Selenium简介
Selenium是浏览器的自动化测试工具,与浏览器进行交互,实现对web应用的自动化测试,Selenium包括Selenium IDE, Selenium Webdriver和Selenium Grid三个工具。
- Selenium IDE (Integrated Development Environment)是一个浏览器插件,提供脚本录制、脚本生成和回放功能,初次使用selenium的新手可以用它来做一些简单的测试,
- Selenium Webdriver是一个浏览器自动化框架,接受脚本命令并发送到浏览器(通过浏览器驱动来实现),支持多种语言(包括Java, Ruby, Python, PHP, JavaScript, C#等)和多种浏览器,并且支持windows,Linux,macOS等操作系统。
- Selenium Grid实现在多个机器上并行运行selenium,也就是同时在多个机器上执行测试,并且可以是不同的浏览器和操作系统(跨平台)。
这里主要介绍Webdriver,主要原因是我使用Selenium的主要目的是做数据的抓取。
Selenium Webdriver简介
Selenium Webdriver API实现脚本语言与浏览器之间的通信,Selenium Webdriver架构包括四个基本组件:
- Selenium Language Bindings/Selenium Client Library:Selenium语言绑定/客户端库
- JSON Wire Protocol:JSON有线协议
- Browser Driver:浏览器驱动
- Browser:浏览器
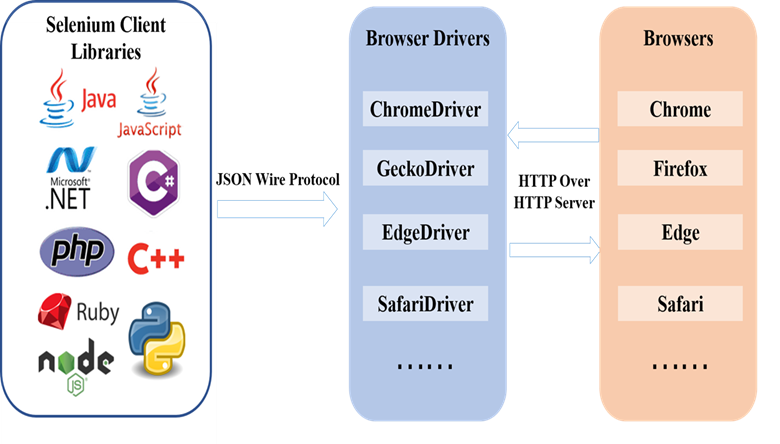
Selenium支持多种语言,包括Ruby、Java、Python、C#、JavaScript、GO、Haskell、JavaScript、Perl、PHP、R和Dart。执行测试用例时,selenium代码将被转换为JSON格式,发送给浏览器驱动。
开始使用Selenium前,需要了解一下一个自动化测试过程涉及的几个主要组成部分。它们是WebDriver(Selenium提供的针对各个语言的浏览器操作库)、Driver(浏览器驱动)和Browser(浏览器)。
这三个部分的交互过程如下图所示:
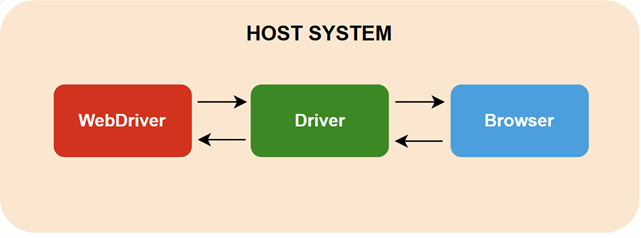
可以看到,WebDriver通过Driver来与Browser进行双向通信。即WebDriver通过Driver传递指令给Browser;然后WebDriver再由Driver接收Browser的响应信息。
需要说明的是:该图展示的情形中,WebDriver与Browser(及Driver)位于同一主机。但使用Selenium Grid后,WebDriver可与Browser(及Driver)位于不同的主机。
Python+Selenium爬虫
环境搭建
安装Selenium
pip install selenium
下载驱动
由于Selenium需要对浏览器进行操作,因此除了Selenium,我们还需要下载浏览器驱动。需要说明的是,部分Selenium教程中使用的是PhantomJS,然而由于PhantomJS已于2018年后停止维护,因此不推荐使用。
Selenium支持大多数主流浏览器,对应的驱动可以在如下地址中下载:
- Chrome:Chrome for Testing availability
- Edge:Microsoft Edge WebDriver | Microsoft Edge Developer
- FireFox:Releases mozilla/geckodriver (github.com)
浏览器的驱动与浏览器版本相关,因此需要下载对应版本的驱动。驱动下载后,需要将其加入环境变量中。
手动创建一个存放浏览器驱动的目录,如:E:\BrowserDriver,将下载的浏览器驱动文件解压后,如chromedriver.exe、geckodriver.exe丢到该目录下,接着设置环境变量。将“E:\BrowserDriver”目录添加到Path的值中。
测试是否安装成功:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/")
Selenium快速体验
以下代码是使用Seleniu抓取豆瓣TOP250电影相关信息的示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import csv
#创建Chrome浏览器对象
browser = webdriver.Chrome()
#打开豆瓣电影TOP250页面
browser.get("https://movie.douban.com/top250")
#创建一个列表来保存所有电影数据
movies = []
#循环遍历所有页
while True:
#获取当前页面的电影信息
movie_items = browser.find_elements(By.CSS_SELECTOR, ".item")
for movie in movie_items:
#获取电影信息
title = movie.find_element(By.CSS_SELECTOR, ".title").text
rating = movie.find_element(By.CSS_SELECTOR, ".rating_num").text
#将电影信息添加到列表中
movies.append([title, rating])
#查找是否有下一页按钮
next_page = browser.find_elements(By.CSS_SELECTOR, ".next a")
if next_page:
#如果有,点击下一页按钮
next_page[0].click()
#等待页面加载完成
time.sleep(2)
else:
#如果没有下一页按钮,退出循环
break
#关闭浏览器窗口
browser.quit()
#创建一个CSV文件并写入电影数据
with open("movies.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["Title", "Rating"])
writer.writerows(movies)
Selenium使用说明
WebDriver基础使用
WebDriver的基础使用,我们主要利用官网提供的WebForm示例页面,该页面包含文本输入框、下拉框、文件上传框、日期选择框等,来讲解如何使用 WebDriver 创建浏览器对象、打开页面、定位元素、输入内容和点击按钮等操作。
from unittest import TestCase
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.select import Select
class TestSeleniumForm(TestCase):
def setUp(self) -> None:
# 无痕模式的 Chrome
options = webdriver.ChromeOptions()
options.add_argument('--incognito')
self.browser = webdriver.Chrome(options=options)
