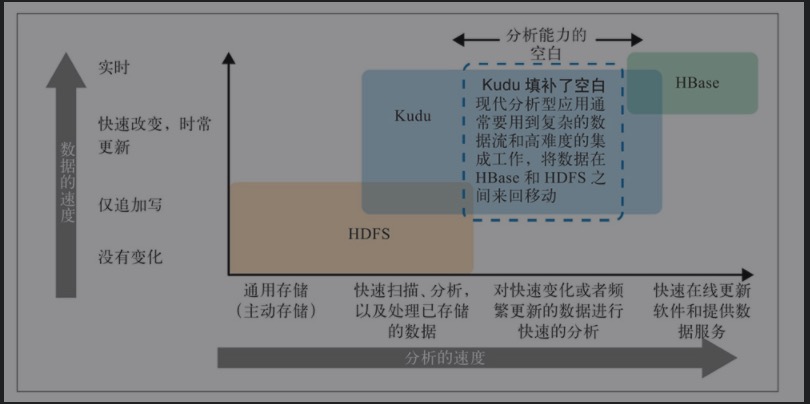
Kudu简介
Apache Kudu是一个开源的列式存储引擎,专为快速分析和随机访问而设计,适用于大数据工作负载。它填补了Hadoop生态系统中对需要快速分析和低延迟更新的应用程序的需求。

核心特性
- 列式存储:Kudu采用列式存储格式,这使得它在分析工作负载中具有很高的性能,特别是在需要扫描大量数据的场景中。
- 快速随机访问:Kudu支持低延迟的随机读写操作,使得它在需要频繁更新和查询的场景中表现出色。
- 水平扩展:Kudu可以通过增加节点来水平扩展,以支持更大的数据集和更高的吞吐量。
- 实时分析能力:Kudu的设计使其能够支持实时数据分析,适合需要快速数据摄取和查询的应用。
- 与Hadoop生态系统的集成:Kudu可以与Apache Impala、Apache Spark等分析工具无缝集成,提供快速的SQL查询能力。
优势
- 低延迟更新和查询:结合了HDFS的批处理能力和HBase的快速随机访问能力,适合需要低延迟的应用。
- 简化的数据管道:通过支持实时摄取和分析,减少了数据管道的复杂性。
- 灵活的查询能力:与Impala、Spark的集成提供了强大的SQL查询能力,支持复杂的分析查询。
限制
- 成熟度和社区支持:相比于其他成熟的存储引擎,Kudu的社区支持和文档可能相对较少。
- 生态系统限制:虽然与Hadoop生态系统中的一些工具集成良好,但在某些场景中,可能不如其他专用工具表现优异。
- 资源消耗:Kudu的性能和扩展性可能需要较高的资源投入,特别是在大规模集群中。
使用场景
- 实时分析:适用于需要快速数据摄取和实时分析的场景,如流处理、物联网数据分析。
- 混合工作负载:支持混合的读写工作负载,适合需要同时进行数据摄取和分析的应用。
- 数据湖架构:在数据湖架构中,Kudu可以作为存储引擎,为数据分析和机器学习提供支持。
