Bigtable是2005年谷歌的论文:《Bigtable: A Distributed Storage System for Structured Data》中介绍的一种分布式存储系统,后来被Hadoop社区实现为HBase。读懂这篇论文,那么理解HBase也就非常容易了。
摘要(Abstract)
Bigtable是一个分布式存储系统,它被设计来为近万台商用服务器规模的、PB级别的数据提供服务。包括网页索引、Google Earth、Google Finance(注:这些应用都是2005年论文发表的时候列举的,现在Google貌似已经抛弃Bigtable使用下一代产品了)在内的许多Google项目都使用Bigtable来存储数据。这些应用在数据粒度和实时性方面的要求都大相径庭,但Bigtable却能很好地为这些应用提供灵活、高性能的解决方案。在这篇论文中我们讨论Bigtable提供的简单数据模型,这个模型让用户能够动态地控制数据布局和格式。接着我们介绍Bigtable的设计和实现。
1 简介(1 Introduction)
在过去的两年半我们已经设计实现并发布了一个分布式存储系统,用来管理Google的结构化数据,叫做Bigtable。Bigtable是一个被设计可以可靠的应付PB级数据规模和上千台机器的系统。Bigtable已经完成了几个目标:广泛的适用性,可扩展性,高性能,以及高可用。Bigtable已经被超过60个谷歌产品和项目所使用,包括Google Analytics, Google Finance, Orkut, Personalized Search, Writely, and Google Earth。这些产品使用Bigtable来应对各种各样的工作量需求,从面向吞吐量的批处理任务到对时间延迟敏感的终端用户服务。这些产品使用的Bigtable集群跨越了各种配置,从少量的服务器到数千台服务器,并存储了高达几百tb的数据。
在许多方面,Bigtable依然和一个数据库相似:它和很多数据库有着相同的实现策略。平行数据库(Parallel databases)和内存为主的数据库已经获得了可扩展性和高性能这些特性了,但是Bigtable提供了不同于这些系统的接口。Bigtable并不支持一个完整的关系数据模型;替代的,他提供给客户端一个简单的数据模型,该模型支持对数据布局和格式的动态控制,并允许客户端可以从底层存储的表示推理出其局部属性。我们使用行和列的名字来索引数据,这些名字可以是任意的字符串。Bigtable可以吧数据当做未处理的字符串进行处理,尽管客户端通常已经将各种形式的结构化和半结构化数据序列化为这些字符串了。客户端可以通过仔细地选择模式来控制其数据的位置。最后,Bigtable模式参数允许客户端动态控制是在内存中还是在磁盘中提供数据。
第2节将描述数据模型的更多细节,第2节会提供一个客户端API的概述。第4节会简要介绍Bigtables所依赖的Google基础架构的底层结构。第5节将描述Bigtable实现的基本原理。第6节描述了我们为了提高Bigtable的性能做的一些改进。第8节中我们会讲述在Google中如何使用Bigtable的几个例子。第9节中讨论一下我们在设计和支持Bigtable中吸取的一些教训。最后,第10节会介绍相关工作,11节会给出我们的结论。
2 数据模型(Data Model)
Bigtable是一个稀疏的,分布式的,持久化,拥有多和维度的有序map。这个map通过一个行key和列key以及一个时间戳来定位一个元素。map中的每个值都是一个未被解析的字节数组。
(row:string, column:string, time:int64)→string
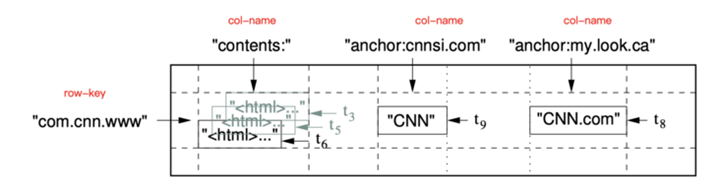
图1:存储web网页例子的一个切片,行的名字是的转置后的URL。contents列族存放的是网页的内容,anchor列族存放的是引用了该网页连接的anchors文本信息。CNN的主页被Sports Illustrated和MY-look主页同时引用,所以这行数据包含了anchor:cnnsi.com和anchor:my.look.ca。每个anchor单元格都有一个版本,contents列有三个版本,对应的时间戳t3,t5和t6。
我们在仔细检查大量的类似Bigtable的系统的潜在使用场景。一个明确驱使我们做出的几个设计决定的例子是:假设我们想要保持备份一个很大的数据集,这个数据集是可能被很多项目使用的网页和相关信息;我们先临时称这个表为Webtable,在Webtable中,我们可以使用URL作为行key,web网页个各种相关信息作为列名,我们将网页的内容存放在contents字段中:每一列都在他们数据被抓取的时候用标记上时间戳,如图1说明的那样。
行(Rows)
在table中row key可以是任意字符串(目前最大支持64kb的字符串,但是对我大部分用户通常都在10-100kb大小)。每一次对一个row key下的数据进行读写的操作都是原子性的(不管这行里面有多少不同的列)。这么设计的原因是我们对一个行并发更新场景下可以让客户端更加容易的理解系统表现行为。
Bigtable通过row key的字典序来组织数据。table会被动态的分片为多个一连串的行。每个这些一连串的行叫做tablet,这是数据分布和负载平衡的最小单位。结果,对于那些比较小的tablet的读操作是高效的并且一般只需要少部分的机器来进行通信。客户端可以利用这个属性来选择他们的row key,这样可以更好的定位他们需要访问的数据。比如,在Webtable中,通过反转URL可以将相同域名的网页分到一个组里面去。举个例子:我们存储maps.google.com/index.html的数据就使用key为com.google.maps/index.html。通过域名让这些需要存储的相临近网页可以让一些对主机和和域名的分析更加高效。
列族(Column Families)
列的key会被分组为一系列集合叫做列族,这将构成基本的访问控制单元。存储在一个列族的中所有数据同上都是一个类型的(我们压缩同时会压缩同一个列族中的数据)。一个列族必须在数据存储到该列族下的列之前被创建;在列族创建完成后,任意该列族下的列key都可以被使用。我们这么设计的意图主要是因为考虑到在一个table中不同的列族的数量会很小(最多数百个),并且列族在操作的时候很少被修改。相对的,一个表的列可能是没有一个具体数量边界的。
一个列key的命名方式需要遵循下面的语法:列族名:修饰符。列族的名字必须是可打印的,而修饰符的名字可以是任意字符串。Webtable一个列族的例子就是language,该列族用来存放编写该网页所用到的语言。我们在该列族里面只有一个列,该列用于存储每个网页的语言ID。另一个有用的列族是anchor;如图1所示,该族里面每一个列key都代表一个单独的anchor。使用的修饰符就是引用网站的名字,而里面存放的内容就是该引用的连接。
访问控制以及磁盘和内存记录均在列族级别来执行。在我们的Webtable示例中,这些控制使我们能够管理不同类型的应用程序:一些如添加新的基本数据,一些如只允许读取基本数据以及创建衍生的列族,某些仅允许查看现有数据(出于隐私原因可能都不能访问所有现有列族)。