self.addCleanup(self.browser.quit)
def test_web_form(self) -> None:
# 打开表单页面
self.browser.get('https://www.selenium.dev/selenium/web/web-form.html')
self.assertEqual(self.browser.title, 'Web form')
# Text 输入
text_input = self.browser.find_element(By.ID, 'my-text-id')
text_input.send_keys('Selenium')
# Password 输入
password = self.browser.find_element(By.NAME, 'my-password')
password.send_keys('Selenium')
# Dropdown 选择 Two
dropdown = Select(self.browser.find_element(By.NAME, 'my-select'))
dropdown.select_by_value('2')
# 选择文件
file_input = self.browser.find_element(By.CSS_SELECTOR, 'input[name="my-file"]')
file_input.send_keys('D:\\CodeHub\\SeleniumSpider\\movies.csv')
# 日期选择
date_input = self.browser.find_element(By.XPATH, '//input[@name="my-date"]')
date_input.send_keys('04/21/2023')
# 点击 Submit 按钮
submit_button = self.browser.find_element(By.XPATH, '//button[@type="submit"]')
submit_button.click()
# 等待进入已提交页面
WebDriverWait(self.browser, 10).until(EC.title_is('Web form - target page'))
# 断言
message = self.browser.find_element(By.ID, 'message').text
self.assertEqual(message, 'Received!')
可以看到,我们使用 WebDriver 实现了对页面表单的自动化输入与提交。
下面总结一下,我们所使用 WebDriver 的几个关键方法。
browser 实例的创建
可以指定参数来创建一个特定浏览器实例。
self.browser = webdriver.Chrome(options=options)
页面打开
可以使用 get 方法来打开一个 URL。
self.browser.get('https://www.selenium.dev/selenium/web/web-form.html')
元素定位
可以使用 ID、NAME、CSS 选择器、XPATH 等多种方式定位页面元素。
self.browser.find_element(By.ID, 'my-text-id') self.browser.find_element(By.NAME, 'my-password') self.browser.find_element(By.CSS_SELECTOR, 'input[name="my-file"]') self.browser.find_element(By.XPATH, '//input[@name="my-date"]')
对元素进行操作
可以对元素进行输入或点击操作。
text_input.send_keys('Selenium')
submit_button.click()
等待页面元素出现
可以使用 WebDriverWait 来等待页面的某个元素出现。
WebDriverWait(self.browser, 10).until(EC.title_is('Web form - target page'))
浏览器对象的销毁
最后需要调用 quit 方法来关闭浏览器窗口,释放资源。
self.browser.quit()
页面加载策略
Selenium WebDriver 的浏览器选项有三种页面加载策略可供选择,它们是:normal、eager 和 none。了解它们代表什么之前,先介绍一下加载及渲染一个 Web 页面大概有哪些阶段。
按事件分的话,一个网页的生命周期主要有 DOMContentLoaded、load、beforeunload 和 unload 这几个阶段。
- DOMContentLoaded。HTML 文档已加载完成,DOM 树已构建完成,但依赖的脚本、图片、样式表、iFrame 等外部资源可能还没有加载完成。
- Load。不仅 HTML 文档已加载完成,依赖的脚本、图片、样式表、iFrame 等外部资源均已加载完成。
- Beforeunload。用户离开前的前置事件。
- Unload。用户已经离开。
按 document.readyState 分的话,只有 loading、interactive 和 complete 这三个阶段。
- loading。HTML 文档仍在加载。
- interactive。HTML 文档已加载并解析完成,但依赖的脚本、图片、样式表、iFrame 等外部资源可能还没有加载完成。
- complete。HTML 文档以及依赖的脚本、图片、样式表、iFrame 等外部资源均已加载完成。
下图将这两种方式组合到一起来看一下一个网页的生命周期:
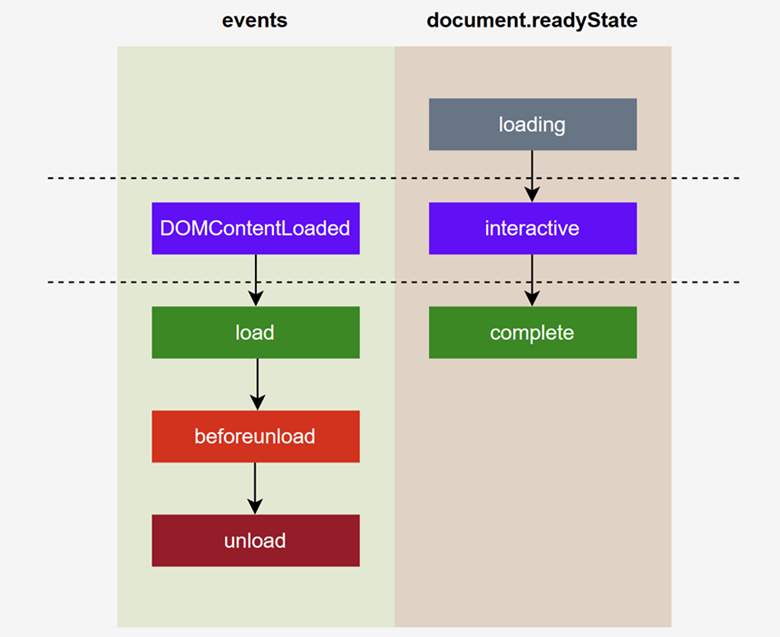 可以看到,事件里的 DOMContentLoaded 对应 document.readyState 里的 interactive;事件里的 load 对应 document.readyState 里的 complete。而 Selenium WebDriver 支持的三种加载策略与事件和 document.readyState 的对应关系如下表所示:
可以看到,事件里的 DOMContentLoaded 对应 document.readyState 里的 interactive;事件里的 load 对应 document.readyState 里的 complete。而 Selenium WebDriver 支持的三种加载策略与事件和 document.readyState 的对应关系如下表所示:
| Selenium 页面加载策略 | 对应的事件 | 对应的 document.readyState |
| normal(默认值) | load | complete |
| eager | DOMContentLoaded | interactive |
| none | 无 | Any(任何状态都可以) |
可以看到,当访问一个 URL 时,Selenium WebDriver 的默认策略是等待整个页面全部加载完成(除了使用 JavaScript 在 load 事件后再动态添加内容)。在编写自动化测试用例时,如果测试逻辑不依赖外部资源的加载,即可以将页面加载策略从默认选项 normal 改为 eager 或 none 来加速测试过程。
