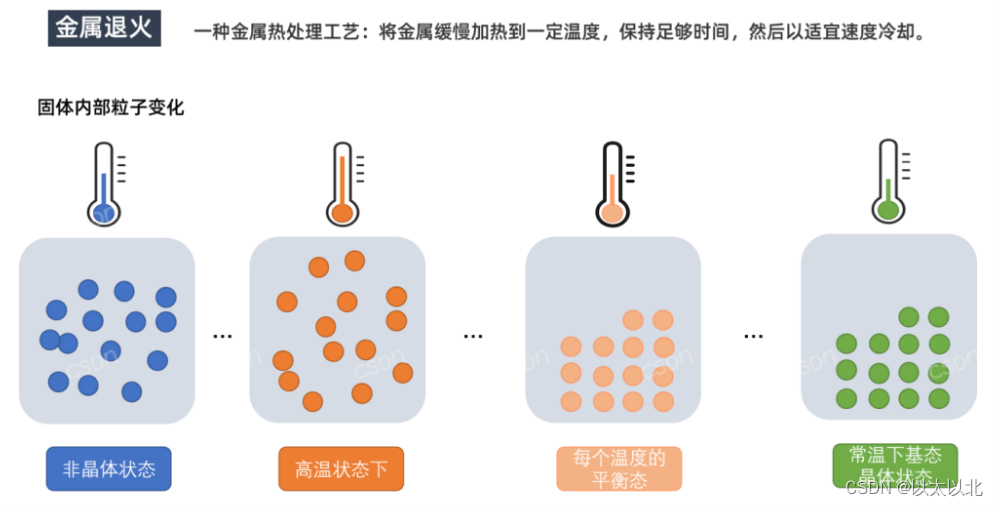
基本原理
模拟退火算法通过模拟这个物理过程来寻找问题的最优解。其基本思想是:
- 初始状态:从一个初始解出发,通常是随机生成的。
- 温度控制:设定一个初始“温度”,温度在算法运行过程中逐渐降低。温度的高低影响接受新解的概率。
- 邻域搜索:在当前解的邻域中随机选择一个新解。
- 接受准则:
- 如果新解比当前解更优,则接受新解。
- 如果新解较差,则以一定概率接受新解,这个概率通常与当前温度和解的优劣有关。这一机制允许算法跳出局部最优解,从而增加找到全局最优解的可能性。
- 温度降温:随着迭代的进行,逐渐降低温度,减少接受较差解的概率,使算法逐渐收敛。
- 终止条件:当达到一定的迭代次数或温度降到某个阈值时,算法停止。
关键要素
- 温度调度:选择合适的温度下降策略是算法性能的关键。常见的降温策略包括线性降温、指数降温等。
- 邻域结构:定义如何从当前解生成新解,即如何在解空间中移动。
- 接受概率:通常采用 Metropolis 准则来计算接受概率。
算法步骤
- 初始化:
- 确定初始温度 T(高),初始解状态 $s$,并计算该状态的能量 $E(s)$。
- 设定终止温度和冷却速率。
- 循环以下步骤直到温度低于终止温度:
- 在 s 的邻域内随机选择一个候选解 $s’$。
- 计算新解 $s’$ 的能量 $E(s’)$。
- 计算能量差 $\Delta E = E(s’) – E(s)$。
- 如果 $\Delta E< 0$,则接受 $s'$ 作为新的当前解。
- 如果 $\Delta E \geq 0$,则以一定的概率接受 $s’$ 作为新的当前解,这一概率为 $e^{-\Delta E/T}$。
- 降低温度 (T)。
- 冷却过程:
- 温度 $T$ 按照一定的冷却速度降低,例如 $T = \alpha T$,其中 $\alpha$ 是一个小于 1 的常数。
- 终止:
- 当温度低于某个阈值或已达到预定的迭代次数后停止。
优点与缺点
优点:
- 能够避免陷入局部最优解,具有较强的全局搜索能力。
- 实现简单,易于理解。
缺点:
- 收敛速度较慢,尤其是在温度较高时。
- 参数调节(如初始温度、降温速度)对算法效果有较大影响。
注意事项
虽然模拟退火算法具有较好的全局搜索能力,但它可能需要较长的时间来找到最优解,特别是在高维优化问题中。因此,在实际应用中,往往需要结合其他优化技术或参数调整策略来提高算法的效率和效果。
模拟退火算法因其简单易懂、实现方便以及在解决某些复杂问题上的优势而被广泛应用于各个领域。
Scikit-Opt 实现:在 Scikit-Opt 中,SA 类实现模拟退火算法,提供冷却机制(降温)和接受差解的规则等功能。
import numpy as np
from sko.SA import SAFast
import matplotlib.pyplot as plt
# 定义目标函数,这里使用 Rastrigin 函数作为示例
history = []
def rastrigin_function(x):
A = 10
value = A * len(x) + sum([(xi**2 - A * np.cos(2 * np.pi * xi)) for xi in x])
history.append(value)
return value
# 设置模拟退火算法的参数
dimension = 5 # 变量维度
lb = [-5.12] * dimension # 每个变量的下界