时间戳(Timestamps)
table中每个cell可以包含同一个数据的多个版本,这些版本通过timestamps时间戳来索引。Bigtable的时间戳是64位的整型。他们可以由Bigtable来分配,代表着微秒级别的“真实时间”,也可以被客户端程序明确指定。为了避免数据的碰撞,客户端必须自己能生成唯一的时间戳。一个cell中不同版本的数据是按照时间戳降序顺序,所以最新的版本可以被最先读取。
为了减轻数据版本的管理工作,我们支持两种针对列族的专门设置,该设置会让Bigtable自动垃圾回收这些cell。客户端可以指定仅保留单元格的最后n个版本,或者仅保留新的足够的版本(例如,仅保留最近7天写入的值)。
在我们的Webtable例子中,我们设置content:列中存储的爬取来的网页的时间戳为实际的抓取时间。上述的垃圾收集机制会让我们仅保留每个页面的最新三个版本。
3 API
Bigtable API提供了创建和删除表和列族的功能。它还提供用于修改群集,表和列族元数据的功能,比如如访问控制权限。

客户的应用程序可以写入或删除BigTable中的值,从单个行中查找某个值,或者对表中某个数据子集进行遍历。图2显示了一段C++代码,它使用了RowMutation抽象来执行一系列的更新(为了使示例简短,省略了无关的细节。)。对Apply的调用,会对Webtable的执行一个原子变更操作:它向www.cnn.com添加一个锚点(原文叫anchor跟容易理解)并删除另一个不同的锚点。

图3显示了一段C++代码,它使用了一个Scanner这样的抽象来遍历一个行中的所有anchor。客户端可以遍历多个列族,并且提供了几种机制可以限制一次扫描中产生的行、列和时间戳。例如,我们可以限制上面的扫描让其只产生的anchor所在的列与正则表达式anchor:*.cnn.com匹配的,或者只产生那些时间戳距离当前时间10天以内的anchor。
BigTable支持几种其他的功能允许用户以更加复杂的方式来操作数据。首先,BigTable支持单行事务,可以允许对某个rowKey下面的数据执行原子的“读-改-写”操作。BigTable目前还不支持通用的跨行rowKey的事务,虽然它在客户端提供了跨rowKey的批量写入数据的接口。其次,BigTable允许单元格被用来作为整数计数器。最后,BigTable支持在服务器的地址空间内执行客户端提供的脚本。这种脚本语言是Google开发出来进行数据处理的叫做Sawzall。目前,我们基于Sawzall的API不允许客户端脚本对BigTable执行回写操作,但是,它确实允许各种形式的数据转换、基于任意表达式的过滤以及通过各种各样的算子得出的总结。
BigTable可以和MapReduce一起使用,MapReduce是Google开发的、用来运行大规模并行计算的框架。我们已经写了一套Wrapper的集合,可以让BigTable被用来作为一个MapReduce作业的输入源或者输出目标。
4构建块(Building Blocks)
BigTable是在其他几个Google基础设施之上构建的。BigTable使用了分布式Google文件系统(GFS)来存储日志和数据文件。一个BigTable集群通常是在一个共享机器池中操作,这个共享机器池也运行着其他一些分布式应用程序。BigTable的进程通常和其他应用的进程共享同样的机器。BigTable依赖一个集群管理系统来进行调度作业、在共享机群上管理资源、处理机器失败和监控机器状态。
Google的SSTable的文件格式被用来作为存储BigTable数据的内部格式。一个SSTable提供一个持久化的、排序的、不可变的、从键到值的映射(map),其中,键和值都是任意的字节字符串。BigTable提供了查询一个指定key的值以及遍历一个指定的key区间内所有的键值对的操作。在内部,每个SSTable都包含一个块序列(通常每个块是64KB,但可配置)。使用一个块索引(存储在SSTable结尾的那个块)来快速定位块的位置。当SSTable被打开时,块索引就会被加载进内存。一个查询操作只需要进行一次磁盘扫描,我们首先在内存中的块索引中使用二分查找方法找到合适的块,然后再去从磁盘中读取相应的块。同样可选的,一个SSTable可以被完全映射到内存中,这样我们在进行查找操作时就不需要读取磁盘。
BigTable依赖一个高可用的、持久性的分布式锁服务叫Chubby。一个Chubby服务包含5个活跃的副本,其中一个被选作主副本来对外提供服务。当大部分副本处于运行状态并且能够彼此通信时,就意味这个服务就是活着的。Chubby使用Paxos算法来使它的副本在失败时保持一致性。Chubby提供了一个名字空间,它包含了一些目录和小文件。每个目录活着的文件都可以被用作一个锁,针对文件的读和写操作都是原子的。Chubby客户端函数库提供了针对Chubby文件的持久性缓存。每个Chubby客户端维护一个和Chubby服务的session。如果租约过期以后不能及时更新session的租约,那么这个客户端的session就会过期。当一个客户端的session过期时,它将会丢失所有锁和开放的句柄。Chubby客户端也可以注册针对Chubby文件和目录的回调服务(callback),从而获取文件变化时候的通知或者session的过期。
BigTable使用Chubby来处理大量的任务:保证在每个时间点只有一个主副本是活跃的;来存储BigTable数据的bootstrap的位置(见5.1节);来发现tablet服务器以及宣告tablet服务器死亡;存储BigTable模式信息(即每个表的列族信息),以及存储访问控制列表。如果在一段时间以后,Chubby变得不可用,BigTable也会变的不可用了。我们最近对涵盖11个Chubby实例的14个BigTable集群进行了这方面的影响测试。由于Chubby的不可用(由于Chubby过时或者网络问题),而导致一些存储在BigTable中的数据变得不可用,这种情形占到BigTable服务小时的平均比例值是0.0047%。单个集群的百分比是0.0326%。
5实现(Implementation)
BigTable实现包括三个主要的功能组件:一个用来链接到每个客户端的库,一个master服务,许多Tablet服务。Tablet服务器可以根据工作负载的变化,从一个集群中动态地增加或删除。master服务负责把Tablet分配到Tablet服务,探测Tablet服务的增加和过期,进行Table服务的负载均衡,以及GFS文件系统中的垃圾回收。除此以外,它还处理模式(schema)变化,比如表和列族创建。
每个Tablet服务管理一个Tablet集合(通常在每个Tablet服务器上我们会放置10到1000个Tablet)。Tablet服务会处理那些对已经加载的Tablet而提出的读写请求,并且会对变得太大的Tablet进行切分。
和许多单master分布式存储系统一样,客户端并不是直接从主服务器读取数据,而是直接从Tablet服务器上读取数据。因为BigTable客户端并不依赖于master服务来获得Tablet的位置信息,大多数客户端从来不和,aster服务器通信。这样在实际应用中master的负载很小。