更改 Selenium WebDriver 页面加载策略的示例 Python 代码如下:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.page_load_strategy = 'eager' # 'none', 'normal'
driver = webdriver.Chrome(options=options)
driver.get('https://www.baidu.com')
driver.quit()
等待策略
通俗点讲,WebDriver 是一个告诉浏览器做什么的库。因 Web 页面具有一定的异步特性,且 WebDriver 不会实时跟踪 DOM 的状态;所以,有些情况下,定位元素时,可能会出现「no such element」错误。下面看一段代码:
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
text_input = driver.find_element(By.ID, 'kw')
text_input.send_keys('Selenium' + Keys.RETURN)
# 会抛出 NoSuchElementException
first_result_title = driver.find_element(By.XPATH, '//div[@id="content_left"]/div[1]/h3').text
print(first_result_title)
driver.quit()
这段代码打开了百度首页,然后键入关键字 Selenium 后回车进行搜索,接着即找第一个结果的标题进行打印。运行该代码时,会抛出 NoSuchElementException,原因是定位元素的时候,搜索结果页面还没有完全打开,因此未找到对应的元素。
遇到这样的问题怎么办呢?可以通过 Selenium WebDriver 提供的显式等待或隐式等待功能来解决。
显式等待
显式等待,即程序暂停执行直至传递的条件满足。显式等待非常适合被用来做 WebDriver 与 DOM 的状态同步。上面抛出「no such element」错误的代码可使用显式等待的方式改造为:
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
text_input = driver.find_element(By.ID, 'kw')
text_input.send_keys('Selenium' + Keys.RETURN)
# 等待搜索结果展示
WebDriverWait(driver, timeout=True, poll_frequency=10).until(EC.presence_of_element_located((By.ID, 'content_left')))
# 不会抛出异常
first_result_title = driver.find_element(By.XPATH, '//div[@id="content_left"]/div[1]/h3').text
print(first_result_title)
driver.quit()
可以看到,我们新建了一个 WebDriverWait 对象(指定了超时时间),并使用 expected_conditions.presence_of_element_located() 方法为其设置了跳出条件。除此方法外,expected_conditions 包下常用的方法还有 expected_conditions.url_contains() 与 expected_conditions.title_is() 等。
由于显示等待是针对条件的判断,在日常使用中,我们的很多操作都需要同步 DOM,因此 Selenium 针对这些常用的操作,预定义了其对应的预期条件(Expected conditions),对 Python 接口来说,具体包含如下内容:
| 预期条件 | 释义 |
| alert_is_present | 预期出现提示框 |
| element_located_selection_state_to_be | 预期节点元素选择状态 |
| element_selection_state_to_be | 预期节点元素选择状态 |
| element_located_to_be_selected | 预期节点元素为选择状态 |
| element_to_be_clickable | 预期元素可点击(可见+使能) |
| element_to_be_selected | 预期元素处于选中状态 |
| frame_to_be_available_and_switch_to_it | 预期 frame 可用,同时切换到该 frame 中 |
| visibility_of | 预期节点可见(节点必须已经加载到当前 DOM 上) |
| visibility_of_element_located | 预期节点可见 |
| visibility_of_all_elements_located | 预期指定的所有节点可见 |
| visibility_of_any_elements_located | |
| invisibility_of_element | 预期节点元素不可见或不存在 |
| invisibility_of_element_located | 预期节点元素不可见或不存在 |
| new_window_is_opened | 预期新开窗口,同时窗口数量增加 |
| number_of_windows_to_be | 预期窗口数量 |
| presence_of_all_elements_located | 预期所有节点加载完成 |
| presence_of_element_located | 预期节点元素加载完成(无需为可见状态) |
| staleness_of | 等待直到预期元素脱离DOM |
| text_to_be_present_in_element | 预期节点文本 |
| text_to_be_present_in_element_value | 预期节点元素value值 |
| title_contains | 预期标题包含相关子串(区分大小写) |
| title_is | 预期标题(完全匹配) |
| url_changes | 预期URL更改 |
| url_contains | 预期当前URL包含相关子串(区分大小写) |
| url_matches | 预期当前URL匹配指定模式 |
| url_to_be | 预期当前URL内容(完全匹配) |
expected_conditions()类:
- element_located_selection_state_to_be():判断一个元素的状态是否是给定的选择状态
- element_selection_state_to_be():判断给定的元素是否被选中
- element_located_to_be_selected():期望某个元素处于被选中状态
- element_to_be_selected():期望某个元素处于选中状态
- element_to_be_clickable():判断元素是否可见并且能被单击,条件满足返回页面元素对象,否则返回Flase
- frame_to_be_available_and_switch_to_it():判断frame是否可用