Apache Kudu是一个强大的工具,特别适合需要快速分析和随机访问的工作负载。它通过在批处理和实时处理之间架起桥梁,为大数据分析提供了一种高效的解决方案。
Kudu与Hbase对比
Apache Kudu和Apache HBase都是Hadoop生态系统中的分布式存储解决方案,但它们在设计目标和特性上有一些不同,这使得Kudu在某些场景下具有相对于HBase的优势。
以下是Kudu相比HBase的一些主要优势:
- 列式存储:
- Kudu:采用列式存储格式,适合分析型工作负载,尤其是在需要扫描大量数据时具有更高的性能。
- HBase:采用行式存储,适合快速随机读写,但在分析型查询上可能不如列式存储高效。
- 实时分析能力:
- Kudu:设计用于支持实时数据摄取和分析,可以在低延迟的情况下进行快速查询。
- HBase:主要用于快速随机访问和OLTP类型的工作负载,实时分析能力相对有限,需要结合其他工具如Apache Phoenix进行优化。
- 一致性和延迟:
- Kudu:使用Raft协议实现强一致性,支持低延迟的更新和查询操作。
- HBase:使用HDFS作为存储层,延迟可能较高,尤其是在写操作时,可能需要等待HDFS的同步。
- 查询性能:
- Kudu:与Apache Impala和Apache Spark的紧密集成提供了强大的SQL查询能力,适合复杂的分析查询。
- HBase:需要结合其他查询引擎(如Phoenix)来支持SQL查询,查询性能可能不如Kudu集成的解决方案。
- 数据模型灵活性:
- Kudu:支持更灵活的数据模型和数据类型,适合需要复杂分析的应用。
- HBase:虽然也支持灵活的数据模型,但在处理复杂数据类型和分析场景时可能不如Kudu直接。
- 简化的数据管道:
- Kudu:支持实时数据摄取和分析,简化了数据管道的复杂性,不需要额外的ETL过程来转换数据格式。
- HBase:通常需要与其他系统集成进行批处理和分析,可能导致数据管道更加复杂。