ub = [5.12] * dimension # 每个变量的上界
# 创建模拟退火算法的实例
sa = SAFast(func=rastrigin_function, x0=np.random.uniform(low=lb, high=ub, size=dimension))
# 执行优化
best_x, best_y = sa.run()
# 输出结果
print('Best solution:', best_x)
print('Best objective value:', best_y)
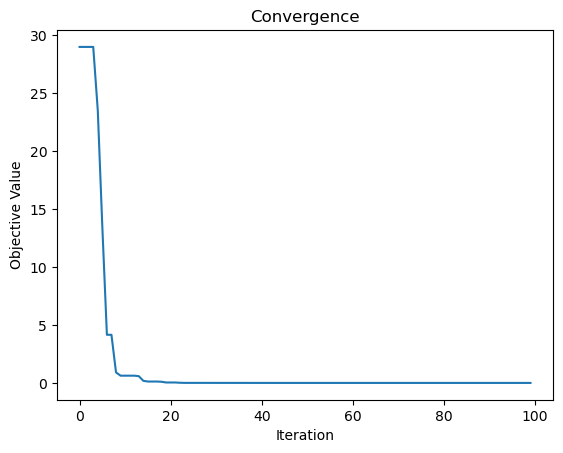
# 可视化收敛过程
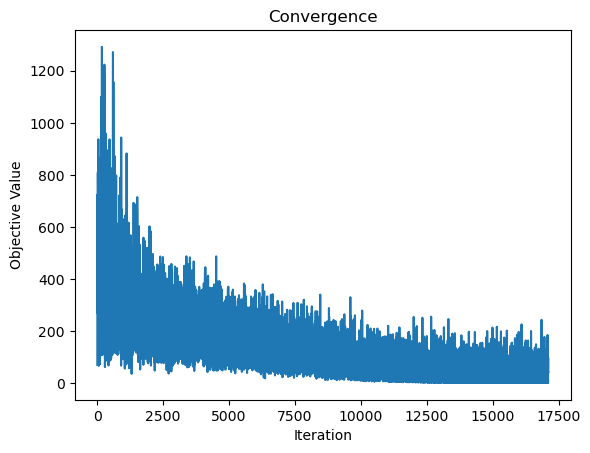
plt.plot(history)
plt.xlabel('Iteration')
plt.ylabel('Objective Value')
plt.title('Convergence')
plt.show()
蚁群算法(Ant Colony Optimization, ACO)
蚁群算法(Ant Colony Optimization, ACO)是一种受自然界蚂蚁觅食行为启发的启发式优化算法,最早由 Marco Dorigo 在 20 世纪 90 年代初提出。它是一种用于解决组合优化问题的元启发式算法,尤其适用于解决旅行商问题(TSP)、车辆路径问题(VRP)等经典的 NP 难问题。
基本原理
蚁群算法模拟了蚂蚁在寻找食物时通过信息素(Pheromone)进行通信的过程。在自然界中,蚂蚁通过在路径上释放信息素来标记路径,其他蚂蚁会倾向于跟随信息素浓度较高的路径,从而逐渐形成最优路径。
算法步骤
- 初始化:
- 在问题的解空间中随机放置一定数量的蚂蚁。
- “`初始化所有路径上的信息素浓度为一个较小的正数。
- 构建解:
- 每只蚂蚁根据某种概率规则选择下一步的路径,通常是根据路径上的信息素浓度和启发式信息(如距离、成本等)来选择。
- 这种选择过程通常使用一个带权重的随机函数来实现。
- 更新信息素:
- 在所有蚂蚁完成路径选择后,根据每只蚂蚁找到的路径质量(如路径长度、路径成本等)来更新路径上的信息素浓度。
- 信息素的更新包括信息素的挥发和新信息素的沉积。通常挥发因子用于避免过早收敛。
- 迭代:
- 重复步骤2和3,直到达到某个停止条件(如达到最大迭代次数或解的质量不再显著提高)。
数学模型
蚁群算法的数学模型通常包括状态转移概率和信息素更新公式。
- 状态转移概率:蚂蚁从城市i转移到城市j的概率通常表示为$p_{ij}(t)=\frac{[\tau_{ij}(t)^\alpha\cdot\eta_{ij}^\beta]}{\sum_{k\in\text{allowed}_k}[\tau_{ik}(t)^\alpha\cdot\eta_{ik}^\beta]}$其中,$\tau_{ij}(t)$表示时刻t路径ij上的信息素浓度,$\eta_{ij}$表示启发式信息(如距离的倒数),$\alpha$和$\beta$是分别表示信息素和启发式信息的相对重要程度的参数。
- 信息素更新公式:信息素的更新通常表示为$\tau_{ij}(t+1)=(1-\rho)\cdot\tau_{ij}(t)+\Delta\tau_{ij}$其中,$\rho$是信息素蒸发系数,$\Delta\tau_{ij}$是本次迭代中路径ij上信息素的增量,由蚂蚁释放的信息素决定。
关键要素
- 信息素更新策略:包括信息素挥发和沉积。信息素挥发是为了防止过多依赖当前最优解而导致的过早收敛;信息素沉积则是为了鼓励那些表现较好的路径。
