线性回归是机器学习中最为简单的模型,但在实际使用过程中可能不太适用。比如以下场景:
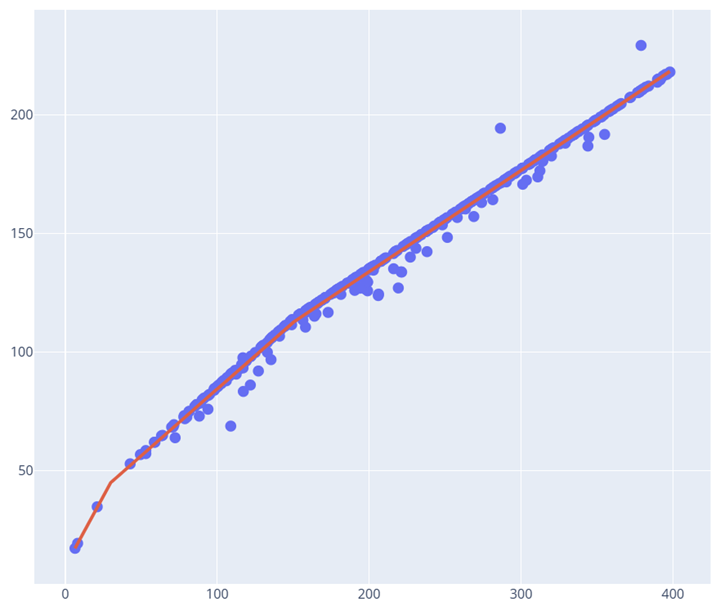
分段线性拟合是一种用于对数据进行建模的回归方法,其中数据在不同的区间内使用不同的线性函数进行建模。与简单线性回归和多项式回归相比,分段线性回归可以更好地适应非线性数据,并且通常具有更高的灵活性和可解释性。
在分段线性拟合中,数据将被划分为多个连续的区间(也称为”段”或”片段”),每个区间内的数据都由一个线性函数进行建模。确定分段线性回归模型的关键是确定断点位置。断点位于两个相邻的区间之间,表示从一个线性函数到下一个线性函数的过渡点。有许多方法可以确定最佳断点位置,例如贝叶斯信息准则、Akaike信息准则、交叉验证等。
方法一:使用numpy.piecewise分段拟合
numpy.piecewise是一个用于创建分段函数的函数,它可以根据指定的条件对输入数组进行分类,并对分类后的每个部分应用不同的操作。下面是numpy.piecewise函数的一般语法:
numpy.piecewise(x, condlist, funclist, *args, **kw)
其中,参数的含义如下:
- x:输入数组,可以是任意形状的数组。
- condlist:条件列表,是一个长度为nnn的列表,其中包含特定条件下的布尔表达式(或值)。当满足第kkk个条件时,piecewise函数会使用第kkk个函数进行操作。
- funclist:函数列表,是一个长度为nnn的列表,其中包含了要执行的操作。当满足第kkk个条件时,piecewise函数会使用第kkk个函数进行操作。
- *args和**kw:可选参数,用于传递给被调用的函数。
下面是一个numpy.piecewise使用的例子:
import numpy as np x = np.array([1.5, 2.5, 3.5, 4.5]) y = np.piecewise(x, [x< 2, (x >= 2) & (x< 4), x >= 4], [lambda x: x**2, lambda x: x**3, lambda x: x**4]) print(y) #[2.25 15.625 42.875 91.125]
在这个例子中,我们首先定义了一个包含四个元素的输入数组x,然后我们使用numpy.piecewise函数对其进行分类。具体地说,我们使用三个布尔表达式作为条件,将x分成了三个部分。当x< 2时,我们使用lambda x: x**2函数对该部分进行操作;当2<= x< 4时,我们使用lambda x: x**3函数对该部分进行操作;当x >= 4时,我们使用lambda x: x**4函数对该部分进行操作。最终,numpy.piecewise函数返回了一个与输入数组x形状相同的输出数组y,其中包含了根据条件分类后的数组元素。
numpy.piecewise进行线性回归代码示例:
from scipy import optimize
import matplotlib.pyplot as plt
import numpy as np
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], dtype=float)
y = np.array([5, 7, 9, 11, 13, 15, 28.92, 42.81, 56.7, 70.59, 84.47, 98.36, 112.25, 126.14, 140.03])
def piecewise_linear(x, x0, y0, k1, k2):
return np.piecewise(x, [x< x0, x >= x0], [lambda x: k1*x + y0 - k1*x0, lambda x: k2*x + y0 - k2*x0])
p, e = optimize.curve_fit(piecewise_linear, x, y)
xd = np.linspace(0, 15, 100)
plt.plot(x, y, "o")
plt.plot(xd, piecewise_linear(xd, *p))
