在当今数据驱动的商业环境中,企业面临着海量、多样且高速增长的数据挑战。为了从这些数据中提取价值,两种主流的存储与管理架构应运而生:数据湖与数据仓库。尽管它们都是用于存储和分析数据的系统,但其设计哲学、技术实现和应用场景存在根本性差异。
数据湖:定义与核心理念
数据湖是一个集中式的存储库,允许企业以任意规模存储所有结构化和非结构化数据,且数据按原始格式保存,无需在存储前进行结构化处理。这个概念最早由Pentaho的CTO James Dixon在2010年提出,他将经过精心处理和封装的数据集市比作“瓶装水”,而将存储原始数据的数据湖比作“自然状态的水体”。数据湖的核心目标是保存数据的“保真性”和“原汁原味”,为后续灵活多样的分析提供基础。
其本质包含四个关键部分:统一的存储系统、存储原始数据、支持丰富的计算模型,并且其概念本身与是否上云无关。现代数据湖,尤其是云数据湖,通常基于对象存储(如AWS S3、阿里云OSS)构建,采用存储与计算分离的架构,以实现更好的弹性与成本效益。

数据湖的核心特点与价值
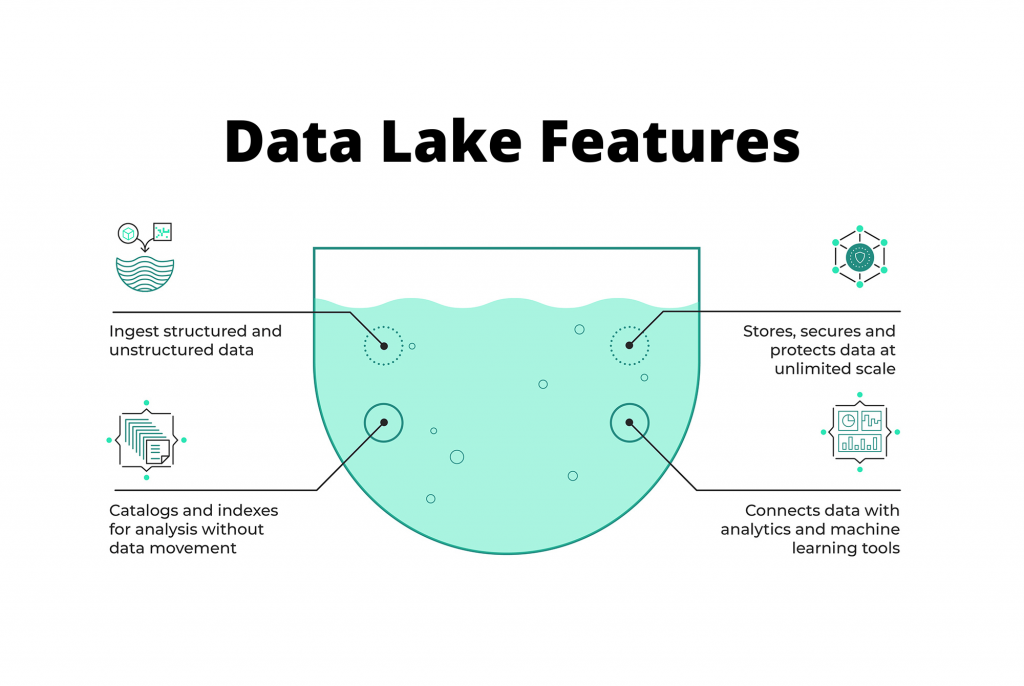
- 数据类型与存储灵活性:数据湖能够容纳结构化(如数据库表)、半结构化(如CSV、JSON、XML)和非结构化(如文档、图像、音视频)等任意类型的数据。这种能力使其成为处理物联网数据、社交媒体流、日志文件等现代数据源的理想场所。
- “读时模式”:这是数据湖与数据仓库最根本的区别之一。数据湖采用 “Schema-on-Read” ,即数据的结构定义和转换发生在数据被读取和分析之时。相比之下,数据仓库采用 “Schema-on-Write” ,要求数据在写入前就必须根据预定义的模型进行清洗和转换。读时模式赋予了数据湖极高的敏捷性,企业可以快速接入数据,待业务需求明确后再进行加工,非常适合业务模式处于探索和创新阶段的场景。
- 可扩展性与成本效益:数据湖通常构建在可水平扩展的分布式文件系统或云存储之上,能够轻松处理PB级甚至更大量的数据增长。同时,采用低成本的对象存储方案,使其在大规模数据存储上比传统数据仓库更具成本优势。
- 支持高级分析与创新:数据湖存储了最原始、最细粒度的数据,为数据科学家和高级分析师提供了进行探索性分析、机器学习模型训练和预测性分析的“富矿”。它像一个沙盒环境,支持用户以自助的方式尝试新的分析方法和工具,从而驱动业务创新。
数据湖与数据仓库的全面对比
尽管数据湖和数据仓库都是数据存储解决方案,但它们在多个维度上存在显著差异,如下表所示:
| 对比维度 | 数据湖 | 数据仓库 |
| 核心数据 | 原始数据(任何格式) | 经过清洗、转换和聚合的结构化数据 |
| 处理流程 | ELT(抽取-加载-转换) | ETL(抽取-转换-加载) |
| 模式 | 读时模式(Schema-on-Read) | 写时模式(Schema-on-Write) |
| 主要用户 | 数据科学家、数据工程师、进行探索性分析的业务分析师 | 商业智能分析师、业务用户(使用SQL和报表) |
| 核心优势 | 灵活性高、支持多类型数据、存储成本低、适合探索与创新 | 查询性能高、数据质量好、治理完善、适合稳定报表与BI |
| 主要挑战 | 易沦为“数据沼泽”(管理混乱、难以发现和使用)、数据治理较难 | 前期建模成本高、架构相对僵化、难以处理非结构化数据 |
| 存储架构 | 扁平化架构,通常基于对象存储或HDFS | 结构化架构,通常为星型或雪花型模型,采用列式存储 |
| 适用场景 | 大数据分析、机器学习、实时数据处理、数据探索与发现 | 历史趋势分析、标准化报表、运营指标监控、即席查询 |
更深入的辨析:
- 方法论差异:数据湖是“事后建模”,鼓励先收集数据再思考如何使用;数据仓库是“事前建模”,要求先明确业务问题再设计数据模型。
- 开放性与优化:数据湖架构开放,支持多种计算引擎(如Spark、Presto、Flink)对接同一份存储,但端到端优化较难。数据仓库通常是封闭的集成系统,存储与计算深度耦合,易于进行端到端性能优化。
- 成本曲线:数据湖初始上手成本低,但随着数据规模增长,治理和运维成本可能急剧上升。数据仓库初始建设成本高(需顶层设计),但后续的运维和管理成本相对可控。
数据湖的挑战与未来趋势:湖仓一体
数据湖并非完美无缺。其最大的风险在于,如果缺乏有效的数据治理、元数据管理和数据目录,海量的原始数据会迅速变得难以查找、理解和信任,从而退化为毫无价值的“数据沼泽”。因此,构建数据湖时必须配套完善的数据管理能力,确保数据的可追溯性和可管理性。
正是为了融合数据湖的灵活性与数据仓库的严谨性,业界提出了 “湖仓一体” 的新范式。它旨在打破两者之间的壁垒,实现:
- 在数据湖的低成本存储上,提供数据仓库般的数据管理、事务支持和性能优化(如Delta Lake, Apache Hudi)。
- 让数据在湖和仓之间无缝流动,原始数据在湖中探索和加工,加工后的高质量数据可注入数仓供BI使用,反之亦然。
- 统一的治理和安全模型,跨越湖和仓,简化数据管理复杂度。
目前,云厂商(如阿里云MaxCompute、AWS Redshift)和开源生态(如Databricks)都在积极推动湖仓一体的落地,这代表了大数据平台未来发展的主要方向。
总结与选型建议
数据湖和数据仓库是互补而非替代的关系。企业选择时需综合考虑:
- 选择数据仓库:当企业有明确、稳定的报表和BI需求,处理的数据以结构化为主,且对查询性能、数据准确性和一致性有极高要求时。
- 选择数据湖:当企业需要处理海量、多源、多类型的原始数据,业务处于快速变化和创新阶段,并希望支持数据科学、机器学习和探索性分析时。
- 采用湖仓一体架构:对于大多数现代化企业,尤其是已经积累了庞大数据资产的公司,采用湖仓一体的混合架构往往是更优解。它既能利用数据湖的灵活性容纳所有数据并支持创新,又能通过数据仓库的能力保障关键业务数据的质量和性能,从而实现数据价值最大化。
总之,理解数据湖与数据仓库的深刻区别,是构建高效、敏捷且面向未来的数据架构的基石。在数据成为核心生产要素的今天,根据自身业务特性选择合适的路径,或迈向湖仓融合的未来,是企业实现数字化转型和智能决策的关键一步。