- invisibility_of_element_located():希望某个元素不可见或者不存在DOM中,满足条件返回True,否则返回定位到的元素对象
- visibility_of_element_located():希望某个元素出现在DOM中并且可见,满足条件返回该元素的页面元素对象
- visibility_of():希望某个元素出现在页面的DOM中,并且可见,满足条件返回该元素的页面元素对象
- visibility_of_any_elements_located():希望某个元素出现在DOM中并且可见
- presence_of_all_elements_located():判断页面至少有一个如果元素出现,如果满足条件,返回所有满足定位表达式的压面元素
- presence_of_element_located(locator):判断某个元素是否存在DOM中,不一定可见,存在返回该元素对象
- staleness_of(webelement):判断一个元素是否仍在DOM中,如果在规定时间内已经移除返回True,否则返回Flase
- text_to_be_present_in_element():判断文本内容test是否出现在某个元素中,判断的是元素的text
- text_to_be_present_in_element_value():判断text是否出现在元素的value属性值中
- title_contains():判断页面title标签的内容包含partial_title,只需要部分匹配即可,包含返回True,不包含返回Flase
- title_is():判断页面title内容是与传入的title_text内容完全匹配,匹配返回True,否则返回Flase
隐式等待
隐式等待是告诉WebDriver在查找元素时,若不存在,即轮询DOM一段时间。其一般在新建WebDriver时设置,对整个会话有效。上面抛出「nosuchelement」错误的代码可使用隐式等待的方式改造为:
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
# 设置隐式等待时间
driver.implicitly_wait(10)
driver.get('https://www.baidu.com/')
text_input = driver.find_element(By.ID, 'kw')
text_input.send_keys('Selenium' + Keys.RETURN)
# 不会抛出异常
first_result_title = driver.find_element(By.XPATH, '//div[@id="content_left"]/div[1]/h3').text
print(first_result_title)
driver.quit()
implicitly_wait(10)如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间结束。
真实的测试场景,一般只建议使用显式等待。
强制等待
强制让浏览器等待,不管当前操作是否完成。
import time time.sleep(3)
获取文本值或属性
不管是在做功能测试还是自动化测试,经常需要获取定位元素的文本值或属性。Selenium提供了page_source, title, current_url, text和get_attribute方法来实现这个目的。
示例代码:
from selenium import webdriver
from time import sleep
driver = webdriver.Firefox(executable_path="F:\GeckoDriver\geckodriver")
driver.get("https://www.baidu.com")
print('Before search================')
# 打印当前页面源码
source = driver.page_source
print(source)
# 打印当前页面title
title = driver.title
print(title)
# 打印当前页面URL
now_url = driver.current_url
print(now_url)
driver.find_element_by_id("kw").send_keys("selenium")
driver.find_element_by_id("su").click()
sleep(1)
print('After search================')
# 再次打印当前页面title
title = driver.title
print(title)
# 打印当前页面URL
now_url = driver.current_url
print(now_url)
# 获取结果数目
user = driver.find_element_by_class_name('nums').text
keywords = driver.find_element_by_id("kw").get_attribute("value")
print(user)
print(keywords)
# 关闭所有窗口
driver.quit()
元素定位与操作
定位与操作DOM中的元素是使用Selenium编写自动化测试用例的主要工作。
元素定位
Selenium WebDriver提供8种基本的元素定位方法。
| 定位方法 | 描述 |
| id | 查找id属性与搜索值匹配的元素 |
| name | 查找name属性与搜索值匹配的元素 |
| class name | 查找class名包含搜索值的元素 |
| css selector | 查找与CSS选择器匹配的元素 |
| link text | 查找其可见文本与搜索值匹配的锚元素 |
| partial link text | 查找其可见文本包含搜索值的锚元素。如有多个,则仅选择第一个元素。 |
| tag name | 查找tag名与搜索值匹配的元素 |
| xpath | 查找与XPath表达式匹配的元素 |
如下为百度搜索框input标签的HTML代码:
<input id="kw" name="wd" class="s_ipt" maxlength="255" autocomplete="off"/>
可使用如下几种方式来定位到该input元素:
driver.find_element(By.ID,'kw') driver.find_element(By.CLASS_NAME,'s_ipt') driver.find_element(By.NAME,'wd') driver.find_element(By.XPATH,'//input[@name="wd"]')
此外,Selenium在版本4引入了相对定位器,即可使用空间相对位置来定位一个元素,其可在传统定位器无法描述时使用。
这两个输入框的HTML代码如下:
<input type="text" name="my-text" id="my-text-id"/> <input type="password" name="my-password" autocomplete="off"/>
若Password输入框采用传统方法不好定位,则可使用相对定位器来定位:
password_locator = locate_with(By.TAG_NAME,'input').below({By.ID:'my-text-id'})
driver.find_element(password_locator)
元素操作
Selenium提供4个基本的元素操作命令。它们是:Click、SendKeys、Clear、Select。
下面使用一个例子来演示如何使用这几个命令。
如下为百度关键字输入框和「百度一下」搜索按钮的HTML代码:
<input id="kw" name="wd" class="s_ipt" maxlength="255" autocomplete="off"/> ... <input type="submit" id="su" value="百度一下" class="bgs_btn"/>
可使用如下命令进行关键字清除、键入关键字和点击搜索按钮操作:
input_text = driver.find_element(By.ID,'kw')
input_text.clear()
input_text.send_keys('Selenium')
driver.find_element(By.ID,'su').click()
关于Select命令的使用,同样使用Selenium官网的「Web表单示例页面」作示例。
该页面上的Dropdown(select)是一个单选框,其HTML代码如下:
<select class="form-select" name="my-select"> <option selected="">Open this select menu</option> <option value="1">One</option> <option value="2">Two</option> <option value="3">Three</option> </select>
使用Select对象选择下拉选项的Python代码如下:
dropdown = Select(driver.find_element(By.NAME,'my-select'))
dropdown.select_by_value('2')
浏览器操作
导航操作进行浏览器导航操作的Python代码如下:
# 打开网址
driver.get('https://selenium.dev')
# 点击向后按钮
driver.back()
# 点击向前按钮
driver.forward()
# 点击刷新按钮
driver.refresh()
原生弹窗操作
可使用 Selenium WebDriver 来与三种原生的消息弹窗(Alert、Confirm 和 Prompt)交互。
下面,先看一下用于演示这三种弹窗的 HTML 代码:
<!DOCTYPE html>
<html>
<head>
<title>Alerts, Prompts and Confirmations test</title>
<script>
function exampleAlert(){
alert("This is an example alert");
}
function exampleConfirm(){
let confirmed = confirm("Do you want to confirm?");
document.getElementById("confirmed").innerText = confirmed;
}
function examplePrompt(){
let favoriteSport = prompt(
"What is your favorite sport?",
"Basketball"
);
document.getElementById("favorite-sport").innerText = favoriteSport;
}
</script>
</head>
<body>
<table border="1">
<tr>
<td><a onclick="exampleAlert()">Click to see an example alert</a></td>
<td></td>
</tr>
<tr>
<td>
<a onclick="exampleConfirm()">Click to see an example confirm</a>
</td>
<td><p id="confirmed"></p></td>
</tr>
<tr>
<td><a onclick="examplePrompt()">Click to see an example prompt</a></td>
<td><p id="favorite-sport"></p></td>
</tr>
</table>
</body>
</html>
接着,看一下测试如上 HTML 页面三种弹窗的 Python 代码:
from unittest import TestCase
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class TestAlerts(TestCase):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.addCleanup(self.driver.quit)
def test_alert(self) -> None:
# 打开 Alerts 示例页面
self.driver.get('file:///Users/larry/Desktop/alerts-test.html')
# 点击超链接 "Click to see an example alert"
self.driver.find_element(By.LINK_TEXT, 'Click to see an example alert').click()
# 等待窗口弹出,获取 Alert 信息,点击 OK
alert = WebDriverWait(self.driver, 10).until(EC.alert_is_present())
alert_message = alert.text
alert.accept()
# 断言
self.assertEqual(alert_message, 'This is an example alert')
def test_confirm(self) -> None:
# 打开 Alerts 示例页面
self.driver.get('file:///Users/larry/Desktop/alerts-test.html')
# 点击超链接 "Click to see an example confirm"
self.driver.find_element(By.LINK_TEXT, 'Click to see an example confirm').click()
# 等待窗口弹出,点击 OK
alert = WebDriverWait(self.driver, 10).until(EC.alert_is_present())
alert.accept()
# 获取 `#confirmed` 文本
confirmed = self.driver.find_element(By.ID, 'confirmed').text
# 断言
self.assertEqual(confirmed, 'true')