- 集群管理和扩展:
- Kudu:设计上简化了集群管理,支持动态扩展和负载均衡。
- HBase:扩展和管理可能更复杂,尤其是在大规模集群中。
以下是Apache Kudu和Apache HBase的详细对比:
| 特性 | Apache Kudu | Apache HBase |
| 存储模型 | 列式存储 | 行式存储 |
| 数据访问模式 | 支持快速随机读写和批量扫描 | 优化随机读写,批量扫描性能较低 |
| 实时分析能力 | 优秀,适合低延迟分析工作负载 | 需要结合其他工具(如Phoenix)进行优化 |
| 一致性模型 | 强一致性,通过Raft协议实现 | 行级强一致性,通过HDFS提供数据持久性 |
| 查询性能 | 与Impala和Spark集成良好,支持高效SQL查询 | 需要结合Phoenix提供SQL查询,性能可能不如Kudu |
| 数据模型 | 类似关系型数据库,支持复杂数据类型 | 灵活的数据模型,主要为键值对 |
| 扩展性 | 支持水平扩展,动态负载均衡 | 支持水平扩展,但扩展和负载均衡可能更复杂 |
| 数据摄取和处理 | 支持实时摄取和处理,简化数据管道 | 通常需要与其他系统集成进行批处理和分析 |
| 与 Impala、Spark 无缝集成,适合实时分析 | 与 Hadoop 生态系统其他工具(如 Hive、Pig)集成良好 | |
| 延迟 | 低延迟的读写操作 | 写操作延迟较高,受限于 HDFS 的同步机制 |
| 应用场景 | 实时数据分析、混合工作负载、数据湖架构 | 高吞吐量随机访问、OLTP 工作负载、时间序列数据管理 |
| 成熟度和社区支持 | 较新,社区支持和文档相对较少 | 成熟度高,广泛应用于生产环境,社区支持良好 |
总结
- Kudu:适合需要实时分析和低延迟查询的场景,特别是在需要结合 SQL 查询和复杂分析的应用中表现出色。其列式存储使其在分析型工作负载中具有更高的性能。
