文章内容如有错误或排版问题,请提交反馈,非常感谢!
ISODATA算法(Iterative Self Organizing Data Analysis Techniques Algorithm,迭代自组织数据分析方法)和K-Means算法是相似的算法,都是属于无监督的聚类分析方法,但是
在之前介绍的K-Means算法中,有两大缺陷:
- K值需要预先设定
- 随机的初始中心选择对计算结果和迭代次数有较大的影响
虽然通过K-Means++有效的解决了随机初始中心选择的问题,但是对于K值的预先设定,在K-Means++中也没有很好的解决,ISODATA算法则可以有效的解决K值需要设定的问题。ISODATA算法是在k-Means算法的基础上,增加对聚类结果的”合并”和”分裂”两个操作,即当两个聚簇中心的值小于某个阈值时,将两个聚类中心合并成一个,当某个聚簇的标准差小于一定的阈值时或聚簇内样本数量超过一定阈值时,将该聚簇分列为2个聚簇,甚至当某个聚簇中的样本量小于一定阈值时,则取消该聚簇。
ISODATA算法
ISODATA算法的输入:
- 预期的聚类中心数目Ko:虽然在ISODATA运行过程中聚类中心数目是可变的,但还是需要由用户指定一个参考标准。事实上,该算法的聚类中心数目变动范围也由Ko决定。具体地,最终输出的聚类中心数目范围是[Ko/2, 2Ko]。
- 每个类所要求的最少样本数目Nmin:用于判断当某个类别所包含样本分散程度较大时是否可以进行分裂操作。如果分裂后会导致某个子类别所包含样本数目小于Nmin,就不会对该类别进行分裂操作。
- 最大方差Sigma:用于衡量某个类别中样本的分散程度。当样本的分散程度超过这个值时,则有可能进行分裂操作(注意同时需要满足[2]中所述的条件)。
- 两个类别对应聚类中心之间所允许最小距离dmin:如果两个类别靠得非常近(即这两个类别对应聚类中心之间的距离非常小),则需要对这两个类别进行合并操作。是否进行合并的阈值就是由dmin决定。
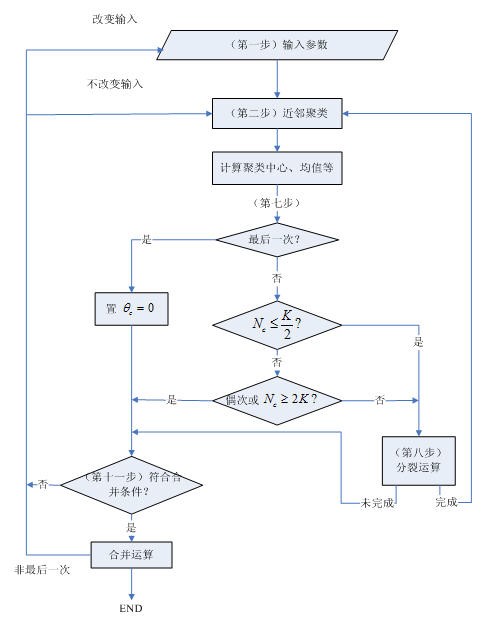
首先给出ISODATA算法主体部分的描述,如下图所示:

上面描述中没有说明清楚的是第5步中的分裂操作和第6步中的合并操作。下面首先介绍合并操作:

最后是ISODATA算法中的分裂操作。

ISODATA算法的原理非常直观,不过由于它和其他两个方法相比需要额外指定较多的参数,并且某些参数同样很难准确指定出一个较合理的值,因此ISODATA算法在实际过程中并没有很受欢迎。