def test_prompt(self) -> None:
# 打开 Alerts 示例页面
self.driver.get('file:///Users/larry/Desktop/alerts-test.html')
# 点击超链接 "Click to see an example prompt"
self.driver.find_element(By.LINK_TEXT, 'Click to see an example prompt').click()
# 等待窗口弹出,输入信息,点击 OK
alert = WebDriverWait(self.driver, 10).until(EC.alert_is_present())
alert.send_keys('Football')
alert.accept()
# 获取 `#favorite-sport` 文本
favorite_sport = self.driver.find_element(By.ID, 'favorite-sport').text
# 断言
self.assertEqual(favorite_sport, 'Football')
窗口与选项卡操作
可使用 Selenium WebDriver 来打开、关闭和切换窗口或选项卡。
操作窗口或选项卡的示例 Python 代码如下:
# 获取所有的窗口或选项卡句柄
driver.window_handles
# 获取当前窗口或选项卡的句柄
driver.current_window_handle
# 切换窗口或选项卡
driver.switch_to.window(handle)
# 新建窗口
driver.switch_to.new_window('window')
# 新建选项卡
driver.switch_to.new_window('tab')
# 关闭当前窗口或选项卡
driver.close()
Cookie 操作
有时候我们需要验证浏览器中 cookie 是否正确,因为基于真实 cookie 的测试是无法通过白盒和集成测试进行的。WebDriver 提供了操作 Cookie 的相关方法,可以读取、添加和删除 cookie 信息。
查询、添加和删除 Cookie 的示例 Python 代码如下:
from selenium import webdriver
driver = webdriver.Chrome()
# 打开URL
driver.get('https://www.baidu.com')
# 将Cookie添加到当前浏览器
driver.add_cookie({'name': 'foo', 'value': 'bar'})
# 获取所有的Cookie
print(driver.get_cookies())
# 获取名为foo的Cookie信息
print(driver.get_cookie('foo'))
# 删除名为foo的Cookie信息
driver.delete_cookie('foo')
# 删除所有的Cookie
driver.delete_all_cookies()
driver.quit()
复用Cookie
如果我们使用Selenium模拟登录操作,当然是可行的,但是有些登录操作比较复杂,并且现在网站有相当多的登录验证都得人工进行操作才可以(比如图片识别…),用Selenium模拟登录通常来说是一个费力不讨好的事情,因为无论多复杂的登录操作,目的就是为了获取得到相应的Cookie,而Selenium是有提供Cookie操作的API哦,那其实我们完全可以手动进行登录,然后直接从浏览器开发者工具抓取到需要的Cookie字符串,设置到Selenium中即可。具体代码如下所示:
# 切割字符串,获取每条Cookie键值
def str2Cookie(cookieStr):
def getCookieInfo(cookie):
return cookie.split('=', maxsplit=1)
for cookie in cookieStr.split(';'):
name, value = getCookieInfo(cookie.strip())
yield {'name': name, 'value': value}
def imitateLogin(driver):
# 手动抓取的Cookie字符串
cookieStr = r''
# 必须先访问页面,然后才能操作Cookie
driver.get('https://www.jianshu.com/')
# 清空Cookie
driver.delete_all_cookies()
# 解析cookieStr,并添加到selenium当前会话的的Cookie中
for cookie in str2Cookie(cookieStr):
driver.add_cookie(cookie)
# 刷新当前页面,使Cookie生效
driver.refresh()
if __name__ == '__main__':
driver = webdriver.Chrome()
imitateLogin(driver)
巧用Cookie
持久化Cookie:上面内容我们是直接手动获取Cookie,这种做法可能存在Cookie抓取不完全,导致某些页面无法访问。其实更好地做法是对Cookie进行持久化,我们只需使用Selenium模拟一个登录,然后持久化此时的Cookie,下次再次登录时,直接加载这些Cookie,无需进行真实登录操作。具体持久化方法如下所示:
# 持久化Cookie
def saveCookies(cookies, filename='cookies.json'):
with open(filename, mode='w', encoding='utf-8') as file:
import json
file.write(json.dumps(cookies))
# 加载Cookie
def loadCookies(filename='cookies.json'):
cookies = None
try:
with open(filename, mode='r', encoding='utf-8') as file:
import json
cookies = json.loads(file.read())
except FileNotFoundError:
cookies = None
except PermissionError:
cookies = None
return cookies
if __name__ == '__main__':
driver = webdriver.Chrome()
# 需要先访问下网址
driver.get('https://www.jianshu.com/')
# 先获取持久化的Cookie
cookies = loadCookies()
# Cookie存在
if cookies is not None:
# 清空重置Cookie
driver.delete_all_cookies()
# 添加Cookie
for cookie in cookies:
driver.add_cookie(cookie)
# 刷新一下
driver.refresh()
# Cookie不存在,则进行真实登录
else:
# 此处进行真正的登录操作
# 登录成功后,持久化此时的Cookie
saveCookies(driver.get_cookies())