这段代码使用了SciPy库中的optimize模块来拟合一个分段线性函数,并将结果可视化。首先,我们定义了两个数组x和y,分别表示自变量和因变量的取值。然后,我们定义了一个名为piecewise_linear的函数,用于计算分段线性函数的值。这个函数包含四个参数x0、y0、k1和k2,它们都是要优化的参数。其中,x0表示分段点的位置,y0表示分段点处的函数值,k1和k2则表示分段点左右两侧的斜率。
接下来,我们使用optimize.curve_fit函数对piecewise_linear函数进行拟合,得到了一组最优参数p,并计算了误差e。最后,我们使用matplotlib库来绘制数据点和拟合曲线。具体地说,我们使用plt.plot函数分别绘制了数据点和拟合曲线。其中,xd=np.linspace(0,15,100)生成了一个从0到15的等差数列,用于在x轴上绘制拟合曲线。通过piecewise_linear(xd,*p)计算了在xd对应的分段线性函数的取值,然后将结果作为y值传递给plt.plot函数,绘制在图像上。
以上代码只支持将线性回归分为2部分。如果需要分为3段:
from scipy import optimize
def piecewise_linear(x, x0, x1, b, k1, k2, k3):
condlist = [x< x0, (x >= x0) & (x< x1), x >= x1]
funclist = [lambda x: k1*x + b, lambda x: k1*x + b + k2*(x-x0), lambda x: k1*x + b + k2*(x-x0) + k3*(x-x1)]
return np.piecewise(x, condlist, funclist)
p, e = optimize.curve_fit(piecewise_linear, x, y)
xd = np.linspace(-30, 30, 1000)
plt.plot(x, y, "o")
plt.plot(xd, piecewise_linear(xd, *p))
方法二:使用Nelder-Mead方法来拟合分段线性函数
Nelder-Mead方法是一种求解无约束优化问题的迭代算法,也称为单纯形法。它通过不断缩小一个n+1维单纯形(即n个顶点和一个重心)的体积,来逼近目标函数的最小值。该方法可以用于求解具有非线性多峰性的目标函数,但通常需要较多的计算次数和较长的计算时间。
算法步骤如下:
- 初始化单纯形:对于n维目标函数,选取n+1个初始点作为单纯形的顶点,计算各个顶点处的函数值,并按照函数值从小到大的顺序对单纯形进行排序。
- 迭代更新单纯形:对于每次迭代,首先根据单纯形中的所有顶点,计算其重心的位置,并计算反射点、扩张点、收缩点和压缩点的位置。然后,根据这些点的函数值,对单纯形进行调整,更新单纯形的顶点和排序,直到满足一定的停止条件为止。
- 停止条件:通常采用以下几种停止条件之一:
- 目标函数的相对误差小于给定阈值。
- 单纯形的体积小于给定阈值。
- 计算次数达到预设的上限。
总结起来,Nelder-Mead方法是一种直观易懂的优化方法,它可以在不知道目标函数的导数的情况下求解最小值,并且可以处理非线性多峰的目标函数。但是,由于该方法只使用了局部信息,通常需要较多的计算次数来找到最小值。同时,该方法对初始点的选择敏感,初始点的选择不当可能会导致算法陷入局部最优解。
%matplotlib inline
import numpy as np
import pylab as pl
def make_test_data(seg_count, point_count):
x = np.random.uniform(2, 10, seg_count)
x = np.cumsum(x)
x *= 10 / x.max()
y = np.cumsum(np.random.uniform(-1, 1, seg_count))
X = np.random.uniform(0, 10, point_count)
Y = np.interp(X, x, y) + np.random.normal(0, 0.05, point_count)
return X, Y
from scipy import optimize