- 启发式信息:通常是基于问题的特定属性(如距离的倒数)来指导蚂蚁的选择。
- 概率选择规则:通常采用如轮盘赌选择法来决定蚂蚁的下一步路径。
优点
- 并行性:蚁群算法天然适合并行计算,因为每只蚂蚁可以独立地构建解。
- 鲁棒性:对于动态变化的问题,蚁群算法表现出较好的适应性。
缺点
- 收敛速度慢:在某些问题上,蚁群算法可能收敛较慢。
- 参数敏感:算法性能对参数(如信息素挥发系数、信息素影响因子等)较为敏感,需要进行精细调整。
蚁群算法自提出以来,已经被广泛应用于各种优化问题中,并在多种领域中取得了成功,如物流、网络路由优化、调度问题等。随着研究的深入,蚁群算法的变种和改进版本也不断涌现,以解决其在不同应用场景中的局限性。
Scikit-Opt实现:虽然直接的ACO实现可能在Scikit-Opt的版本中不显眼,但其提供的方法和工具可间接应用于ACO的开发。
import numpy as np
from sko.ACA import ACA_TSP
import matplotlib.pyplot as plt
# fix the 'numpy.int' attribute error
np.int = int
# 定义城市坐标
num_points = 20
points = np.random.rand(num_points, 2) # 生成随机城市坐标
# 计算距离矩阵
distance_matrix = np.sqrt(((points[:, np.newaxis, :] - points[np.newaxis, :, :])**2).sum(axis=2))
# 创建蚁群算法的实例
aca = ACA_TSP(func=lambda p: distance_matrix[p[:-1], p[1:]].sum() + distance_matrix[p[-1], p[0]], n_dim=num_points,
size_pop=50, max_iter=200, distance_matrix=distance_matrix)
# 执行优化
best_x, best_y = aca.run()
# 输出结果
print('Best path:', best_x)
print('Best path length:', best_y)
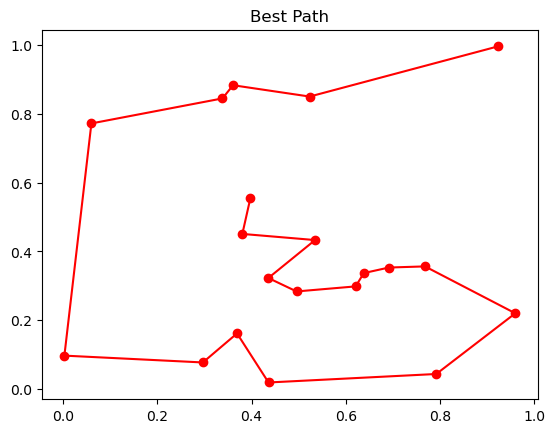
# 可视化最优路径
best_path_points = points[best_x]
plt.plot(best_path_points[:, 0], best_path_points[:, 1], 'o-r')
plt.title('Best Path')
plt.show()
免疫优化算法(Immune Optimization Algorithm)
免疫优化算法(Immune Optimization Algorithm, IOA)是一种受生物免疫系统启发的优化算法。生物免疫系统能够识别和消灭入侵的病原体,并具有自学习和记忆功能。这些特性为优化算法提供了灵感。免疫优化算法通常用于解决复杂的优化问题,包括函数优化、组合优化和多目标优化等。
免疫优化算法的基本概念
- 抗体与抗原:
- 抗体:在免疫优化算法中,抗体通常表示一个解或候选解。
- 抗原:问题的目标或目标函数,可以看作是需要优化的对象。
- 亲和度:亲和度用于衡量抗体与抗原之间的匹配程度。在优化问题中,亲和度通常与目标函数的值相关联。亲和度越高,表示解越优。
