多版本并发控制(MVCC,Multi-Version Concurrency Control)是PostgreSQL中实现并发控制的一种机制。MVCC允许多个事务同时访问数据库,而不会产生锁定冲突。这种机制通过维护数据的多个版本,提供了一种高效的方法来处理并发事务。

为什么需要MVCC?
多版本并发控制(MVCC)的引入和使用主要是为了有效解决数据库系统中的并发控制问题。以下是MVCC的几个关键需求和优点:
- 提高并发性能:
- 在传统的锁机制中,读写操作可能会相互阻塞,特别是在高并发环境下,这会显著降低系统性能。
- MVCC通过允许读操作不加锁地访问数据,从而提高了系统的并发性能。写操作不会阻塞读操作,反之亦然。
- 减少锁竞争:
- 传统锁机制中,多个事务同时访问同一数据时,会出现锁竞争问题。
- MVCC通过版本化数据,避免了大多数情况下的锁竞争,尤其是读操作之间的竞争。
- 实现事务隔离:
- MVCC支持多种事务隔离级别(如Read Committed、Repeatable Read、Serializable),通过维护数据的多个版本,确保事务在执行过程中可以看到一致的快照。
- 这使得事务在读取数据时不会看到其他未提交事务的中间状态,保证了数据的一致性和隔离性。
- 减少锁等待和死锁风险:
- 由于读操作不需要锁,MVCC有效地减少了锁等待的情况。
- 这也降低了死锁发生的风险,因为读操作不会与其他事务争夺锁。
- 支持长时间运行的查询:
- MVCC允许长时间运行的查询在获取快照后可以一致地访问数据,即使在查询期间其他事务对数据进行了修改。
- 这对于分析型查询和报告生成非常有用,因为这些操作通常需要长时间读取大量数据。
- 提高系统吞吐量:
- 通过减少锁争用和提高并发能力,MVCC能够提高数据库系统的整体吞吐量。
- 这对需要处理大量并发请求的应用程序(如在线交易系统)特别重要。
总的来说,MVCC通过提供更细粒度的并发控制,解决了传统锁机制在高并发环境下的性能瓶颈和一致性问题,使得数据库系统能够更高效地处理并发事务。
MVCC的基本概念
多版本并发控制(MVCC)的基本概念主要围绕如何在数据库中管理和访问数据的多个版本。以下是MVCC的几个核心概念:
- 数据版本化:
- 在MVCC中,每次对数据行进行更新时,数据库不会直接覆盖原有数据,而是创建一个新的版本。这意味着同一行的数据可能会有多个版本共存。
- 每个数据版本都有两个重要的隐含字段:xmin和xmax。
- xmin:创建该版本的事务ID,表示哪个事务创建了这个数据版本。
- xmax:删除该版本的事务ID,表示哪个事务删除了这个数据版本(如果行未被删除,则为未定义)。
- 事务ID(Transaction ID, XID):
- 每个事务在开始时都会被分配一个唯一的事务ID,用于标识该事务。
- 事务ID用于确定数据版本的可见性和管理事务的顺序。
- 快照(Snapshot):
- 每个事务在开始时获取一个数据库快照,这个快照包含了当时数据库中所有可见的数据版本。
- 快照用于保证事务在其生命周期内看到的数据是一致的,即使其他事务正在并发地修改数据。
- 可见性规则:
- 一个数据版本对一个事务可见的条件是:
- 该版本的xmin小于当前事务的ID,意味着该版本在当前事务开始之前已存在。
- 该版本的xmax要么未定义,要么大于当前事务的ID,意味着该版本在当前事务期间未被删除。
- 隔离级别:
- MVCC支持多种事务隔离级别,如Read Committed、Repeatable Read、Serializable。每种隔离级别定义了不同的可见性规则,以平衡一致性和并发性。
- 通过快照机制,MVCC在不使用锁的情况下实现了高效的事务隔离。
- 并发读写:
- MVCC允许读操作不需要加锁即可访问数据,避免了与写操作的锁竞争。
- 写操作通过创建新版本实现,只有在需要防止写-写冲突时才使用锁。
- 一个数据版本对一个事务可见的条件是:
通过这些基本概念,MVCC在数据库中实现了高效的并发控制和一致性管理,使得多个事务可以同时读取和修改数据,而不会相互干扰。
MVCC的实现
多版本并发控制(Multi-Version Concurrency Control, MVCC)是一种通过冗余多份历史数据来达到并发读写目的的一种技术,在写入数据时,旧版本的历史数据将不会被删除,那么此时并发的读仍然能够读取到对应的历史数据,这样就使得读和写能够并发运行,并且不会出现数据不一致的问题。
事务ID