一个BigTable集群存储了许多表。每个表都是一个Tablet集合,每个Tablet包含了位于某个域区间内的所有数据。在最初阶段,每个表只包含一个Tablet。随着表的增长,它会被自动分解成许多Tablet,每个Tablet默认尺寸大约是100到200MB。
5.1Tablet位置(TabletLocation)
我们使用了一个类似于B+树的三层架构来存储Tablet位置信息(如图4所示)。
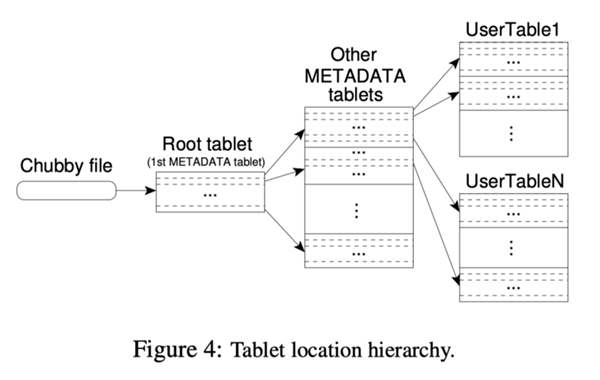 第一个层次是存储在 Chubby 中的一个文件,它包含了 root tablet 的位置信息。root tablet 把 Tablet 的所有位置信息都保存在一个特定的元数据(METADATA)表中。每个 METADATA 表都包含了一个 user tablet 集合的位置信息。root tablet 其实就是 METADATA 表当中的第一个 Tablet,但是对待的方式有区别,它永远不会被拆分,这样就确保 Tablet 位置层次结构不会超过三层。
第一个层次是存储在 Chubby 中的一个文件,它包含了 root tablet 的位置信息。root tablet 把 Tablet 的所有位置信息都保存在一个特定的元数据(METADATA)表中。每个 METADATA 表都包含了一个 user tablet 集合的位置信息。root tablet 其实就是 METADATA 表当中的第一个 Tablet,但是对待的方式有区别,它永远不会被拆分,这样就确保 Tablet 位置层次结构不会超过三层。
METADATA 表存储了属于某个 rowkey 的 Tablet 的位置信息,rowkey 是 Tablet 表标识符和它的最后一行这二者的一个编码。每个 METADATA 行,在内存中大约存储 1KB 的数据。由于 METADATA Tablet 128M 大小的限制,我们的三层位置模式足够用来存放 2^34 的 Tablet 的位置信息(或者 2^61 字节在 128M 的 tablets 中)。
客户端的函数库会缓存 Tablet 位置信息。如果客户端不知道一个 Tablet 的位置,或者它发现它缓存的 Tablet 位置信息不正确,它就会在 Tablet 位置层次结构中依次向上寻找。如果客户端缓存是空的,那么定位算法就需要进行三次网络轮询,其中就包括一次从 Chubby 中读取信息。如果客户端的缓存是过期的,定位算法就要进行六次轮询,因为,只有在访问不存在的时候才会发现缓存中某个 entry 是过期的(假设 METADATA Tablets 不会频繁移动)。虽然,Tablets 位置信息是保存在内存中,所以不需要访问 GFS,我们仍然通过让客户端库函数预抓取 tablet 位置信息来进一步减少代价,具体方法是:每次读取 METADATA 表时,都要读取至少两条以上的 Tablet 位置信息。
我们也在 METADATA 表中存储了二级信息,包括一个日志,它记载了和每个 tablet 有关的所有事件(比如一个服务器什么时候开始提供这个 tablet 服务)。这些信息对于调试和性能分析是非常有用的。
5.2 Tablet 分配(Tablet Assignment)
同一时间每个 Tablet 只可以被分配到一个 tablet 服务器。master 服务保持跟踪 tablet 服务器们的情况,以及 tablet 被分配到 tablet 服务器的情况,这包括哪个 tablet 还没有被分配。当一个 tablet 没有被分配,并且有一个 tablet 服务器有足够空间可以容纳该 tablet 时,master 服务器会向 tablet 服务器发送一个 tablet 加载请求来把当前这个 tablet 分配给这个 tablet 服务器。
BigTable 使用 Chubby 来跟踪 tablet 服务器。当一个 tablet 服务器启动的时候,Chubby 创建并且获得一个独占的排他锁,这个锁会锁住在指定的 Chubby 目录中的一个唯一命名的文件。master 会监视这个目录(服务器目录),来发现 tablet 服务器。如果一个 tablet 服务器停止服务,它就会丢失这个锁,比如,由于网络故障,导致这个 tablet 服务器丢失了它与 Chubby 的会话。(Chubby 提供了一个完善的机制,来允许一个 tablet 服务器检查自己是否已经丢失了这个独占排他锁)。如果丢失了锁,只要目录中的这个文件还存在,一个 tablet 服务器就会努力去获得这个锁。如果文件不再存在,那么这个 tablet 服务器就不能再够对外提供服务,因此它会自杀。每当 tablet 服务终止了(比如,集群管理系统把这个 tablet 服务器从集群中移除),它就会尝试释放锁,这样主服务器就可以更快地重新分配这个 tablet。
master 有责任去探测什么时候 tablet 服务器不再提供 tablet 服务,并且要尽快重新分配这些 tablet。为了探测什么时候 tablet 服务器不再提供 tablet 服务,主服务器会周期性地询问每个 tablet 服务器,了解他们的锁的状态。如果一个 tablet 服务器报告它已经丢失了锁,或者在最近的几次尝试 master 都无法与 tablet 服务器取得联系,master 就会努力获得一个针对这个服务器文件的独占排他锁。如果 master 可以获取这个锁,说明 Chubby 还活着只是 tablet 服务器已经死亡或者某些故障导致它无法连接到 Chubby。因此 master 就要从 Chubby 中删除这个 tablet 服务器的文件,从而确保这个 tablet 服务器不再能够提供服务。一旦一个服务器文件被删除,主服务器就可以把所有以前分配给该服务器的 tablet,都移动到待分配 tablet 的集合。为了保证一个 BigTabl 集群不会轻易受到主服务器和 Chubby 之间的网络故障的影响,如果一个主服务器的 Chubby 会话过期了,这个主服务器就会自杀。但是,正如上所述,主服务器失效并不会改变 tablet 到 table 的分配。
当一个 master 被集群管理系统启动时,它在能够改变 tablet 分配之前必须首先了解当前的 tablet 分配信息。因此在启动的时候,master 会执行以下步骤:(1)master 在 Chubby 中抓取一个独特的 master lock,这就防止了多个 master 并发启动的情形。(2)master 扫描 Chubby 中的服务器目录,从而发现当前可用的服务器。(3)master 和当前每个可用的 tablet 服务器通信,来发现哪些 tablets 已经被分配到哪个 tablet 服务器。(4)主服务器扫描 METADATA 表来学习 tablets 表集合。一旦在扫描过程中,主服务器发现某个 tablet 还没有被分配,主服务器就把这个 tablet 放置到待分配 tablet 集合,这就让这些 tablet 可以分配到合理的地方。
