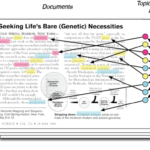
先前对于生存分析的理解比较片面,虽然知道生存分析不仅仅适用于预料行业,对于用户留存的也有一定的范围,当时的理解是只适合订阅制的网站用来分析用户留存,但是仔细分析后发现适用场景还是蛮多的。其中个人觉得…

Fuzzy C-Means简介 模糊理论 模糊控制是自动化控制领域的一项经典方法。其原理则是模糊数学、模糊逻辑。1965,L.A. Zadeh发表模糊集合“Fuzzy Sets”的论文,首次引入隶属度函数的概念,打破了经典数学“非0即1”的局限…
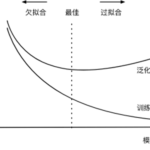
对于深度学习或机器学习模型而言,我们不仅要求它对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的…
Hive简介 Hive由Facebook实现并开源,是基于Hadoop的一个数据仓库工具。可以将结构化的数据映射为一张数据库表并提供HQL(Hive SQL)查询功能。底层数据是存储在HDFS上,Hive的本质是将SQL语句转换为MapReduce任务运…

Google,作为全球最大的搜索引擎公司,其伟大之处不仅在于建立了一个强大的搜索引擎,还在于它创造了3项革命性的技术,即:GFS、MapReduce和BigTable。作为Google早期三驾马车,这三项革命性的技术不仅在大数据领域…

Bigtable是2005年谷歌的论文:《Bigtable: A Distributed Storage System for Structured Data》中介绍的一种分布式存储系统,后来被Hadoop社区实现为HBase。读懂这篇论文,那么理解HBase也就非常容易了。 摘要(…
GFS系统简介 Google文件系统(Google File System,缩写为GFS或Google FS),一种由Google公司开发专有分布式文件系统。 它与传统文件系统的的区别在于: 分布式 - 提供很高的横向扩展性 使用大量廉价的普通…
GBRank是一种pair-wise的学习排序算法,他是基于回归来解决pair对的先后排序问题。在GBRank中,使用的回归算法是梯度提升数GBT (Gradient Boosting Tree) 算法原理 Learning To Rank需要解决的问题是给定一个Query…
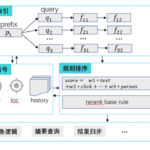
谈到推荐系统,很多人的印象中是“个人性推荐”和“千人千面”。关于“千域千面”应该很少人提及,主要能用到的场景不多,先前有想过在酒店场景上应用,但是由于各种原因最终没有尝试。以下是高德地图在“千域千面”的一些…
在潜在语义分析LSA的文章中对LDA有一些简单的介绍,今天的目标是对LDA进行相对深入的了解,大致搞明白其原理。 LDA简介 在机器学习领域中有2个LDA: 线性判别分析(Linear Discriminant Analysis),主要用于降维和…