多版本并发控制既然会保留一份数据的多个版本,那么就需要能够区分出哪个版本是最新的,哪个版本是最旧的。一个最朴素的想法就是给每一个版本添加一个时间戳,用时间戳来比较新旧,但是时间戳不稳定,万一有人修改了服务器的配置,事情就乱套了。因此,PostgreSQL使用了一个32位无符号自增整数来作为事务标识以比较新旧程度。
我们可以通过 txid_current() 函数来获取当前事务的标识:
postgres=# select txid_current(); txid_current -------------- 507 (1 row)
Tuple结构
紧接着我们需要了解堆元组的组成结构,堆元组由HeapTupleHeaderData、NULL值位图以及用户数据所组成,如下图所示:

与MVCC相关的字段只有4个,其含义如下:
- t_xmin: 保存了插入该元组的事务的txid
- t_xmax: 保存删除或者是更新该元组的事务的txid,若一个tuple既没有被更新也没有被删除的话,该字段的值为0
- t_cid: 即Command ID,表示在当前事务中,执行当前命令之前共执行了多少条命令,从0开始计数。t_cid的主要作用就在于判断游标的数据可见性,将在后文详细描述
- t_infomask: 位掩码,主要保存了事务执行的状态,如XMIN_COMMITTED、XMAX_COMMITTED 等。同时也保存了 COMBOCID 这一非常重要的标识位,也是和游标相关的字段。
接下来就通过一些小实验来理清这些字段的具体含义,在此之前需要引入一个小工具: pageinspect。pageinspect 是官方所编写的一个拓展工具,可用于查看数据库一个 page 的全部内容
postgres=# CREATE EXTENSION pageinspect;
CREATE EXTENSION
postgres=# CREATE TABLE t(a int);
CREATE TABLE
postgres=# insert into t values(1);
INSERT 0 1
postgres=# create view info_t as select lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid from heap_page_items(get_raw_page('t', 0)) order by tuple;
插入: t_xmin
t_xmin 与创建相关,当我们 insert 一条数据时,t_xmin 就会被设置成执行事务的 txid,并且一旦设置,便不会修改:
postgres=# begin;
BEGIN
postgres=# select txid_current(); --获取当前事务 txid
txid_current
--------------
582
(1 row)
postgres=# insert into t values(1); --插入数据
INSERT 0 1
postgres=# select * from info_t; --获取 t_xmin
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 582 | 0 | 0 | (0,1)
(1 row)

可以看到,t_xmin 被设置成了 582,因为该元组就是被 txid 为 582 的事务所插入的。同时 t_xmax 被设置成 0,因为没有更新和删除。
删除: t_xmax
t_xmax 与删除有关,当我们删除一条数据时,t_xmax 就会被设置成执行事务的 txid:
postgres=# truncate table t;
TRUNCATE TABLE
postgres=# insert into t values(1); --插入数据
INSERT 0 1
postgres=# begin;
BEGIN
postgres=# select txid_current(); --获取当前事务 txid
txid_current
--------------
588
(1 row)
postgres=# delete from t; --删除数据
DELETE 1
postgres=# select * from info_t;
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 587 | 588 | 0 | (0,1)
(1 row)
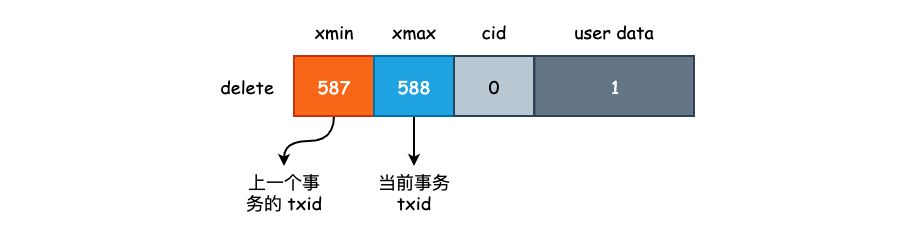
当我们使用 DELETE FROM 删除数据时,数据只是逻辑上被标记删除,实际上就是设置目标元组的 t_xmax 为执行 DELETE 命令事务的 txid,这些被标记为已删除的元组将会在 VCAUUM 过程中被物理清除。
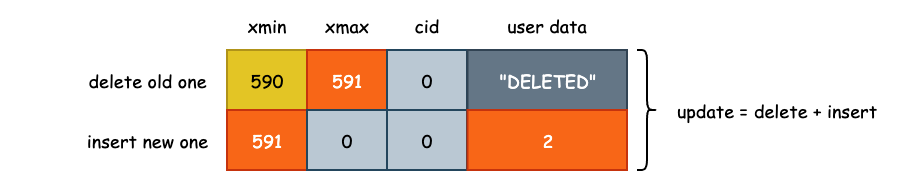
更新: t_xmin + t_xmax
在 PostgresSQL 中,元组的更新并不是原地的,也就是说新数据不会覆盖旧有的数据,而是通过将旧数据标记为删除,新插入一条数据的方式来完成更新。也就是说,假如说我们对 100 条数据进行更新的话,最终会在文件中产生 200 条数据,其中有 100 条被标记为删除。
postgres=# truncate table t;
TRUNCATE TABLE
postgres=# insert into t values(1); --插入数据
INSERT 0 1
postgres=# begin;
BEGIN
postgres=# select txid_current(); --获取当前事务 txid
txid_current
--------------
591
(1 row)
postgres=# update t set a=2; --更新数据
UPDATE 1
postgres=# select * from info_t;
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 590 | 591 | 0 | (0,2)
2 | 591 | 0 | 0 | (0,2)
(2 rows)
事务快照
事务快照是一个数据集合,保存了某个事务在某个特定时间点所看到的事务状态信息,包括哪些事务已经结束,哪些事务正在进行,以及哪些事务还未开始,我们可以通过 txid_current_snapshot() 函数来获取当前的事务快照:
postgres=# select txid_current_snapshot(); txid_current_snapshot ----------------------- 580:584:581,583 (1 row)
txid_current_snapshot() 的文本表示含义为 xmin:xmax:xip_list,其中 xmin 表示所有小于它的事务要么已提交,要么已经回滚,即事务结束。xmax 则表示第一个尚未分配的 txid,即所有 txid>=xmax 的事务都还没有开始。而 xip_list 则是使用逗号分割的一组 txid,表示在获取快照时还是进行的事务。
以 580:584:581,583 该快照为例,在判断可见性时,所有 txid<580 的并且已提交的 tuple 都是对当前快照可见的。所有 txid>=584 的 tuple 不管其状态如何,对当前快照都是不可见的。同时,由于 581 和 583 在获取快照时仍然处于活跃状态,因此对于该快照也是不可见的。最后,对于 txid 为 580 以及 582 的元组而言,只要其事务提交了,那么对当前快照来说就是可见的。
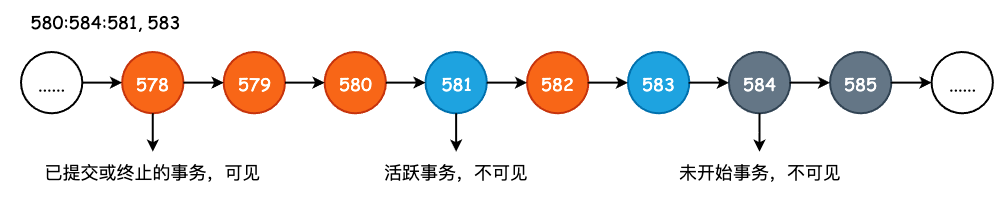
当然,这只是一个非常粗糙的判断规则,并没有考虑到元组是否被删除、是否被当前事务所创建、是否是对游标的可见性判断等情况。
PostgreSQL 使用结构体 SnapshotData 来表示所有类型的快照,并且通过函数 GetSnapshotData() 来获取事务快照。该函数最重要的功能就是填充 xmin、xmax 以及 xip 这三个核心字段:
```html
typedef struct SnapshotData {
SnapshotType snapshot_type; /* type of snapshot */
TransactionId xmin; /* all XID< xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
/*
* 正在运行的事务 txid 列表
* note: all ids in xip[] satisfy xmin<= xip[i] < xmax
*/
TransactionId *xip;
uint32 xcnt; /* # of xact ids in xip[] */
......