- HBase:适合需要高吞吐量和快速随机访问的应用,如在线服务的后端存储和时间序列数据管理。其行式存储和强一致性支持使其在 OLTP 类型的工作负载中具有优势。
Kudu 的架构
Kudu 的核心架构
Kudu 使用单个 Master 节点管理集群和元数据,使用任意数量的 TabletServer 节点来存储实际数据,可以部署多个 Master 节点来提高容错。
Kudu 架构中分为 MasterServer,TabletServer,Table,Tablet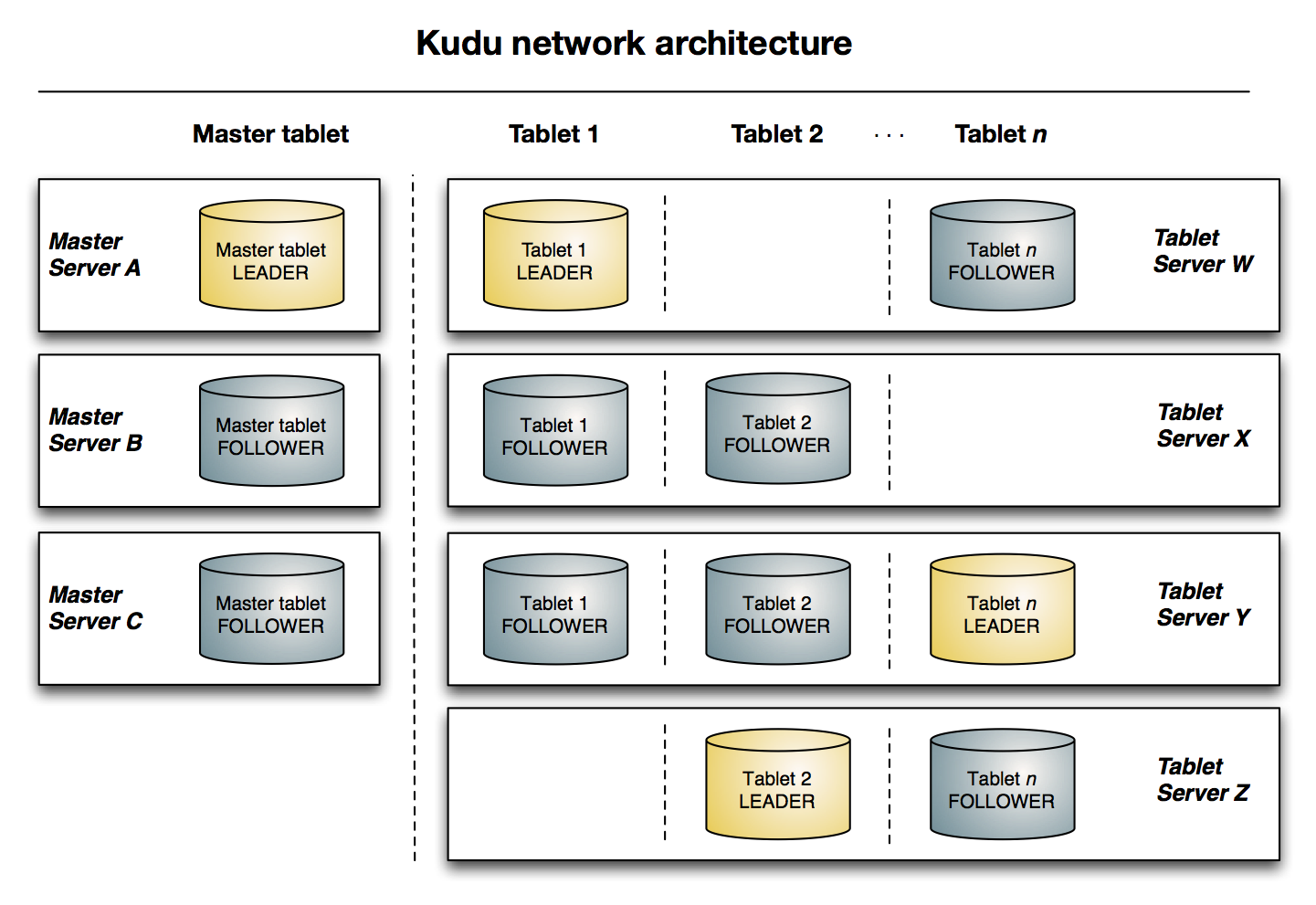
- MasterServer: Kudu 集群中的老大,可以有多个 MasterServer 提高集群的容错能力,但是只有一个 MasterServer 对外提供服务,负责管理集群和管理元数据。
- TabletServer: Kudu 集群中的小弟,可以有任意多个,负责存储数据和数据读写。在 TabletServer 上存储 Tablet,对于一个 Tablet,只有其中一个 TableServer 作为 leader,提供读写服务,其他 TableServer 都是 follower,只提供读服务。
- Table: Kudu 中的表概念,有 Schema 和 PrimaryKey 概念,Kudu 中的表会被水平方向分为多个 Tablet 片段存储在 TabletServer 上。
- Tablet: 一个 Tablet 是一张表的一个连续片段,tablet 是表的水平分区,tablet 之间的 primary key 范围不会重叠,一张表的所有 tablet 片段构成了这张表的所有 primary key 范围。tablet 会冗余存储在多个 TabletServer 上设置副本,任何时刻只有一个 TabletServer 是 leader,其他都是 follower。