- 克隆选择:克隆选择是免疫系统中一种重要的机制,它通过选择高亲和度的抗体进行复制和变异,生成新的抗体,从而提高系统的适应性。
- 多样性保持:生物免疫系统通过生成多样的抗体库来识别多种病原体。免疫优化算法通过保持解的多样性来避免陷入局部最优解。
基本原理
- 抗体与抗原:在免疫优化算法中,问题的解通常用“抗体”来表示,而需要解决的问题或目标则被称为“抗原”。算法的目标是通过不断进化抗体(即解)来找到能够最好地适应抗原(即问题)的最佳解。
- 选择机制:类似于生物免疫系统中的自然选择过程,免疫优化算法也会选择那些更适应环境(即更接近最优解)的抗体进行后续操作。
- 克隆与变异:为了增加种群多样性并避免过早收敛到局部最优解,算法会通过克隆操作复制优秀的抗体,并对这些复制的抗体进行变异以探索新的解空间。
- 抑制机制:为了避免种群中出现过多相似的解而导致搜索陷入局部最优,免疫优化算法引入了抑制机制来控制种群的多样性。这通常通过定义一个阈值或者采用某种形式的记忆库来实现。
- 记忆库:在迭代过程中,算法会维护一个记忆库来保存迄今为止找到的最佳解或者一系列较好的解。这样可以在一定程度上防止算法忘记之前探索过的优质区域。
免疫优化算法的步骤
- 初始化:生成初始的抗体库,通常是随机生成若干个解。
- 亲和度评价:计算每个抗体的亲和度,即评估每个解的质量。
- 选择与克隆:根据亲和度选择出表现较好的抗体,并对其进行克隆。克隆的数量通常与抗体的亲和度成正比。
- 变异:对克隆的抗体进行变异,以产生新的解。变异率通常与抗体的亲和度成反比,高亲和度的抗体变异率较低,以保持其优良特性。
- 替换:将变异后的抗体与原有抗体库进行比较,根据亲和度进行替换,以保持抗体库中解的质量。
- 多样性保持:引入多样性机制(如随机生成新的抗体)以保持解的多样性。
终止条件:根据预设的终止条件(如达到最大迭代次数或亲和度达到阈值)结束算法。
免疫优化算法的类型
- 克隆选择算法(CSA):模拟免疫系统中的克隆选择机制,对高亲和力的抗体进行克隆和变异,以优化解。
- 人工免疫网络(AIN):模仿免疫系统中的网络理论,通过抗体间的交互来改进解。
- 负选择算法(NSA):基于免疫系统的自我与非自我识别机制,主要用于异常检测和模式识别。
免疫优化算法具有以下优点:
- 较强的全局搜索能力,能够避免陷入局部最优。
- 对复杂问题具有较好的适应性。
- 能够利用免疫记忆机制,加快收敛速度。
然而,免疫优化算法也存在一些局限性,如参数设置较为敏感、计算复杂度较高等。在实际应用中,通常需要根据具体问题进行适当的调整和改进。
Scikit-Opt实现:Scikit-Opt中包含基于免疫优化思想的相关实现或启发式框架,帮助用户应用于实际问题。
import numpy as np
from sko.IA import IA_TSP
import matplotlib.pyplot as plt
# 定义城市坐标
num_points = 20
points = np.random.rand(num_points, 2) # 生成随机城市坐标
# 计算距离矩阵
distance_matrix = np.sqrt(((points[:, np.newaxis, :] - points[np.newaxis, :, :])**2).sum(axis=2))
# 定义适应度函数
def cal_total_distance(routine):
'''The objective function. Input routine, return total distance.