}
基本的可见性判断
在PostgreSQL中,事务一共有4种状态,分别是:
- TRANSACTION_STATUS_IN_PROGRESS: 事务正在运行中
- TRANSACTION_STATUS_COMMITTED: 事务已提交
- TRANSACTION_STATUS_ABORTED: 事务已回滚
- TRANSACTION_STATUS_SUB_COMMITTED: 子事务已提交
其中子事务的情况本文暂且不做考虑,同时本小节也不讨论关于 cid 的可见性判断,也就是游标的可见性判断,与游标相关的可见性判断将于在下篇文章中描述。
在读取堆元组的时PostgreSQL将使用 HeapTupleSatisfiesMVCC() 函数判断是否对读取的tuple可见,其函数签名如下:
static bool
HeapTupleSatisfiesMVCC(Relation relation, HeapTuple htup, Snapshot snapshot,
Buffer buffer)
接下来的可见性规则其实就是对该函数的拆解。
xmin 的状态为 ABORTED
首先来看一个最简单的情况,但我们开启一个事务并已经获取了一个快照,并且需要对一个tuple进行可见性判断时,如果发现该tuple的 xmin 所对应的事务状态为 ABORTED,即已经回滚了,那么这一条"废数据"对当前快照当然不可见。
if (!HeapTupleHeaderXminCommitted(tuple)) { /* 事务状态为未提交 */
if (HeapTupleHeaderXminInvalid(tuple)) { /* 事务已终止 */
return false; /* 不可见 */
}
}
xmin 的状态为 IN_PROGRESS
当创建元组的事务正在进行时,按理来说这部分数据对当前快照是不可见的,但是唯一的例外就是当前事务自己创建了该元组,并在后续使用SELECT语句进行了查看。那么此时,该元组对于当前快照来说就是可见的:
if (!HeapTupleHeaderXminCommitted(tuple)) {
if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmin(tuple))) {
if (tuple->t_infomask & HEAP_XMAX_INVALID) /* 未被当前事务删除 */
return true;
}
/* 该元组在进行中,并且插入语句不由当前事务执行,则不可见 */
return false;
}
xmin 的状态为 COMMITTED
当创建元组的事务已提交,如果该元组没有被删除,以及不在当前快照的活跃事务列表中的话,那么是可见的。
/* xmin is committed, but maybe not according to our snapshot */
if (!HeapTupleHeaderXminFrozen(tuple) &&
XidInMVCCSnapshot(HeapTupleHeaderGetRawXmin(tuple), snapshot))
return false; /* 创建元组的事务在获取快照时还处理活跃状态,故快照不应看到此条元组 */
/* by here, the inserting transaction has committed */
if (tuple->t_infomask & HEAP_XMAX_INVALID) /* 元组未被删除,即xmax无效 */
return true;
/* 元组被删除,但删除元组的事务正在进行中,尚未提交 */
if (!(tuple->t_infomask & HEAP_XMAX_COMMITTED)) {
/* 若删除行为是当前事务自己进行的,则删除有效,但是仍然需要进行游标的判断 */
if (TransactionIdIsCurrentTransactionId(HeapTupleHeaderGetRawXmax(tuple))) {
if (HeapTupleHeaderGetCmax(tuple) >= snapshot->curcid)
return true; /* deleted after scan started */
else
return false; /* deleted before scan started */