一个比较复杂地方是在 METADATA tablets 被分配之前,我们是不能扫描 METADATA 表的。因此,在开始扫描(上述步骤 4)之前,如果主服务器在步骤 3 的扫描中发现 root tablet 没有被发现,master 会把 root tablet 增加到待分配 tablet 集合。这个增加确保 root tablet 一定会被分配。因为 root tablet 包含了所有 METADATA tablets 的名字。主服务器只有在扫描了 root tablet 以后,才可能知道所有这些 METADATA tablets 的名字。
现有的 tablet 集合,只有在以下情形才会发生改变:当一个 tablet 被创建或删除;对两个现有的 tablet 进行合并得到一个更大的 tablet 一个现有的 tablet 被分割成两个较小的 tablet。master 可以跟踪这些变化。因为 Tablet 分割是由一个 tablet 服务器发起的所以会被特殊对待。Tablet 服务器通过把新的 tablet 信息记录在 METADATA 表中,来提交分割操作。当分割被提交以后,这个 tablet 服务器会通知 master。为了防止分割通知丢失(或者由于 master 死亡或者由于 tablet 服务器死亡),当主服务器要求一个 tablet 服务器加载已经被分割的 tablet 时,主服务器会对这个新的 tablet 进行探测。Tablet 服务器会把分割的情况通知给 master,因为它在 METADATA 表中能所找到的 tablet entry 只是 master 要求它加载的数据的一部分。
5.3 Tablet 服务(Tablet Serving)
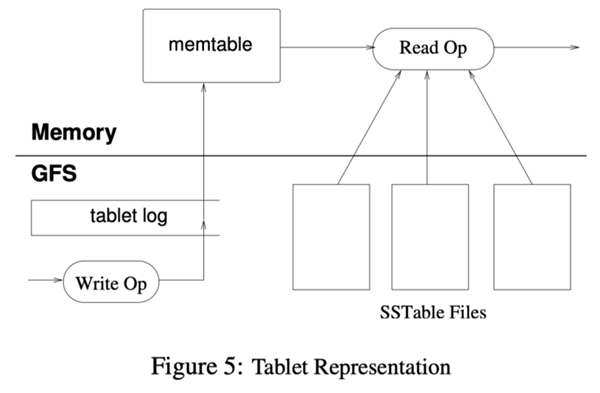
一个 tablet 的持久化状态是存储在 GFS 中的,如图 5 所示。更新被提交到一个提交日志,日志中记录了 redo 记录。在这些更新当中,最近提交的更新被存放到内存当中的一个被称为 memtable 的排序缓冲区,比较老的更新被存储在一系列 SSTable 中。为了恢复一个 tablet,tablet 服务器从 METADATA 表当中读取这个 tablet 的元数据。这个元数据包含了 SSTable 列表,其中每个 SSTable 都包括一个 tablet 和一个重做点(redo point)的集合,这些 redo point 是一些指针,它们指向那些可能包含 tablet 所需数据的重做日志。服务器把 SSTable 索引读入内存,执行 redo point 以后的所有已经提交的更新来重新构建 memtable。
当一个写操作到达 tablet 服务器时,服务器首先检查它定义是否良好,并且发送者是否被授权执行该变更。执行授权检查时,会从一个 Chubby 文件中读取具有访问权限的写入者的列表,这个 Chubby 文件通常总能够在 Chubby 客户端缓存中找到。一个有效的变更会被写入提交日志中。分组提交是为了优化许多小变更操作的吞吐量。在写操作已经被提交以后,它的内容就会被插入到 memtable。
当一个读操作到达 Tablet 服务器,与写操作类似,服务器也会首先检查它是否是良好定义和得到授权的。一个有效地读操作是在一系列 SSTable 和 memtable 的合并的视图上执行的。由于 SSTable 和 memtable 是字典排序的数据结构,视图合并的执行效率很高。
当 tablet 发生合并或分割操作时,正在到达的读写操作仍然可以继续进行。
5.4 压缩合并(Compactions)
随着写操作的执行,memtable 的大小逐渐增加。当 memtable 的大小到达一个阈值的时候,memtable 就会被冻结然后创建一个新的 memtable,被冻结的 memtable 就转化成一个 SSTable 并被写入到 GFS。这个小压缩(minor compaction)过程有两个目标:它缩小了 tablet 服务器的内存使用率;当发生服务器宕机需要恢复时可以减少了需要从重做日志中读取的数据量。当压缩过程正在进行时,正在到达的读写操作仍然可以继续进行。
每一次小压缩都会创建一个新的 SSTable,如果这种行为没有约束地持续进行,读操作可能需要从任意数量的 SSTable 中合并更新。相反,我们会对这种文件的数量进行限制,我们在后台周期性地运行一个合并压缩程序。一个合并压缩程序从一些 SSTable 和 memtable 中读取内容,并且写出一个新的 SSTable。一旦压缩过程完成,这个输入的 SSTable 和 memtable 就可以被删除。
一个合并压缩程序,把所有的 SSTable 的数据重写到一个 SSTable,这个合并压缩被称为“主压缩”(major compaction)。非主压缩所产生的 SSTable 可以包含特殊的删除入口(entry),它把被删除的数据压缩在仍然存活的比较老的 SSTable 当中。另一方面,一个主压缩过程,产生一个不包含删除信息或被删除的数据的 SSTable。BigTable 定期检查它的所有 tablet,并执行主压缩操作。这些主压缩过程可以允许 BigTable 收回被删除数据占用的资源,并且保证被删除数据在一定时间内就可以及时的从系统中消失,这对于一些存储敏感数据的服务来说是非常重要的。
6 完善(Refinements)
在前面章节描述的实现需要一系列完善措施来获取我们用户所需要的高的性能、可用性和可靠性。本节将更详细地描述实现的各个部分,以凸显这些完善。
位置分组(Locality groups)
客户端可以把多个列族一起分组到一个 locality group 中。我们会为每个 tablet 中的每个 locality group 都生成一个单独的 SSTable。把那些通常不会被一起访问的列族分割在不同的 locality group,可以实现更高效的读。例如,在 WebTable 当中网页的元数据(比如语言和校验码),可以被放置到同一个 locality group 当中,网页的内容可以被放置到另一个 locality group 当中。这样想要读取页面元数据的应用就不需要去访问所有的页面内容。
另外,可以针对每个 locality group 来指定一些有用的参数。例如,一个 locality group 可以设置成存放在内存中。常驻内存的 locality group 的 SSTable 采用懒加载的方式加载到 tablet 服务器的内存中。一旦加载,属于这些 locality group 的列族,就可以被应用直接访问,而不需要读取磁盘。这个特性对于那些被频繁访问的小量数据来说是非常有用的:我们在内部使用其获取 METADATA 表的列族位置。
压缩(Compression)
客户端可以控制是否对相应于某个 locality group 的 SSTable 进行压缩,如果压缩,应该采用什么格式。用户自定义的压缩格式可以被应用到每个 SSTable 块中(块的大小可以通过 locality group 指定的参数来进行控制)。虽然对每个块进行单独压缩会损失一些空间,但是我们可以从另一个方面受益,当解压缩时只需要对小部分数据进行解压而不需要解压全部数据。许多客户端都使用两段自定义压缩模式。第一遍使用 Bentley and McIlroy 模式,它对一个大窗口内的长的公共字符串进行压缩。第二遍使用一个快速的压缩算法,这个压缩算法在一个 16KB 数据量的窗口内寻找重复数据。两个压缩步骤都非常快,在现代计算机上运行,他们编码的速度是 100-200MB/S,解码的速度在 400-1000MB/S。
在选择我们的压缩算法时,即使我们强调速度而不是空间压缩率,这个两段压缩模式也表现出了惊人的性能。例如,在 WebTable 中,我们使用这种压缩模式来存储网页内容。在其中一个实验当中,我们在一个压缩后的 locality group 中存储了大量的文档。为了达到实验的目的,我们只为每个文档存储一个版本,而不是存储我们可以获得的所有版本。这个压缩模式获得了 10:1 的空间压缩率。这比传统的 GZip 方法的效果要好得多,GZip 针对 HTML 数据通常只能获得 3:1 到 4:1 的空间压缩率。这种性能上的改进是和 WebTable 中的行的存储方式紧密相关的,即所有来自同一个站点的网页都存储在相近的位置。这就使得 Bentley and McIlroy 算法可以从同一个站点的网页中确定大量相似的内容。许多应用,不只是 WebTable,都会很好地选择行名称,从而保证相似的数据可以被存放到同一个集群当中,这样就可以取得很好的压缩率。当我们在 BigTable 中存储同一个值的多个不同版本时,可以取得更好的压缩率。
为读性能做缓存(Caching for read performance)
为了改进读性能,tablet 服务使用了二级缓存。Scan 缓存是一个高层次的缓存,它缓存着键值对,这些键值对是由 tablet 服务器代码的 SSTable 接口返回的。Block 缓存是比较低层次的缓存,它缓存了从 GFS 当中读取的 SSTable 块。Scan 缓存对于那些频繁读取相同数据的应用来说是非常有用的。Block 缓存对于那些倾向于读取与自己最近读取数据位置临近的数据的应用来说,是比较有用的(比如顺序读取,或者随机读取属于同一个 locality group 中的不同的列)。
布隆过滤器(Bloom filters)
正如 5.3 节描述的,一个读操作需要从构成一个 tablet 的当前状态的所有 SSTable 中读取数据。如果这些 SSTable 不在内存中,我们就不得不造成很多磁盘访问。我们通过下面的方式来减少磁盘访问,即允许客户端来确定,为某个特定 locality group 中的 SSTable 创建布隆过滤器(Bloom filter)。一个 Bloom filter 允许我们询问,一个 SSTabble 是否包含属于指定的行/列对的数据。对于某个特定的应用,一个 tablet 服务器只需要使用少量内存空间来存储 Bloom filter,都可以极大减少读操作的磁盘访问次数。我们使用 Bloom filter 也意味着,大多数对目前不存在的行或列的查询并不需要访问磁盘。
提交日志实现(Commit-log implementation)
如果我们为每个 tablet 都设置一个单独的文件来保存提交日志,那么就会在 GFS 中产生大量的文件并发写操作。这些写操作会引起大量的磁盘访问,这取决于每个 GFS 服务器底层文件系统的实现方式。除此以外,让每个 tablet 都有一个单独的日志文件,会降低分组提交优化的效率。为了解决这些问题,我们对每个 tablet 服务器具备一个独立日志文件这种方式进行了修改,不是把更新都写入相应 tablet 的独立文件中,而是把几个不同 tablet 的更新内容都添加到一个同样的物理日志文件中。
使用单个日志文件,明显改善了普通操作时的性能收益,但是它使得故障恢复变得复杂起来。当一个 tablet 服务器死亡,它上面承载的 tablet 会被重新分配到其他多个 tablet 服务器,每个 tablet 服务器通常只接收一部分 tablet。为了给一个 tablet 恢复状态,新的 tablet 服务器需要根据原来 tablet 服务器中记载的提交日志文件,为这个 tablet 重新执行一遍更新操作。但是,针对这些 tablet 的更新操作的日子记录,都混合存放在一个日志文件中。一种方法是,让新的 tablet 服务器完整地读取一份提交日志文件,然后,只把恢复这个 tablet 时所需要的日志记录读取出来,完成恢复。但是,在这种机制下,如果有 100 个机器,每个都被分配了来自死亡 tablet 服务器的一个单独的 tablet,那么这个日志文件就必须被重复读取 100 遍(每个服务读一次)。
我们通过以下的方式来避免日志的重复读写:首先以键(表,行名称,日志顺序号)的顺序对日志文件的条目(entry)进行排序。在排序得到的结果中,所有针对某个特定 tablet 的更新都是连续存放的,因此,可以通过一次磁盘寻找,然后顺序批量读取数据,这种方法具有较高的效率。为了实现并行排序,我们把日子文本分割成 64MB 为单位的分段,在不同的 tablet 服务器上对每个分段进行并行排序。主服务器会对排序过程进行协调,当一个 tablet 服务器表示需要从一些提交日志文件中恢复数据时,就需要启动排序过程。
因为很多原因(例如,GFS 服务器发生了许多写崩溃,或为到达某组三个 GFS 服务器经过的网络路径正在拥塞,或负载过重),将提交日志写入到 GFS 中去,有时会造成性能上的瓶颈。为了使得更新免受 GFS 延迟的影响,每个 tablet 服务器实际上有两个写日志线程,每个线程都写到它自己的日志中。在同一时间这 2 个线程只有一个线程在工作。如果当前活跃的写日志线程性能比较差,那么就切换到另一个写日志线程,提交日志队列中的更新就由这个新激活的线程来写入。日志条目包含了序号有助于在恢复过程删除那些由于线程切换而导致的重复的日志记录。
加速 tablet 恢复(Speeding up tablet recovery)
如果 master 把一个 tablet 从一个 tablet 服务器转移到另一个 tablet 服务器,这个源 tablet 服务器首先会对这个 tablet 做一个 minor compaction。这个压缩通过减少 tablet 服务器中的提交日志中的未压缩状态的数量可以减少了恢复时间。在完成这个压缩过程以后,这个源 tablet 服务器就停止提供针对这个 tablet 的服务。在源服务器完全卸载这个 tablet 之前,它要做另一个次压缩(通常很快)去删除该 tablet 服务器的中所有未压缩状态的日志,这些日志都是在第一个次压缩过程中产生的。当第二个次压缩完成时,这个 tablet 就可以被加载到另一个 tablet 服务器而不需要任何日志条目的恢复。
利用不变性(Exploiting immutability)
除了 SSTable 缓存外,因为我们所产生的所有 SSTable 都是不变的,这也简化了 BigTable 系统的其他部分。例如,当我们从 SSTable 中读取数据时,不需要进行同步任何对文件系统访问。因此针对行级别的并发控制可以高效地执行。只有 memtable 在被同时被读操作和写操作访问数据结构会是变化的。为了减少读 memtable 的冲突,我们让每个 memtable 行进行 copy-on-write 方式来允许读和写操作并行执行。
因为 SSTable 是不可变的,永久性删除数据的问题就转变成收集过时的 SSTable 的问题。每个 tablet 的 SSTable 都在 METADATA 表注册了。master 使用标记-清除垃圾收器来移除这些过时的 SSTable 集合,其中 METADATA 表中包含了这些 SSTable 的 root 集合。
最后,SSTable 的不可变性让我们可以更快地分割 tablet,而不是为每个子 tablet 生成一个新的 SSTable 集合。我们让子 tablet 和父 tablet 共享一个 SSTable 集合。
7 性能评估(Performance Evaluation)
我们建立了一个有 N 个 tablet 服务器的 BigTable 集群,通过不断修改 N 的值来衡量 Bigtable 的性能和可扩展性。Tablet 服务器的配置为:1GB 内存,并且把数据写到 GFS 单元中,这个 GFS 单元包含了 1786 个机器,每个机器具备 400GB IDE 硬盘。为了测试我们让 N 个客户端机器产生针对 BigTable 的负载(我们采用的客户端的数量和 tablet 服务器的数量是相等的,从而保证客户端不会成为瓶颈)。每个机器都有两个双核 Opteron 2GHz 芯片、充足的能够容纳工作集产生的数据的物理内存和一条千兆以太网链路。这些机器被安排为两层树型交换网络,在根部的带宽可以达到 100-200Gbps。所有这些机器都采用相同的配置,都在同一个域内,因此任何两台机器之间的通讯时间都不会超过 1 微秒。
Tablet 服务器、master、测试客户端和 GFS 服务器都在同样的机器集合上运行。每个机器都运行一个 GFS 服务器。其中一些机器还运行了一个 tablet 服务或一个客户端进程,或者运行了与这些实验同时使用池的其他作业的进程。
R 是参与这次测试的 BigTable 的 rowkey 去重后的数量,R 的选择需要确保每个 benchmark 在每个 tablet 服务器上读或写的数据量大约 1GB。
负责顺序写的 benchmark,使用名称从 0 到 R-1 的行键。行键的空间被分区成 10N 个等尺寸区间。这些区间被中央调度器分配到 N 个客户端,一旦,某个客户端已经处理完前面分配到的区间后,中央调度器就立即给这个客户端分配另一个区间。这种动态分配,可以减轻其他运行于当前机器上的进程对该机器的影响。我们在每个行键下面,写了一个单个字符串。每个字符串都是随机生成的,因此,不具备可压缩性。除此以外,在不同行键下面的字符串都是不同的,这样就不会存在跨行压缩。负责随机写的 benchmark 也是类似的,初了行键在写之前要以 R 为模数进行哈希操作,从而使得在整个 benchmark 期间,写操作负载可以均匀分布到整个行空间内。
负责顺序读的 benchmark 产生行键的方式,也和负责顺序写的 benchmark 类似。但是,顺序读 benchmark 不是在行键下面写数据,而是读取存储在行键下面的字符串,这些字符串是由前面的顺序写 benchmark 写入的。类似地,随机读 benchmark 会以随机的方式读取随机写 benchmark 所写入的数据。
Scan benchmark 和顺序读 benchmark 类似,但是,使用了由 BigTable API 所提供的支持,来扫描属于某个域区间内的所有值。使用一个 scan,减少了由 benchmark 所执行的 RPC 的数量,因为在 Scan 中,只需要一个 RPC 就可以从 tablet 服务器中获取大量顺序值。
随机读(mem) benchmark 和随机读 benchmark 类似,但是,包含这个 benchmark 数据的局部群组,被标记为 in-memory,因此,它是从内存中读取所需数据,而不是从 GFS 中读取数据。对这个 benchmark 而言,我们把每个 tablet 服务器所包含数据的数量,从 1GB 减少到 100MB,从而可以很好地装入 tablet 服务器可用内存中。

图 6 显示了,当读或写 1000 字节的数据到 BigTable 中时,我们的 benchmark 的性能。表格内容显示了每个 tablet 服务器每秒的操作的数量。图显示了每秒的操作的总数量。
单 tablet 服务性能(Single tablet-server performance)
让我们首先考虑只有一个 tablet 服务器的性能。随机读的性能要比其他类型的操作的性能都要差一个数量级,甚至差更多。每个随机读操作包含了,把一个 64KB 的 SSTable 块通过网络从 GFS 传输到一个 tablet 服务器,在这个块中,只有 1000 字节的数据会被使用。Tablet 服务器大约每秒执行 1200 个操作,这会导致从 GFS 需要读取大约 75MB/s。在这个过程中,带宽是足够的。许多具有这种访问模式的 BigTable 应用都把块大小设置为更小的值 8KB。
从内存读取数据的随机读会更快一些,因为,每个 1000 字节读都是从 tablet 服务器内存当中读取,而不需要从 GFS 当中读取 64KB 的数据。
随机和顺序写执行的性能要好于随机读,因为,每个 tablet 服务器都把所有到达的写都追加到一个单独的提交日志中,并且使用分组提交,从而使得到 GFS 的写操作可以流水化。在随机写和顺序写之间,没有明显的性能差别。在两种情形下,所有的写都记录在同一个提交日志中。
顺序读的性能要好于随机读,因为从 GFS 中获取的每 64KB SSTable 块,会被存储到块缓存中,它可以为后面的 64 个读操作服务。
Scan 操作会更快,因为针对单个 RPC,tablet 服务器可以返回大量的值,因此,RPC 开销就可以分摊到大量的值当中。
伸缩(Scaling)
当我们在系统中把 tablet 服务器的数量从 1 增加到 500 的过程中,累计吞吐量急剧增加,通常以 100 倍的规模。例如,随着 tablet 服务器增长了 500 倍,针对内存的随机读的性能,增长了大约 300 倍,之所以会发生这种情况,因为这个 benchmark 的性能瓶颈是单个 tablet 服务器的 CPU。
但是,性能不会线性增长。对于多数 benchmark 来说,当把 tablet 服务器的数量从 1 增加到 50 时,每个服务器的吞吐量有显著的降低。这个问题,是由多服务器环境中,负载不均衡引起的,通常由于有其他进程争抢 CPU 资源和网络带宽。我们的负载均衡算法努力解决这个问题,但是,无法实现完美的目标,主要原因在于:第一,重新负载均衡有时候会被禁止,这样做可以减少 tablet 迁移的数量(当一个 tablet 迁移时,在短时间内是不可用的,通常是一秒);第二,我们的 benchmark 的负载是动态变化的。
随机读 benchmark 显示了最差的可扩展性。当服务器数量增加 500 倍时,累计吞吐量的增长只有 100 倍左右。导致这个问题的原因在于,对于每个 1000 字节的读操作,我们都会转移一个 64KB 的块。这个数据转移使得我们的 GB 级别的网络很快达到饱和,这样,当我们增加机器的数量时,单个服务器的吞吐量就会很快降低。
8 实际应用(Real Applications)
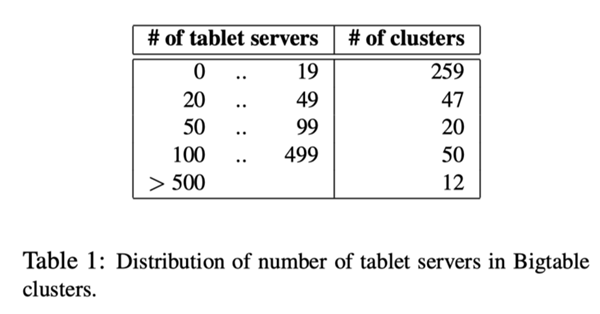
截止到2006年8月,已经又388个非测试的BigTable集群运行在不同的Google服务器集群里,包括总共大约24500个tablet服务器。表1显示了每个集群中的tablet服务器的大概分布。许多集群都是用于开发目的,因此,在很多时间内都是空闲的。一组包含14个繁忙集群(包含8069个tablet服务器),每秒钟的累积负载是120万个请求。其中,到达的RPC流量是741MB/s,出去的RPC流量大约是16GB/s。
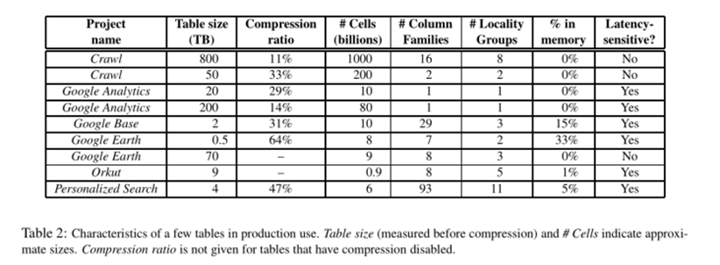
表2提供了一些关于当前正在使用的表的数据。一些表存储为用户服务的数据,而其他表则存储为批处理服务的数据。在总尺寸、平均单元格尺寸、从内存服务的数据的百分比以及表模式的复杂性方面,这些表区别很大。下面,我们将要分别描述三个产品团队如何使用BigTable。
8.1 谷歌分析(Google Analytics)
Google Analytics是一种服务,它帮助网站管理者分析网站流量模式。它提供了汇总分析,比如,每天不同访问者的数量,以及每天每个URL的网页视图的数量,以及网站流量报告,比如浏览了某个网页以后发生购买行为的用户的数量。
为了支持这项服务,网站管理员在网页中嵌入了一个小的Javascript程序。每当页面被访问时,都会触发这个Javascript程序。它把关于这个用户访问的所有相关信息都记录在Google Analytics中,比如用户标识以及被访问的网页的信息。Google Analytics分析这些数据,并提供给网站管理员访问。
我们简单地描述Google Analytics所使用的两个表。网站点击表(200TB)为每个用户访问都维护了一个行。行的名称是一个元祖,它包含了网站的名称以及session被创建的时间。这个表模式保证了,访问同一个WEB站点的session都是临近的,并且以时间顺序进行存储。这个表的压缩率可以达到14%。
汇总表(大约20TB)包含了针对每个网站的不同的汇总信息。这个表是从网站点击表中通过周期性地运行MapReduce作业而得到的。每个MapReduce作业从网站点击表当中抽取最近的session信息。系统的总吞吐量,受到了GFS吞吐量的限制。这个表的压缩率在29%左右。
8.2 谷歌地球(Google Earth)
Google提供很多服务,它支持用户访问高清晰度的卫星图片,或者通过基于浏览器的Google Maps接口,或者通过定制的客户端软件Google Earth。这些产品允许用户在地球表面进行导航。该产品支持在不同清晰度下查看和标注地图信息。该系统采用一个表进行数据预处理,用另一个表位用户提供数据服务。
这个预处理管道使用一个表来存储卫星图片。在预处理过程中,影像数据被清洗并转换成最后的服务数据。这个表包含了大约70TB的数据,因此,是从磁盘访问的。影像数据都是经过压缩的,因此,BigTable就不存在数据压缩了。
影像表中的每行,都对应一个单个的地理片段。行被命名,以保证相邻的地理分段在存储时彼此接近。表包含了一个列家族来跟踪每个分段的数据。这个列家族包含了大量的列,基本上为每个原始影像创建一个列。因为,每个分段只是从少量几个列中的影像构建得到的,因此,这个列家族很稀疏。
这个预处理管道严重依赖于针对BigTable的MapReduce操作来转换数据。在这些MapReduce作业运行期间,整个系统的每个服务器大约处理1MB/秒的数据。
这个服务系统使用一个表来对存储在GFS中的数据建立索引。这个表相对比较小,大约500GB。但是,每个数据中心每秒钟必须以很低的延迟处理成千上万个请求。因而,这个表通常被重复存放到多个tablet服务器上,并且包含了内存列家族。
8.3 个性化搜索(Personalized Search)
Personalized search是一种服务,它记录了用户查询和点击数据,涵盖了各个方面的Google属性,比如,网页搜索、图片和新闻。用户可以浏览他们自己的访问历史,他们可以要求根据Google使用历史模式来获得个性化的搜索结果。
Personalized search把所有的用户数据都存放在BigTable中。每个用户都有一个独特的用户ID,并被分配了以这个用户ID为名字的行。每种类型的动作都会存储到特定的列家族中,比如,有一个列家族存储了所有的网页查询。每个数据元素都把这个动作发生的时间作为BigTable的时间戳。Personalized search在BigTable上使用MapReduce产生用户的profile。这些用户profile用来协助生成个性化的用户搜索结果。
Personalized Search的数据被分布到多个BigTable集群,来增加可用性,减少由距离而产生的延迟。Personalized Search最初构建了基于BigTable的客户端副本模式,从而保证所有副本的最终一致性。当前的系统使用了一个复制子系统,它是内嵌到服务器端的。
Personalized Search存储系统的设计,允许其他分组增加新的用户信息到他们自己的列中,这个系统当前正在被许多Google属性使用,这些属性需要存储用户的配置信息和设置。在多个分组之间共享一个表,导致了列家族数量比较大。为了帮助支持共享,我们为BigTable增加了一个简单的配额机制,从而对共享表当中某个特定应用可以使用的存储空间进行限制。这种机制为每个用户在使用本系统的不同的产品分组之间建立了隔离。
9 教训(Lessons)
在设计、实现、维护和支持BigTable的过程中,我们收获了有益的经验,并且获得了几个有意思的教训。
我们得到的一个教训是,大的分布式系统很发生多种错误,不仅是其他分布式系统经常遇到的标准的网络分割和故障。例如,我们已经遇到问题,他们是由以下原因引起的:内存和网络故障、大的时钟扭曲、机器挂起、我们所使用的其他系统(比如Chubby)中存在的故障、GFS配额当中的溢出以及计划或非计划之中的硬件维护。随着我们获得了更多的针对这些问题的经验,我们已经通过改变不同的协议来解决他们。例如,我们为RPC机制增加了checksumming。我们通过移除一部分系统针对另一部分系统所做的假设,也解决了一些问题。例如,我们取消了假设一个给定的Chubby操作只返回一个固定错误集合。
我们获得的另一个教训是,在很清楚地知道如何使用一个新特性之前,不要随便增加这个新特性。例如,我们最初计划在我们的应用API当中支持通用的事务。因为我们不会立即用到这种功能,所以,我们没有实现它。现在我们有许多应用都是运行在BigTable之上,我们就可以考察他们的应用需求,发现很多应用只需要针对单个记录的事务。当人们需要分布式事务时,最主要的用途就在于维护二级索引,我们就考虑增加一个特定的机制来满足这种需求。在通用性方面,这种特定机制会比通用事务模型差一些,但是,它更高效,尤其是对于那些需要跨越多个行的更新而言。
从支持BigTable运行中获得的一个比较实际的教训是,合适的系统级别的监视的重要性,即监视BigTable自己,也监视运行在BigTable上的进程。例如,我们扩展了我们的RPC系统,从而使得对一些RPC样本,它会详细跟踪记录针对该RPC的重要动作。这种特性已经允许我们探测和解决许多问题,比如针对tablet数据结构的锁冲突,当执行BigTable更新时的慢写,以及当METADATA tablet不可用时,访问METADATA表发生的阻塞。说明监视比较有用的另一个例子是,每个BigTable集群都是在Chubby中注册的。这就允许我们跟踪所有的集群,发现这些集群的大小,看看它们当前使用的是我们软件的哪个版本,以及是否存在一些预料之外的问题,比如很大的延迟。
我们所获得的最重要的教训就是简单设计的价值。假设我们系统的尺寸是大约10万行非测试代码,以及这些代码会随着时间演化,我们发现代码和设计的清晰性对于代码和系统维护具有重要的帮助。一个例子是我们的tablet服务器成员协议。我们的第一个协议很简单,主服务器周期性地发布租约给tablet服务器,如果tablet服务器发现租约到期就自杀。不幸的是,当存在网络问题时,这种协议极大降低了系统的可用性,并且对于主服务器的恢复时间也很敏感。我们先后几次更改了协议的设计,直到找到一个好的协议。但是,这个比较好的协议,太复杂,并且依赖于那些很少被其他应用使用的Chubby功能。我们发现,我们花费了大量的时间来调试各种晦涩的案例。最后,我们废弃了这个协议,转向采用一个比较简单的新的协议,它只依赖那些经常被使用的Chubby功能。
10 相关工作(Related Work)
Boxwood 项目具有一些和 Chubby、GFS 以及 BigTable 重叠的组件,因为 Boxwood 支持分布式协议和分布式 B 树存储。在每个发生重叠的领域中,Boxwood 看起来似乎针对的是 Google 所提供服务的低一层次的服务。Boxwood 项目的目标是提供构建高层次服务的基础架构,比如文件系统或数据库,而 BigTable 的目标是直接支持那些需要存储数据的客户端应用。
许多最近的计划,已经解决了在广域网内提供分布式存储和高层次服务的问题。这些计划包括,在分布式哈希表方面的工作,比如项目 CAN、CHORD、Tapestry 和 Pastry。这些系统解决的问题,在 BigTable 中没有出现,比如高可用性带宽、不可信的参与者或频繁地重配置。分布式控制和理想的零错误不是 BigTable 的设计目标。
就可以提供给应用开发者的分布式存储模型而言,我们认为,分布式 B 树所提供的“键-值对”模型或者分布式哈希表具有很大的局限性。“键-值对”是一个有用的积木,但是,它不应该是可以提供给应用开发者的唯一的积木。我们所能提供的模型比简单的“键-值对”更加丰富,并且支持稀疏的半结构化数据。但是,它是非常简单的,并且足以支持非常高效的平面文件表示,并且它足够透明,允许用户来调节系统重要的行为。
有几个数据库开发商已经开发了并行数据库,它可以存储大量的数据。Oracle 的 Real Application Cluster 数据库,使用共享的磁盘来存储数据(BigTable 使用 GFS),并且使用一个分布式的锁管理器(BigTable 使用 Chubby)。IBM 的 DB2 Parallel Edition 是基于非共享的体系架构,这一点和 BigTable 类似。每个 DB2 服务器负责表中行的一个子集,它被存储在一个局部关系数据库中。IBM 的 DB2 Parallel Edition 和 Oracle 的 Real Application Cluster 都提供了完整的事务模型。
BigTable 局部分组实现了和其他一些系统类似的压缩和磁盘读性能,这些系统在磁盘上存储数据时,采用基于列而不是基于行的存储,包括 C-store 和商业化产品,比如 Sybase IQ,SenSage,KDB+,以及在 MonetDB/X100 当中的 Column BM 存储层。另一个把数据垂直和水平分区到平面文件中并且取得了很好的数据压缩率的系统是,AT&T 的 Daytona 数据库。局部分组不支持 CPU 缓存级别的优化,比如那些在 Ailamaki 中描述的。
BigTable 使用 memtable 和 SSTable 来存储 tablet 更新的方式,和 Log-Structured Merge Tree 用来存储索引更新的方式是类似的。在这两个系统中,排序的数据在写入到磁盘之前是存放在内存之中的,读操作必须把来自磁盘和内存的数据进行合并。
C-Store 和 BigTable 具有很多相似的特性:两个系统都使用非共享的体系架构,都有两个不同的数据结构,一个是为存放最近的写操作,一个是为存放长期的数据,并且设计了把数据从一个结构转移到另一个结构的机制。但是,这两个系统在 API 方面具有很大的区别:C-Store 就像一个关系型的数据库,而 BigTable 提供了一个低层次的读和写接口,并且被设计成在每个服务器上每秒钟内提供成千上万的这种操作。C-Store 也是一个读优化的关系型 DBMS,而 BigTable 对读敏感和写敏感的应用都提供了很好的性能。
BigTable 的负载均衡器,必须解决负载均衡和内存均衡问题,这也是非共享数据库通常面临的问题。我们的问题更加简单一些:(1)我们不考虑同一个数据存在多个副本的情形,我们可能采用视图或索引的形式以另一种方式来看待副本;(2)我们让用户告诉我们,什么数据应该放在内存中,什么数据应该放在磁盘上,而不是系统自己尽力去猜测数据的存放位置;(3)我们没有复杂的查询优化机制,也不执行复杂的查询。
总结(Conclusions)
我们已经描述了 BigTable,一个为 Google 存储数据的分布式存储系统。自从 2005 年 4 月开始,BigTable 集群已经在实际生产系统中使用。在那之前,我们已经投入了 7 个 person-years 在设计和开发上。截止 2006 年 8 月,有超过 60 项计划正在使用 BigTable。我们的用户喜欢 BigTable 提供的高性能和高可用性。当用户的资源需求随着时间变化时,他们只需要简单地往系统中添加机器,就可以实现服务器集群的扩展。
鉴于 BigTable 的不同寻常的接口,一个有意思的问题是,我们的用户适应 BigTable 的过程是多么艰难。新的用户有时候不知道如何很好地使用 BigTable 提供的接口,尤其是,他们已经习惯使用支持通用事务的关系型数据库。但是,许多 Google 产品成功地使用 BigTable 来存放数据这样一个事实,已经说明 BigTable 设计的成功。
我们正在考虑增加其他几个额外的 BigTable 功能,比如支持二级索引,以及一个基础框架,它可以支持构建跨数据中心分布 BigTable 数据。我们已经开始把 BigTable 作为一个服务提供给产品组,从而使得每个组都不需要维护他们自己的集群。随着我们的服务集群的扩展,我们需要处理更多的 BigTable 内部的资源共享的问题。
最后值得一提的是,我们发现在 Google 构建我们的存储解决方案有很大的优势。我们不仅有足够的灵活度为 BigTable 设计数据模型,我们还能够完全控制 BigTable 的实现,甚至 BigTable 依赖的其它 Google 基础设施。这些权限意味着一旦(BigTable 或其依赖的基础设施)出现了瓶颈和低效之处,我们能够及时解决。