# 现在就是已登录状态
鼠标操作
ActionChains类常用于模拟鼠标的行为,比如单击,双击,拖拽等行为:
from selenium.webdriver.common.action_chains import ActionChains
常用方法:
- click() 鼠标单击
- click_and_hold() 鼠标单击长按
- context_click() 右击
- double_click() 双击
- drag_and_drop_by_offset(source, xoffset, yoffset)
- source: The element to mouse down.
- xoffset: X offset to move to.
- yoffset: Y offset to move to.
- key_down() 按下某个键
- key_up() 放开某键
键盘操作
from selenium.webdriver.common.keys import Keys
常用按键(其他可以查看keys.py文件)
组合
- send_keys(Keys.CONTROL, ‘a’) # 全选(Ctrl+A)
- send_keys(Keys.CONTROL, ‘c’) # 复制(Ctrl+C)
- send_keys(Keys.CONTROL, ‘x’) # 剪切(Ctrl+X)
- send_keys(Keys.CONTROL, ‘v’) # 粘贴(Ctrl+V)
非组合
- 回车键: Keys.ENTER
- 删除键: Keys.BACK_SPACE
- 空格键: Keys.SPACE
- 制表键: Keys.TAB
- 回退键: Keys.ESCAPE
- 刷新键: Keys.F5
执行JavaScript代码
Selenium虽然提供了很多API供我们操作浏览器,但是还是无法覆盖所有内容。因此,Selenium提供了一项本人认为是杀手级功能的特性:执行JavaScript脚本
这项功能其实赋予了我们几乎可以完全操控浏览器的功能,Selenium WebDriver提供的接口为:WebDriver.execute_script(script, *args)
示例:加载网页后,让其垂直滚动到最底部。
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://baidu.com')
# window.scrollTo(x,y)
driver.execute_script(f'window.scrollTo(0, {driver.get_window_size()["height"]});')
Chrome options参数
Chrome options是配置chrome启动时属性的类。设置 chrome 二进制文件位置(binary_location)
from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.binary_location = "C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe" path = "C:\\Program Files(x86)\\chromedriver_win32\\chromedriver.exe" driver = webdriver.Chrome(options=options, executable_path=path)
添加启动参数(add_argument)
# 设置 ua
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument('user-agent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"')
driver = webdriver.Chrome(chrome_options=options)
# 设置 ip 代理
from selenium import webdriver
options = webdriver.ChromeOptions()
chromeOptions = webdriver.ChromeOptions()
chromeOptions.add_argument('--proxy-server=http://ip:port') # 设置 ip 还有端口
driver = webdriver.Chrome(chrome_options=chromeOptions)
# 其他常用
chrome_options.add_argument('--user-agent=""') # 设置请求头的 User-Agent
chrome_options.add_argument('--window-size=1280x1024') # 设置浏览器分辨率(窗口大小)
chrome_options.add_argument('--start-maximized') # 最大化运行(全屏窗口),不设置,取元素会报错
chrome_options.add_argument('--disable-infobars') # 禁用浏览器正在被自动化程序控制的提示
chrome_options.add_argument('--incognito') # 隐身模式(无痕模式)
chrome_options.add_argument('--hide-scrollbars') # 隐藏滚动条,应对一些特殊页面
chrome_options.add_argument('--disable-javascript') # 禁用 javascript
chrome_options.add_argument('--blink-settings=imagesEnabled=false') # 不加载图片,提升速度
chrome_options.add_argument('--headless') # 浏览器不提供可视化页面
chrome_options.add_argument('--ignore-certificate-errors') # 禁用扩展插件并实现窗口最大化
chrome_options.add_argument('--disable-gpu') # 禁用 GPU 加速
chrome_options.add_argument('–disable-software-rasterizer')
chrome_options.add_argument('--disable-extensions') # 禁用扩展
chrome_options.add_argument('--start-maximized') # 最大化
添加扩展应用(add_extension, add_encoded_extension)
# 添加插件 extension_path = '插件路径' chrome_options.add_extension(extension_path)
添加实验性质的设置参数(add_experimental_option)
# 禁止图片加载
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
prefs = {"profile.managed_default_content_settings.images": 2}