数据模型
Kudu 的设计是面向结构化存储的,数据模型与传统的关系型数据库类似,一个 Kudu 集群由多个表组成,每个表由多个字段组成,一个表必须指定一个由若干个(>=1)字段组成的主键,如下图:
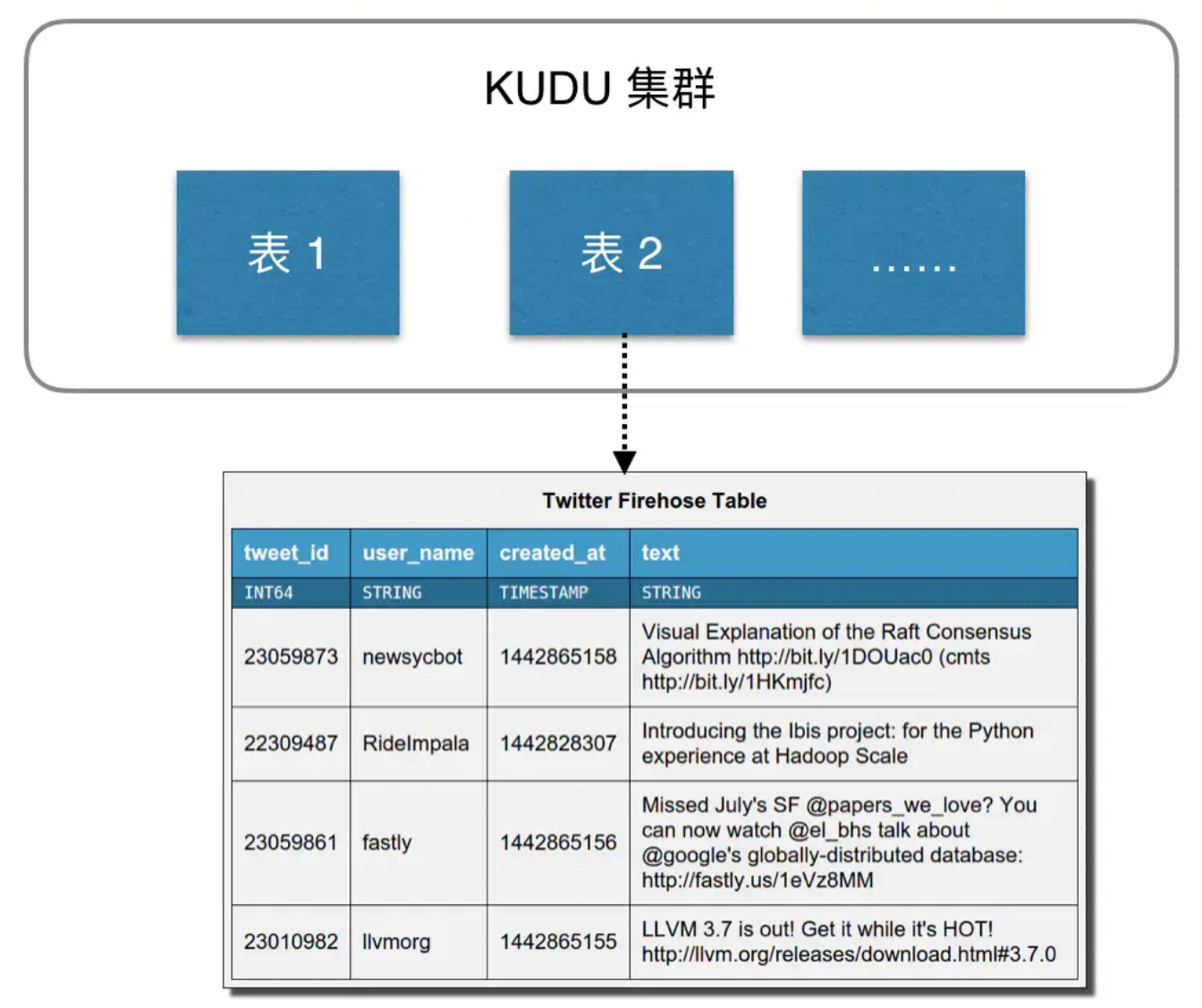
- Kudu 需要在建表时定义 Schema 信息,包括定义列(列类型)和主键 primary key。
- Kudu 的数据唯一性依赖与 primary key 的列组合
- Kudu 不支持传统关系型数据库的二级索引
- Kudu 表中的每个字段是强类型的,而不是 HBase 那样所有字段都认为是 bytes。这样做的好处是可以对不同类型数据进行不同的编码。
- Kudu 的数据类型包括 BOOL, INT8, INT16, INT32, BIGINT, INT64, FLOAT, DOUBLE, STRING, BINARY
底层数据模型
Kudu 的底层存储基于 table/tablet/replica 视图级别的底层存储系统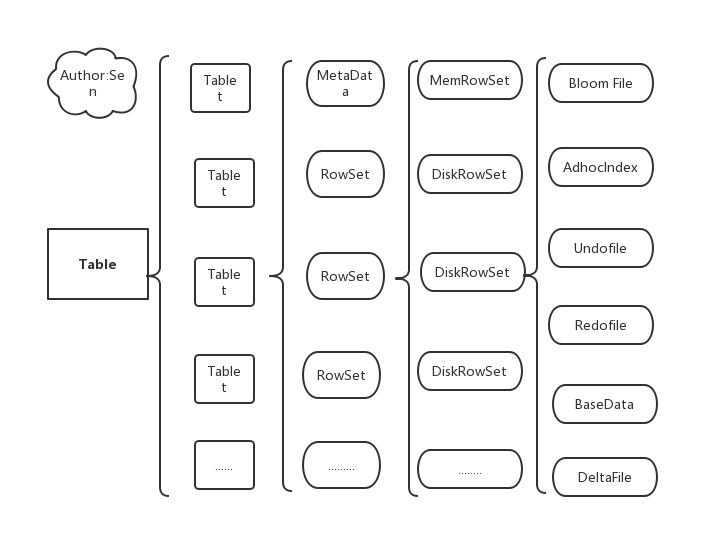
- 每个 table 被划分为 tablet,每个 tablet 包含一个 MetaData 和若干个 RowSet(行集合)
- MetaData 记录元数据,即记录该 tablet 属于哪个 table,RowSet 包含一个 MemRowSet 和若干个 DiskRowSet
- MemRowSet:当有新数据插入时写入 MemRowSet,以及修改已经在 MemRowSet 中的数据,当 MemRowSet 写满或者超过一定时间后刷入磁盘形成若干个 DiskRowSet,默认是 1G 或者 120s
- DiskRowSet:MemRowSet 每刷新一次就会生成一个 DiskRowSet,DiskRowSet 刷下来之后就不在变化了,DiskRowSet 中又包含 BloomFIle,AdhoxIndex,BaseData,UndoFile,RedoFile,DeltaMem
