就像哲学有不同的流派一样,推荐系统的算法设计思路也可以分为不同的流派。排序学习恰恰就是其中的一种流派。熟悉 RecSys 等推荐系统国际会议的从业者可能会发现,自 2010 年以后的若干年内,陆续出现了许多基于排…

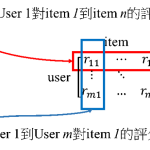
ALS(alternating least squares) ALS是交替最小二乘的简称。在机器学习中,ALS特指使用交替最小二乘求解的一个协同推荐算法。如:将用户(user)对商品(item)的评分矩阵分解成2个矩阵: user对item潜在因素的…
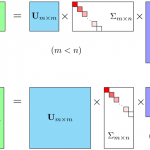
什么是 SVD? 奇异值分解(singular value decomposition)是线性代数中一种重要的矩阵分解,在生物信息学、信号处理、金融学、统计学等领域有重要应用,SVD 都是提取信息的强度工具。在机器学习领域,很多应用与奇…
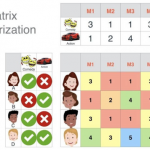
矩阵分解简介 推荐领域的人一般都会听说过十年前 Netflix Prize 的比赛,随着 Netflix Prize 推荐比赛的成功举办,近年来隐语义模型(Latent Factor Model,LFM)受到越来越多的关注。隐语义模型最早在文本挖掘领域…
点击率(click-through rate, CTR)是点击特定链接的用户与查看页面,电子邮件或广告的总用户数量之比。它通常用于衡量某个网站的在线广告活动是否成功,以及电子邮件活动的有效性,是互联网公司进行流量分配的核心依…
异常的分类 时间序列的异常检测问题通常表示为相对于某些标准信号或常见信号的离群点。虽然有很多的异常类型,但是我们只关注业务角度中最重要的类型,比如意外的峰值、下降、趋势变化以及等级转换(level shifts)…
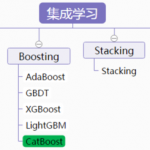
CatBoost是俄罗斯的搜索巨头Yandex在2017年开源的机器学习库,是Gradient Boosting(梯度提升)+Categorical Features(类别型特征),也是基于梯度提升决策树的机器学习框架。 CatBoost 简介 CatBoost这个名字来…
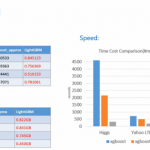
上一篇文章介绍了一个梯度提升决策树模型XGBoost,这篇文章我们继续学习一下GBDT模型的另一个进化版本:LightGBM。LigthGBM是boosting集合模型中的新进成员,由微软提供,它和XGBoost一样是对GBDT的高效实现,原理…
在上一篇Boosting方法的介绍中,对XGBoost有过简单的介绍。为了更还的掌握XGBoost这个工具。我们再来对它进行更加深入细致的学习。 什么是XGBoost? 全称:eXtreme Gradient Boosting 作者:陈天奇(华盛顿大学博…
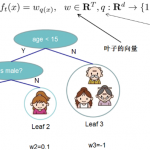
集成学习 集成学习是通过训练若干个弱学习器,并通过一定的结合策略,从而形成一个强学习器。有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等。 集成学…