cal_total_distance(np.arange(num_points))
'''
num_points, = routine.shape
return sum([distance_matrix[routine[i % num_points], routine[(i + 1) % num_points]] for i in range(num_points)])
# 创建免疫优化算法的实例
ia = IA_TSP(func=cal_total_distance, n_dim=num_points, size_pop=50, max_iter=200, prob_mut=0.2)
# 执行优化
best_x, best_y = ia.run()
# 输出结果
print('Best path:', best_x)
print('Best path length:', best_y)
# 可视化最优路径
best_path_points = points[best_x]
plt.plot(best_path_points[:, 0], best_path_points[:, 1], 'o-r')
plt.scatter(points[:, 0], points[:, 1], c='blue')
plt.title('Best Path')
plt.show()
人工鱼群算法(Artificial Fish-Swarm Algorithm, AFSA)
人工鱼群算法(Artificial Fish Swarm Algorithm, AFSA)是一种基于鱼群行为模拟的优化算法,由中国学者李春葆于2002年提出。该算法通过模拟鱼群在自然界中的觅食、聚群和追尾等行为,实现对复杂优化问题的求解。
主要行为
- 觅食行为(Prey Behavior):
- 鱼群通过感觉周围环境的浓度(目标函数值)来判断食物的丰富程度。
- 每条鱼在其视野范围内随机选择一个方向移动,如果新的位置浓度更高,则向该方向移动,否则继续随机搜索。
- 聚群行为(Swarm Behavior):
- 鱼群会趋向于聚集成群,以提高生存概率。
- 每条鱼计算视野内鱼群中心的位置及其浓度,如果中心浓度较高且群体密度适中,则向中心移动。
- 追尾行为(Follow Behavior):
- 鱼群倾向于追随视野范围内游得最快、浓度最高的鱼。
- 每条鱼在其视野范围内找到游得最快的鱼,如果该鱼的位置浓度较高,则跟随该鱼移动。
人工鱼群算法的步骤
- 初始化:随机生成N条人工鱼,每条鱼的位置代表解空间中的一个可能解。
- 行为选择:每条人工鱼根据自己的局部环境信息(例如食物浓度)选择以下行为之一:
- 觅食行为
- 聚群行为
- 追随行为
- 如果以上行为都不能使其位置得到改善,则执行随机行为。
- 计算适应度:每次人工鱼移动后,计算其在新位置的适应度。
- 更新:根据人工鱼的适应度更新鱼的位置。
- 迭代:重复行为选择、计算适应度和更新过程,直到满足结束条件(例如达到最大迭代次数或适应度达到要求的阈值)。
算法特点
- 具有较快的收敛速度:人工鱼群算法在迭代初期具有较快的收敛速率,能够迅速找到问题的较优解。
- 对初值敏感度低:算法对初始值的设置不敏感,不同的初始值对最终结果的影响较小。
- 鲁棒性强:算法具有较强的鲁棒性,能够在不同的环境和问题中表现出较好的性能。
- 并行性和全局性:算法中的每个人工鱼都进行并行搜索,有利于找到全局最优解。
然而,人工鱼群算法也存在一些不足,如迭代后期收敛性能下降、寻优精度不高以及可能陷入局部极值等。为了改进这些缺陷,学者们提出了各种改进策略,如引入禁忌搜索、改进人工鱼的行为机制等。
Scikit-Opt实现:提供了基于鱼群算法的优化方法和框架,使用户能够轻松地构建和优化此类问题的解。
import numpy as np
from sko.AFSA import AFSA
import matplotlib.pyplot as plt
# 定义目标函数
def func(x):
return -(x[0]**2 + x[1]**2) # 示例目标函数
# 搜索空间的维度
dim = 2
# 创建人工鱼群算法的实例
afsa = AFSA(func=func, n_dim=dim, size_pop=50, max_iter=200, step=0.5, visual=0.3, q=0.98)
# 执行优化
best_x, best_y = afsa.run()
# 输出结果
print('Best solution:', best_x)
print('Best value:', best_y)
# 可视化结果
# 如果AFSA没有`best_x_history`,我们可以通过其他方式获取历史数据。
# 在这个示例中,我们假设AFSA没有直接提供历史记录的属性。
# 由于没有现成的历史数据可用,我们将生成一些模拟数据来展示可视化过程。
# 这部分代码在真实应用中应根据实际的库实现进行调整。
# 假设我们有一些历史位置数据
# 这里我们仅生成一些随机数据作为示例
history_x = np.random.uniform(-5, 5, (100, dim))
plt.scatter(history_x[:, 0], history_x[:, 1], label='History', alpha=0.5)
plt.scatter(best_x[0], best_x[1], c='red', s=100, label='Best')
plt.title('Artificial Fish Swarm Algorithm')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.show()
参考链接:


