CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Gradient Boosting(梯度提升)+Categorical Features(类别型特征),也是基于梯度提升决策树的机器学习框架。
CatBoost 简介
CatBoost这个名字来自两个词”Category”和”Boosting“。如前所述,该库可以很好地处理各种类别型数据,是一种能够很好地处理类别型特征的梯度提升算法库。
CatBoost的优点
- 性能卓越:在性能方面可以匹敌任何先进的机器学习算法
- 鲁棒性/强健性:它减少了对很多超参数调优的需求,并降低了过度拟合的机会,这也使得模型变得更加具有通用性
- 易于使用:提供与scikit集成的Python接口,以及R和命令行界面
- 实用:可以处理类别型、数值型特征
- 可扩展:支持自定义损失函数
与其他提升(Boosting)算法相比,CatBoost怎么样?
CatBoost的开发人员将其性能与标准ML数据集的竞争对手进行了比较:
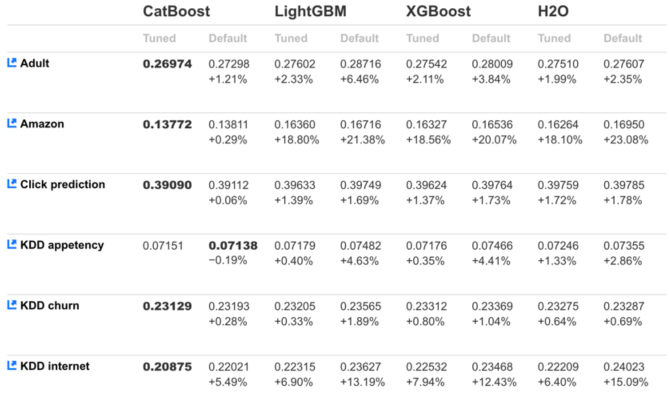
上面的比较显示了测试数据的对数损失(log-loss)值,在CatBoost的大多数情况下,它是最低的。图中清楚地表明了CatBoost对调优和默认模型的性能都更好。
CatBoost技术介绍
类别型特征
CatBoost算法的设计初衷是为了更好的处理GBDT特征中的categorical features。在处理GBDT特征中的categorical features的时候,最简单的方法是用categorical feature对应的标签的平均值来替换。在决策树中,标签平均值将作为节点分裂的标准。这种方法被称为Greedy Target-based Statistics,简称Greedy TBS,用公式来表达就是:
$$\hat{x}_k^i=\frac{\sum_{j=1}^{n}[x_{j,k}=x_{i,k}]\cdot Y_i}{\sum_{j=1}^{n}[x_{j,k}=x_{i,k}]}$$
这种方法有一个显而易见的缺陷,就是通常特征比标签包含更多的信息,如果强行用标签的平均值来表示特征的话,当训练数据集和测试数据集数据结构和分布不一样的时候会出问题(条件偏移问题)。
一个标准的改进Greedy TBS的方式是添加先验分布项,这样可以减少噪声和低频率数据对于数据分布的影响:
$$\hat{x}_k^i=\frac{\sum_{j=1}^{p-1}[x_{\sigma_j,k}=x_{\sigma_p,k}]Y_{\sigma_j}+a\cdot P}{\sum_{j=1}^{p-1}[x_{\sigma_j,k}=x_{\sigma_p,k}]+a}$$
其中P是添加的先验项,a通常是大于0的权重系数。添加先验项是一个普遍做法,针对类别数较少的特征,它可以减少噪音数据。对于回归问题,一般情况下,先验项可取数据集的均值。对于二分类,先验项是正例的先验概率。利用多个数据集排列也是有效的,但是,如果直接计算可能导致过拟合。CatBoost利用了一个比较新颖的计算叶子节点值的方法,这种方式可以避免多个数据集排列中直接计算会出现过拟合的问题。
特征组合
值得注意的是几个类别型特征的任意组合都可视为新的特征。例如,在音乐推荐应用中,我们有两个类别型特征:用户ID和音乐流派。如果有些用户更喜欢摇滚乐,将用户ID和音乐流派转换为数字特征时,根据上述这些信息就会丢失。结合这两个特征就可以解决这个问题,并且可以得到一个新的强大的特征。然而,组合的数量会随着数据集中类别型特征的数量成指数增长,因此不可能在算法中考虑所有组合。为当前树构造新的分割点时,CatBoost会采用贪婪的策略考虑组合。对于树的第一次分割,不考虑任何组合。对于下一个分割,CatBoost将当前树的所有组合、类别型特征与数据集中的所有类别型特征相结合。组合被动态地转换为数字。CatBoost还通过以下方式生成数值型特征和类别型特征的组合:树选择的所有分割点都被视为具有两个值的类别型特征,并且组合方式和类别型特征一样。
重要的实现细节
用数字代替类别值的另一种方法是计算该类别值在数据集特征中出现的次数。这是一种简单但强大的技术,在CatBoost也有实现。这种统计量也适用于特征组合。
CatBoost算法为了在每个步骤中拟合最优的先验条件,我们考虑多个先验条件,为每个先验条件构造一个特征,这在质量上比提到的标准技术更有效。
克服梯度偏差
CatBoost,和所有标准梯度提升算法一样,都是通过构建新树来拟合当前模型的梯度。然而,所有经典的提升算法都存在由有偏的点态梯度估计引起的过拟合问题。在每个步骤中使用的梯度都使用当前模型中的相同的数据点来估计,这导致估计梯度在特征空间的任何域中的分布与该域中梯度的真实分布相比发生了偏移,从而导致过拟合。
许多利用GBDT技术的算法(例如,XGBoost、LightGBM),构建一棵树分为两个阶段:选择树结构和在树结构固定后计算叶子节点的值。为了选择最佳的树结构,算法通过枚举不同的分割,用这些分割构建树,对得到的叶子节点中计算值,然后对得到的树计算评分,最后选择最佳的分割。两个阶段叶子节点的值都是被当做梯度或牛顿步长的近似值来计算。CatBoost第一阶段采用梯度步长的无偏估计,第二阶段使用传统的GBDT方案执行。
快速评分
CatBoost使用oblivious树作为基本预测器。在这类树中,相同的分割准则在树的整个级别上使用。这种树是平衡的,不太容易过拟合。梯度提升oblivious树被成功地用于各种学习任务。在oblivious树中,每个叶子节点的索引可以被编码为长度等于树深度的二进制向量。这在CatBoost模型评估器中得到了广泛的应用:我们首先将所有浮点特征、统计信息和独热编码特征进行二值化,然后使用二进制特征来计算模型预测值。
所有样本的所有二进制特征值都存储在连续向量B中。叶子节点的值存储在大小为$2^d$的浮点数向量中,其中d是树的深度。为了计算第t棵树的叶子节点的索引,对于样本x,我们建立了一个二进制向量:
$$\sum_{i=0}^{d-1}2^{i}\cdot B(x,f(t,j))$$
其中B(x,f)是从向量B读取的样本x上的二进制特征f的值,而f(t,i)是从深度i上的第t棵树中的二进制特征的数目。这些向量可以以数据并行的方式构建,这种方式可以实现高达3倍的加速。
基于GPU实现快速学习
密集的数值特征
对于任何GBDT算法而言,最大的难点之一就是搜索最佳分割。尤其是对于密集的数值特征数据集来说,该步骤是建立决策树时的主要计算负担。CatBoost使oblivious决策树作为基础模型,并将特征离散化到固定数量的箱子中以减少内存使用。箱子的数量是算法的参数。因此,可以使用基于直方图的方法来搜索最佳分割。我们利用一个32位整数将多个数值型特征打包,规则:
- 存储二进制特征用1位,每个整数包括32个特征
- 存储不超过15个值的特征用4位,每个整数包括8个特征
- 存储其他特征用8位(不同值的个数最大是255),每个整数包括4个特征
就GPU内存使用而言,CatBoost至少与LightGBM一样有效。主要不同是利用一种不同的直方图计算方法。LightGBM和XGBoost的算法有一个主要缺点:它们依赖于原子操作。这种技术在内存上很容易处理,但是在性能好的GPU上,它会比较慢。事实上直方图可以在不涉及原子操作的情况下更有效地计算。
类别型特征CatBoost实现了多种处理类别型特征的方法。对于独热编码特征,我们不需要任何特殊处理,基于直方图的分割搜索方法可以很容易地处理这种情况。在数据预处理阶段,就可以对单个类别型特征进行统计计算。CatBoost还对特征组合使用统计信息。处理它们是算法中速度最慢、消耗内存最多的部分。
CatBoost使用完美哈希来存储类别特征的值,以减少内存使用。由于GPU内存的限制,我们在CPU RAM中存储按位压缩的完美哈希,以及要求的数据流、重叠计算和内存等操作。动态地构造特征组合要求我们为这个新特征动态地构建(完美)哈希函数,并为哈希的每个唯一值计算关于某些排列的统计数据。CatBoost使用基数排序来构建完美的哈希,并通过哈希来分组观察。在每个组中,需要计算一些统计量的前缀和。该统计量的计算使用分段扫描GPU图元进行(CatBoost分段扫描实现通过算子变换完成,并且基于CUB中扫描图元的高效实现)。
多GPU支持
CatBoost中的GPU实现可支持多个GPU。分布式树学习可以通过数据或特征进行并行化。CatBoost采用多个学习数据集排列的计算方案,在训练期间计算分类特征的统计数据。
CatBoost的安装与使用
CatBoost的安装非常的简单,只需执行 pip install catboost 即可。
CatBoost使用示例
import numpy as np
import catboost as cb
train_data = np.random.randint(0, 100, size=(100, 10))
train_label = np.random.randint(0, 2, size=(100))
test_data = np.random.randint(0, 100, size=(50, 10))
model = cb.CatBoostClassifier(iterations=2, depth=2, learning_rate=0.5, loss_function='Logloss',
logging_level='Verbose')
model.fit(train_data, train_label, cat_features=[0, 2, 5])
preds_class = model.predict(test_data)
preds_probs = model.predict_proba(test_data)
