Scrapy是一个Python爬虫框架,用于快速、高效地抓取网页数据。它通过异步方式处理HTTP请求和响应,支持多线程和分布式部署,可以方便地从互联网上获取大量的结构化数据。
使用Python来做抓取程序非常的方便,比较简单的方式是使用Requests包进行抓取。Scrapy相对来说更加复杂。但是功能更加强大。特别适合漫游式的抓取。
以下是Scrapy的一些重要特性:
- 快速高效的异步处理机制:Scrapy使用Twisted库实现异步I/O,可以同时发送多个HTTP请求并几乎不受阻塞,可大幅提升爬取效率。
- 灵活的数据提取方法:Scrapy支持XPath和CSS选择器等多种数据提取方式,使得开发者可以灵活地从HTML或XML中抽取所需的信息。
- 全面的错误处理机制:Scrapy提供了丰富的异常处理机制,能够有效地捕获和处理各种异常情况,比如网络错误、HTTP错误、解析错误等。
- 方便的数据存储方式:Scrapy可以将数据直接存储到本地文件、数据库或其他数据存储系统中,并支持多种格式,比如CSV、JSON、XML、SQLite、MySQL等。
- 高度可定制化:Scrapy提供了丰富的配置选项和插件接口,可以满足各种爬虫场景的需求,并支持自定义中间件、扩展、管道、下载器等组件。
Scrapy是一个强大的Python爬虫框架,它有以下优点:
- 快速高效:Scrapy使用Twisted异步网络库实现了异步I/O和并发请求,可以快速、高效地抓取网页。
- 方便易用:Scrapy提供了丰富的数据提取方法和事件处理机制,使得开发者可以轻松地完成数据抓取任务。
- 可扩展性强:Scrapy支持多个插件,包括自定义中间件、下载器、扩展和管道等,为用户提供了高度可定制化的选择。
- 高度灵活:Scrapy的编写方式非常灵活,用户可以根据需要编写各种类型的爬虫程序,并且还支持在运行时修改配置,以及动态加载模块等功能。
- 大量的文档和资源:Scrapy有着广泛的社区支持,并且提供了详细的文档、教程和示例代码,可以帮助开发者更好地使用它。
然而,Scrapy也存在一些缺点:
- 学习曲线较陡峭:由于Scrapy具有很多灵活性和可扩展性,因此初次接触可能需要花费一些时间来学习相关的概念和技术。
- 技术要求较高:Scrapy要求用户掌握Python编程和XPath/CSS选择器等前端技术,对非专业开发人员来说可能有一定的难度。
- 网站反爬虫机制:随着互联网的不断发展,越来越多的网站开始采取反爬虫措施,这给Scrapy的使用带来了一定的挑战。
总之,Scrapy是一款功能强大、灵活高效的Python爬虫框架,适合各种类型的Web数据抓取任务,但是也需要开发者具备一定的技术能力和知识储备。
Scrapy框架简介
下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程。下面就来一个个解释每个组件的作用及数据的处理过程。
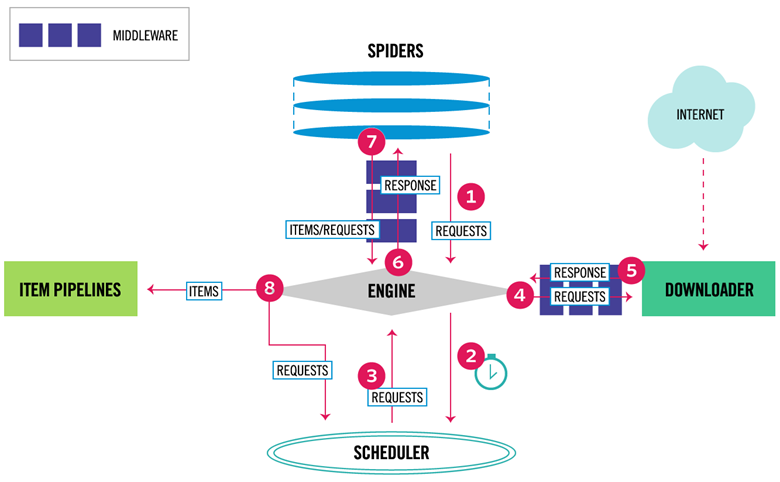
Scrapy的组成
- Scrapy Engine(Scrapy引擎) Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。更多的详细内容可以看下面的数据处理流程。
- Scheduler(调度) 调度程序从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
- Downloader(下载器) 下载器的主要职责是抓取网页并将网页内容返还给蜘蛛(Spiders)。
- Spiders(蜘蛛) 蜘蛛是有Scrapy用户自己定义用来解析网页并抓取制定URL返回的内容的类,每个蜘蛛都能处理一个域名或一组域名。换句话说就是用来定义特定网站的抓取和解析规则。
- Item Pipeline(项目管道) 项目管道的主要责任是负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清洗、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。每个项目管道的组件都是有一个简单的方法组成的Python类。他们获取了项目并执行他们的方法,同时他们还需要确定的是是否需要在项目管道中继续执行下一步或是直接丢弃掉不处理。
- Downloader middlewares(下载器中间件) 下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。下载中间件是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