- BloomFIle:根据一个 DiskRowSet 中的 key 生成布隆过滤器,用于快速模糊定位某个 key 是否在 DiskRowSet 中
- AdhoxIndex:如果 key 在 DiskRowSet 中定位 key 的具体偏移位置
- BaseData:MemRowSet 刷如磁盘的数据,按列存储,按主键排序
- RedoFile:保存更新后的数据,防止事务成功后数据未在磁盘更新
- UbdoFile:保存更新前的数据,防止事务失败后恢复原始数据
- DeltaMem:用于 DiskRowSet 数据的更新,存储 DiskRowSet 中变更的数据,随着 DiskRowSet 的变化,DeltaMem 记录变更记录,DeltaMem 增长到一定程度刷到磁盘形成 deltaData
tablets 在 Kudu 里面被切分成更小的单元 RowSets:
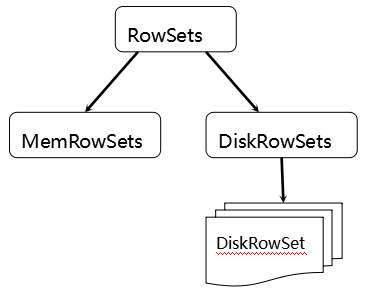
MemRowSets 可以对比理解成 HBase 中的 MemStore, 而 DiskRowSets 可理解成 HBase 中的 HFile。MemRowSets 中的数据按照行试图进行存储,数据结构为 B-Tree。MemRowSets 中的数据被 Flush 到磁盘之后,形成 DiskRowSets。
DiskRowSet 中的数据按照 Column 进行组织,与 Parquet 类似。这是 Kudu 可支持一些分析性查询的基础。
一个 DiskRowSet 包含两部分数据:基础数据 (BaseData),以及变更数据 (DeltaStores)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
