Newspaper3k Newspaper3k 是一个专门用于新闻文章抓取和内容提取的Python库。该项目由 Lucas Ou-Yang 开发,灵感来源于Requests库的简洁性,底层使用lxml实现高效解析。 核心特性 文章内容提取 自…

requests-html简介 requests-html是一个用于网页抓取和解析的Python库,由Kenneth Reitz创建,旨在为开发者提供一个强大且易用的工具来处理HTML内容。与传统的网页抓取库不同,requests-html集成了对现代网页技术(…

PyQuery是一个用于解析和操作HTML文档的Python库,灵感来自于jQuery,提供了一种简洁且强大的方式来处理HTML文档。它允许开发者使用类似于jQuery的CSS选择器来查找和操作HTML元素,这使得处理网页数据变得直观和高…

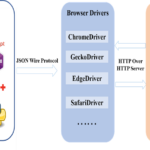
Selenium简介 Selenium是浏览器的自动化测试工具,与浏览器进行交互,实现对web应用的自动化测试,Selenium包括Selenium IDE, Selenium Webdriver和Selenium Grid三个工具。 Selenium IDE (Integrated Developmen…
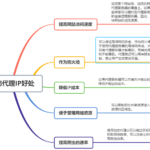
随着互联网的发展,网站的反爬虫技术也在不断提升。其中最常见的一种手段就是对IP地址进行封禁,防止爬虫程序访问网站。为了避免这种情况的发生,爬虫程序需要使用动态IP代理来隐藏自己的真实IP地址。本文将介绍Pyt…
用户代理 User-Agent 客户端向服务器请求一张页面时,可以额外附上一些自己的信息(如使用什么操作系统、什么浏览器),以便让服务器提供更好的服务(如根据不同设备返回不同的页面)。额外附上的信息叫请求头(HTT…

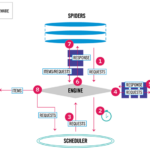
Scrapy是一个Python爬虫框架,用于快速、高效地抓取网页数据。它通过异步方式处理HTTP请求和响应,支持多线程和分布式部署,可以方便地从互联网上获取大量的结构化数据。 使用Python来做抓取程序非常的方便,比较…
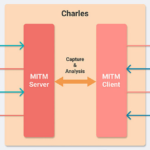
Charles简介 Charles是一个HTTP代理服务器,当浏览器连接Charles的代理访问互联网时,Charles可以监控浏览器发送和接收的所有数据。它允许一个开发者查看所有连接互联网的HTTP通信,这些包括request, response和HTT…