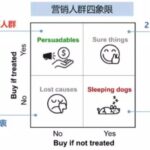
随着机器学习等技术的发展,智能化营销已经渗透到各行各业。商家可以通过多种渠道触达消费者,比如淘宝上商家可以圈定他想要的目标人群,进行广告推送,为店铺拉新,也可以通过短信或旺旺这些渠道定向发放优惠券。…
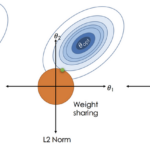
什么是正则化? 正则化(Regularization)是机器学习中一种防止模型过拟合的核心技术。它的核心思想是:在模型训练过程中,对模型的复杂度施加惩罚,让模型在“拟合数据”和“保持简单”之间找到平衡。简单来说,正则…
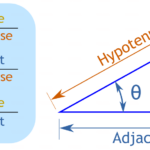
三角函数回顾 六大三角函数 直角三角形定义 在一个直角三角形中,假设有一个锐角$\theta$,定义: 邻边(Adjacent):与角$\theta$相邻的边。 对边(Opposite):与角$\theta$相对的边。 斜边(Hypotenuse):…
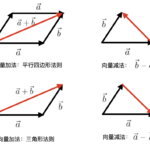
在线性代数中,向量和矩阵是重要的概念。向量是一种特殊的矩阵,矩阵也是一种特殊的向量。一个n维向量,可以写成nx1的矩阵,或者1xn的矩阵,分别叫做列向量与行向量。单个向量可以视为一阶矩阵,多个向量组合在一起…
Scikit-Opt 简介 scikit-opt 是一个封装了多种启发式算法的 Python 代码库,可以用于解决优化问题。虽然它的名字与著名的机器学习库 scikit-learn 相似,但两者并没有直接的隶属关系。 核心特点: 多算法支…
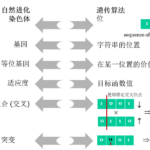
2024高考作文「新课标一卷」的作文题目:随着互联网的普及、人工智能的应用,越来越多的问题能很快得到答案。那么,我们的问题是否会越来越少?以上材料引发了你怎样的联想和思考?请写一篇文章。要求:选准角度,…
线性回归是机器学习中最为简单的模型,但在实际使用过程中可能不太适用。比如以下场景: 分段线性拟合是一种用于对数据进行建模的回归方法,其中数据在不同的区间内使用不同的线性函数进行建模。与简单线性回归…
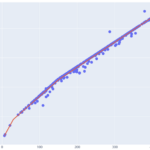
超参数优化简介 目前人工智能和深度学习越趋普及,大家可以使用开源的 Scikit-Learn、TensorFlow 来实现机器学习模型。对于各种模型而言,或多或少都具有要调节的超参数。相同的模型应用在不同的数据集上,如何选择…

针对 Facebook Prophet 的使用,很多年以前就整理过一篇文章《Facebook 时间序列预测工具 fbprophet》,过了 N 年以后当重新需要使用这个工具的时候,发现部分内容已经更新,中间的很多细节内容都没有表述清楚。实…
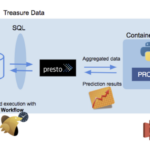
在上一篇重新认识Excel 的文章中,提到了Excel无所不能,然后就想到了曾经看到的这篇关于如何使用Excel搭建推荐引擎的文章。于是找了出来做了下简单的翻译(只翻译了重点部分)。 在互联网上有无限的货架空间,找…