- Spider middlewares(蜘蛛中间件) 蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蜘蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
- Scheduler middlewares(调度中间件) 调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
蜘蛛的整个抓取流程(周期)是这样的:
- 首先获取第一个URL的初始请求,当请求返回后调取一个回调函数。第一个请求是通过调用start_requests()方法。该方法默认从start_urls中的Url中生成请求,并执行解析来调用回调函数。
- 在回调函数中,你可以解析网页响应并返回项目对象和请求对象或两者的迭代。这些请求也将包含一个回调,然后被Scrapy下载,然后有指定的回调处理。
- 在回调函数中,你解析网站的内容,同程使用的是Xpath选择器(但是你也可以使用BeautifuSoup, lxml或其他任何你喜欢的程序),并生成解析的数据项。
- 最后,从蜘蛛返回的项目通常会进驻到项目管道。
项目管道通常执行的过程有:
- 清洗HTML数据
- 验证解析到的数据(检查项目是否包含必要的字段)
- 检查是否是重复数据(如果重复就删除)
- 将解析到的数据存储到数据库中
下载器中间件的使用场景:
- 在将请求发送给下载者之前处理该请求(即在Scrapy将请求发送到网站之前);
- 变更在传递给spider之前收到响应;
- 发送新的请求,而不是将收到的响应传递给spider;
- 在不获取网页的情况下将响应传递给蜘蛛;
- 悄悄地放弃一些请求。
蜘蛛中间件的使用场景:
- spider回调的后处理输出-更改/添加/删除请求或项;
- 后处理启动请求;
- 处理spider异常;
- 对一些基于响应内容的请求调用errback,而不是回调。
核心API与组件
Scrapy是一个功能强大的Python爬虫框架,其中包含了多个核心组件,以下是Scrapy的几个重要组件介绍:
- Request用于封装HTTP请求,包括请求URL、请求方法、请求头信息、请求体等内容。它是Scrapy的核心组件之一,每个Spider都可以发送多个Request对象到指定的URL,并处理响应结果。
- 使用Scrapy框架时,通常会在Spider中实例化Request对象,然后通过Scrapy引擎将这些对象分发给下载器进行下载。在下载完成后,下载器会将响应结果封装成Response对象返回给Spider进行处理。
- Response用于封装HTTP响应,包括状态码、响应头信息、响应体等内容。它也是Scrapy的核心组件之一,用于存储从网站上获取到的数据。
- Selector是Scrapy中的数据提取工具,它可以从HTML或XML中提取出需要的数据,并以Unicode字符串的形式返回。Selector支持多种数据提取方法,包括XPath和CSS选择器。
- 使用Selector可以有效地将网页中的数据抽取出来,从而进行进一步的处理和分析。可以将其看作是一种基本的数据预处理工具,帮助我们快速完成数据清洗和格式化。
- Spider是Scrapy中最为重要的一个组件,用于定义爬虫的逻辑和流程。Spider可以从一个或多个URL开始,逐步地跟踪链接,抓取数据并存储到本地文件或数据库中。
- 在Spider中,我们可以通过编写回调函数来处理Response对象,并根据需要进行下一步的数据提取或跟进链接。同时,Spider还支持设置各种参数和配置选项,比如起始URL、数据提取规则、翻页方式、请求延迟等。
- Item是Scrapy中用于表示爬虫抓取的数据模型,在Spider中通过Selector解析出数据后封装成Item对象返回。Item相当于爬虫程序中的一条记录,包含了多个字段和对应的值。
- 在Scrapy中,我们需要在项目中先定义Item的结构,然后在Spider中实例化Item,并将提取到的数据赋值给Item对象相应的字段。最后,Scrapy会将所有的Item对象交给Pipeline组件进行后续的处理。
- Pipeline是Scrapy中的数据处理管道,用于对Item对象进行处理,包括数据清洗、去重、存储等操作。Pipeline可以同时存在多个,并且按照优先级顺序依次执行。
- 在Scrapy中,我们可以通过编写Pipeline类来实现自定义的数据处理逻辑。每个Pipeline都需要实现三个方法:process_item(self, item, spider)、open_spider(self, spider)和close_spider(self, spider)。其中,process_item()方法是Pipeline的核心方法,用于处理Item对象。
