背包问题(Knapsack problem)是动态规划的经典问题。动态规划的基础是递归,和分治一样,都是假设子问题已经解决,由子问题的解组合计算得到父问题的解,类似裴波那契数列中的递推式如f(n) = f(n-1) + f(n-2)。但…

就像哲学有不同的流派一样,推荐系统的算法设计思路也可以分为不同的流派。排序学习恰恰就是其中的一种流派。熟悉 RecSys 等推荐系统国际会议的从业者可能会发现,自 2010 年以后的若干年内,陆续出现了许多基于排…

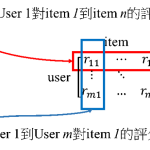
ALS(alternating least squares) ALS是交替最小二乘的简称。在机器学习中,ALS特指使用交替最小二乘求解的一个协同推荐算法。如:将用户(user)对商品(item)的评分矩阵分解成2个矩阵: user对item潜在因素的…
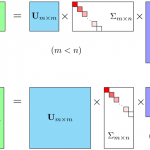
什么是 SVD? 奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分解,在生物信息学、信号处理、金融学、统计学等领域有重要应用,SVD 都是提取信息的强度工具。在机器学习领域,很多应用与奇…
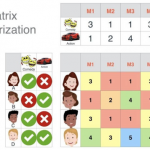
矩阵分解简介 推荐领域的人一般都会听说过十年前 Netflix Prize 的比赛,随着 Netflix Prize 推荐比赛的成功举办,近年来隐语义模型(Latent Factor Model,LFM)受到越来越多的关注。隐语义模型最早在文本挖掘领域…
点击率(click-through rate, CTR)是点击特定链接的用户与查看页面,电子邮件或广告的总用户数量之比。它通常用于衡量某个网站的在线广告活动是否成功,以及电子邮件活动的有效性,是互联网公司进行流量分配的核心依…
神经网络简介 神经网络的结构模仿生物神经网络,生物神经网络中的每个神经元与其他神经元相连,当它"兴奋"时,向下一级相连的神经元发送化学物质,改变这些神经元的电位;如果某神经元的电位超过一个阈值,则被激活…
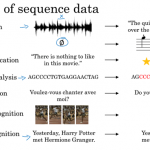
普通RNN存在的问题 循环神经网络(Recurrent Neural Network,RNN)是一种用于处理序列数据的神经网络。相比一般的神经网络来说,他能够处理序列变化的数据。比如某个单词的意思会因为上文提到的内容不同而有不同的…
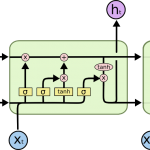
循环神经网络 RNN 简介 传统的神经网络是层与层之间是全连接的,但是每层之间的神经元是没有连接的(其实是假设各个数据之间是独立的),这种结构不善于处理序列化的问题。比如要预测句子中的下一个单词是什么,这…
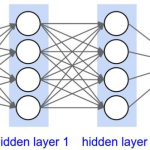
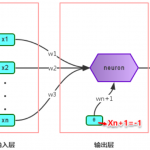
全连接神经网络 全连接神经网络是一种最基本的神经网络结构,英文为 Full Connection,所以一般简称 FC。FC 的准则很简单:神经网络中除输入层之外的每个节点都和上一层的所有节点有连接。 上图是一个双隐层的前…