# def segments_fit(X, Y, count):
# xmin = X.min()
# xmax = X.max()
#
# seg = np.full(count - 1, (xmax - xmin) / count)
#
# px_init = np.r_[np.r_[xmin, seg].cumsum(), xmax]
# py_init = np.array([Y[np.abs(X - x) < (xmax - xmin) * 0.01].mean() for x in px_init])
#
# def func(p):
# seg = p[:count - 1]
# py = p[count - 1:]
# px = np.r_[np.r_[xmin, seg].cumsum(), xmax]
# return px, py
#
# def err(p):
# px, py = func(p)
# Y2 = np.interp(X, px, py)
# return np.mean((Y - Y2)**2)
#
# r = optimize.minimize(err, x0=np.r_[seg, py_init], method='Nelder-Mead')
# return func(r.x)
def segments_fit(X, Y, maxcount):
xmin = X.min()
xmax = X.max()
n = len(X)
AIC_ = float('inf')
BIC_ = float('inf')
r_ = None
for count in range(1, maxcount + 1):
seg = np.full(count - 1, (xmax - xmin) / count)
px_init = np.r_[np.r_[xmin, seg].cumsum(), xmax]
py_init = np.array([Y[np.abs(X - x) < (xmax - xmin) * 0.1].mean() for x in px_init])
def func(p):
seg = p[:count - 1]
py = p[count - 1:]
px = np.r_[np.r_[xmin, seg].cumsum(), xmax]
return px, py
def err(p): # This is RSS/n
px, py = func(p)
Y2 = np.interp(X, px, py)
return np.mean((Y - Y2)**2)
r = optimize.minimize(err, x0=np.r_[seg, py_init], method='Nelder-Mead')
# Compute AIC/BIC.
AIC = n * np.log10(err(r.x)) + 4 * count
BIC = n * np.log10(err(r.x)) + 2 * count * np.log(n)
if ((BIC< BIC_) & (AIC< AIC_)): # Continue adding complexity.
r_ = r
AIC_ = AIC
BIC_ = BIC
else: # Stop.
count = count - 1
break
return func(r_.x) # Return the last (n-1)
X, Y = make_test_data(10, 2000)
px, py = segments_fit(X, Y, 8)
pl.plot(X, Y, ".")
pl.plot(px, py, "-or");
X = np.random.uniform(0, 10, 2000)
Y = np.sin(X) + np.random.normal(0, 0.05, X.shape)
px, py = segments_fit(X, Y, 8)
pl.plot(X, Y, ".")
pl.plot(px, py, "-or");
这段代码实现了一种基于信息准则的自动分段线性函数拟合方法。给定输入数据X和对应的输出数据Y,以及最大的分段数量maxcount,该函数会在1到maxcount范围内遍历所有可能的分段数量,得到最优的分段线性函数,并返回其取值。
