CURE(Clustering Using Representatives)是一种针对大型数据库的高效的聚类算法。基于层次的传统的聚类算法得到的是球状的,相等大小的聚类,对异常数据比较脆弱。CURE采用了用多个点代表一个簇的方法,可以较好…
BIRCH算法简介 BIRCH算法的全称是Balanced Iterative Reducing and Clustering using Hierarchies,它使用聚类特征来表示一个簇,使用聚类特征树(CF-树)来表示聚类的层次结构,算法思路也是“自底向上”的。 BI…
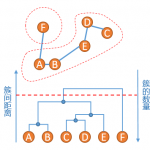
层次聚类简介 层次聚类算法(Hierarchical Clustering)将数据集划分为一层一层的clusters,后面一层生成的clusters基于前面一层的结果。层次聚类算法一般分为两类: Divisive 层次聚类:又称自顶向下(top-dow…
Prophet简介 时间序列(Time Series Analysis)作为计量经济学的三大数据形态之一, 比较主流的观点认为,时间序列受四种成分影响: 趋势:宏观、长期、持续性的作用力 周期:比如商品价格在较短时间内,…
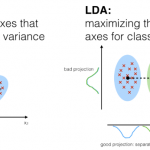
线性判别分析(linear discriminant analysis, LDA)一种常用的数据降维方法,目的是在保持分类的前体下把数据投影至低维空间以降低计算复杂度。在学习LDA之前,有必要将其与自然语言处理领域的LDA区别开来,在自然…
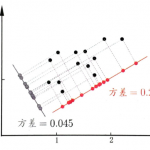
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。一般我们提到降维最容易想到的算法就是PCA,下面我们就对PCA的原理做…
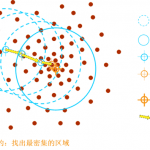
在K-Means算法中,最终的聚类效果受初始的聚类中心的影响,K-Means++算法的提出,为选择较好的初始聚类中心提供了依据,但是算法中,聚类的类别个数k仍需事先制定,对于类别个数事先未知的数据集,K-Means和K-Means…
在Python中经常使用matplotlib画图,为了让图像显示的更加好看,经常需要对图表点、线形状及颜色进行设置。为了避免遗忘,整理相关的信息。 先来看看matplotlib画图方法的官方说明: from matplotlib import py…

欧几里得距离 在数学中,欧几里得距离或欧几里得度量是欧几里得空间中两点间“普通”(即直线)距离。欧几里得距离有时候有称欧氏距离,在数据分析及挖掘中经常会被使用到,例如聚类或计算相似度。 如果我们…

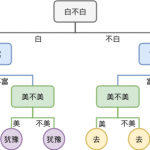
什么是决策树 决策树(decision tree)是一种依托于策略抉择而建立起来的树。机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。 树中每个节点表示某个对象,而每个分叉路径则代…