先前对于生存分析的理解比较片面,虽然知道生存分析不仅仅适用于预料行业,对于用户留存的也有一定的范围,当时的理解是只适合订阅制的网站用来分析用户留存,但是仔细分析后发现适用场景还是蛮多的。其中个人觉得…

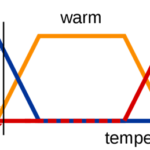
Fuzzy C-Means简介 模糊理论 模糊控制是自动化控制领域的一项经典方法。其原理则是模糊数学、模糊逻辑。1965,L.A. Zadeh发表模糊集合“Fuzzy Sets”的论文,首次引入隶属度函数的概念,打破了经典数学“非0即1”的局限…
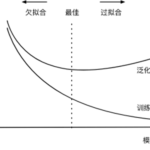
对于深度学习或机器学习模型而言,我们不仅要求它对训练数据集有很好的拟合(训练误差),同时也希望它可以对未知数据集(测试集)有很好的拟合结果(泛化能力),所产生的测试误差被称为泛化误差。度量泛化能力的…
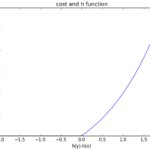
GBRank是一种pair-wise的学习排序算法,他是基于回归来解决pair对的先后排序问题。在GBRank中,使用的回归算法是梯度提升数GBT (Gradient Boosting Tree) 算法原理 Learning To Rank需要解决的问题是给定一个Query…
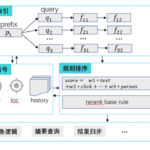
谈到推荐系统,很多人的印象中是“个人性推荐”和“千人千面”。关于“千域千面”应该很少人提及,主要能用到的场景不多,先前有想过在酒店场景上应用,但是由于各种原因最终没有尝试。以下是高德地图在“千域千面”的一些…
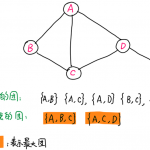
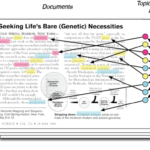
在潜在语义分析LSA的文章中对LDA有一些简单的介绍,今天的目标是对LDA进行相对深入的了解,大致搞明白其原理。 LDA简介 在机器学习领域中有2个LDA: 线性判别分析(Linear Discriminant Analysis),主要用于降维和…
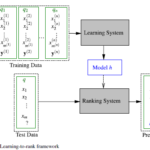
Learning to Ranking简介 Learning to Rank(LTR)是指一系列基于机器学习的排序算法,最初主要应用于信息检索(Information Retrieval,IR)领域,最典型的是解决搜索引擎对搜索结果的排序问题。除了信息检索以外…
什么是信息熵? 信息是我们一直在谈论的东西,但信息这个概念本身依然比较抽象。在百度百科中的定义:信息,泛指人类社会传播的一切内容,指音讯、消息、通信系统传输和处理的对象。但信息可不可以被量化,怎样量…
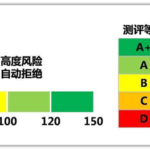
什么是信用评分卡模型? 评分卡模型又叫做信用评分卡模型,最早由美国信用评分巨头 FICO 公司于 20 世纪 60 年代推出,在信用风险评估以及金融风险控制领域中广泛使用。银行利用评分卡模型对客户的信用历史数据的多…
条件随机场(conditional random field, CRF)是用来标注和划分序列结构数据的概率化结构模型。言下之意,就是对于给定的输出,标识序列Y和观测序列X,条件随机场通过定义条件概率P(Y|X),而不是联合概率分布P(X,Y)来…