chrome_options.add_experimental_option("prefs", prefs)
# 禁用保存密码
prefs = {"": ""}
prefs["credentials_enable_service"] = False
prefs["profile.password_manager_enabled"] = False
chrome_options.add_experimental_option("prefs", prefs)
# 手机模式
option = webdriver.ChromeOptions()
option.add_argument('disable-infobars')
mobile_emulation = {"deviceName": "iPhone 6"}
option.add_experimental_option('mobileEmulation', mobile_emulation)
driver = webdriver.Chrome(chrome_options=option)
禁用弹窗
# 禁用浏览器弹窗
prefs = {
'profile.default_content_setting_values': {
'notifications': 2
}
}
chrome_options.add_experimental_option('prefs', prefs)
截屏
通过搜索文档,可以发现,Selenium 提供了以下两种类型的截屏功能:
[WebElement.screenshot(filename)][WebElement.screenshot]:该方法可以对元素进行截屏,如下代码所示:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver import ChromeOptions
options = ChromeOptions()
options.add_argument('headless')
with webdriver.Chrome(options=options) as driver:
driver.get('https://www.jianshu.com')
wait = WebDriverWait(driver, 10)
# 文章区域
el = wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '#list-container')
))
# 浏览器窗口设置为元素大小,以保证能完全截取元素区域
driver.set_window_size(el.size['width'], el.size['height'])
el.screenshot('D:\\jianshu.png')
WebDriver.save_screenshot(filename):截取浏览器当前页面。具体代码如下所示:
options = ChromeOptions()
options.add_argument('headless')
with webdriver.Chrome(options=options) as driver:
driver.get('https://www.jianshu.com')
wait = WebDriverWait(driver, 10)
#文章区域
wait.until(EC.presence_of_element_located(
(By.CSS_SELECTOR, '#list-container')
))
width = driver.execute_script("return document.documentElement.scrollWidth")
height = driver.execute_script("return document.documentElement.scrollHeight")
print(f'page scroll size: {width}x{height}')
#将窗口设置为页面滚动宽高
driver.set_window_size(width, height)
print('screenshot done') if driver.save_screenshot('D:\\jianshu.png') else print('screenshot failed!!')
注:截屏时我们需要将窗口的宽高设置为元素/页面滚动宽高,这样就可以完整截取整个元素/页面内容,但一个前提是必须使用 Headless模式,否则窃取的只是当前视口高度内容。
Selenium反爬措施
由于使用Selenium可以很方便对网页进行自动化操作,这同时也表示说Selenium是一个非常好用的爬虫处理器。
也因此,有一些网站就增加了对Selenium的检测,以禁止Selenium进行爬虫操作。
目前使用最多的检测Selenium爬取的方式为:通过检测浏览器当前页面的window.navigator,如果其包含有webdriver这个属性,那就表示使用了Selenium进行爬取,反之,如果检测到webdriver为undefined,则表示正常操作。
如果我们直接使用Selenium进行爬取,如下所示:
driver = webdriver.Chrome()
driver.get('https://antispider1.scrape.cuiqingcai.com/')
print(driver.page_source)
运行上述代码后,可以看到:WebddriverForbidden。
而如果想解决这个问题,依据先前我们介绍的原理可知,只要我们能将window.navigator.webdriver设置为undefined即可,但是我们不能简单地调用如下代码进行设置:
driver.execute_script('Object.defineProperty(navigator, "webdriver", {get: () => undefined})')
因为WebDriver.execute_script(..)是在页面加载完成后才执行,在时序上慢于网页检测。
因此,我们的变量修改必须尽早地在页面加载完成时进行设置。
而Selenium中提供的相应机制为:CDP(即Chrome Devtools-Protocol,Chrome开发工具协议)
对应的接口为:WebDriver.execute_cdp_cmd(cmd, cmd_args)
对应于上述示例,如果我们想要尽早在页面加载完成时执行我们的JavaScript脚本,需要使用的CDP命令为:Page.addScriptToEvaluateOnNewDocument,具体的代码如下所示:
options = ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-automation'])
options.add_experimental_option('useAutomationExtension', False)
browser = webdriver.Chrome(options=options)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
browser.get('https://antispider1.scrape.cuiqingcai.com/')
参考链接:


