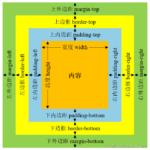
CSS简介 CSS,全称为 Cascading Style Sheets(层叠样式表),是一种用于控制网页外观和布局的语言。它与 HTML 分离,可以更高效地管理和维护网页的视觉设计。 CSS的作用: 样式定义:CSS可以定义各种样式如颜色…
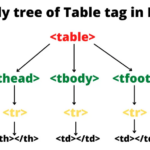
HTML表格在展示结构化数据时非常有用。HTML表格是用于在网页中展示结构化数据的一种标记语言元素。表格由<table>元素定义,表格的行由<tr>元素定义,而单元格则由<td>元素(用于数据单元格)和&l…
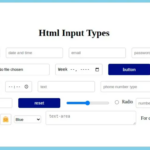
HTML表单是Web开发中非常重要的一部分,用于收集用户输入的数据。表单的相关内容可以分为几个主要部分: 表单的基本结构 常用表单控件 表单属性 表单验证 表单提交 表单的基本结构 HTML表单的基本结构由<…
旅行商问题简介 旅行商问题(Traveling Salesman Problem,简称TSP)是路径规划中的一个经典问题。旅行商问题是指一个旅行商人需要拜访N个城市,他必须选择一条路径,使得每个城市只被拜访一次,并最终返回出发城…
在日常的工作中,使用较多的是 Presto,原因是它比 Spark 快非常多。当然,使用过程中也会遇到一些问题,其中主要的是一些内置函数与SparkSQL 存在较大的差异。这里对 Presto SQL 一个简单的整理。关于 Presto 的相…
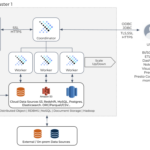
Apache Hive 是一个开源的数据仓库框架,用于查询和分析大数据集存储在 Hadoop 文件系统中。 Hive 提供了一种类 SQL 的查询语言,叫做 HiveQL,它使得熟悉 SQL 的用户可以在 Hive 上查询、汇总和分析数据。同时,…
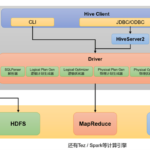
日常工作很多自动化的任务使用的是 Spark 运行,这里抽时间地 SparkSQL 进行系统的学习。 SparkSQL 与 HiveSQL 的区别 Hive 和 Spark 都是 Apache 的开源框架,而HiveSQL 和 SparkSQL 是这两种框架上运行的 SQL …

在机票搜索中,最关键的三要素通常包括: 出发地和目的地:这是任何机票搜索的基本核心。你需要知道从哪里出发,以及你想要去哪里。 日期:你需要知道出发和返回的日期。这一信息将直接影响航班的可用性和价…

公司记录日志的时候,将请求数据和返回数据以JSON格式存储到了数据库中,为了更高的处理这部分JSON数据,就用到了SparkSQL自带的一些JSON函数。这里做这些函数的方法做了一些整理。 get_json_object(json_txt, pa…

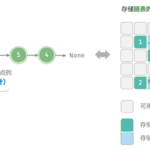
链表简介 链表(LinkedList)是一种基础的数据结构,是由一系列节点(Node)组成的集合。每个节点包括两部分:一部分是数据,另一部分是指向下一个节点的引用(在双向链表中,还有指向前一个节点的引用)。 这是链…