具体而言,该函数首先求出输入数据X中的最小值和最大值,并将其用于计算分段点之间的长度。然后,该函数从1开始逐步增加分段数量,每次都进行分段线性函数的拟合,并计算相应的AIC和BIC值。AIC和BIC都是信息准则,用于权衡模型的复杂度和预测能力,其中AIC的惩罚项比BIC更大。如果当前的AIC和BIC均优于前面的最优值,那么就继续增加分段数量;否则,就选择当前的最优分段线性函数,并停止增加分段数量。
对于每个分段数量count,该函数使用segments_fit函数来拟合分段线性函数。它首先根据分段数量count和输入数据X的最大值最小值,初始化一个分段长度数组seg,并使用均匀采样方式确定初始分段点处的函数取值py_init。然后,该函数定义两个辅助函数func(p)和err(p),分别用于计算分段线性函数的取值和预测误差。接下来,该函数使用optimize.minimize函数来寻找最优的拟合参数。最后,该函数根据当前的分段数量count计算AIC和BIC值,并更新最优的AIC、BIC值和对应的分段线性函数对象。
方法三:使用linear-tree
linear-tree是一个Python包,用于构建线性模型。它提供了实现线性回归、逻辑回归和Lasso回归的类。其中,线性回归模型适合用于预测数值型变量的值,而逻辑回归则适合用于预测二元变量的概率。Lasso回归是一种特殊的线性回归,它对不重要的变量施加惩罚,从而可以实现特征选择的功能。
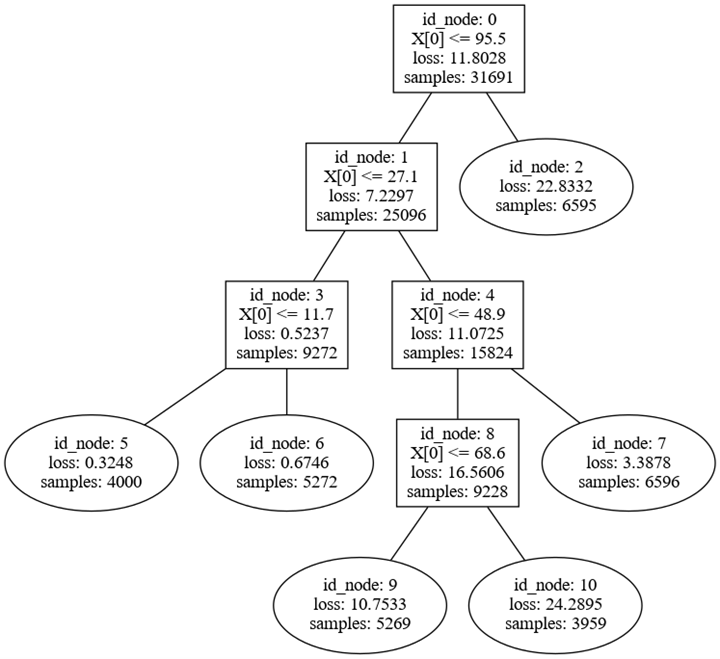
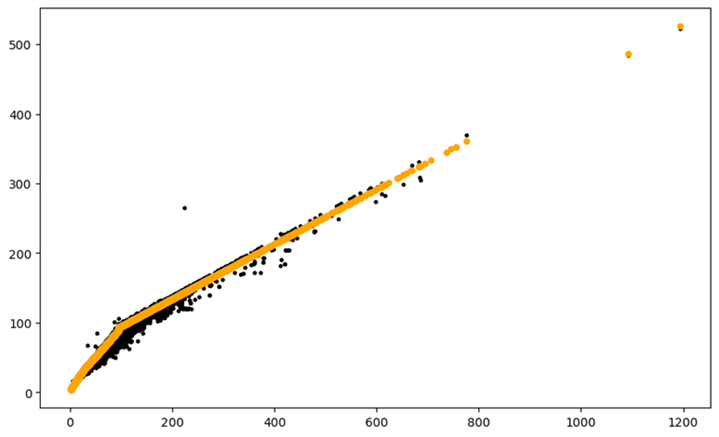
linear-tree也可以做分段线性拟合。且也能做很好的拟合,但是LinearTreeRegressor类并没有直接提供coef_和intercept_属性来获取线性模型的系数和截距。这是因为LinearTreeRegressor是一个决策树回归模型,它不是一个直接的线性模型。
from sklearn.linear_model import LinearRegression from lineartree import LinearTreeRegressor regr = LinearTreeRegressor(base_estimator=LinearRegression()) regr.fit(x.reshape(-1, 1), y) regr.plot_model()
方法四:使用Pwlf包
pwlf是一个用于实现分段线性回归的Python库。它提供了一些有用的功能,例如可视化数据和逐步添加断点以创建最佳模型。它还可以处理多元分段线性回归问题。
在pwlf中,断点可以通过手动指定或使用算法自动确定。如果要手动指定断点位置,请使用pwlf.PiecewiseLinFit.fit_with_breaks()方法,并将所有想要的断点位置作为参数传递。例如,以下代码将数据分成三个段,每个段的断点位置分别为x=3和x=6:
import pwlf x = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0] y = [1.0, 1.5, 2.0, 4.0, 4.5, 4.0, 3.5, 3.0, 2.0, 1.0] my_pwlf = pwlf.PiecewiseLinFit(x, y) breaks = [3.0, 6.0] res = my_pwlf.fit_with_breaks(breaks) print(my_pwlf.intercepts) print(my_pwlf.slopes) print(my_pwlf.fit_breaks) print(my_pwlf.ssr)
如果希望自动确定最佳的断点位置,则可以使用pwlf.PiecewiseLinFit.fitfast()方法来拟合数据并自动确定最佳的断点位置。例如:
import pwlf x = [1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.0] y = [1.0, 1.5, 2.0, 4.0, 4.5, 4.0, 3.5, 3.0, 2.0, 1.0] my_pwlf = pwlf.PiecewiseLinFit(x, y) res = my_pwlf.fitfast(3) #3表示最多可以有3个段
此方法将使用快速拟合算法来自动确定断点,因此可能不会找到全局最优解。如果需要更好的结果,可以尝试使用pwlf.PiecewiseLinFit.fit()方法来进行全局拟合。