print('class=', preds_class)
print('proba=', preds_probs)
方法(method):
- Fit
- X:输入数据数据类型可以是,list;pandas.DataFrame;pandas.Series
- y=None
- cat_features=None:拿来做处理的类别特征
- sample_weight=None:输入数据的样本权重
- logging_level=None:控制是否输出日志信息,或者何种信息
- plot=False:训练过程中,绘制,度量值,所用时间等
- eval_set=None:验证集合,数据类型list(X,y)tuples
- baseline=None
- use_best_model=None
- verbose=None
- predict返回验证样本所属类别,数据类型为array
- predict_proba返回验证样本所属类别的概率,数据类型为array
- get_feature_importance
- eval_metrics
- save_model
- load_model
- get_params
- score
属性(attribute):
- is_fitted_
- tree_count_
- feature_importances_
- random_seed_
CatBoost参数详解
通用参数:
- loss_function损失函数,支持的有RMSE,Logloss,MAE,CrossEntropy,Quantile,LogLinQuantile,Multiclass,MultiClassOneVsAll,MAPE,Poisson。默认RMSE。
- custom_metric训练过程中输出的度量值。这些功能未经优化,仅出于信息目的显示。默认None。
- eval_metric用于过拟合检验(设置True)和最佳模型选择(设置True)的lossfunction,用于优化。
- iterations最大树数。默认1000。
- learning_rate学习率。默认03。
- random_seed训练时候的随机种子
- l2_leaf_regL2正则参数。默认3
- bootstrap_type定义权重计算逻辑,可选参数:Poisson(supportedforGPUonly)/Bayesian/Bernoulli/No,默认为Bayesian
- bagging_temperature贝叶斯套袋控制强度,区间[0,1]。默认1。
- subsample设置样本率,当bootstrap_type为Poisson或Bernoulli时使用,默认66
- sampling_frequency设置创建树时的采样频率,可选值PerTree/PerTreeLevel,默认为PerTreeLevel
- random_strength分数标准差乘数。默认1。
- use_best_model设置此参数时,需要提供测试数据,树的个数通过训练参数和优化lossfunction获得。默认False。
- best_model_min_trees最佳模型应该具有的树的最小数目。
- depth树深,最大16,建议在1到10之间。默认6。
- ignored_features忽略数据集中的某些特征。默认None。
- one_hot_max_size如果feature包含的不同值的数目超过了指定值,将feature转化为float。默认False
- has_time在将categoricalfeatures转化为numericalfeatures和选择树结构时,顺序选择输入数据。默认False(随机)
- rsm随机子空间(Randomsubspacemethod)。默认1。
- nan_mode处理输入数据中缺失值的方法,包括Forbidden(禁止存在缺失),Min(用最小值补),Max(用最大值补)。默认Min。
- fold_permutation_block_size数据集中的对象在随机排列之前按块分组。此参数定义块的大小。值越小,训练越慢。较大的值可能导致质量下降。
- leaf_estimation_method计算叶子值的方法,Newton/Gradient。默认Gradient。
- leaf_estimation_iterations计算叶子值时梯度步数。
- leaf_estimation_backtracking在梯度下降期间要使用的回溯类型。
- fold_len_multiplierfolds长度系数。设置大于1的参数,在参数较小时获得最佳结果。默认2。
- approx_on_full_history计算近似值,False:使用1/fold_len_multiplier计算;True:使用fold中前面所有行计算。默认False。
- class_weights类别的权重。默认None。
- scale_pos_weight二进制分类中class1的权重。该值用作class1中对象权重的乘数。
- boosting_type增压方案
- allow_const_label使用它为所有对象训练具有相同标签值的数据集的模型。默认为False
CatBoost默认参数:
- ‘iterations’: 1000,
- ‘learning_rate’: 0.03,
- ‘l2_leaf_reg’: 3,
- ‘bagging_temperature’: 1,
- ‘subsample’: 0.66,
- ‘random_strength’: 1,
- ‘depth’: 6,
- ‘rsm’: 1,
- ‘one_hot_max_size’: 2
- ‘leaf_estimation_method’: ‘Gradient’,
- ‘fold_len_multiplier’: 2,
- ‘border_count’: 128,
- ‘learning_rate’: Log-uniform distribution [e^{-7}, 1]
- ‘random_strength’: Discrete uniform distribution over a set {1, 20}
- ‘one_hot_max_size’: Discrete uniform distribution over a set {0, 25}
- ‘l2_leaf_reg’: Log-uniform distribution [1, 10]
- ‘bagging_temperature’: Uniform [0, 1]
- ‘gradient_iterations’: Discrete uniform distribution over a set {1, 10}‘
CatBoost参数取值范围:
其他参考:https://catboost.ai/
CatBoost参数调优
from catboost import CatBoostRegressor
from sklearn.model_selection import GridSearchCV
# 指定category类型的列,可以是索引,也可以是列名
cat_features = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13]
X = df_ios_droped.iloc[:, :-1]
y = df_ios_droped.iloc[:, -1]
cv_params = {'iterations': [500, 600, 700, 800]}
other_params = {
'iterations': 1000,
'learning_rate': 0.03,
'l2_leaf_reg': 3,
'bagging_temperature': 1,
'random_strength': 1,
'depth': 6,
'rsm': 1,
'one_hot_max_size': 2,
'leaf_estimation_method': 'Gradient',
'fold_len_multiplier': 2,
'border_count': 128,
}
model_cb = CatBoostRegressor(**other_params)
optimized_cb = GridSearchCV(estimator=model_cb, param_grid=cv_params, scoring='r2', cv=5, verbose=1, n_jobs=2)
optimized_cb.fit(X, y, cat_features=category_features)
print('参数的最佳取值:{0}'.format(optimized_cb.best_params_))
print('最佳模型得分:{0}'.format(optimized_cb.best_score_))
print(optimized_cb.cv_results_['mean_test_score'])
print(optimized_cb.cv_results_['params'])
# params = {'depth': [3, 4, 5, 7, 8, 9, 10],
# 'iterations': [100, 250, 500, 1000],
# 'learning_rate': [0.001, 0.01, 0.003, 0.1, 0.2, 0.3],
# 'l2_leaf_reg': [1, 3, 5, 10, 100],
# 'border_count': [2, 4, 8, 16, 32, 64, 128, 256]}
其他参考:Using GridSearch to Optimise CatBoost Parameters
相关链接:


