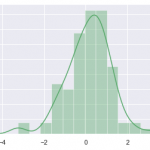
在观察数据的时候离散度是一个重要的指标。通常认为离散度越低数据会越好,但是现实场景并不如此。举个例子,比如某个电商网站有上万的商品,但是其每个商品的点评分离散度较低,那么将用户点评呈现给用户的价值就…
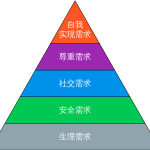
马斯洛需求层次理论的内容 马斯洛的需求层次理论是马斯洛于1943年《心理学评论》的论文〈人类动机的理论〉中所提出的理论。马斯洛理论把需求分成生理需求(Physiological needs)、安全需求(Safety needs)、爱和…
什么是PageRank PageRank,简称PR,是Google排名运算法则(排名公式)的一部分,是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的重要标准之一。PageRank计算页面的重要性,对…

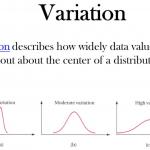
所谓核密度估计,就是采用平滑的峰值函数(“核”)来拟合观察到的数据点,从而对真实的概率分布曲线进行模拟。核密度估计更多详细内容,可以参考先前的Mean Shift聚类中的相关说明。一维数据的聚类这边文章中,讲到了…
LibShortText LibShortText是一个开源的Python短文本(包括标题、短信、问题、句子等)分类工具包。它在LibLinear的基础上针对短文本进一步优化,主要特性有: 支持多分类 直接输入文本,无需做特征向量化…
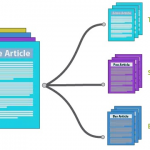
在数据挖掘中,一个最基本的问题就是比较两个集合的相似度。通常通过遍历这两个集合中的所有元素,统计这两个集合中相同元素的个数,来表示集合的相似度;这一步也可以看成特征向量间相似度的计算(欧氏距离,余弦…
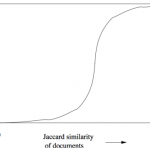
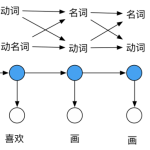
词性标注(Part-of-Speech tagging 或POS tagging),又称词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性的程序,也即确定每个词是名词、动词、形容词或其他词性的过程。词主要可以分为以下2…
结巴分词 就是前面说的中文分词,这里需要介绍的是一个分词效果较好,使用起来像但方便的Python模块:结巴。 结巴中文分词采用的算法 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况…

NLTK简介 NLTK(Natural Language Toolkit)是由宾夕法尼亚大学计算机和信息科学使用python语言实现的一种自然语言工具包,其收集的大量公开数据集、模型上提供了全面、易用的接口,涵盖了分词、词性标注(Part-Of-Sp…
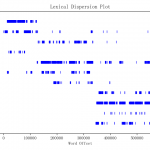
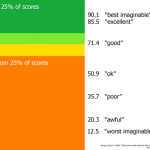
最近收到了对两个平台进行对比调研的需求,原以为做下简单的问卷设计就可以了,找了一些资料发现中间的门道还是非常的深,想要很好的掌握实属不易。可用性测试的问卷有很多中,如下图: 什么是标准化的问卷 …