在Spider中,我们可以通过XPath或CSS选择器等方式对Response进行解析,提取想要的数据。同时,Scrapy提供了一些方便的方法和属性,如xpath()、css()、text、status等,可以帮助我们更加方便地操作Response对象。
Scrapy的数据处理流程
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
- 引擎打开一个域名,时蜘蛛处理这个域名,并让蜘蛛获取第一个爬取的URL。
- 引擎从蜘蛛那获取第一个需要爬取的URL,然后作为请求在调度中进行调度。
- 引擎从调度那获取接下来进行爬取的页面。
- 调度将下一个爬取的URL返回给引擎,引擎将他们通过下载中间件发送到下载器。
- 当网页被下载器下载完成以后,响应内容通过下载中间件被发送到引擎。
- 引擎收到下载器的响应并将它通过蜘蛛中间件发送到蜘蛛进行处理。
- 蜘蛛处理响应并返回爬取到的项目,然后给引擎发送新的请求。
- 引擎将抓取到的项目管道,并向调度发送请求。
- 系统重复第二部后面的操作,直到调度中没有请求,然后断开引擎与域之间的联系。
Scrapy的安装与使用
在几年前安装Scrapy的时候应该比较繁琐,现在好像只要使用pip install scrapy即可完成安装。
使用Scrapy进行爬虫开发的一般步骤如下:
- 创建Scrapy项目:在命令行中使用scrapy startproject命令创建一个Scrapy项目,包括配置文件、Spider、Item、Pipeline等组件。
- 编写Spider:在Scrapy项目中编写Spider,定义起始请求URL、数据提取规则、如何跟进链接等内容,通常采用基于回调函数的方式实现。
- 定义Item:在Scrapy项目中定义Item,即要抓取的数据模型,在Spider中通过Selector解析出数据后封装成Item对象返回。
- 编写Pipeline:在Scrapy项目中定义Pipeline,用于处理Item对象,进行数据清洗、去重、存储等操作。
- 启动和运行爬虫:使用命令行工具启动Scrapy爬虫,即可开始抓取数据并存储到指定的数据源中。
在使用Scrapy进行爬虫开发时,应该注意以下几点:
- 网站的反爬虫措施:随着互联网发展,越来越多的网站采取了反爬虫措施,比如IP封禁、验证码、限制访问频率等。为了避免被反爬虫机制拦截,需要采取相应的对策,比如使用代理IP、设置User-Agent、添加延迟等。
- 安全性问题:在进行爬虫开发时,一定要尊重网站的合法权益,并且遵守相关法律法规和道德规范。不得在未经授权的情况下窃取他人数据,也不能对网站造成损失或影响正常运行。
- 数据质量问题:爬虫抓取到的数据可能存在噪声、空值、重复等问题,需要进行清洗和去重处理,保证数据的质量和可用性。
- 代码可维护性:Scrapy支持高度的定制化和扩展性,但是也需要考虑代码的可读性、可维护性和稳定性等因素,比如注释、变量命名、异常处理、日志记录等。
- 不断更新的技术和知识:由于互联网信息更新速度快,新的网站和新的反爬虫技术层出不穷,因此需要不断学习和掌握最新的技术和知识,以提高爬虫开发的效率和准确性。
以下是Scrapy最佳使用实践:
- 设置User-Agent。在发送请求时,设置合适的User-Agent可以模拟浏览器行为,降低被网站认为是爬虫的概率。可以使用随机User-Agent或者从一个User-Agent列表中选择一个合适的进行设置。
- 关闭重定向。有些网站会通过302重定向来限制爬虫行为,可以通过在Scrapy中设置REDIRECT_ENABLED=False来关闭重定向功能,从而避免被反爬虫机制拦截。
- 定期更换IP。为了防止被网站封禁IP,可以定期更换IP,也可以使用代理IP进行访问。
- 使用分布式爬虫。对于大规模的数据抓取任务,可以采用分布式爬虫的方式,并使用消息队列等技术来进行协调和管理,提高爬虫的效率和可扩展性。
- 缓存数据。如果某些数据非常耗时,建议将其缓存起来,不必每次都重新获取。可以使用Python的内置缓存库或者第三方缓存库,比如Redis、Memcached等。
- 遵循ROBOT协议。ROBOT协议是指网站所有者创建的一种协议,用于告诉爬虫哪些页面可以爬取,哪些页面不能爬取。在进行爬虫开发时,应该遵循ROBOT协议,避免对网站造成不必要的影响。
- 数据清洗和去重。在进行数据处理时,需要进行数据清洗和去重操作,保证数据的质量和准确性。可以使用Python的内置工具或者第三方库进行处理和过滤,比如Pandas、NumPy等。
参考链接:


