背景与基础 目前的机器学习模型都是数学模型,其对应的输入要求必须是数字形式(number)的,而我们处理的真实场景往往会包含许多非数字形式的输入(有时候即使原始输入是数字形式,我们也需要转换),最典型的就是…
ChatGPT与GPT ChatGPT,全称聊天生成预训练转换器(英语:Chat Generative Pre-trainedTransformer),是OpenAI开发的人工智能聊天机器人程序,于2022年11月推出。该程序使用基于GPT-3.5、GPT-4架构的大型语言模型…
BERT简介 BERT(Bidirectional Encoder Representations from Transformers)是一种预训练语言表示的方法,由Google的研究者在2018年提出。它在自然语言处理(NLP)领域取得了革命性的进展,尤其是在理解上下文含义…

Transformer简介 Transformer是一种深度学习架构,由Google的研究者在2017年的论文《Attention Is All You Need》中首次提出。它在自然语言处理(NLP)和其他领域取得了巨大的成功,特别是在处理长序列数据方面。Tr…
线性回归是机器学习中最为简单的模型,但在实际使用过程中可能不太适用。比如以下场景: 分段线性拟合是一种用于对数据进行建模的回归方法,其中数据在不同的区间内使用不同的线性函数进行建模。与简单线性回归…
NeuralProphet 产生背景 大多数时间序列问题需要易于理解的预测。同时,需要有效的预测。这两个愿望导致了一种权衡:可解释性与准确率。准确率的显著提高通常归因于更复杂的模型。然而,复杂性与可解释性存在天然的…
超参数优化简介 目前人工智能和深度学习越趋普及,大家可以使用开源的 Scikit-Learn、TensorFlow 来实现机器学习模型。对于各种模型而言,或多或少都具有要调节的超参数。相同的模型应用在不同的数据集上,如何选择…

DTW简介 DTW(Dynamic Time Warping)是一种用于比较时间序列之间相似性的算法。它可以有效地处理在时间轴上存在偏移、缩放和扭曲等变形的时间序列数据。DTW算法通过对两个时间序列进行动态规整,将它们按最优路径…
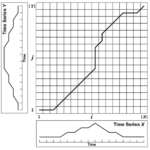
针对 Facebook Prophet 的使用,很多年以前就整理过一篇文章《Facebook 时间序列预测工具 fbprophet》,过了 N 年以后当重新需要使用这个工具的时候,发现部分内容已经更新,中间的很多细节内容都没有表述清楚。实…
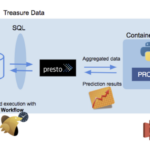
在上一篇重新认识Excel 的文章中,提到了Excel无所不能,然后就想到了曾经看到的这篇关于如何使用Excel搭建推荐引擎的文章。于是找了出来做了下简单的翻译(只翻译了重点部分)。 在互联网上有无限的货架空间,找…






