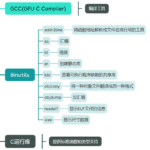
GCC简介 GCC(GNU Compiler Collection)是由 GNU 项目开发的程序语言编译器。原名为 GNU C Compiler(GNU C 编译器),因为最初只能处理 C 语言。GCC 现在已经能支持多种编程语言,包括 C、C++、Objective-C、Fort…
在介绍WebP的时候,我们已经知道了相比JPG和PNG来说,WebP已经兼顾了高呈现质量以及更小的文件体积,可以说已经非常优秀了,然后还是有一群人不满足于此,他们开发出了AVIF这种号称下一代图像压缩格式的玩意。 AVIF…

事务简介 事务的定义 事务(Transaction)在计算和数据库处理中是一个非常重要的概念。事务是一个被数据库管理系统(DBMS)视为一次性、逻辑上的操作单元的操作序列。这个操作序列中包含了对数据库的读、写操作。 …
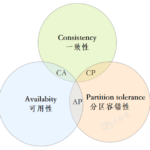
CAP理论 CAP简介 CAP理论是计算机分布式系统设计中的一个重要理论,由Eric Brewer教授在2000年的ACM会议上首次提出。CAP是Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容忍性)的首…
什么是推断统计? 推断统计是一种通过样本数据推断总体参数的统计方法。它不仅能够根据样本数据对总体参数进行点估计和区间估计,还能够进行假设检验,通过建立统计模型对数据进行解释和预测。 推断统计主要包括以…
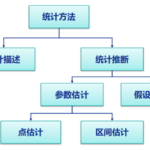
参数估计的基本概念 参数估计是指用样本统计量去估计总体的参数。总体参数通常是未知的,我们通过对一部分样本的观察来对这些未知参数进行估计。 在统计学中,参数和估计量是两个核心概念,它们在进行统计…
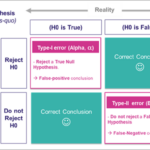
假设检验的基本概念 假设检验(Hypothesis Testing)是一种统计决策理论的方法,它利用观察得到的数据,对某个统计假设进行检验,以判断该假设是否合理。 在假设检验中,首先会提出两个对立的假设:原假设(Null H…
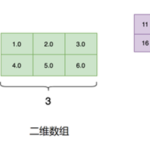
在C语言中,数组是由相同类型的数据元素构成的数据结构。这些元素在内存中连续存放,每个元素都可以通过索引(数组下标)进行访问。 下面是在学习和使用数组时需要注意的一些重要知识点: 数组的声明:C语言中的…
在学习编程语言的时候经常有一些教程指导如何编写一个博客程序或CMS系统,但整体内容偏简单,核心点集中在如何增删改查的实现,并没有达到一个“可用”状态。 不再流行的博客 依稀记2005年左右,博客非常的流行,从…

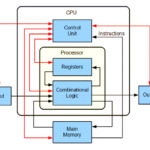
在下载安装Linux或Linux软件时,有时需要选择不同的架构的版本,由于对CPU架构缺乏一定的了解,可能会导致一些混乱,今天就抽空整理下。 什么是CPU架构? CPU架构,也称为微处理器架构,CPU架构(Central Pro…