}
/* 删除行为不是本事务执行的,并且在删除元组的事务在获取快照时还处理活跃状态,故删除无效 */
if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmax(tuple), snapshot))
return true;
} else {
/* 删除元组事务已提交,但是在删除元组的事务在获取快照时还处理活跃状态,故删除无效 */
if (XidInMVCCSnapshot(HeapTupleHeaderGetRawXmax(tuple), snapshot))
return true; /* treat as still in progress */
}
/* 删除元组事务已提交且不在快照的活跃事务中,即删除有效,不可见 */
return false;
xmin 的状态为 COMMITTED 的情况要稍微复杂一些,需要综合考虑 xmax、xip 以及 cid 之间的关系。
可见性判断函数与获取快照的时机
最后,我们来看一下可见性判断函数,在不同的场景下,我们观察一个堆元组的视角也不尽相同,因此就需要调用不同的可见性判断函数来判断其可见性:
| 可见性判断函数 | 作用 |
| HeapTupleSatisfiesMVCC | 读取堆元组时所使用的可见性函数,是使用最为频繁的函数 |
| HeapTupleSatisfiesUpdate | 更新堆元组时所使用的可见性函数 |
| HeapTupleSatisfiesSelf | 不考虑事务之间的"相对时间因素"(即xip) |
| HeapTupleSatisfiesAny | 全部堆数据元组都可见,常见的使用场景是建立索引时(观察HOT链) |
| HeapTupleSatisfiesVacuum | 运行vacuum命令时所使用的可见性函数 |
同时,我们可能通过在不同的时机获取快照来实现不同的事务隔离级别。例如对于可重复读(RR)来说,只有事务的第一条语句才生成快照数据,随后的语句只是复用这个快照数据,以保证在整个事务期间,所有的语句对不同的堆元组具有相同的可见性判断依据。而对于读已提交(RC)来说,事务中的每条语句都会生成一个新的快照,以保证能够对其他事务已经提交的元组可见。
MVCC的使用场景和限制
```多版本并发控制(MVCC)在数据库系统中提供了强大的并发控制和事务隔离能力,但它也有特定的使用场景和一些限制。以下是MVCC的主要使用场景和限制:
使用场景
- 高并发环境:
- MVCC非常适合需要处理大量并发读写操作的应用程序,如在线交易系统、社交网络平台和电子商务网站。
- 由于读操作不需要加锁,系统可以在高并发情况下高效地处理读请求。
- 需要强一致性的应用:
- 应用程序需要在事务中保证数据的一致性时,MVCC可以提供良好的事务隔离,避免读到未提交的数据。
- 适用于金融系统等对数据一致性要求严格的场景。
- 长时间运行的查询:
- 在需要长时间运行的分析型查询中,MVCC允许这些查询在不被中断的情况下读取一致的快照数据。
- 这对于需要进行复杂报告和数据分析的应用程序特别有用。
- 减少锁竞争的场合:
- 在存在大量读操作的场景中,MVCC可以有效减少锁竞争,提高系统的整体吞吐量。
限制
- 存储空间消耗:
- 由于MVCC会为每次更新创建新的数据版本,可能会导致数据库存储空间的增加。
- 需要定期运行VACUUM操作来清理过时的行版本,以释放存储空间。
- 管理复杂性:
- MVCC的实现需要维护多个版本的数据,这增加了数据库管理的复杂性。
- 数据库管理员需要更频繁地进行性能调优和空间管理。
- 性能开销:
- 虽然MVCC减少了锁的使用,但在某些情况下,尤其是高写入负载下,管理多个版本的数据可能会带来额外的性能开销。
- 长时间运行的事务可能会阻止旧版本的清理,导致性能下降。
- 事务ID耗尽:
- 在极端情况下,事务ID可能会耗尽(事务ID是一个有限的数值),这需要数据库采取措施(如冻结和重置事务ID)来避免问题。
- 写-写冲突:
- 虽然MVCC减少了读-写冲突,但写-写冲突仍然需要通过锁机制来解决。
MVCC通过提供细粒度的并发控制,解决了许多传统数据库锁机制中的瓶颈问题。然而,它也带来了管理上的挑战,需要在使用时综合考虑应用的特定需求和系统的性能特点。