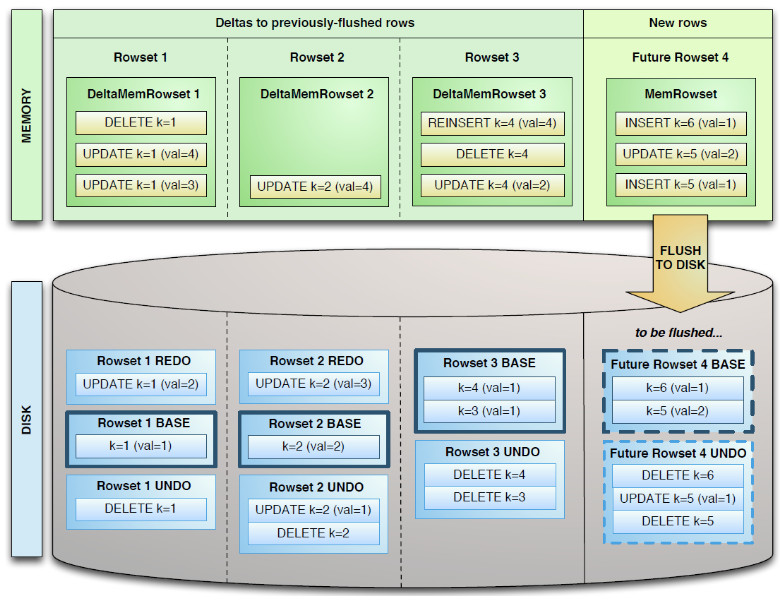
Delta 数据部分包含 REDO 与 UNDO 两部分:
- REDO DeltaFiles 包含了 BaseData 自上一次被 Flush/Compaction 之后的变更值。REDO DeltaFiles 按照 Timestamp 顺序排列。
- UNDO DeltaFiles 包含了 BaseData 自上一次 Flush/Compaction 之前的变更值。这样才可以保障基于一个旧 Timestamp 的查询能够看到一个一致性视图。UNDO 按照 Timestamp 倒序排列。
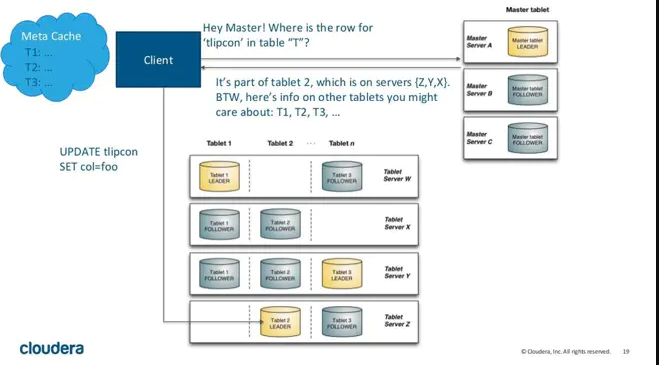
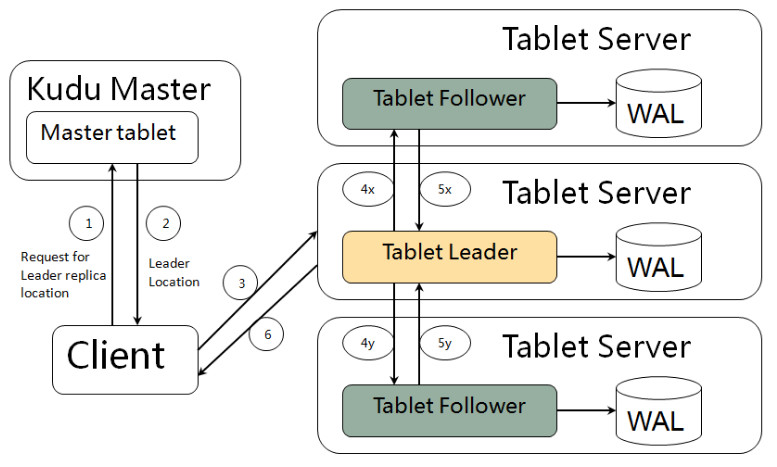
kudu client与服务端交互,先从Master Server获取元数据信息,然后去Tablet Server读写数据,如下图:
数据分区策略
Kudu对表进行横向分区,Kudu表会被横向切分存储在多个tablets中。不过相比与其他存储引擎,Kudu提供了更加丰富灵活的数据分区策略。一般数据分区策略主要有两种,一种是Range Partitioning,另一种分区策略是Hash Partitioning。
- Range Partitioning: 按照字段值范围进行分区,HBase就采用了这种方式,优势是在数据进行批量读的时候,可以把大部分的读变成同一个tablet中的顺序读,能够提升数据读取的吞吐量。并且按照范围进行分区,我们可以很方便的进行分区扩展。其劣势是同一个范围内的数据写入都会落在单个tablet上,写的压力大,速度慢。
- Hash Partitioning: 按照字段的Hash值进行分区,Cassandra采用了这个方式,由于是Hash分区,数据的写入会被均匀的分散到各个tablet中,写入速度快。但是对于顺序读的场景这一策略就不太适用了,因为数据分散,一次顺序读需要将各个tablet中的数据分别读取并组合,吞吐量低。并且Hash分区无法应对分区扩展的情况。
Kudu支持用户对一个表指定一个范围分区规则和多个Hash分区规则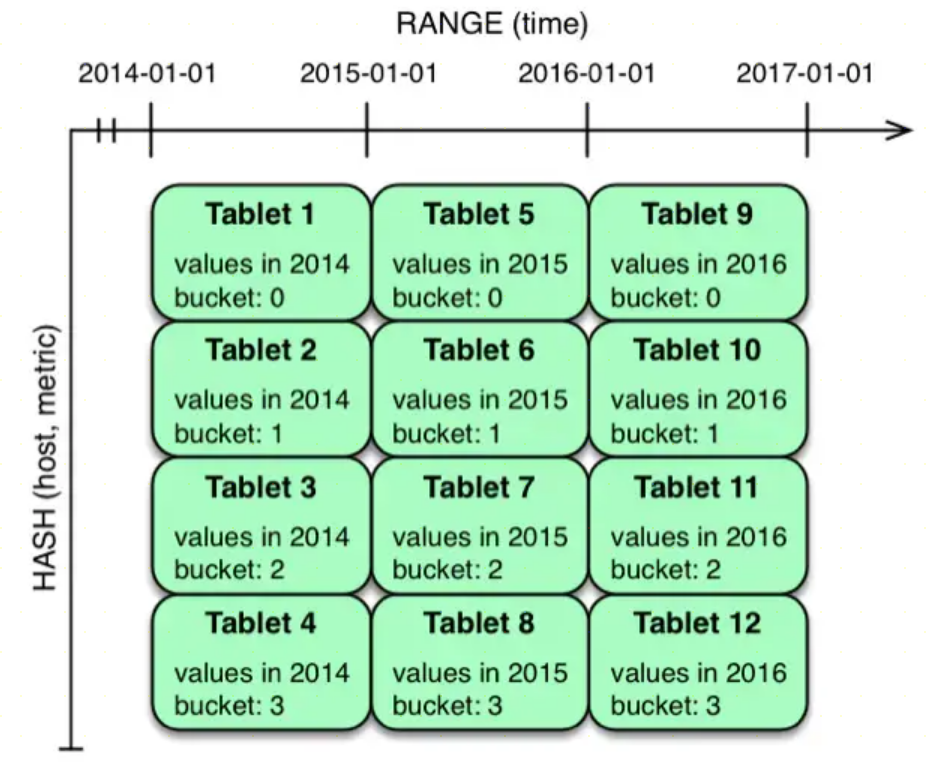
Kudu的读写更新流程
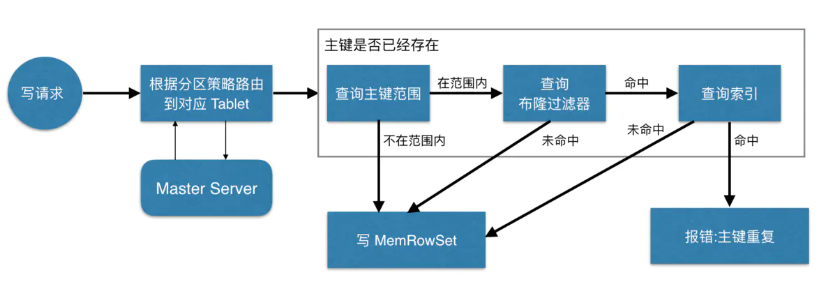
写数据
当Client请求写数据时,先根据主键从Mater Server中获取要访问的目标Tablets,然后到依次对应的Tablet获取数据。因为KUDU表存在主键约束,所以需要进行主键是否已经存在的判断,这里就涉及到之前说的索引结构对读写的优化了。一个Tablet中存在很多个RowSets,为了提升性能,我们要尽可能地减少要扫描的RowSets数量。首先,我们先通过每个RowSet中记录的主键的(最大最小)范围,过滤掉一批不存在目标主键的RowSets,然后在根据RowSet中的布隆过滤器,过滤掉确定不存在目标主键的RowSets,最后再通过RowSets中的B-树索引,精确定位目标主键是否存在。如果主键已经存在,则报错(主键重复),否则就进行写数据(写MemRowSet)。
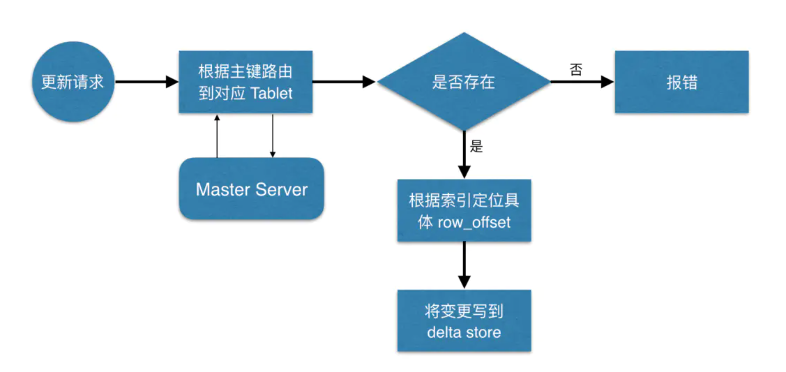
更新数据
定位到具体位置后,然后将变更写到对应的deltastore中。
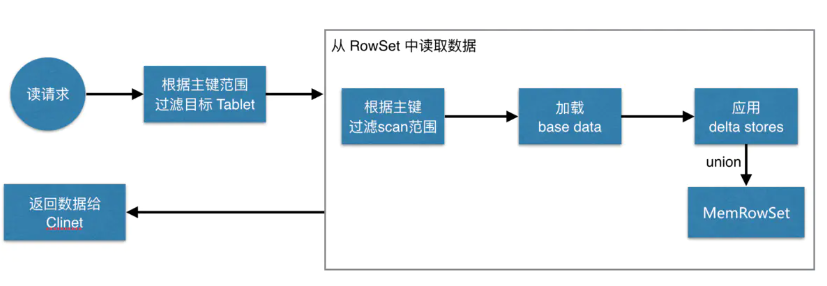
读数据
先根据要扫描数据的主键范围,定位到目标的Tablets,然后读取Tablets中的RowSets。在读取每个RowSet时,先根据主键过滤要scan范围,然后加载范围内的base data,再找到对应的deltastores,应用所有变更,最后union上MenRowSet中的内容,返回数据给Client。
参考链接:


